【CV中的Attention机制】最简单最易实现的SE模块
1. Squeeze-and-Excitation Network¶
SENet是Squeeze-and-Excitation Networks的简称,拿到了ImageNet2017分类比赛冠军,其效果得到了认可,其提出的SE模块思想简单,易于实现,并且很容易可以加载到现有的网络模型框架中。SENet主要是学习了channel之间的相关性,筛选出了针对通道的注意力,稍微增加了一点计算量,但是效果比较好。
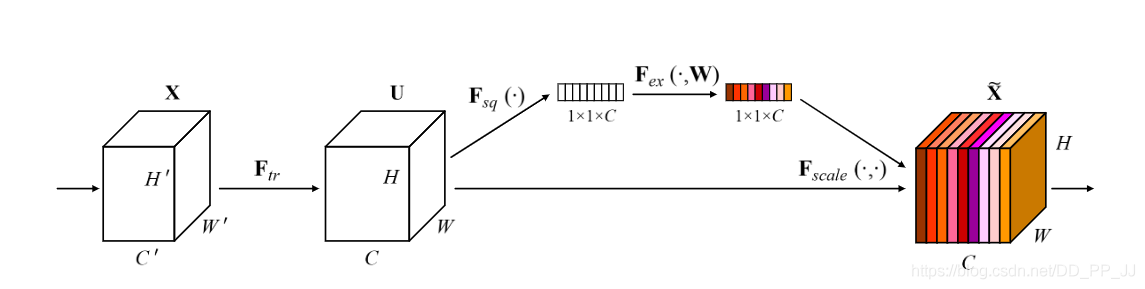
通过上图可以理解他的实现过程,通过对卷积的到的feature map进行处理,得到一个和通道数一样的一维向量作为每个通道的评价分数,然后将改分数分别施加到对应的通道上,得到其结果,就在原有的基础上只添加了一个模块,下边我们用pytorch实现这个很简单的模块。

2. 代码¶
class SELayer(nn.Module):
def __init__(self, channel, reduction=16):
super(SELayer, self).__init__()
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Linear(channel, channel // reduction, bias=False),
nn.ReLU(inplace=True),
nn.Linear(channel // reduction, channel, bias=False),
nn.Sigmoid()
)
def forward(self, x):
b, c, _, _ = x.size()
y = self.avg_pool(x).view(b, c)
y = self.fc(y).view(b, c, 1, 1)
return x * y.expand_as(x)
3. 实验¶
虽然核心就是以上的内容,不过不能简单地结束,我们需要看一下以下几个点:
-
作为一个重要的attention机制的文章,这篇文章如何描述attention,related work如何组织?
attention机制当时已经有一定的研究和发展,也是集中于序列学习,image captioning, understanding in images这些工作,也已经有很多出色的工作是探索了attention机制。senet这篇文章主要探索了通过对通道间关系进行建模来提升模型的表达能力。related work 主要从更深的网络架构,架构搜索,注意力机制三个角度进行了梳理,确实非常全面。
-
如何解释SE模块?
Sequeeze:对C\times H\times W 进行global average pooling,得到 1\times 1\times C大小的特征图,这个特征图可以理解为具有全局感受野。
Excitation :使用一个全连接神经网络,对Sequeeze之后的结果做一个非线性变换。
特征重标定:使用Excitation 得到的结果作为权重,乘到输入特征上。
-
SE模块如何加到分类网络,效果如何?
分类网络现在一般都是成一个block一个block,se模块就可以加到一个block结束的位置,进行一个信息refine。这里用了一些STOA的分类模型如:resnet50,resnext50,bn-inception等网络。通过添加SE模块,能使模型提升0.5-1.5%,效果还可以,增加的计算量也可以忽略不计。在轻量级网络MobileNet,ShuffleNet上也进行了实验,可以提升的点更多一点大概在1.5-2%。
-
SE模块如何加到目标检测网络,效果如何?
主要还是将SE模块添加到backbone部分,优化学习到的内容。目标检测数据集使用的是benchmark MSCOCO, 使用的Faster R-CNN作为目标检测器,使用backbone从ResNet50替换为SE-ResNet50以后带了了两个点的AP提升,确实有效果。
-
这篇文章的实验部分是如何设置的?
这篇文章中也进行了消融实验,来证明SE模块的有效性,也说明了设置reduction=16的原因。
- squeeze方式:仅仅比较了max和avg,发现avg要好一点。
- excitation方式:使用了ReLU,Tanh,Sigmoid,发现Sigmoid好。
- stage: resnet50有不同的阶段,通过实验发现,将se施加到所有的阶段效果最好。
- 集成策略:将se放在残差单元的前部,后部还是平行于残差单元,最终发现,放到前部比较好。
-
如何查看每个通道学到的attention信息并证明其有效性?
作者选取了ImageNet中的四个类别进行了一个实验,测试backbone最后一个SE层的内容,如下图所示:

可以看出这两个类激活出来的内容有一定的差距,起到了一定的作用。
4. Reference¶
论文地址:https://arxiv.org/abs/1709.01507
代码参考地址:https://github.com/moskomule/senet.pytorch
核心代码:https://github.com/pprp/SimpleCVReproduction/blob/master/attention/SE/senet.py
本文总阅读量次