1. 前言¶
前几天听人聊到了这个YOLT,本着长见识的目的稍微看了看,然后打算在这里给没看到的人做一个科普,希望这里面的几个Tricks可以对你有所启发。YOLT论文全称You Only Look Twice: Rapid Multi-Scale Object Detection In Satellite Imagery ,是专为卫星图像目标检测而设计的一个检测器,是在YOLOV2的基础上进行改进的。论文原文和代码实现见附录。
2. 介绍¶
众所周知,卫星图像的目标检测和普通场景的目标检测最大的区别在于卫星图像尺寸很大比如16000\times 16000,并且其目标通常很小且容易聚集在一起。针对这一痛点,YOLT被提出,另外YOLT中也提出了一些对普通检测场景有用的Trick,可以让我们借鉴,所以还是值得一读的。在卫星图像中,图片的分辨率一般用ground sample distance(GSD)来表示,比如最常见的卫星图像是30cm GSD。
3. YOLT核心理论¶
下面的Figure3详细展示了卫星图像目标检测的主要几个难点以及YOLT的解决方案,左边这一列代表难点,右边则代表YOLT提出的方法。
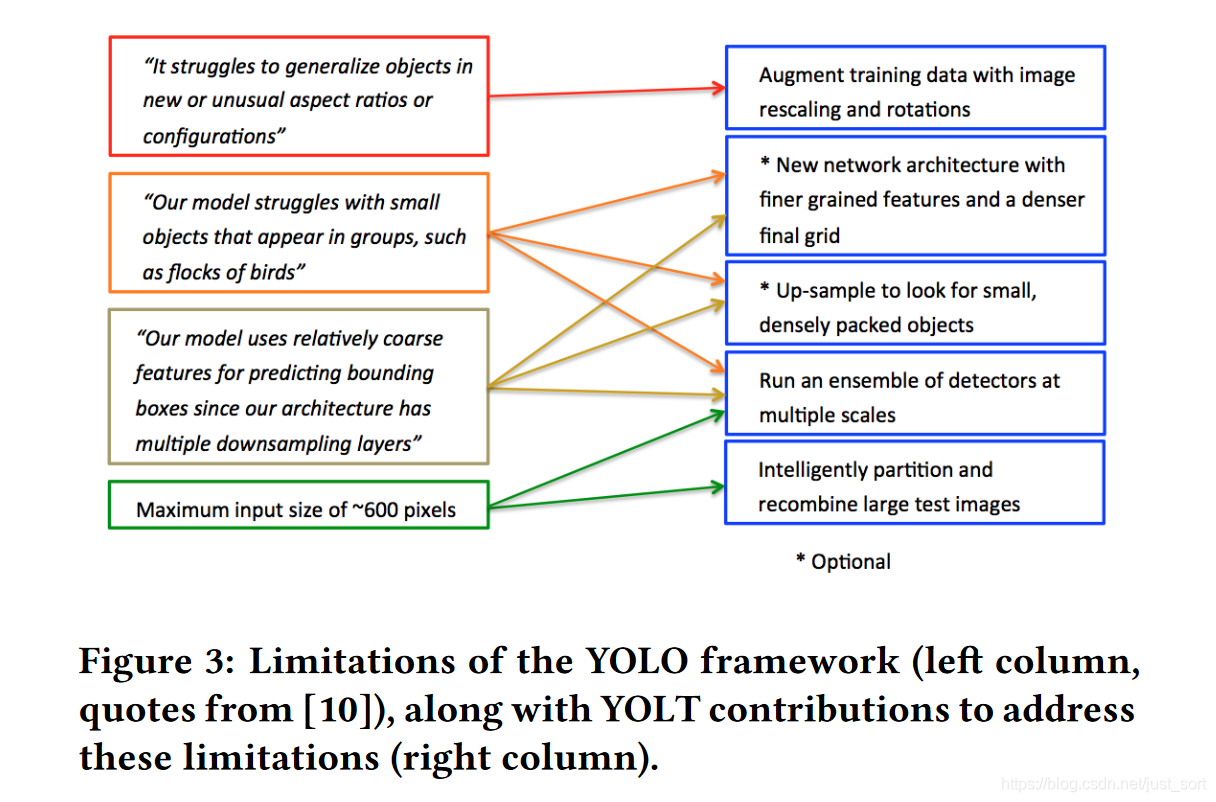
我们来描述一下这几个难点和解决方案:
- 一,卫星图目标的尺寸,方向多样。卫星图是从空中拍摄的,因此角度不固定,像船、汽车的方向都可能和常规目标检测算法中的差别较大,因此检测难度大。针对这一点的解决方案是对数据做尺度变换,旋转等数据增强操作。
- 二,小目标的检测难度大。针对这一点解决方案有下面三点。
1、修改网络结构,使得YOLOV2的stride变成16,而不是原始的32,这样有利于检测出大小在16\times 16 -> 32\times 32。
2、沿用YOLOV2中的passthrough layer,融合不同尺度的特征(52\times 52和26\times 26大小的特征),这种特征融合做法在目前大部分通用目标检测算法中被用来提升对小目标的检测效果。
3、不同尺度的检测模型融合,即Ensemble,原因是例如飞机和机场的尺度差异很大,因此采用不同尺度的输入训练检测模型,然后再融合检测结果得到最终输出。
- 三,卫星图像尺寸太大。解决方案有将原始图像切块,然后分别输入模型进行检测以及将不同尺度的检测模型进行融合。
YOLT的网络结构如下面的Table1所示:
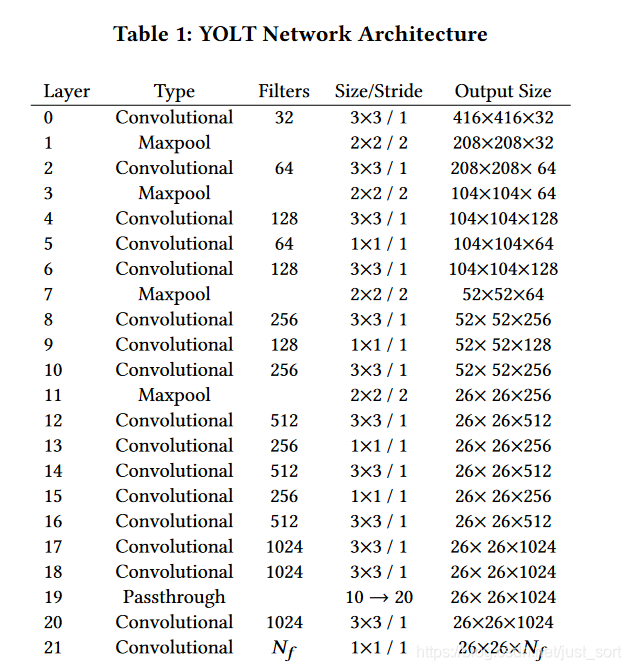
可以看到网络结构相对于YOLOV2最大的修改就是最后输出特征尺寸只到了26\times 26,这样就能有效的提高对小目标的检测效果。
4. 一些观察¶
下面的Figure2展示了使用两种不同类型的图像作为输入时模型(原始的YOLOv2)的预测结果对比,左边是直接把卫星图像原图resize到416\times 416大小,可有看到结果是一辆车都检测不出来。右边则是从原图中裁剪出416\times 416大小的区域然后作为模型的输入,可以看到部分车被检测出来了,但是效果一般。从这个实验可以发现,如果直接将原图resize到网络输入大小是不靠谱的,所以YOLT采用了裁剪方式进行训练和测试图片。

下面的Figure4则展示了在测试模型时如何对输入图像进行处理。

上半部分表示的是原始的卫星图片,因为图片分辨率太大,所以采用了划窗方式裁剪指定尺寸如416\times 416的图像作为模型的输入,论文将裁剪后的区域称为chip,并且相邻的chip会有15%的重叠,这样做的目的是为了保证每个区域都能被完整检测到,虽然这带来了一些重复检测,但可以通过NMS算法滤掉。通过这种操作,一张卫星图像会被裁剪出数百/千张指定尺寸的图像,这些图像被检测之后将检测结果合并经过NMS处理后就可以获得最终的检测结果了。
下面的Figure5展示了训练数据的整体情况,一共有5个类别,包括飞机,船,建筑物,汽车,机场等。对训练数据的处理和测试数据是类似的,也是从原图裁剪多个chip喂给网络。

这篇论文的一个核心操作就是:
针对机场目标和其它目标分别训练了一个检测模型,这两个检测模型的输入图像尺度也不一样,测试图像时同理,最后将不同检测模型、不同chip的检测结果合并在一起就得到最终一张卫星图像的输出。也即是说这篇文章的核心操作就是这个不同尺度的模型融合以及针对机场单独训练一个模型,这样确实是从数据出发能够很好的解决实际场景(卫星图像)中机场目标数据太少带来的问题。
5. 实验结果¶
下面的Figure7展示了一张对于汽车目标的检测结果,可以看到效果还是不错的,并且在1s内能获得结果,同时F1值达到0.95。

接下来作者还对不同输入分辨率做了实验,下面的Figure10代表对原始分辨率(左上角的0.15m表示GSD是0.15m)进行不同程度的放大之后获得的低分辨率图像,这些图像都被用来训练模型,

然后Figure13将不同分辨率输入下检测模型的F1值进行了图表量化,其中横坐标代表目标的像素尺寸。可以看到,随着分辨率的降低,图像中目标的像素尺寸也越来越小,检测效果(F1值)也越来越低。
我们还可以发现即便目标只有5个像素点,依然有很好的检测效果,但需要注意的是这里的5个像素点指的是在原图上,你crop之后目标的相对于网络输入的大小肯定是大于5个像素点的,至少让YOLT网络能够检测出来。
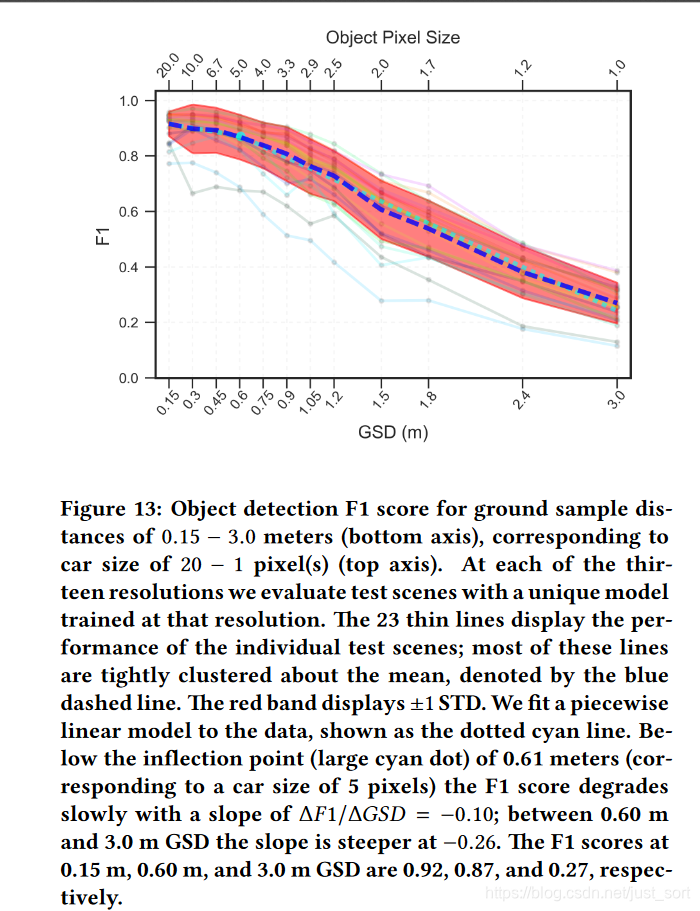
其中不同的场景有不同颜色的线代表,不过这不重要,重要的已经讲过了。
下面的Figure12则可视化了不同分辨率图像的检测效果,左边是15cm GSD的结果,右边则表示了90cm GSD的效果,直观来说,左边的效果是比右边好的。

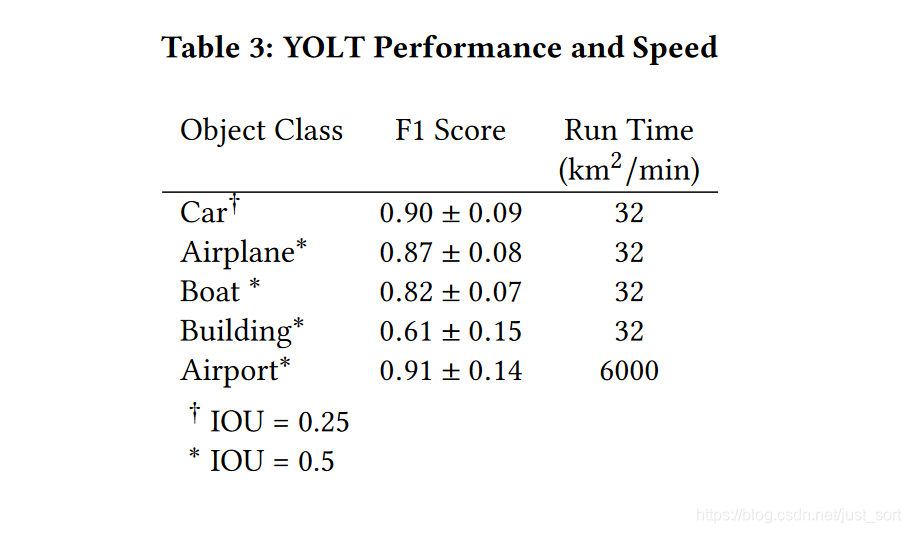
最后Table3展示了YOLT算法对于不同目标的测试精度以及速度情况。
6. 结论¶
这篇文章没什么特别新的东西,但是我比较欣赏这篇文章对数据进行分析的思路。我认为深度学习不应该是把数据输入进去直接给我们返回结果,我们也应当自己思考数据是否有突破点,是否可以降低CNN模型的处理难度,我觉得这一点是十分重要的。
7. 附录¶
- 论文:https://arxiv.org/abs/1805.09512
- 代码:https://github.com/CosmiQ/yolt
- https://blog.csdn.net/u014380165/article/details/81556805
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

本文总阅读量次