前言¶
算法和工程是我们算法工程师不可缺少的两种能力,之前我介绍了DeepLab V1,V2, V3,但总是感觉少了点什么?只有Paper,没有源码那不相当于是纸上谈兵了,所以今天尝试结合论文的源码来进行仔细的分析这三个算法。等我们分析清楚这三个算法之后,有机会再解析一下DeepLabV3。由于博主最近正在看Pytorch版本的《动手学深度学习》,不妨用Pytorch的源码来进行分析。我分析的源码均来自这个Pytorch工程:https://github.com/kazuto1011/deeplab-pytorch/tree/master/libs/models
DeepLab V1源码分析¶
DeepLab V1的算法原理可以看我之前的推文,地址是:https://mp.weixin.qq.com/s/rvP8-Y-CRuq4HFzR0qJWcg 。我们今天解析的网络模型是在ResNet残差模块的基础上融合空洞卷积实现的,第一层为 普通卷积,stride = 2,紧跟着 stride = 2 的 max-pooling,然后一个普通的 bottleneck ,一个 stride = 2 的 bottleneck,然后 dilation =2、dilation =4 的bottleneck。
from __future__ import absolute_import, print_function
import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义DeepLabV1的网络结构
class DeepLabV1(nn.Sequential):
"""
DeepLab v1: Dilated ResNet + 1x1 Conv
Note that this is just a container for loading the pretrained COCO model and not mentioned as "v1" in papers.
"""
def __init__(self, n_classes, n_blocks):
super(DeepLabV1, self).__init__()
ch = [64 * 2 ** p for p in range(6)]
self.add_module("layer1", _Stem(ch[0]))
self.add_module("layer2", _ResLayer(n_blocks[0], ch[0], ch[2], 1, 1))
self.add_module("layer3", _ResLayer(n_blocks[1], ch[2], ch[3], 2, 1))
self.add_module("layer4", _ResLayer(n_blocks[2], ch[3], ch[4], 1, 2))
self.add_module("layer5", _ResLayer(n_blocks[3], ch[4], ch[5], 1, 4))
self.add_module("fc", nn.Conv2d(2048, n_classes, 1))
# 这里是看一下是使用torch的nn模块中BatchNorm还是在encoding文件中定义的BatchNorm
try:
from encoding.nn import SyncBatchNorm
_BATCH_NORM = SyncBatchNorm
except:
_BATCH_NORM = nn.BatchNorm2d
_BOTTLENECK_EXPANSION = 4
# 定义卷积+BN+ReLU的组件
class _ConvBnReLU(nn.Sequential):
"""
Cascade of 2D convolution, batch norm, and ReLU.
"""
BATCH_NORM = _BATCH_NORM
def __init__(
self, in_ch, out_ch, kernel_size, stride, padding, dilation, relu=True
):
super(_ConvBnReLU, self).__init__()
self.add_module(
"conv",
nn.Conv2d(
in_ch, out_ch, kernel_size, stride, padding, dilation, bias=False
),
)
self.add_module("bn", _BATCH_NORM(out_ch, eps=1e-5, momentum=0.999))
if relu:
self.add_module("relu", nn.ReLU())
# 定义Bottleneck,先1*1卷积降维,然后使用3*3卷积,最后再1*1卷积升维,然后再shortcut连接。
# 降维到多少是由_BOTTLENECK_EXPANSION参数决定的,这是ResNet的Bottleneck。
class _Bottleneck(nn.Module):
"""
Bottleneck block of MSRA ResNet.
"""
def __init__(self, in_ch, out_ch, stride, dilation, downsample):
super(_Bottleneck, self).__init__()
mid_ch = out_ch // _BOTTLENECK_EXPANSION
self.reduce = _ConvBnReLU(in_ch, mid_ch, 1, stride, 0, 1, True)
self.conv3x3 = _ConvBnReLU(mid_ch, mid_ch, 3, 1, dilation, dilation, True)
self.increase = _ConvBnReLU(mid_ch, out_ch, 1, 1, 0, 1, False)
self.shortcut = (
_ConvBnReLU(in_ch, out_ch, 1, stride, 0, 1, False)
if downsample
else lambda x: x # identity
)
def forward(self, x):
h = self.reduce(x)
h = self.conv3x3(h)
h = self.increase(h)
h += self.shortcut(x)
return F.relu(h)
# 定义ResLayer,整个DeepLabv1是用ResLayer堆叠起来的,下采样是在每个ResLayer的第一个
# Bottleneck发生的。
class _ResLayer(nn.Sequential):
"""
Residual layer with multi grids
"""
def __init__(self, n_layers, in_ch, out_ch, stride, dilation, multi_grids=None):
super(_ResLayer, self).__init__()
if multi_grids is None:
multi_grids = [1 for _ in range(n_layers)]
else:
assert n_layers == len(multi_grids)
# Downsampling is only in the first block
for i in range(n_layers):
self.add_module(
"block{}".format(i + 1),
_Bottleneck(
in_ch=(in_ch if i == 0 else out_ch),
out_ch=out_ch,
stride=(stride if i == 0 else 1),
dilation=dilation * multi_grids[i],
downsample=(True if i == 0 else False),
),
)
# 在进入ResLayer之前,先用7*7的卷积核在原图滑动,增大感受野。padding方式设为same,大小不变。
# Pool层的核大小为3,步长为2,这会导致特征图的分辨率发生变化。
class _Stem(nn.Sequential):
"""
The 1st conv layer.
Note that the max pooling is different from both MSRA and FAIR ResNet.
"""
def __init__(self, out_ch):
super(_Stem, self).__init__()
self.add_module("conv1", _ConvBnReLU(3, out_ch, 7, 2, 3, 1))
self.add_module("pool", nn.MaxPool2d(3, 2, 1, ceil_mode=True))
# 相当于Reshape,网络并没有用到
class _Flatten(nn.Module):
def forward(self, x):
return x.view(x.size(0), -1)
# 主函数,输出构建的DeepLab V1模型的结构还有原始图像分辨率和结果图像的分辨率
if __name__ == "__main__":
model = DeepLabV1(n_classes=21, n_blocks=[3, 4, 23, 3])
#model.eval()
image = torch.randn(1, 3, 513, 513)
print(model)
print("input:", image.shape)
print("output:", model(image).shape)
我们看一下网络的输入和输出特征图尺寸:
input: torch.Size([1, 3, 513, 513])
output: torch.Size([1, 21, 65, 65])
网络结构已经非常清晰了,可以直接运行Python代码打印出网络结构或者按照我的源码注释来理解。注意,训练的时候ground truth要resize到和模型的输出特征图尺寸一样大才可以。
DeepLab V2源码分析¶
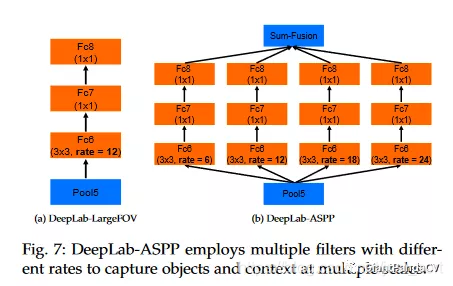
DeepLab V2的论文解读请看我前面发的文章:https://mp.weixin.qq.com/s/ylv3QfOe_BOuVuxQTd_m_g 。简单的说,DeepLab V2就是DeepLab V1的基础上加了一个ASPP模块,这是一个类似于Inception模块的结构,包含不同膨胀系数的空洞卷积,增强模型识别同一物体的多尺度能力。这里仍然只分析源码: 为了方便理解把上篇文章中的ASPP模块的示意图放在这里:
from __future__ import absolute_import, print_function
import torch
import torch.nn as nn
import torch.nn.functional as F
# 定义ASPP模块,这是DeepLab V2和V1的主要区别,可以看到其他部分和V1的代码一模一样
class _ASPP(nn.Module):
"""
Atrous spatial pyramid pooling (ASPP)
"""
def __init__(self, in_ch, out_ch, rates):
super(_ASPP, self).__init__()
for i, rate in enumerate(rates):
self.add_module(
"c{}".format(i),
nn.Conv2d(in_ch, out_ch, 3, 1, padding=rate, dilation=rate, bias=True),
)
for m in self.children():
nn.init.normal_(m.weight, mean=0, std=0.01)
nn.init.constant_(m.bias, 0)
def forward(self, x):
return sum([stage(x) for stage in self.children()])
class DeepLabV2(nn.Sequential):
"""
DeepLab v2: Dilated ResNet + ASPP
Output stride is fixed at 8
"""
def __init__(self, n_classes, n_blocks, atrous_rates):
super(DeepLabV2, self).__init__()
ch = [64 * 2 ** p for p in range(6)]
self.add_module("layer1", _Stem(ch[0]))
self.add_module("layer2", _ResLayer(n_blocks[0], ch[0], ch[2], 1, 1))
self.add_module("layer3", _ResLayer(n_blocks[1], ch[2], ch[3], 2, 1))
self.add_module("layer4", _ResLayer(n_blocks[2], ch[3], ch[4], 1, 2))
self.add_module("layer5", _ResLayer(n_blocks[3], ch[4], ch[5], 1, 4))
self.add_module("aspp", _ASPP(ch[5], n_classes, atrous_rates))
def freeze_bn(self):
for m in self.modules():
if isinstance(m, _ConvBnReLU.BATCH_NORM):
m.eval()
try:
from encoding.nn import SyncBatchNorm
_BATCH_NORM = SyncBatchNorm
except:
_BATCH_NORM = nn.BatchNorm2d
_BOTTLENECK_EXPANSION = 4
class _ConvBnReLU(nn.Sequential):
"""
Cascade of 2D convolution, batch norm, and ReLU.
"""
BATCH_NORM = _BATCH_NORM
def __init__(
self, in_ch, out_ch, kernel_size, stride, padding, dilation, relu=True
):
super(_ConvBnReLU, self).__init__()
self.add_module(
"conv",
nn.Conv2d(
in_ch, out_ch, kernel_size, stride, padding, dilation, bias=False
),
)
self.add_module("bn", _BATCH_NORM(out_ch, eps=1e-5, momentum=0.999))
if relu:
self.add_module("relu", nn.ReLU())
class _Bottleneck(nn.Module):
"""
Bottleneck block of MSRA ResNet.
"""
def __init__(self, in_ch, out_ch, stride, dilation, downsample):
super(_Bottleneck, self).__init__()
mid_ch = out_ch // _BOTTLENECK_EXPANSION
self.reduce = _ConvBnReLU(in_ch, mid_ch, 1, stride, 0, 1, True)
self.conv3x3 = _ConvBnReLU(mid_ch, mid_ch, 3, 1, dilation, dilation, True)
self.increase = _ConvBnReLU(mid_ch, out_ch, 1, 1, 0, 1, False)
self.shortcut = (
_ConvBnReLU(in_ch, out_ch, 1, stride, 0, 1, False)
if downsample
else lambda x: x # identity
)
def forward(self, x):
h = self.reduce(x)
h = self.conv3x3(h)
h = self.increase(h)
h += self.shortcut(x)
return F.relu(h)
class _ResLayer(nn.Sequential):
"""
Residual layer with multi grids
"""
def __init__(self, n_layers, in_ch, out_ch, stride, dilation, multi_grids=None):
super(_ResLayer, self).__init__()
if multi_grids is None:
multi_grids = [1 for _ in range(n_layers)]
else:
assert n_layers == len(multi_grids)
# Downsampling is only in the first block
for i in range(n_layers):
self.add_module(
"block{}".format(i + 1),
_Bottleneck(
in_ch=(in_ch if i == 0 else out_ch),
out_ch=out_ch,
stride=(stride if i == 0 else 1),
dilation=dilation * multi_grids[i],
downsample=(True if i == 0 else False),
),
)
class _Stem(nn.Sequential):
"""
The 1st conv layer.
Note that the max pooling is different from both MSRA and FAIR ResNet.
"""
def __init__(self, out_ch):
super(_Stem, self).__init__()
self.add_module("conv1", _ConvBnReLU(3, out_ch, 7, 2, 3, 1))
self.add_module("pool", nn.MaxPool2d(3, 2, 1, ceil_mode=True))
if __name__ == "__main__":
model = DeepLabV2(
n_classes=21, n_blocks=[3, 4, 23, 3], atrous_rates=[6, 12, 18, 24]
)
model.eval()
image = torch.randn(1, 3, 513, 513)
print(model)
print("input:", image.shape)
print("output:", model(image).shape)
可以看到DeepLab V2的代码除了ASPP模块,其他部分和V1完全一样,所以就没什么好解释的了。但需要注意的一个点是,训练的时候,DeepLabV2的学习率采用了Poly的策略,公式为: lr_{iter}=lr_0*(1-\frac{iter}{max_iter})^{power},当power=0.9时,模型可以取得不普通的分段学习策略MAP值高1.17%的效果。这部分作者也在他的代码中实现了,如下所示:
from torch.optim.lr_scheduler import _LRScheduler
class PolynomialLR(_LRScheduler):
def __init__(self, optimizer, step_size, iter_max, power, last_epoch=-1):
self.step_size = step_size
self.iter_max = iter_max
self.power = power
super(PolynomialLR, self).__init__(optimizer, last_epoch)
def polynomial_decay(self, lr):
return lr * (1 - float(self.last_epoch) / self.iter_max) ** self.power
def get_lr(self):
if (
(self.last_epoch == 0)
or (self.last_epoch % self.step_size != 0)
or (self.last_epoch > self.iter_max)
):
return [group["lr"] for group in self.optimizer.param_groups]
return [self.polynomial_decay(lr) for lr in self.base_lrs]
可以看到这个类是直接继承了Pytorch中的学习率调整类_LRScheduler,可以方便的在每个epoch进行学习率调整。
最后网络的输入分辨率和输出分辨率和DeepLab V1一样,具体训练和数据制作请看作者的github工程:https://github.com/kazuto1011/deeplab-pytorch/tree/master/libs/models 。
DeepLab V3源码分析¶
DeepLab V3论文原理请看我之前发的推文:https://mp.weixin.qq.com/s/D9OX89mklaU4tv74OZMqNg 。这里再简单回归一下DeepLab V3使用的关键Trick。 - 将BN层加到了ASPP模块中。 - 使用了Multi-Grid策略,即在模型后端多加几层不同rate的空洞卷积。 - 具有不同 atrous rates 的 ASPP 能够有效的捕获多尺度信息。不过,论文发现,随着sampling rate的增加,有效filter特征权重(即有效特征区域,而不是补零区域的权重)的数量会变小,极端情况下,当空洞卷积的 rate 和 feature map 的大小一致时,3\times 3卷积会退化为1\times 1卷积。为了解决这一问题,并将全局内容信息整合到模型中,则采用图像级特征。即,采用全局平均池化(global average pooling)对模型的 feature map 进行处理,将得到的图像级特征输入到一个 1×1 convolution with 256 filters(加入 batch normalization)中,然后将特征进行双线性上采样(bilinearly upsample)到特定的空间维度。
DeepLab V3的源码如下:
from __future__ import absolute_import, print_function
from collections import OrderedDict
import torch
import torch.nn as nn
import torch.nn.functional as F
# 全局平均池化,将得到的图像特征输入到一个拥有256个通道的1*1卷积中,最后将特征进行
# 双线性上采样到特定的维度(就是输入到ImagePool之前特征图的维度)
class _ImagePool(nn.Module):
def __init__(self, in_ch, out_ch):
super().__init__()
self.pool = nn.AdaptiveAvgPool2d(1)
self.conv = _ConvBnReLU(in_ch, out_ch, 1, 1, 0, 1)
def forward(self, x):
_, _, H, W = x.shape
h = self.pool(x)
h = self.conv(h)
h = F.interpolate(h, size=(H, W), mode="bilinear", align_corners=False)
return h
# ASPP模块,DeepLabV3改进后的,新增了1*1卷积以及图像全局池化。
class _ASPP(nn.Module):
"""
Atrous spatial pyramid pooling with image-level feature
"""
def __init__(self, in_ch, out_ch, rates):
super(_ASPP, self).__init__()
self.stages = nn.Module()
self.stages.add_module("c0", _ConvBnReLU(in_ch, out_ch, 1, 1, 0, 1))
for i, rate in enumerate(rates):
self.stages.add_module(
"c{}".format(i + 1),
_ConvBnReLU(in_ch, out_ch, 3, 1, padding=rate, dilation=rate),
)
self.stages.add_module("imagepool", _ImagePool(in_ch, out_ch))
def forward(self, x):
return torch.cat([stage(x) for stage in self.stages.children()], dim=1)
# 完整的DeepLabV3的结构,使用带空洞卷积的ResNet+multi-grid策略+改进后的ASPP
class DeepLabV3(nn.Sequential):
"""
DeepLab v3: Dilated ResNet with multi-grid + improved ASPP
"""
def __init__(self, n_classes, n_blocks, atrous_rates, multi_grids, output_stride):
super(DeepLabV3, self).__init__()
# Stride and dilation
if output_stride == 8:
s = [1, 2, 1, 1]
d = [1, 1, 2, 4]
elif output_stride == 16:
s = [1, 2, 2, 1]
d = [1, 1, 1, 2]
ch = [64 * 2 ** p for p in range(6)]
self.add_module("layer1", _Stem(ch[0]))
self.add_module("layer2", _ResLayer(n_blocks[0], ch[0], ch[2], s[0], d[0]))
self.add_module("layer3", _ResLayer(n_blocks[1], ch[2], ch[3], s[1], d[1]))
self.add_module("layer4", _ResLayer(n_blocks[2], ch[3], ch[4], s[2], d[2]))
self.add_module(
"layer5", _ResLayer(n_blocks[3], ch[4], ch[5], s[3], d[3], multi_grids)
)
self.add_module("aspp", _ASPP(ch[5], 256, atrous_rates))
# 连接所有分支的最终特征,输入到256个通道的1*1卷积中,并加入BN,再进入最终的1*1卷积,
# 得到logits结果。
concat_ch = 256 * (len(atrous_rates) + 2)
self.add_module("fc1", _ConvBnReLU(concat_ch, 256, 1, 1, 0, 1))
self.add_module("fc2", nn.Conv2d(256, n_classes, kernel_size=1))
try:
from encoding.nn import SyncBatchNorm
_BATCH_NORM = SyncBatchNorm
except:
_BATCH_NORM = nn.BatchNorm2d
_BOTTLENECK_EXPANSION = 4
# 和DeepLabV1定义一样
class _ConvBnReLU(nn.Sequential):
"""
Cascade of 2D convolution, batch norm, and ReLU.
"""
BATCH_NORM = _BATCH_NORM
def __init__(
self, in_ch, out_ch, kernel_size, stride, padding, dilation, relu=True
):
super(_ConvBnReLU, self).__init__()
self.add_module(
"conv",
nn.Conv2d(
in_ch, out_ch, kernel_size, stride, padding, dilation, bias=False
),
)
self.add_module("bn", _BATCH_NORM(out_ch, eps=1e-5, momentum=0.999))
if relu:
self.add_module("relu", nn.ReLU())
class _Bottleneck(nn.Module):
"""
Bottleneck block of MSRA ResNet.
"""
def __init__(self, in_ch, out_ch, stride, dilation, downsample):
super(_Bottleneck, self).__init__()
mid_ch = out_ch // _BOTTLENECK_EXPANSION
self.reduce = _ConvBnReLU(in_ch, mid_ch, 1, stride, 0, 1, True)
self.conv3x3 = _ConvBnReLU(mid_ch, mid_ch, 3, 1, dilation, dilation, True)
self.increase = _ConvBnReLU(mid_ch, out_ch, 1, 1, 0, 1, False)
self.shortcut = (
_ConvBnReLU(in_ch, out_ch, 1, stride, 0, 1, False)
if downsample
else lambda x: x # identity
)
def forward(self, x):
h = self.reduce(x)
h = self.conv3x3(h)
h = self.increase(h)
h += self.shortcut(x)
return F.relu(h)
class _ResLayer(nn.Sequential):
"""
Residual layer with multi grids
"""
def __init__(self, n_layers, in_ch, out_ch, stride, dilation, multi_grids=None):
super(_ResLayer, self).__init__()
if multi_grids is None:
multi_grids = [1 for _ in range(n_layers)]
else:
assert n_layers == len(multi_grids)
# Downsampling is only in the first block
for i in range(n_layers):
self.add_module(
"block{}".format(i + 1),
_Bottleneck(
in_ch=(in_ch if i == 0 else out_ch),
out_ch=out_ch,
stride=(stride if i == 0 else 1),
dilation=dilation * multi_grids[i],
downsample=(True if i == 0 else False),
),
)
class _Stem(nn.Sequential):
"""
The 1st conv layer.
Note that the max pooling is different from both MSRA and FAIR ResNet.
"""
def __init__(self, out_ch):
super(_Stem, self).__init__()
self.add_module("conv1", _ConvBnReLU(3, out_ch, 7, 2, 3, 1))
self.add_module("pool", nn.MaxPool2d(3, 2, 1, ceil_mode=True))
if __name__ == "__main__":
model = DeepLabV3(
n_classes=21,
n_blocks=[3, 4, 23, 3],
atrous_rates=[6, 12, 18],
multi_grids=[1, 2, 4],
output_stride=8,
)
model.eval()
image = torch.randn(1, 3, 513, 513)
print(model)
print("input:", image.shape)
print("output:", model(image).shape)
和V1,V2的区别在源码里详细注释了。最后DeepLab V3得到输出结果和V1/V2得到输出结果是一致的,训练标签的设置也是一致的。
结论¶
通过源码解析,应该可以对DeepLab V1,V2,V3的原理和特征图维度变化以及 训练有清楚的认识了,所以暂时就讲到这里了。之后有时间再补上DeepLab V3 Plus的论文理解和源码解析语义分割就算暂时完结了。之后准备做目标检测/分类网络的解析,敬请期待吧。
代码链接¶
https://github.com/kazuto1011/deeplab-pytorch/tree/master/libs/models
本文总阅读量次