高分遥感图像解决方案
简单记录一下我们仨参加一个遥感图像比赛的方案。
赛事简介¶
中科星途遥感图像解译大赛今年有六个赛道,涵盖检测、分割、跟踪等任务。其中检测主赛道依托中科院新发布的百万级实例的FAIR1M数据集。具体赛道情况如下:

比赛分为初赛和决赛,分别有各自的测试集。所有模型性能都是线下训练,在线评估打分和排序。初赛截止时需要提交技术报告,排名前列的队伍进入决赛。决赛前6为优胜队伍。
最后成绩是:初赛4/222,决赛6/220,top3%,拿到优胜团队。
数据分析¶
本赛道采用的FAIR1M数据集具有以下特点:
- 百万级实例规模
- 旋转包围框标注
- 细粒度目标识别
- 类别覆盖广泛
- 数据长尾分布
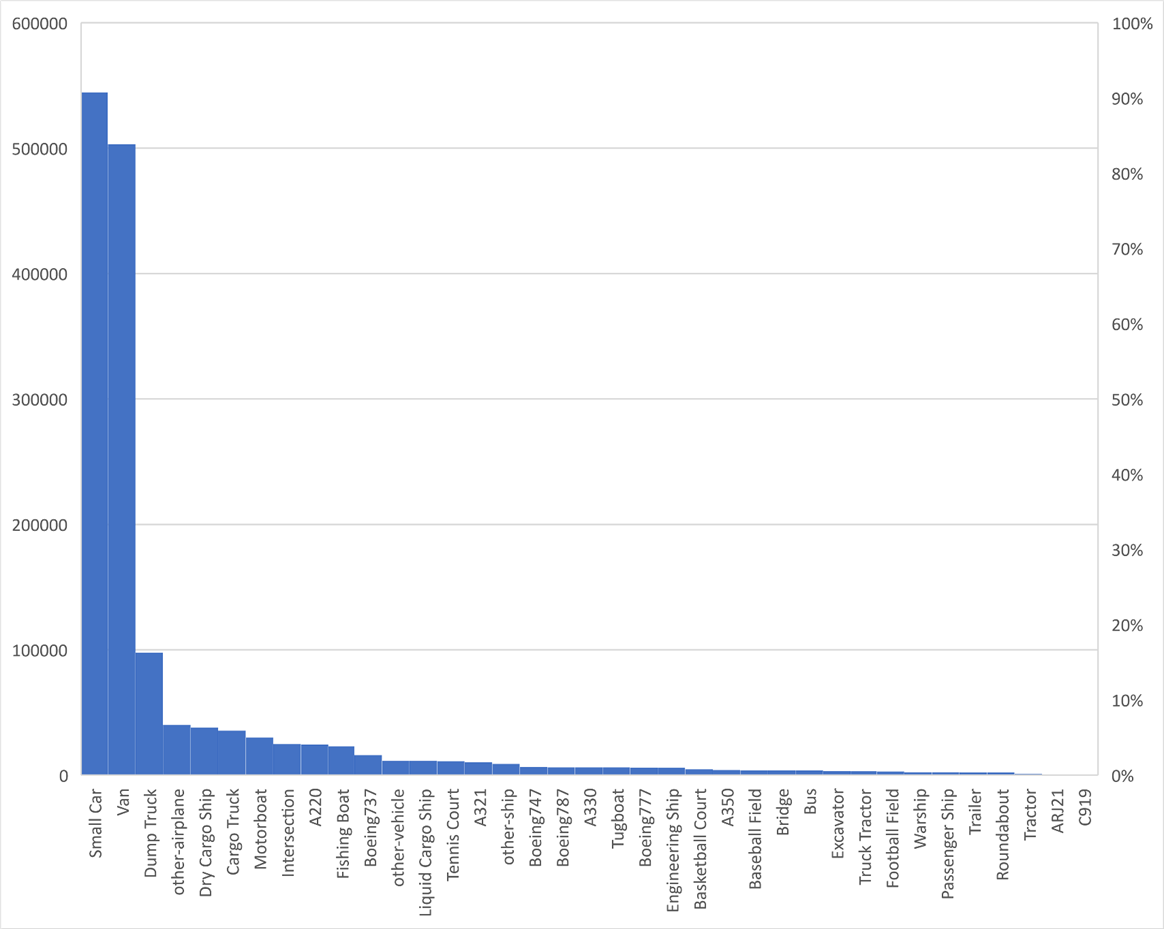
根据官方介绍,该数据集包含37个小类,5个大类,共计15000张图像。覆盖全球50多个机场/港口/城乡等场景。共计37类细粒度类别,包括Boeing737、Boeing747、Boeing777、Boeing787、C919、A220、A321、A330、A350、ARJ21、other-airplane、Passenger Ship、Motorboat、Fishing Boat、Tugboat、Engineering Ship、Liquid Cargo Ship、Dry Cargo Ship、Warship、other-ship、Small Car、Bus、Cargo Truck、Dump Truck、Van、Trailer、Tractor、Excavator、Truck Tractor、other-vehicle、Basketball Court、Tennis Court、Football Field、Baseball Field、Intersection、Roundabout、Bridge。图像尺度1000~10000。统计发现极大尺度的图像比例并不像DOTA那样高,但是裁剪后总的图像数目约40000张。
部分样本示例如图:


统计发现数据分布极端不均衡:
解决方案¶
模型选择¶
我们最后实际用到的单模型包括ORCNN,RoITransformer,ReDet。 代码采用OBBDetection,由于参加较晚时间有限主要基于这个测的。在多尺度训练和测试下,12轮的orcnn有44.8, RoItransformer达到45.6,double head只有41,AOPG只有40。而武大的ReDet能达到47+(缺点是训练太慢,而且不好加swin作backbone)。
性能评估¶
由于高分比赛测试集评估次数有限,但是同时开放的ISPRS benchmark榜单是不限提交的。所以我们都是在ISPRS benchmark上测试,取最好性能的模型测试高分测试集进行提交。据实验观察,benchmark和高分初赛的性能基本保持一致,但是和决赛略有出入。
方案尝试¶
之前参加比赛经验不多,尝试了各种策略,默认均采用orcnn在benchmark上进行试验。策略归类如下:
- 类间NMS:掉点了3%左右。可视化发现细粒度目标的识别冗余框非常多,强行NMS会导致召回降低从而拉低mAP的积分区间。
- 更低的conf:能够提升0.4%。会带来有限的提升,但是会导致检测结果文件非常大,影响后面集成的效率。
- NMS阈值调整:基本没影响,设置大了会掉点,测试的最佳是0.1。
- soft NMS:掉点2-4%。需要细致调参,后未用。
- 更换backbone:由于算力有限,我们大多数模型都用的Res50,没有尝试其他的。就加了个swin,比较香。在orcnn上单尺度就实现48%。但是很诡异的是,使用多尺度后掉点0.4%,没找到原因,导致最终swin也没能带我们进一步上分。
- 多尺度训练和测试:提升3%左右。但是加swin后掉0.4%,试过不同模型都是如此。
- 针对特定类训练:没用。即便参照胡凯旋老哥说的对少量单类目标进行强数据扩充(mixup,mosaic,affine)到十倍,训练出来的单类检测器还是效果很差。
- 过采样:早期在jittor的代码里对比过,效果不明显。后来没用过。
- 更长的训练周期:这个“trick”并不好使,至少对于本次用的三个模型是如此。但是swin没试,算力时间有限。
- 针对密集场景的模型参数修改:图像中密集目标场景还是很多的,默认的512个肯定不够。因此增多了roi数目和检测输出的个数。未做消融实验。
- DOTA预训练:些微提升,但是收敛会快很多。在JDet的s2anet上即使训练一轮也有30+的mAP了。
- 复杂的数据增强:我们采用仿射、HSV抖动、随机缩放、随机翻转将原数据集扩充了一倍。
- 模型集成:必备技巧,无需多言。我们进行了模型内和模型间的集成。模型内能提升大概0.3-0.5左右。
遇到而未解决的问题¶
- 多尺度的swin会掉点。时间和算力不够,后面没再做对比实验。
- 单类的小样本检测器训练不起作用。看到其他组在榜单上也刷单类检测器的分数,但是效果都不好,不知道是不是我们理解有问题。
希望有经验的大佬帮忙解答一下。
代码开源在github:https://github.com/ming71/OBBDet_Swin
本文总阅读量次