ECCV22 Oral VQFR 基于矢量量化字典与双解码器的人脸盲修复网络
ECCV'22 Oral|VQFR|基于矢量量化字典与双解码器的人脸盲修复网络¶
ECCV'22 Oral - VQFR: Blind Face Restoration with Vector-Quantized Dictionary and Parallel Decoder
解读:Owen718 论文链接:https://arxiv.org/pdf/2205.06803.pdf
Background&Motivation¶
尽管生成式面部先验和结构化面部先验最近已经证明了可以生成高质量的人脸盲修复结果,稳定、可靠生成更细粒度的脸部细节仍然是一个具有挑战性的问题。这篇文章受最近基于字典的方法和基于矢量量化的方法启发,提出了一种 基于矢量量化(VQ-based)的人脸盲修复方法VQFR。 VQFR从高质量的图像中抽取特征,构建low-level特征库从而恢复逼真的面部细节。
这篇工作重点关注如下两个问题: * 1.codebook中每个code对应的原图patch大小会极大影响人脸网络修复结果的质量与保真度权衡,而实际落地应用中,质量与保真度需要做到良好的平衡以获得最佳视觉效果。 * 2.原图退化特征需要与来自codebook的高质量特征做融合,融合过程中,如何做到高质量特征不被退化特征所干扰而导致性能降低?
详细介绍引入¶
人脸恢复的目标是恢复低质量(LQ)面孔并纠正未知退化,例如噪声、模糊、下采样引起的退化等。在实际情况下,此任务变得更具挑战性,因为存在更复杂的退化、多样的面部姿势和表情。以前的作品通常利用特定于人脸的先验,包括几何先验、生成先验和参考先验。具体来说,几何先验通常包括面部标志、面部解析图和面部组件热图。它们可以为恢复准确的面部形状提供全局指导,但不能帮助生成逼真的细节。此外,几何先验是从退化图像中估计出来的,因此对于具有严重退化的输入变得不准确。这些特性促使研究人员寻找更好的先验。最近的人脸修复工作开始研究生成先验(GAN-Prior),并取了优异的性能。这些方法通常利用预先训练的人脸生成对抗网络(例如StyleGAN)的强大生成能力来生成逼真的纹理。这些方法通常将退化的图像投影回GAN潜在空间,然后使用预先训练的生成器解码高质量(HQ)人脸结果。尽管基于GAN先验的方法最初从整体上讲具有良好的恢复质量,但仍然无法生成细粒度的面部细节,特别是精细的头发和精致的面部组件。这是因为训练有素的GAN模型,其潜在空间仍然是不够完善的。 基于参考的方法(Reference-based methods)—探索了高质量的指导面孔或面部组件字典来解决面部恢复问题。DFDNet是该类别中的代表方法,它不需要访问相同身份的面孔,就可以产生高质量的结果。它明确建立高质量的“纹理库”,用于几个面部组件,然后用字典中最近的高质量面部组件替换退化的面部组件。这种离散的替换操作可以直接弥合低质量面部部件与高质量部件之间的差距,因此具有提供良好面部细节的潜力。然而,DFDNet中的面部组件字典仍然有两个缺点。1)它使用预先训练的VGGFace网络进行离线生成,该网络是为识别任务优化的,明显并不适合恢复任务。2)它只关注几个面部组件(即眼睛、鼻子和嘴巴),但不包括其他重要区域,例如头发和皮肤。
面部组件字典的局限性促使VQFR探索矢量量化(VQ)码本,这是一个为所有面部区域构建的字典。VQFR提出的人脸恢复方法VQFR既利用字典方法又利用GAN训练,但不需要任何几何或GAN先验。与面部组件字典相比,VQ码本可以提供更全面的低层特征库,而不局限于有限的面部组件。它也是通过面部重建任务以端到端的方式来学习的。此外,矢量量化的机制使其在不同的退化情况下更加稳健。尽管简单地应用VQ码本可以取得不错的效果,但要实现良好的结果也不容易。后续进一步介绍了两个特殊的网络设计以应对前文提到的两个problems,这将帮助VQFR在细节生成和身份保留方面都超越先前的方法。

具体来说,为了生成逼真的细节,作者发现选择适当的压缩补丁大小至关重要,它表示codebook的一个code“由多大的补丁表示”。如图2所示,较大的patch可以带来更好的视觉质量,但是真实度却会下降。经过全面的调查,我们建议输入图像大小512x512时,32大小的patch size最合适。然而,这种选择只是在质量和真实度之间进行权衡。表情和身份也可能会因适当的压缩补丁大小而有很大的变化。一个直接的解决方案是将输入特征与不同的解码器层融合,这与GFP-GAN中的操作类似。尽管输入特征可以带来更多的真实度信息,但它们也会干扰从VQ代码本生成的逼真细节特征。这个问题引出了作者的第二个网络设计: 并行解码器。具体而言,并行解码器结构包括纹理解码器和主解码器。VQFR的纹理解码器仅接收来自VQ代码本的潜在表示的信息,而主解码器将纹理解码器中的特征做变换以匹配退化输入的需保留的特征。为了避免高质量细节的损失并更好地匹配退化的面部,VQFR在主解码器中进一步采用了具有可变卷积的纹理变换模块。通过VQ codebook作为面部字典和并行解码器设计,VQFR可以实现更高质量的面部细节修复,同时尽可能得保留面部恢复的真实度。
VQFR方法概述¶
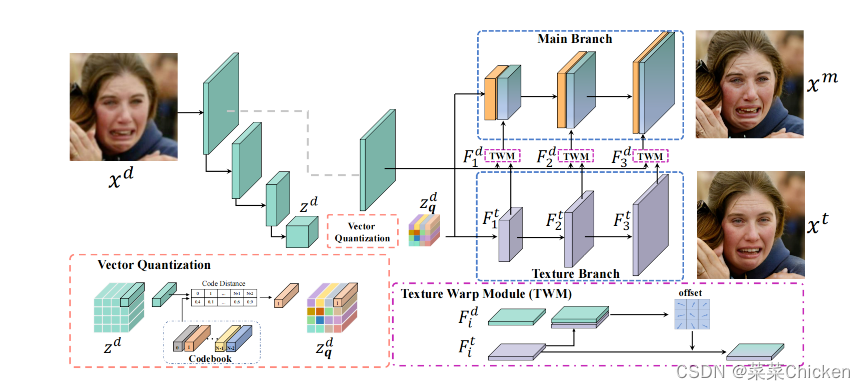
Vector-Quantized Codebook最早在VQVAE中被引入,旨在学习离散的先验来编码图像。VQFR中的codebook部分与VQGAN中的基本一致。VQGAN 主要是采用了感知损失和对抗性损失以鼓励具有更好感知质量的重建。 VQFR方法主要基于以下两个观察来提高修复性能: 1. 通过采用合适的压缩补丁大小,可以用仅由高品质人脸训练的VQ码本来去除LQ人脸的退化。 2. 在训练恢复任务时,在改进的细节纹理和保真度变化之间需要保持一个平衡。
针对观察现象一,VQFR采用合适的f大小来控制codebook效果,f取32最佳。针对观察现象二,VQFR提出利用双分支架构的decoder来逐渐将高质量纹理特征补充进待修复特征中,texture warp module利用可变形卷积很好的实现了这一目的。反观之前的相似工作,之前工作中单一分支decoder架构很难较好的融合低质特征和高质量特征,这导致了恢复性能不佳。
实验¶
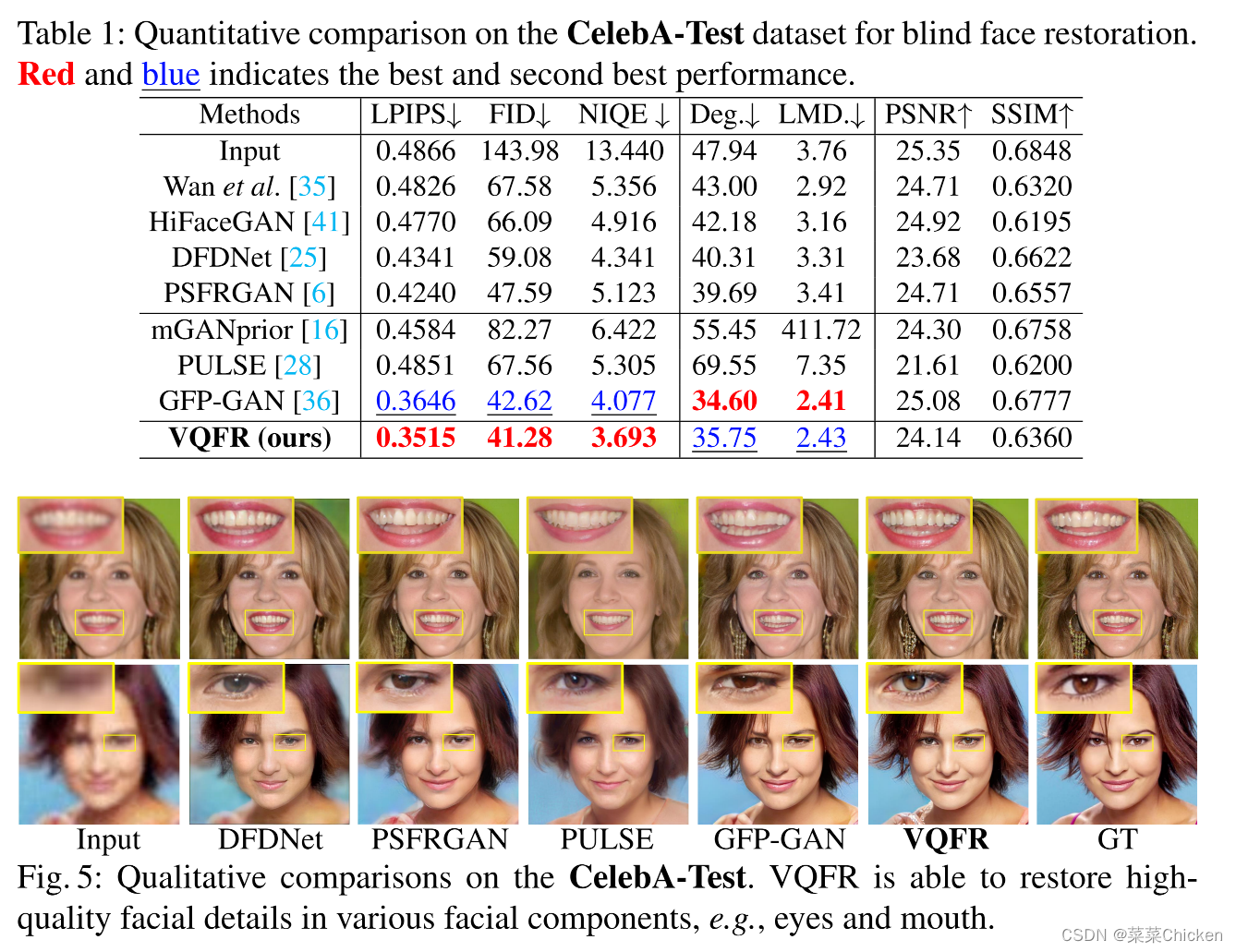
VQFR在CelebA-Test数据集和LFW数据集上均取得了领先的性能结果,值得关注的是其PSNR/SSIM指标并不十分出色,但是FID、NIQE、LMD指标非常不错,视觉效果也体现了该方法的优越性。
真实度与保真度的平衡¶
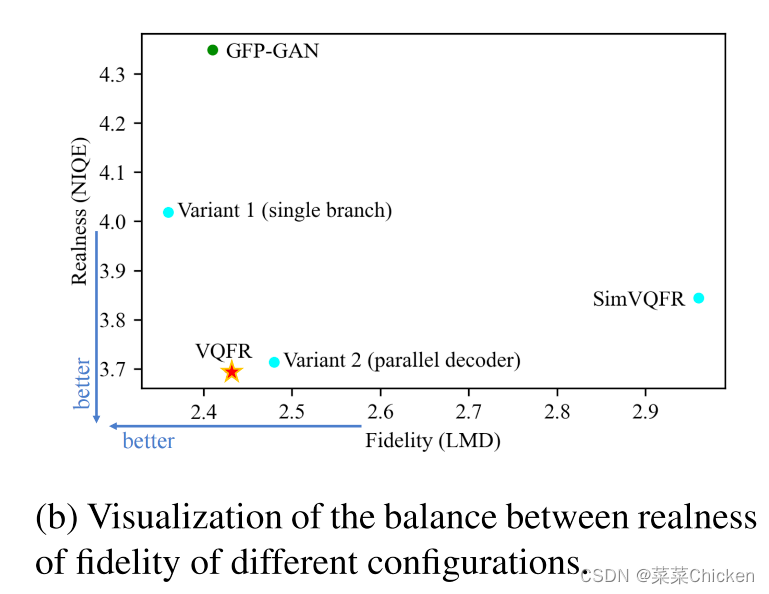 可以看出VQFR取得了非常不错的真实度与保真度的平衡,实验效果很出色。
可以看出VQFR取得了非常不错的真实度与保真度的平衡,实验效果很出色。
总结¶
本文提出的VQFR是一种性能非常不错的人脸盲修复方法,文章思路非常清晰,明确点出核心motivation和为解决的相关问题,最后的实验结果也非常精彩,很好的证明了方法的基本理论与出发点,更多细节建议大家参考原文。
本文总阅读量次