斯坦福大学最新扩散模型工作DID用于低光照文字识别的扩散模型
斯坦福大学最新扩散模型工作|DID|用于低光照文字识别的扩散模型¶
解读:Owen718
Paper title:Diffusion in the Dark:A Diffusion Model for Low-Light Text Recognition Arxiv Link:https://arxiv.org/pdf/2303.04291
主要解决的问题¶
DiD的核心动机是解决低光图像的退化修复、图像重建问题,由于下游文字识别任务所需的高频细节的丢失,该问题变得具有挑战性。本论文提出DiD作为一种低光图像重建的扩散模型,它可以提供与现有最先进方法相比具有质量更优良的重建效果,并且在极度嘈杂、黑暗的情况下仍可以保留高频细节。DiD的动机是在不损失细节的情况下,使准确的下游任务如文本识别在低光条件下得以实现。
简介¶
自动化任务已经在日常生活中变得极为流行和普遍。从高速公路上读取车牌到在自动结账队列中识别杂货,由人工智能驱动的自动化任务极大地依赖于视觉信号,如RGB图像。真实世界的成像受到噪声、光学模糊和其他畸变的影响,这使得使用图像进行下游应用变得具有挑战性。值得注意的是,处理这些图像的流程通常是由人类专家决定的,旨在满足感知和美学方面的需求。虽然这些图像仍可能被人类观察,但这些处理流程却可能无法保留高频细节。这些高频细节对于观赏体验可能没有必要,但对于下游应用——如物体分割和分类等——来说却是至关重要的。在低光环境下,图片中的光子计数很低,使得信噪比很小,这使得低光图像增强变得困难。深度学习,特别是卷积神经网络(CNNs),在解决低光图像增强方面表现出很好的效果。此外,生成模型也能够成功地将低光图像转换为高光照分布的图像。这些方法通常能够适度地修复图像美学效果,但所需要的方法不仅要修复美感,还需要重建适用于高级任务(如文本识别)所需的高频细节。因此作者提出DID (Diffusion in Dark), 主要的核心贡献包括:
-
引入一种新颖的低光重建方法,使用条件扩散模型,可以仅在补丁上进行训练,并重建不同分辨率的图像,从而有效减少训练时间和计算成本。
-
引入了用于在极度黑暗或右偏分布数据上训练扩散模型的关键归一化技术。右偏分布数据,(Right-tailed data)是指数据分布的尾部(右边)存在极端值或离群值的情况。在这种数据分布中,较小的值出现的频率较高,而较大的值出现的频率较低。这可能会导致某些统计学方法的精度下降,因为它们假设数据遵循正态或对称分布,并且不是为处理高度扭曲或不对称的分布而设计的。对于right-tailed data,常见的应对方法是使用归一化技术来调整它的分布,使其更符合正态或对称分布,以便更好地应用于统计学或机器学习方法中。
-
证明DiD在真实图像的低光文本识别中优于现有最先进的低光方法,而无需任何任务特定的优化。
-
提供了DiD与其他低光增强方法的定性和定量比较,显示即使在极度嘈杂、黑暗的情况下,DiD始终表现良好。
总的来说,DiD的核心贡献是其在保留下游任务必需的细节的同时准确重建低光图像的能力,其训练和计算的效率以及与最先进方法相比的竞争性能。
为什么是扩散模型?¶
DID选择了扩散模型进行低光图像重建,因为它们是一种新兴的概率生成模型类型,可生成多样化、高分辨率的图像。不同形式的扩散模型包括DDPM、基于评分的生成建模和随机微分方程。然而,它们都遵循相似的过程,其中包括向清洁样本逐渐添加噪声的正向过程,以及将退化过程反转以从噪声中恢复合理样本的反向过程。
扩散模型在许多基于图像的任务中都取得了成功,如无条件图像生成、修补、上色、图像分割和医学成像等领域。该论文指出,扩散模型特别适用于低光图像重建,因为它们保留了细致的细节,即使在极为嘈杂和黑暗的情况下也如此。DID 旨在保持下游任务所需的高频细节,同时准确重建低光图像。
方法 Method¶
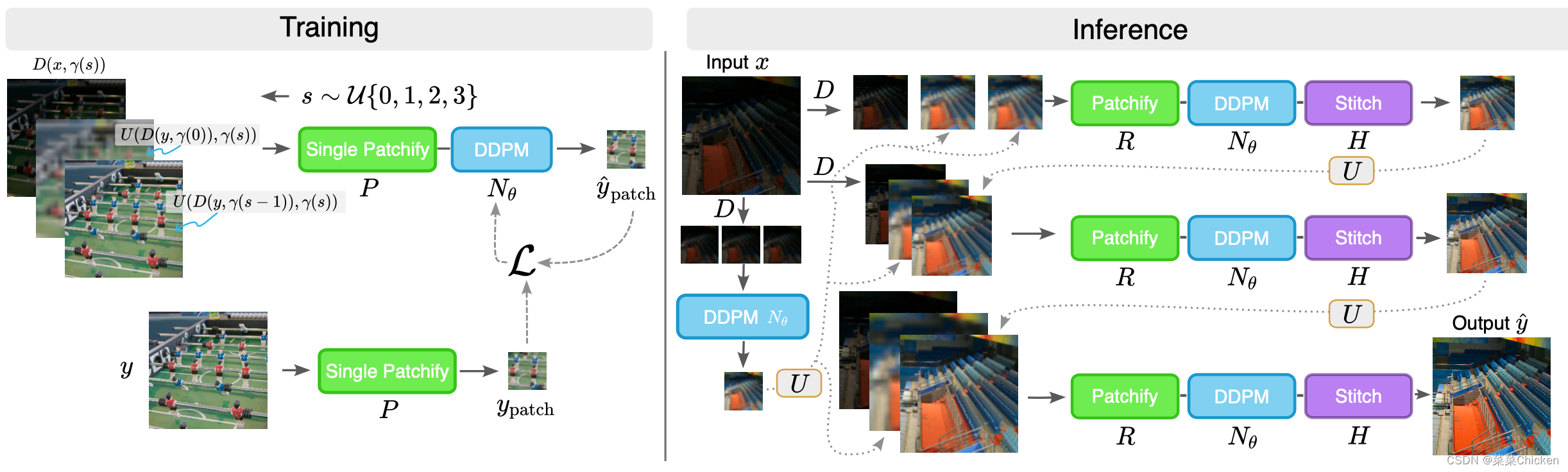
训练一个高分辨率的扩散模型需要大量计算资源,并且需要在几天内通过多个GPU进行训练。此前的方法常通过采用级联策略来解决这个问题,即在多个训练阶段中训练单个模型或训练多个模型,每个模型在不同的分辨率下受训练。DID采用了一种新的训练方法,即同时使用多个分辨率来训练单个模型,并采用多尺度图像块策略(multi-scale patch-based approach)。这种训练方案可以大大减少训练时间和计算需求,DID模型只需要一个GPU并且可以在3天内训练完成。 那为什么不直接把一张256\times256的图分解为多个不重叠的32\times32大小的patch,然后用于训练,从而加快训练速度呢? 这是因为将低光图像分解为32x32的小块,对每个小块运行DDPM,然后将小块拼接在一起,会导致不同小块之间在曝光和白平衡方面存在不一致性。因此,需要一个方法来约束所有小块具有相同的外观。为此,DID使用多个尺度来进行训练,使用第一个尺度s=0的恢复曝光作为条件的起点,同时利用前几个尺度恢复的曝光信息来进一步细化高频细节。
训练阶段 Training Stage¶
DID作者设置了四种不同的scale:{32,64,128,256},每次随机从中选择一个scale作为crop操作的目标size,来对输入低光照退化图cropping。DID采用了三种不同的condition inputs: * c_{x1}:低光退化条件输入表征低光退化情况。这个输入提供了重建的基础,对于每个尺度,DID会下采样到相应的分辨率γ(s)\times γ(s)上。 * c_{y1}:光照较充足的条件输入,前一尺度的预测结果光照充足但分辨率低。利用c_{y1}提供的曝光水平作为条件,其比c_x更接近于真实值,但同时又有光照充足的高频细节。 * c_{y2}:来自第一个尺度阶段的光照充足但低分辨率的预测结果。这张图片提供了全局统一的曝光水平来进行条件限制,进一步约束恢复的曝光水平。
当处于第一个尺度s_{0}时,没有之前阶段的信息c_{y1}或c_{y2}作为额外的conditional输入,因此用成对的训练数据x_{i},y_{i}来组建conditioning input (x_{patch_{i}}, y_{patch_{i}} ):
其中 ,D(x,k)表示将一个输入x,下采样到k\times k的分辨率。值得注意的是,\gamma(0) \times \gamma(0) 或 32\times 32是DID网络固定的一个训练patch大小。用U(x,k)表示一个上采样操作将一个输入x,上采样到k\times k的分辨率,用\eta \in \mathcal{R}^{32 \times 32 \times 3}表示采样得到的高斯噪声,在其他尺度上, conditional inputs用下式来定义:
\begin{aligned} c_x & =D\left(x_i, \gamma(s)\right), \\ c_{y_1} & =U\left(D\left(y_i, \gamma(s-1)\right), \gamma(s)\right)+\eta, \\ c_{y_2} & =U\left(D\left(y_0, \gamma(0)\right), \gamma(s)\right)+\eta, \\ \left(x_{\text {patch }_i}, y_{\text {patch }_i}\right) & =\left(P\left(\left[c_x, c_{y_1}, c_{y_2}\right]_i\right), P\left(y_i\right)\right) .\end{aligned}
上式中添加η是为了更好地类比推理阶段中后面尺度上的噪声预测。然后,在上述Contional inputs上应用前向扩散过程,按照论文《Elucidating the design space of diffusion-based generative models》中的流程向x_{patch_{i}}添加噪声。最终,将上述退化图像和噪声输入去噪网络来获得高质量的修复图像,一次修复forward过程需要重复N = 18次。在训练过程中,DID仅对32×32的补丁进行训练,但随机选择每个图像的比例或分辨率。 这可以训练出一个性能优越的图像修复模型,并且能够在多个分辨率下进行重建。DID的损失函数则采用了LPIPS loss和L2损失的简单线性结合。
推理阶段 Inference Stage¶
DID采用级联方法来得到最终图像。DID从已知的低光测量值x_i开始,组成条件输入,对其应用反向扩散过程,并将扩散预测用作下一尺度的输入,一直持续到组成最终256×256分辨率的光照充足图像。作者观察到,即使预测是基于相同的条件下曝光实例化,但不同补丁之间的曝光水平和白平衡情况仍热不一致。为了实现完全的尺度一致性,我们需要一个额外的步骤:迭代潜在变量细化(Iterative Latent Variable Refinement,ILVR)。在每个反向去噪的步骤中,DID用来自前一个尺度的低分辨率图像的低频内容替换预测的低频细节。ILVR的引入不需要任何额外的训练,因为它们仅在推理过程中使用。DID作者发现在反向过程的每个步骤中都使用ILVR会导致模糊,而使用18个步骤中的6个扩散去噪步骤使用ILVR可以获得最优性能。
Data Normalization for low-light data¶
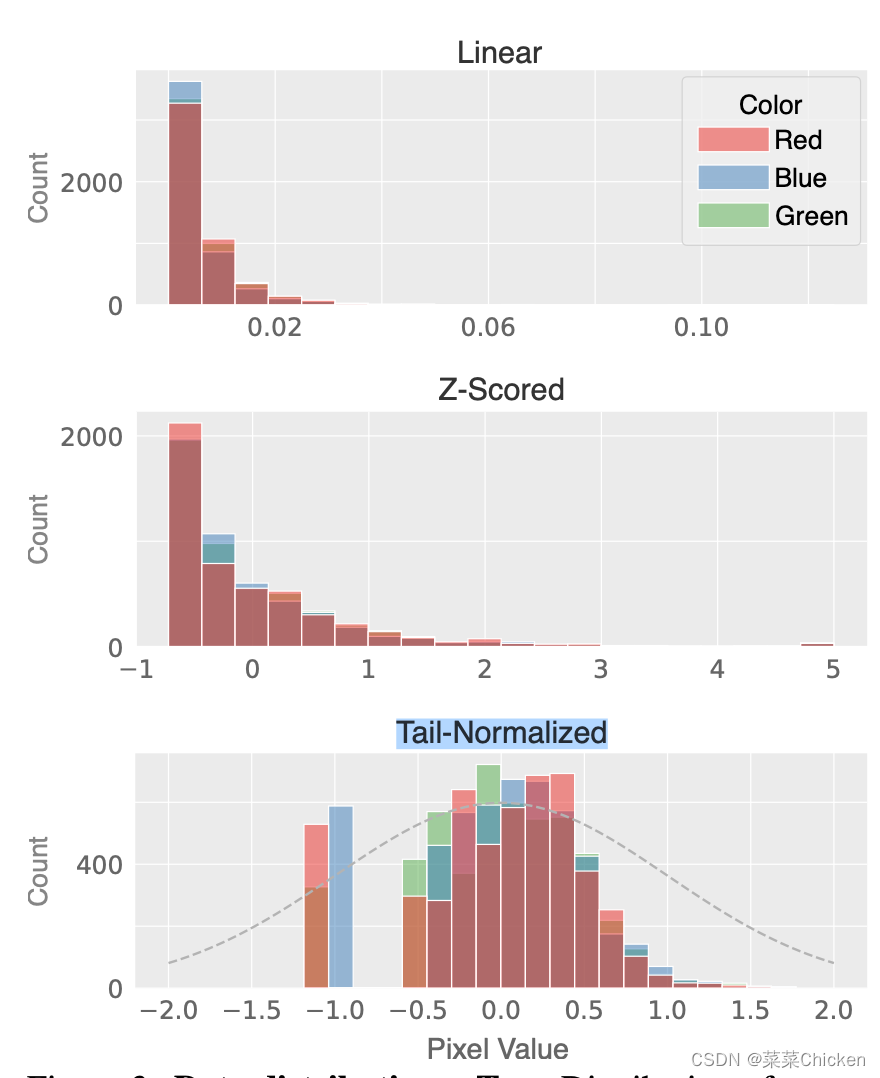
Z-scoring是一种将数据标准化为标准正态分布的方法,也被称为标准得分或标准化。它通过将每个数据点减去数据集的均值并除以标准差来转换数据。通过Z-scoring,将数据规范化为均值为0,标准差为1的分布,使不同数据集之间的比较更为可行和客观,也能够减弱数据中噪声或异常值(outlier)的影响。鉴于低光数据的右偏特性(见下图),直接应用常见的Norm技术是不适合的。扩散模型需要在训练时选择一个noise schedule),尤其是选择σ_{min}和σ_{max}。σ_{min}被选择为最低噪声级别时,与图像基本不可区分,σ_{max}被选择为最高噪声级别时,则与白高斯噪声不可区分。由于我们使用的σ值是为图像设计的,因此我们需要将图像的范围大致相同以满足这些条件,从而对数据进行规范化处理,使其分布在[-1,1]之间。 DID作者发现,对于右偏的低光照数据,将数据取四次方根、进行Z-score标准化,然后除以2可以得到一个合适的分布,作者将这种标准化方式称为Tail-Normalized。如DID原文在消融研究中观察到的,这种规范化非常关键。
实验¶
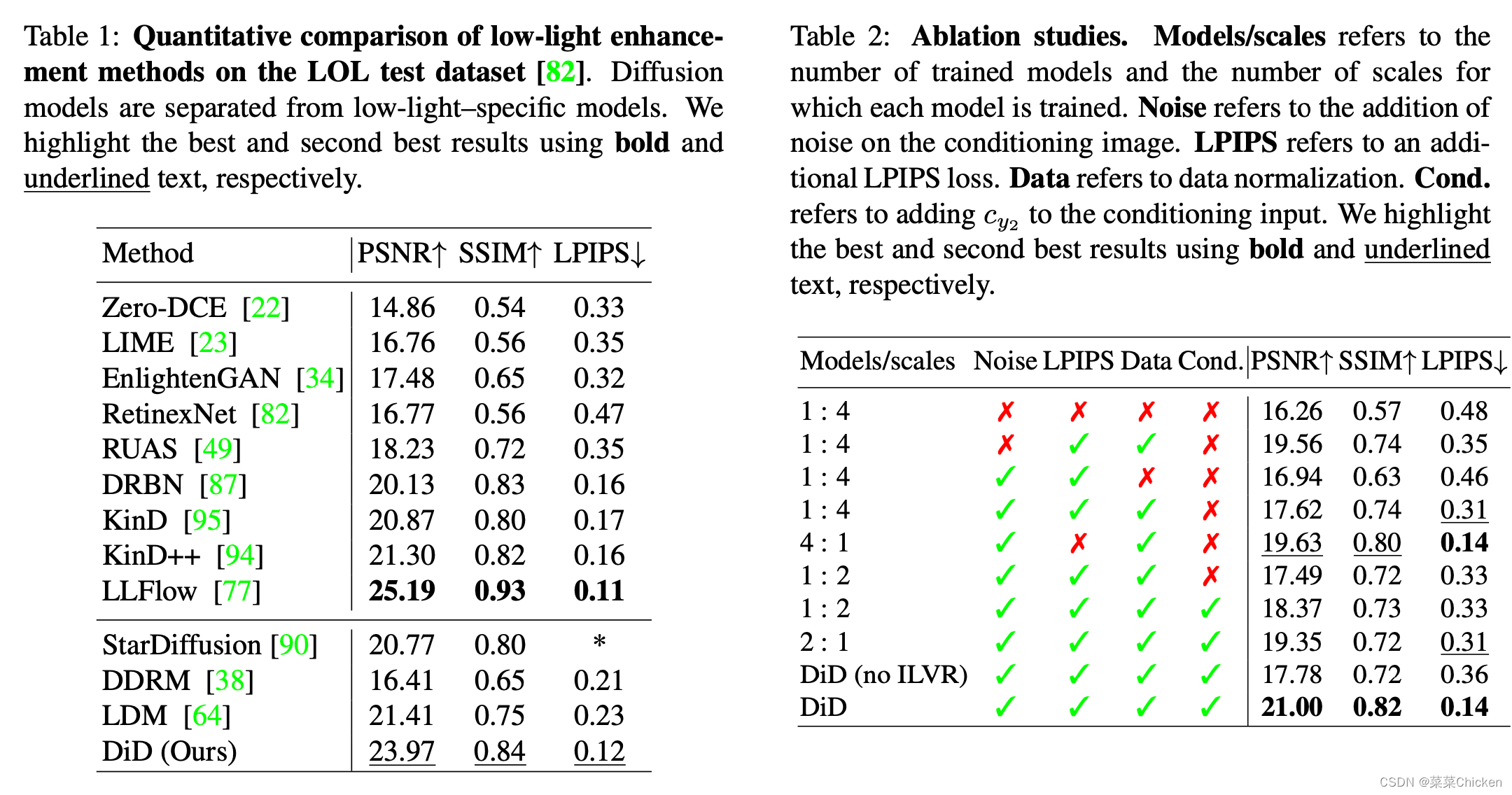 作者在NVIDIA Quadro RTX 8000上使用PyTorch实现了我们的框架。作者使用ADAM优化器,学习率为8 \times 10^{-4},我们训练批量大小为160,共进行3000次迭代。考虑到使用的是小型数据集,作者发现这个迭代次数足以使模型收敛。通过添加随机高斯模糊或锐化,并缩放亮度和饱和度来增强数据。作者和扩散模型StarDiffusion、DDRM、LDM做了比较,可以看出相比于之前的扩散方法,DID取得了非常不错的性能优势。消融实验可以看出,作者提出的训练策略非常有效,Tail-Normalized Norm的性能提高效果也很不错。
作者在NVIDIA Quadro RTX 8000上使用PyTorch实现了我们的框架。作者使用ADAM优化器,学习率为8 \times 10^{-4},我们训练批量大小为160,共进行3000次迭代。考虑到使用的是小型数据集,作者发现这个迭代次数足以使模型收敛。通过添加随机高斯模糊或锐化,并缩放亮度和饱和度来增强数据。作者和扩散模型StarDiffusion、DDRM、LDM做了比较,可以看出相比于之前的扩散方法,DID取得了非常不错的性能优势。消融实验可以看出,作者提出的训练策略非常有效,Tail-Normalized Norm的性能提高效果也很不错。
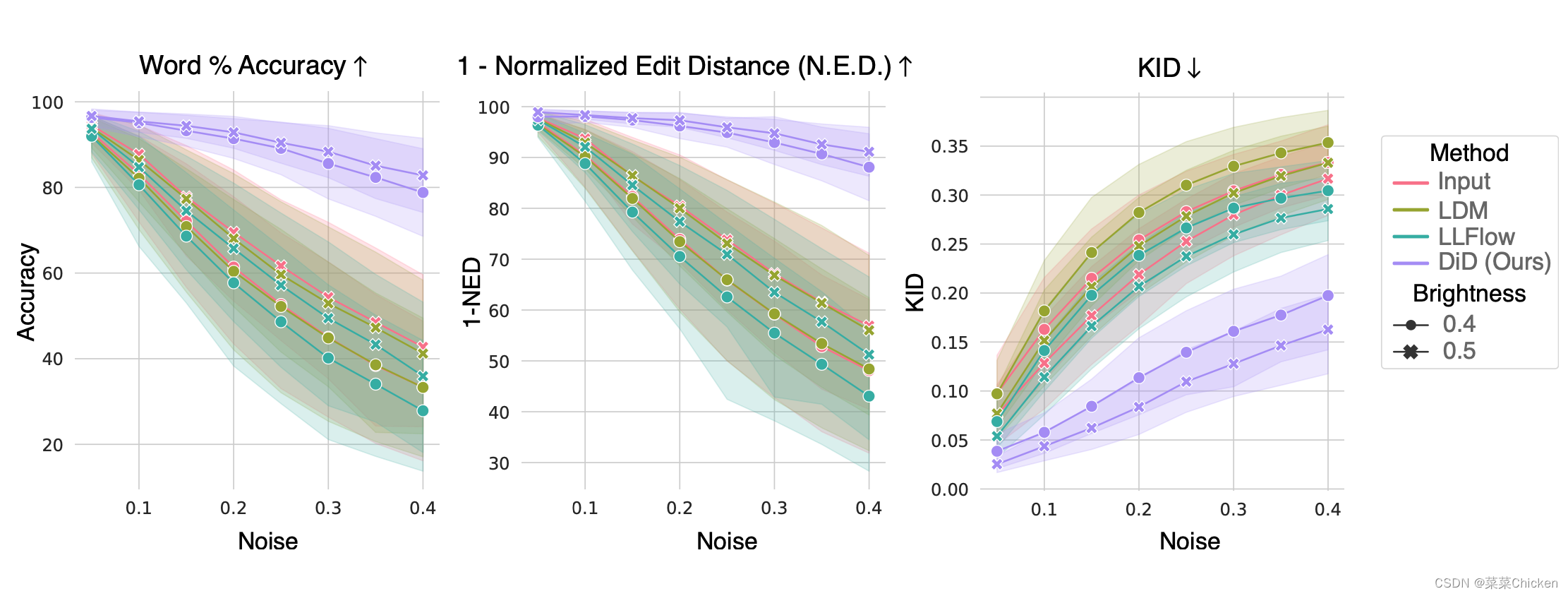
对下游文字识别任务的增强效果上,DID的表现非常不错,如上图所示,在word准确度和KID上,DID的表现远比LLFlow和LDM等sota方法好得多。
结论 Conclusion¶
DiD最具创新性的贡献是引入了一种新的低光条件扩散模型重建方法。该方法可以训练多尺度的图像重建,并只需要使用32\times32图像块进行训练,从而降低了计算和训练时间。这个方法的创新之处在于在保留下游任务所需细节的同时实现了高效的训练和计算。此外,该论文中还介绍了在处理极暗或右偏数据时,采用归一化技巧进行扩散模型训练,这进一步提高了DiD在低光图像重建方面的性能。
本文总阅读量次