CVPR 2023 中的领域适应: 通过自蒸馏正则化实现内存高效的 CoTTA¶
目录¶
- 前言
- 内存比较
- EcoTTA 实现
- Memory-efficient Architecture
-
Self-distilled Regularization
-
实验
- 分类实验
-
分割实验
-
总结
-
参考
前言¶
我们介绍了 CoTTA 方法,这次介绍的是基于它的优化工作:EcoTTA,被接受在 CVPR 2023 上。
推荐阅读顺序是:
上一篇文章我们提到 CoTTA 的输入是随时间轴变化的数据(比如自动驾驶中不断切换的天气条件),且是测试伴随训练任务。所以,CoTTA 通常在内存有限的边缘设备上进行,因此减少内存消耗至关重要。先前的 TTA 研究忽略了减少内存消耗的重要性。此外,上一篇文章也提到了长期适应通常会导致灾难性的遗忘和错误积累,从而阻碍在现实世界部署中应用 TTA。
EcoTTA 包括解决这些问题的两个组成部分。第一个组件是轻量级元网络,它可以使冻结的原始网络适应目标域。这种架构通过减少反向传播所需的中间激活量来最大限度地减少内存消耗。第二个组成部分是自蒸馏正则化,它控制元网络的输出,使其与冻结的原始网络的输出不显著偏离。这种正则化可以保留来自源域的知识,而无需额外的内存。这种正则化可防止错误累积和灾难性遗忘,即使在长期的测试时适应中也能保持稳定的性能。
内存比较¶
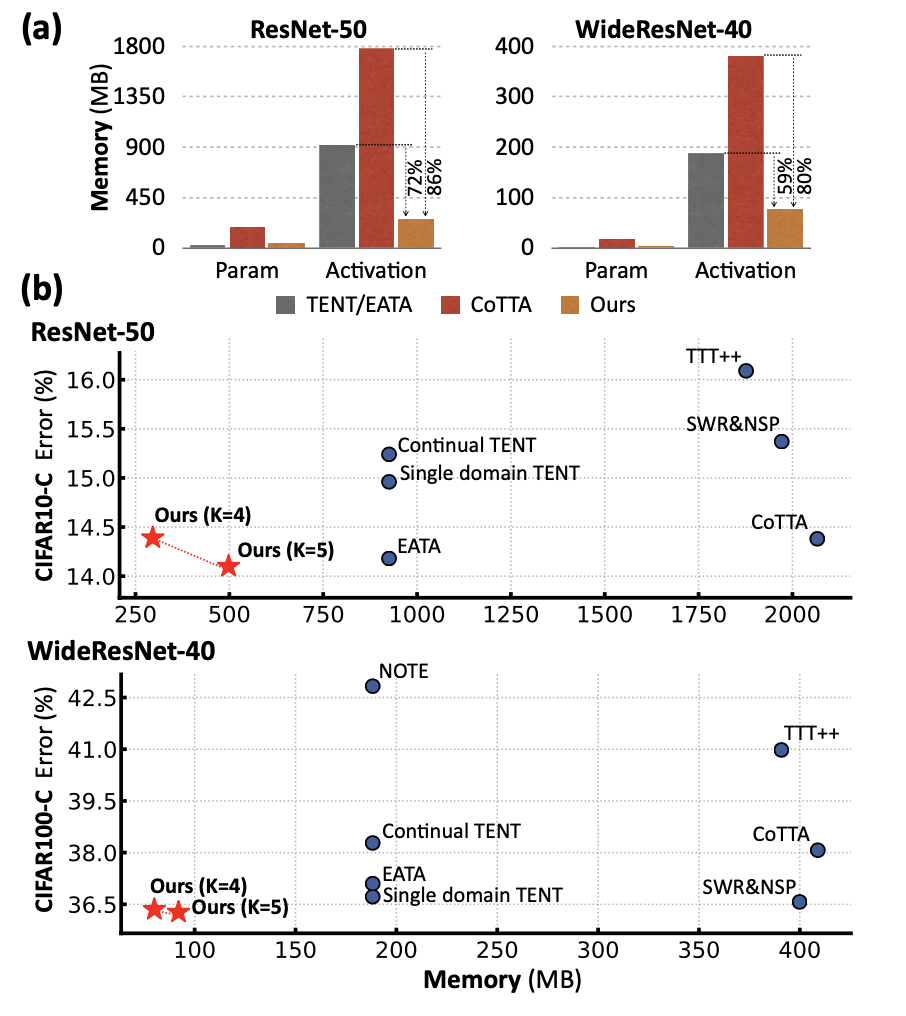
首先,我们先看一下 EcoTTA 和其他方法的内存比较。下图(a)表示在训练过程中,与参数相比,激活的大小是主要的内存瓶颈。下图(b)中,x 轴和 y 轴分别表示所有平均误差和总内存消耗,包括参数和激活。对 CIFAR-C 数据集进行连续的在线适应,EcoTTA在消耗最少的内存的同时取得了最佳结果。这里我们发现,作者全文的实验只对比了类 ResNet 架构,而 CoTTA 中性能最高的架构是 SegFormer。
EcoTTA 实现¶
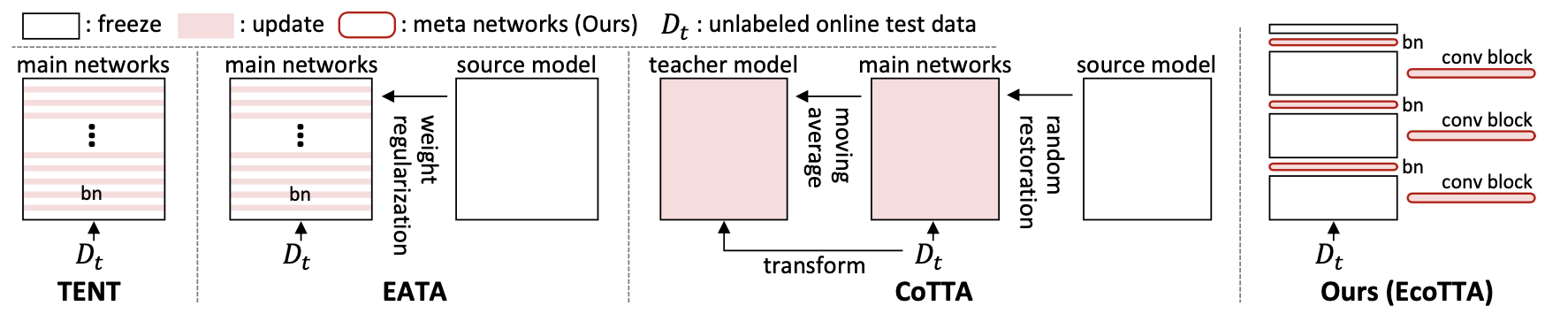
关于相关工作的部分,我们已经在 CoTTA 中介绍过了。将 EcoTTA 的策略和其他方法(都是 TTA 的)对比如下图,包括 TENT、EATA 和 CoTTA。TENT 和 EATA 更新了多个 BN 层,这需要存储大量激活以进行梯度计算。这可能会导致内存问题,尤其是在内存有限的边缘设备上。CoTTA 使用额外的持续适应策略来训练整个网络,这需要大量的内存和时间。相比之下,EcoTTA 要求通过仅更新几层来最大限度地减少激活量。这减少了内存消耗,使其适用于内存有限的边缘设备。
下面我们关注 EcoTTA 两个部分的实现。
Memory-efficient Architecture¶
假设模型中的第 i 个线性层由权重 W 和偏置 b 组成,该层的输入特征和输出特征分别为 fi 和 fi+1。给定 fi+1 = fiW + b 的前向传播,从第 i+1 层到第 i 层的反向传播和权重梯度分别制定为: $$ \frac{\partial \mathcal{L}}{\partial f_i}=\frac{\partial \mathcal{L}}{\partial f_{i+1}} \mathcal{W}^T, \quad \frac{\partial \mathcal{L}}{\partial \mathcal{W}}=f_i^T \frac{\partial \mathcal{L}}{\partial f_{i+1}} $$ 意味着需要更新权重 W 的可学习层必须存储中间激活 fi 以计算权重梯度。相反,冻结层的反向传播可以在不保存激活的情况下完成,只需要其权重 W。
相对于可学习参数,激活占据了训练模型所需内存的大部分。基于这个事实,CoTTA 需要大量的内存(因为要更新整个 model)。另外,仅仅更新 BN 层中的参数(例如 TENT 和 EATA)并不是一种足够有效的方法,因为它们仍然保存了多个 BN 层的大量中间激活。EcoTTA 提出了一种简单而有效的方法,通过丢弃这些激活来显著减少大量的内存占用。
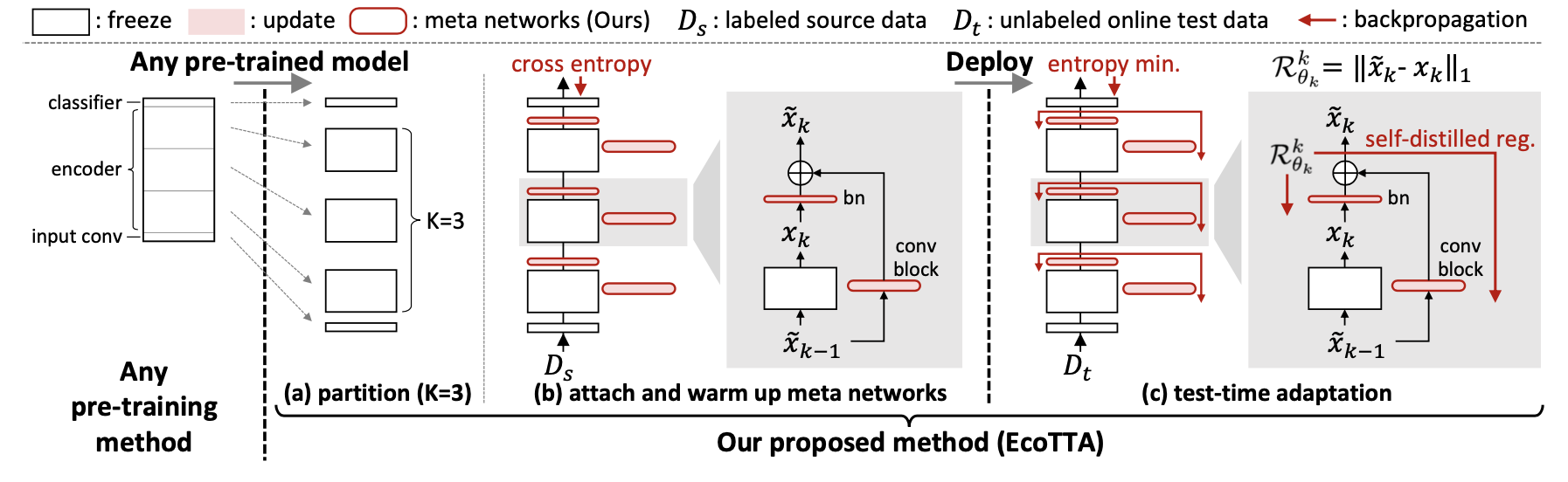
在部署之前,我们首先使用任何预训练方法获取一个预训练模型。然后,我们将预训练模型的编码器分成 K 个部分,如上图(a)所示。一个元网络组由一个批归一化层和一个卷积块(ConvBN-Relu)组成,将轻量级元网络附加到原始网络的每个部分上,如上图(b)所示。我们在源数据集上对元网络进行预训练,同时冻结原始网络。这个预热过程完成后,我们可以进行模型部署。强调一点,在测试时不需要源数据集 Ds,所以本质上还是 TTA 的范式。更详细的元网络组成如下:

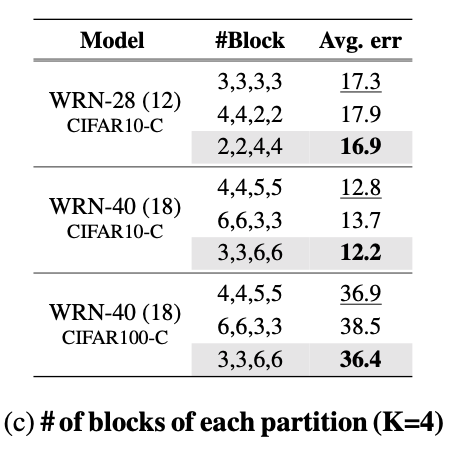
此外,我们需要预训练模型的几个分区。先前解决域偏移的 TTA 研究表明,相对于更新深层,更新浅层对于改善适应性能更为关键。受到这样的发现启发,假设预训练模型的编码器被划分为模型分区因子 K(例如 4 或 5),我们将编码器的浅层部分(即 Dense)相对于深层部分进行更多的划分,表现如下表所示。
在部署期间,我们只对目标域适应元网络,而冻结原始网络。适应过程中,我们使用熵最小化方法对熵小于预定义阈值的样本进行适应,计算方法如下面的公式所示,并使用自提出的正则化损失来防止灾难性遗忘和错误累积。
$$ \begin{aligned} & \mathcal{L}^{e n t}=\mathbb{I}{\left{H(\hat{y})<H_0\right}} \cdot H(\hat{y}) \ & \mathcal{L}\theta^{\text {total }}=\mathcal{L}\theta^{e n t}+\lambda \sum_k^K \mathcal{R}{\theta_k}^k \end{aligned} $$ 在第二个公式中,左右两项分别表示适应损失(主要任务是适应目标域)和正则化损失。整体而言,EcoTTA 在内存使用方面比之前的工作更加高效,平均使用的内存比 CoTTA 和 TENT/EATA 少 82% 和 60%。
Self-distilled Regularization¶
无标签测试数据集 Dt 上的无监督损失往往会向模型提供错误的信号(即噪声,\hat{y} \neq y_t,其中 y_t 是测试样本的真实标签)。使用无监督损失进行长期适应会导致过拟合(由于误差累积)和灾难性遗忘的问题。为了解决这些关键问题,EcoTTA 提出了一种自蒸馏正则化方法。如上图(c)所示,对每个元网络的第 k 组输出 \tilde{x}_k 进行正则化,使其与冻结的原始网络的第 k 部分输出 x_k 保持接近。正则化损失使用平均绝对误差(L1 Loss)进行计算,表达式如下: $$ \mathcal{R}_{\theta_k}^k=\left|\tilde{x}_k-x_k\right|_1 $$
由于原始网络不会被更新,从中提取的输出 x_k, k∼K 被认为包含了从源域学到的知识。利用这个事实,通过将元网络的输出 \tilde{x}_k 与原始网络的输出进行知识蒸馏的方式进行正则化。也就是说,防止适应模型与原始模型显著偏离,可以避免灾难性遗忘。通过保留源域知识和利用原始模型的类别区分度,避免误差累积。值得注意的是,与先前的方法不同,自蒸馏正则化方法无需保存额外的原始网络,它只需要很少的计算量和内存开销。
实验¶
分类实验¶
下表是在 CIFAR-C 数据集上的错误率比较结果。包括连续 TTA 上处理了 15 种不同的损坏样本后的平均错误率,并考虑了模型参数和激活大小所需的内存。其中,还使用了 AugMix 数据处理方法来增强模型的鲁棒性。Source 表示未经过适应的预训练模型。single domain的 TENT 是在适应到新的目标域时重置模型(因为这篇论文和 CoTTA 都是在 domian flow 的 setting 下考虑的,而不是 single domain),因此需要使用域标签来指定目标域。
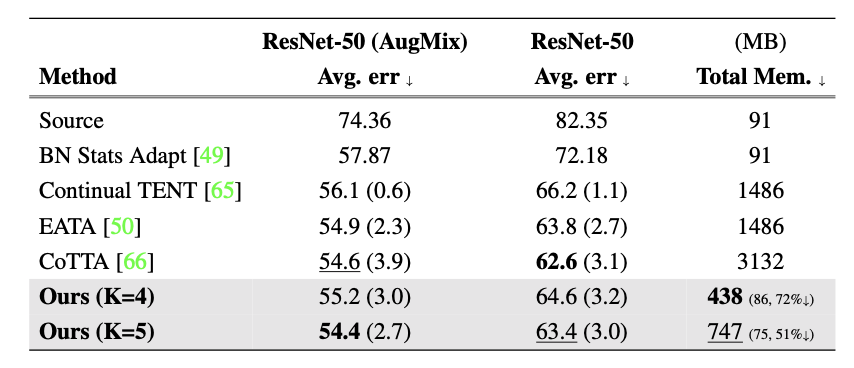
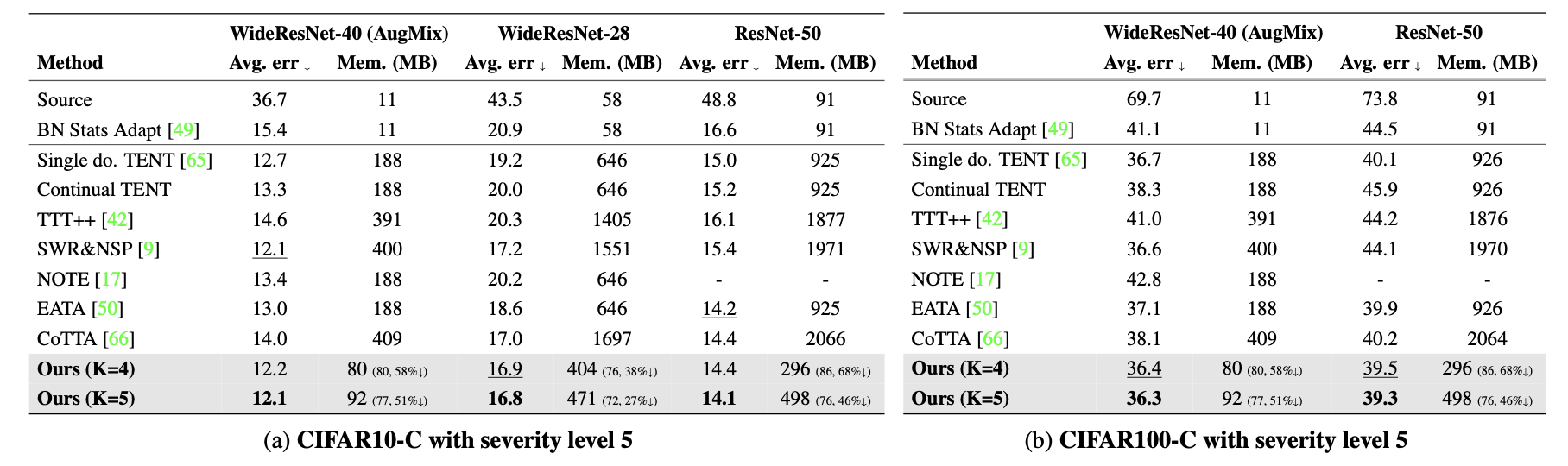 下表是 ImageNet 到 ImageNet-C 的结果:
下表是 ImageNet 到 ImageNet-C 的结果:
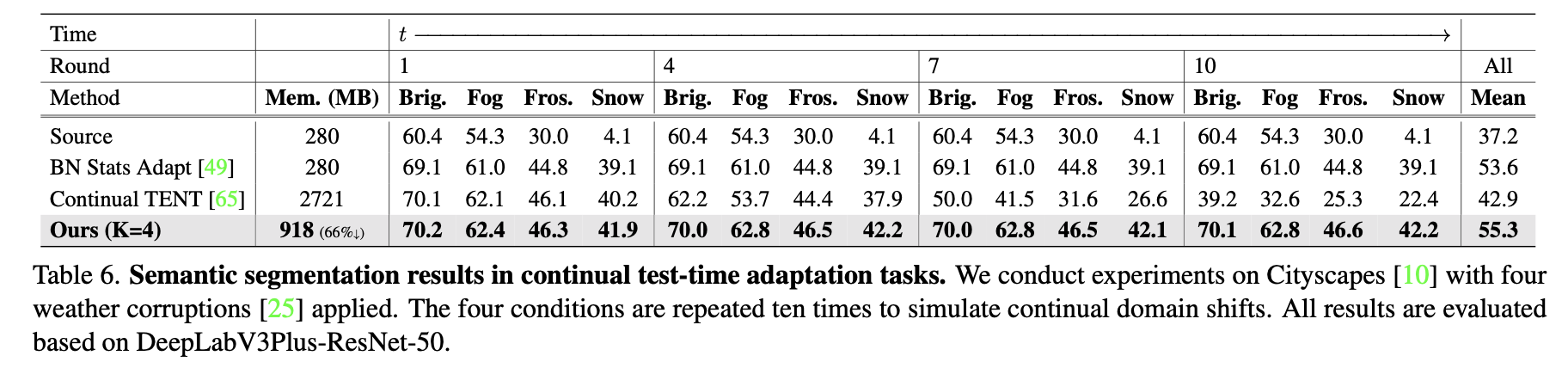
分割实验¶
下表是分割实验的对比结果,可以发现没有和 CoTTA 比较,因为 EcoTTA 没有用和 CoTTA 一样的 backbone: Segformer,而是 ResNet family。这里我的考虑是,在 Segformer 上性能提高可以可能不明显,并且 Segformer 的内存占用更大。
总结¶
这个工作改进了 CoTTA 的性能并节省了大量内存,适用于内存有限的边缘设备(例如,具有 512MB 的树莓派和具有 4G B的 iPhone 13)。首先,提出了一种内存高效的架构,由原始网络和元网络组成。通过减少用于梯度计算的中间激活值,该架构所需的内存大小比先前的 TTA 方法要小得多。其次,在解决长期适应问题中,提出了自蒸馏正则化方法,以保留源知识并防止由于噪声的无监督损失导致的错误累积。该方法通过控制元网络的输出与原始网络的输出没有显著偏离来实现。通过对多个数据集和主干网络进行广泛的实验证明了 EcoTTA 的内存效率和 TTA 上的性能。
参考¶
本文总阅读量次