1. 前言¶
DSDD全称为Deconvolutional Single Shot Detector,即在SSD算法的前面加了一个反卷积单词,这是CVPR 2017的一篇文章,主要是对SSD进行了一个改进。关于SSD的详细解释请看目标检测算法之SSD,然后关于反卷积请看深入理解神经网络中的反(转置)卷积。
2. DSDD算法的贡献¶
这篇论文的主要贡献是在常用的目标检测算法中加入了上下文信息。换句话说,常规的目标检测算法一般都是在一个(YOLO,Faster-RCNN)或者多个特征图上进行检测(SSD),但是各个特征层之间的信息并没有有效的结合以及利用,DSSD的贡献正是解决了这一点。
3. 出发点¶
我们知道SSD最明显的缺点就是对小目标不够鲁棒,原因是什么呢?我们知道SSD为了解决小目标检测的思路是在尽量多的特征层上进行检测,来更好的匹配小目标,因为分辨率越大的特征图小目标的空间信息就保留得越多。但是,这样做有个问题,那就是浅层提取的特征图表达能力不够强,也即是说浅层特征图中每个格子也可以判断这个格子中包含的是哪一个类,但是不够那么确定。具体来说有可能出现 框对了,但是分类出错或者置信度不够好或者将背景误认为目标等等,也就是说SSD同样还是存在误检和漏检的情况。这种情况对于小目标场景出现的概率更大,因此SSD对于小目标的检测仍然不够鲁棒。
4. DSSD的网络结构¶
SSD和DSSD的网络结构如Figure1所示:

经过上一节的分析我们知道SSD对小目标不够鲁棒的主要原因就是特征图的表征能力不够强。为了解决这一点,DSSD就使用了更好的BackBone网络(ResNet)和反卷积层,跳跃链接来给浅层特征图更好的表征能力。那么具体是怎么做的呢?
既然DSSD算法的核心就是提高浅层特征图的表征能力,首先想到的肯定是将基础网络由VGG换成ResNet,下面的Table2说明了在VGG和ResNet上哪些层作为最后的预测特征图。如果你对这里有点模糊,可以看一下我的这篇推文目标检测算法之SSD代码解析(万字长文超详细)

另外需要注意的是这些层可不是随便选择的,大致要和VGG相互对应感受野也要对应,这样才能保证效果会变好,不然也有可能会变差。下面Table3中的实验结果也展示出了浅层的特征更具有表示能力时,在小目标上的效果就会更好。

5. 预测模块¶
基于ResNet的实验还有一点就是修改网络的预测模块,作者使用了4种不同的预测模块,如Figure2所示。
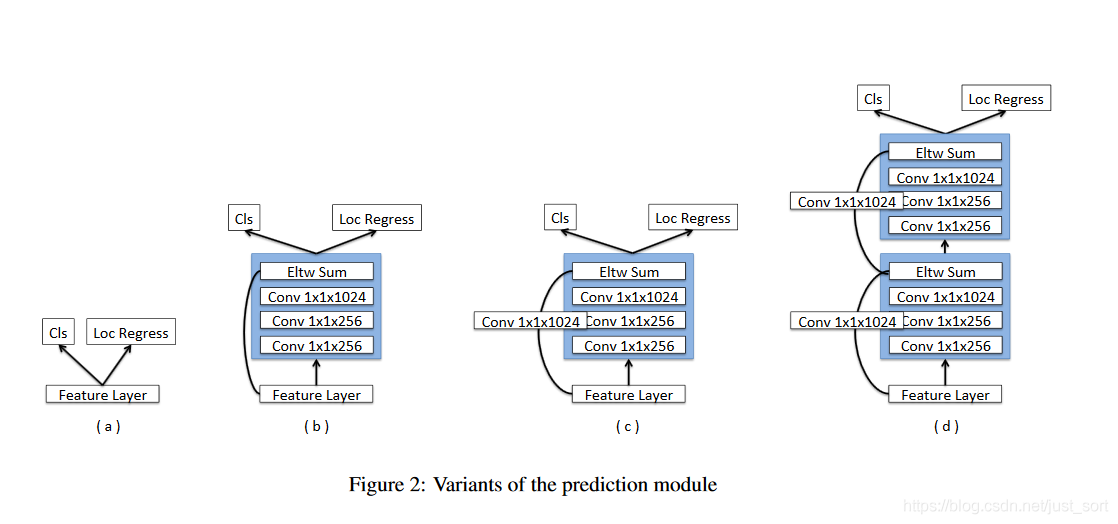
从下面的Table4可以看到这确实提升了效果,并且c这种结构比d这种结构更好一些,这个设计的灵感据说来自于MS-CNN,它指出改善每个任务的分支网络同样可以提高准确率。
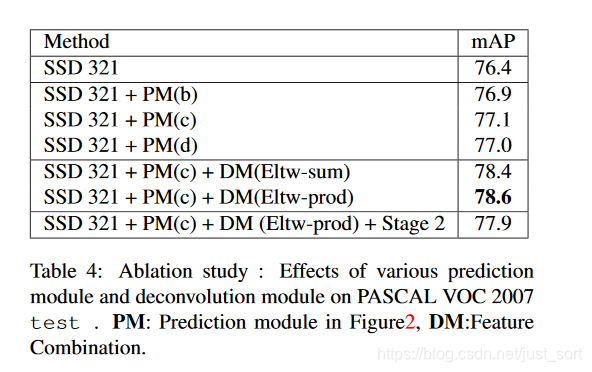
注意最后一行是使用了approximate bilinear pooling(CVPR 2016)的结果。
6. 反卷积模块¶
在SSD的网络结构图中的:

就代表了本文的主要创新点,即反卷积模块,它的具体结构如Figure3所示:
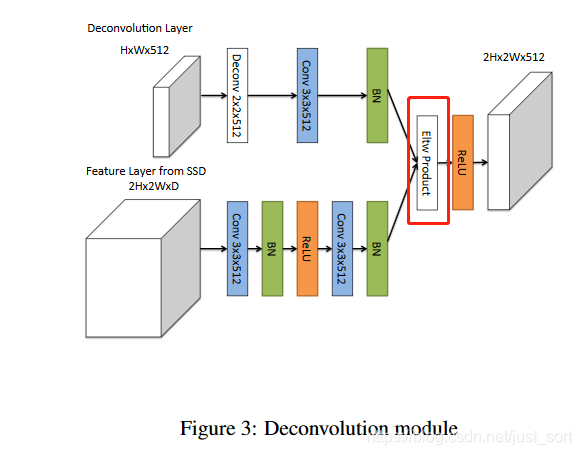
这个模块里面被红色框部分圈住的可以有两种连接方式,Eltw Product其实就是矩阵的点积,还有sum的形式就是求和。上一节的Table4展示了这两种操作的精度差距,相关部分截图如下:
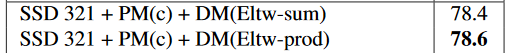
将ResNet,反卷积模块和预测模块结合在一起就构成了最终的DSSD算法。
7. 模型训练¶
在实验时,使用SSD模型初始化DSSD网络,但是对于default box选取的长宽比例,作者在论文中做了详细的分析和改进。为了得到PASCAL VOC 2007和2012 trainval图片里各个物体对应的真实位置框的长宽比例,作者用K-means以这些真实框内区域面积的平方根作为特征做了一个聚类分析,做聚类的时候增加聚类的个数来提升聚类的准确度,最后确定七类的时候收敛的错误率最低如Table1所示:
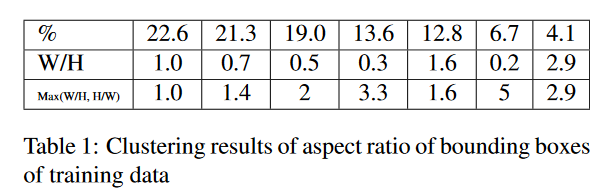
因为SSD训练时使用的训练图片会重新调整比例变成方形的尺寸,但是在大多数的训练图片都是比较宽的图片,所以相应的真实框的宽度会变小一点。通过这种聚类实验最后确定了预测使用的default box的长宽比例为1、1.6、2和3,作为每一个特征图的default box所使用的长宽比例。
DSSD的作者WeiLiu大神在Caffe框架中将SSD的基础网络改成ResNet101然后重新训练了一个新的SSD模型,以VOC的数据集为例,训练集使用的数据是VOC2007和VOC2012的trainval数据集,测试用的是07的测试集,训练时一共迭代了70k次,使用学习率为1e-3在前40k次iterations,然后调整学习率为1e-4、1e-5再分别训练20k次、10k次iterations。然后用用训练好的SSD模型来初始化DSSD网络。训练DSSD的过程分为两个阶段,第一个阶段,加载SSD模型初始化DSSD网络,并冻结SSD网络的参数,然后只增加反卷积模型(不添加预测模型),在这样的条件下只训练反卷积模型,设置学习率为1e-3、1e-4分别迭代20k次和10k次;第二个阶段,fine-tune第一阶段的模型,解冻第一阶段训练时候冻结的所有参数,并添加预测模型,设置学习率为1e-3、1e-4再分别训练20k次、20k次iterations。
8. 总结¶
这篇论文表达出,提升浅层特征图的表达能力是可以提高类似的目标检测器对小目标的检测能力的,可以作为我们思考的一个方向。
9. 参考¶
- https://zhuanlan.zhihu.com/p/33036037
- https://blog.csdn.net/zj15939317693/article/details/80599596
- 开源代码:https://github.com/chengyangfu/caffe/tree/dssd
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

本文总阅读量次