前言¶
前面介绍了使用特征脸法进行人脸识别,这里介绍一下OpenCV人脸识别的另外两种算法,一种是FisherFace算法,一种是LBPH算法。
FisherFace算法¶
FisherFace是基于线性判别分析(LDA)实现的。LDA算法思想最早由英国统计与遗传学家,现代统计科学的奠基人之一罗纳德*费舍尔(Ronald)提出。LDA算法使用统计学方法,尝试找到物体间特征的一个线性组合,在降维的同时考虑类别信息。通过该算法得到的线性组合可以用来作为一个线性分类器或者实现降维。
LDA的算法原理可以看我之前发的两篇推文,和《周志华机器学习》的线性判别分析那一个节,我的推文地址如下:https://mp.weixin.qq.com/s/4gowEl_OA13y5u6VueOChg 和 https://mp.weixin.qq.com/s/K6ASbhVrV5-YXrp-rldP6A 。
通过之前讲过的LDA算法原理,我们知道,该算法是在样本数据映射到另外一个特征空间后,将类内距离最小化,类间距离最大化。LDA算法可以用作降维,该算法的原理和PCA算法很相似,因此LDA算法也同样可以用在人脸识别领域。通过使用PCA算法来进行人脸识别的算法称为特征脸法,而使用LDA算法进行人脸识别的算法称为费舍尔脸法。由于LDA算法与PCA算法很相似,我们简单的对二者做一个比较。 LDA和PCA算法的相似之处在于:
- 在降维的时候,两者都使用了矩阵的特征分解思想。
- 两者都假设数据符合高斯分布。 LDA和PCA的不同之处在于:
- LDA是有监督的降维方法,而PCA是无监督的。
- 如果说数据是k维的,那么LDA只能降到(k-1)维度,而PCA不受此限制。
- 从数学角度来看,LDA选择分类性能最好的投影方向,而PCA选择样本投影点具有最大方差的方向。
通过LDA算法得到的这些特征向量就是FisherFace,后续的人脸人脸识别过程和上一节的完全一致,只需要把特征脸法模型改成FisherFace模型即可,要更改的代码就一行,如下:
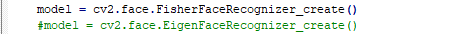
值得一提的是,FisherFace算法识别的错误率低于哈佛和耶鲁人脸数据库测试的特征脸法识别结果。
LBPH¶
算法原理¶
OpenCV除了提供特征脸法,FisherFace以外,还提供了另外一种经典的人脸识别算法即LBPH。KBPH是Local Binary Patterns Histograms的缩写,翻译过来就是局部二进制编码直方图。该算法基于提取图像特征的LBP算子。如果直接使用LBP编码图像用于人脸识别。其实和不提取LBP特征区别不大,因此在实际的LBP应用中,一般采用LBP编码图像的统计直方图作为特征向量进行分类识别。
该算法的大致思路是:
先使用LBP算子提取图片特征,这样可以获取整幅图像的LBP编码图像。再将该LBP编码图像分为若干个区域,获取每个区域的LBP编码直方图,从而得到整幅图像的LBP编码直方图。该方法能够在一定范围内减少因为没完全对准人脸区域而造成的误差。另一个好处是我们可以根据不同的区域赋予不同的权重,例如人脸图像往往在图像的中心区域,因此中心区域的权重往往大于边缘部分的权重。通过对图片的上述处理,人脸图像的特征便提取完了。
当需要进行人脸识别时,只需要将待识别人脸数据与数据集种的人脸特征进行对比即可,特征距离最近的便是同一个人的人脸。再进行特征距离度量的时候,通常使用基于直方图的图像相似度计算函数,该比较方法对应于OpenCV中的comparreHist()函数,该函数提供巴氏距离,相关性与基于卡方的相似度衡量方式。
关于LBPH的细节可以自己搜索一下。
代码实现¶
这里我还是用上次推文的代码来测试一下LBPH人脸识别模型,仍然只需要改一行代码,即是:
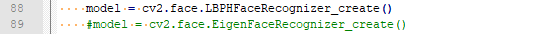
然后就可以和上次推文一样获得一个简单的基于LBPH的人脸识别demo 了。
Dlib人脸检测¶
原理¶
Dlib是一款优秀的跨平台开源的C++工具库,该库使用C++编写,具有优异的性能。Dlib库提供的功能十分丰富,包括线性代数,图像处理,机器学习,网络,最优化算法等众多功能。同时该库也提供了Python,这一节我们正是要用到这个Python接口。
Dlib的核心原理是使用了图像Hog特征来表示人脸,和其他特征提取算子相比,它对图像的几何和光学的形变都能保持很好的不变形。该特征与LBP特征,Harr特征共同作为三种经典的图像特征,该特征提取算子通常和支持向量机(SVM)算法搭配使用,用在物体检测场景。
Dlib 实现的人脸检测方法便是基于图像的Hog特征,综合支持向量机算法实现的人脸检测功能,该算法的大致思路如下:
- 对正样本(即包含人脸的图像)数据集提取Hog特征,得到Hog特征描述子。
-
对负样本(即不包含人脸的图像)数据集提取Hog特征,得到Hog描述子。 其中负样本数据集中的数据量要远远大于正样本数据集中的样本数,负样本图像可以使用不含人脸的图片进行随机裁剪获取。
-
利用支持向量机算法训练正负样本,显然这是一个二分类问题,可以得到训练后的模型。
- 利用该模型进行负样本难例检测,也就是难分样本挖掘(hard-negtive mining),以便提高最终模型的分类能力。具体思路为:对训练集里的负样本不断进行缩放,直至与模板匹配位置,通过模板滑动串口搜索匹配(该过程即多尺度检测过程),如果分类器误检出非人脸区域则截取该部分图像加入到负样本中。
- 集合难例样本重新训练模型,反复如此得到最终分类模型。
应用最终训练出的分类器检测人脸图片,对该图片的不同尺寸进行滑动扫描,提取Hog特征,并用分类器分类。如果检测判定为人脸,则将其标定出来,经过一轮滑动扫描后必然会出现同一个人脸被多次标定的情况,这就用NMS完成收尾工作即可。
Dlib人脸检测实战¶
talk is cheep, show me the coder。 这一节就用Python调用Dlib完成人脸检测来看看效果。 在调用之前首先要安装Dlib人脸检测库,我使用的是Windows 10,Core i5的处理器。 我的安装方式为: 到网站找到对应自己电脑型号的wheel文件,网站地址是:https://pypi.org/simple/dlib/ 然后pip install *** 这个库才2M,下载起来十分轻松。
然后去这个网站下载训练好的模型文件:http://dlib.net/files/ 。我这里下载了这个网站的最下面一个,也就是: shape_predictor_68_face_landmarks.dat.bz2 ,解压出来,我们就可以加载这个文件进行人脸68个关键点检测了。
单张人脸检测¶
这里检测一张胡歌的图片。
代码如下:
import cv2
import dlib
import matplotlib.pyplot as plt
import numpy as np
# 读取图片
img_path = 'F:\\face_recognize\\huge.jpg'
img = cv2.imread(img_path)
origin_img = img.copy()
# 定义人脸检测器
detector = dlib.get_frontal_face_detector()
# 定义人脸关键点检测器
predictor = dlib.shape_predictor("F:\\face_recognize\\shape_predictor_68_face_landmarks.dat")
# 检测得到的人脸
faces = detector(img, 0)
# 如果存在人脸
if len(faces):
print("Found %d faces in this image." % len(faces))
for i in range(len(faces)):
landmarks = np.matrix([[p.x, p.y] for p in predictor(img, faces[i]).parts()])
for point in landmarks:
pos = (point[0, 0], point[0, 1])
cv2.circle(img, pos, 1, color=(0, 255, 255), thickness=3)
else:
print('Face not found!')
cv2.namedWindow("Origin Face", cv2.WINDOW_FREERATIO)
cv2.namedWindow("Detected Face", cv2.WINDOW_FREERATIO)
cv2.imshow("Origin Face", origin_img)
cv2.waitKey(0)
cv2.imshow("Detected Face", img)
cv2.waitKey(0)
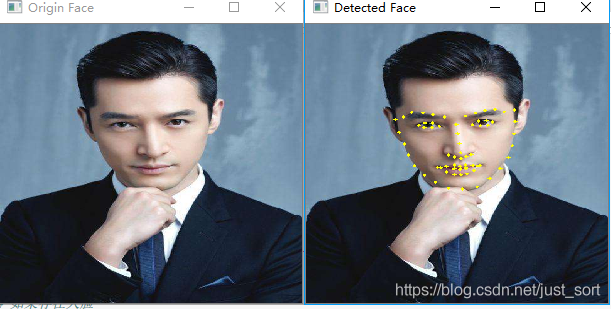
实时检测¶
不知道这个算法是否可以实时,我们写一个代码,打开一个摄像头,并实时显示一下帧率。
import cv2
import dlib
import matplotlib.pyplot as plt
import numpy as np
import time
def FaceRecognize():
# 定义人脸检测器
detector = dlib.get_frontal_face_detector()
# 定义人脸关键点检测器
predictor = dlib.shape_predictor("F:\\face_recognize\\shape_predictor_68_face_landmarks.dat")
#打开摄像头
camera = cv2.VideoCapture(0)
st = 0
en = 0
while(True):
# 读取一帧图像
ret,img = camera.read()
#判断图片读取成功
start_time = time.time()
if ret:
# 检测到的人脸
faces = detector(img, 0)
# 如果存在人脸
if len(faces):
print("Found %d faces in this image." % len(faces))
for i in range(len(faces)):
landmarks = np.matrix([[p.x, p.y] for p in predictor(img, faces[i]).parts()])
for point in landmarks:
pos = (point[0, 0], point[0, 1])
cv2.circle(img, pos, 1, color=(0, 255, 255), thickness=3)
else:
print('Face not found!')
#rint("FPS: ", 1.0 / (time.time() - start_time))
cv2.putText(img, "FPS {0}" .format(str(1.0 / (time.time() - start_time))), (40, 40), 3, 1, (255, 0, 255), 2)
cv2.imshow('Face',img)
#如果按下q键则退出
if cv2.waitKey(100) & 0xff == ord('q') :
break
camera.release()
cv2.destroyAllWindows()
FaceRecognize()

(打了点马赛克)
Dlib检测的效果还不错,而且速度在我的I5处理器1s都到80-90帧了,如果做一个简单的人脸检测任务可以考虑使用这个算法。
OK, 今天讲到这里了,有问题下方留言。
欢迎关注我的微信公众号GiantPadaCV,期待和你一起交流机器学习,深度学习,图像算法,优化技术,比赛及日常生活等。
本文总阅读量次