增强CNN学习能力的Backbone:CSPNet¶
CSPNet全称是Cross Stage Partial Network,主要从一个比较特殊的角度切入,能够在降低20%计算量的情况下保持甚至提高CNN的能力。CSPNet开源了一部分cfg文件,其中一部分cfg可以直接使用AlexeyAB版Darknet还有ultralytics的yolov3运行。
1. 简介¶
Cross Stage Partial Network(CSPNet)就是从网络结构设计的角度来解决以往工作在推理过程中需要很大计算量的问题。
作者认为推理计算过高的问题是由于网络优化中的梯度信息重复导致的。CSPNet通过将梯度的变化从头到尾地集成到特征图中,在减少了计算量的同时可以保证准确率。CSPNet是一种处理的思想,可以和ResNet、ResNeXt和DenseNet结合。
下图是cspnet对不同backbone结合后的效果,可以看出计算量大幅下降,准确率保持不变或者略有提升(ps: 分类的提升确实不多)

下图是CSPNet用于目标检测的结果:

AlexeyAB版本的darknet的首页就是这张图,使用CSPNet做backbone可以极大提升模型的准确率,在同等FPS的情况下,CSPNet准确率更有竞争力。
CSPNet提出主要是为了解决三个问题:
- 增强CNN的学习能力,能够在轻量化的同时保持准确性。
- 降低计算瓶颈
- 降低内存成本
2. 实现¶
CSPNet作者也设计了几种特征融合的策略,如下图所示:

图中的Transition Layer代表过渡层,主要包含瓶颈层(1x1卷积)和池化层(可选)。 (a)图是原始的DenseNet的特征融合方式。 (b)图是CSPDenseNet的特征融合方式(trainsition->concatenation->transition)。 (c)图是Fusion First的特征融合方式(concatenation->transition) (d)图是Fusion Last的特征融合方式(transition->concatenation)
Fustion First的方式是对两个分支的feature map先进行concatenation操作,这样梯度信息可以被重用。
Fusion Last的方式是对Dense Block所在分支先进性transition操作,然后再进行concatenation, 梯度信息将被截断,因此不会重复使用梯度信息 。
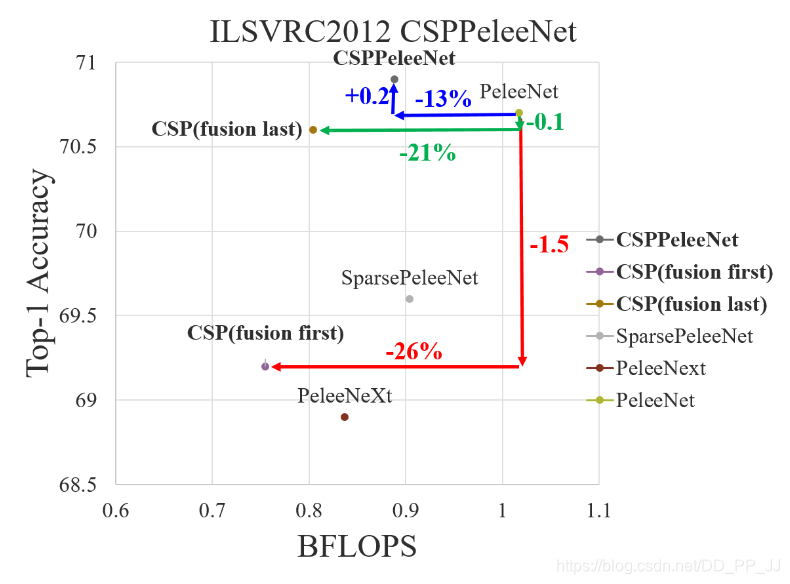
上图是对Fusion First、Fusion Last和CSP最终采用的融合方式(对应上图CSPPeleeNet)在ILSVRC2012分类数据集上的对比,可以得到以下结论:
- 使用Fusion First有助于降低计算代价,但是准确率有显著下降。
- 使用Fusion Last也是极大降低了计算代价,top-1 accuracy仅仅下降了0.1个百分点。
- 同时使用Fusion First和Fusion Last的CSP所采用的融合方式可以在降低计算代价的同时,提升准确率。

上图是DenseNet的示意图以及CSPDenseNet的改进,改进点在于CSPNet将浅层特征映射为两个部分,一部分经过Dense模块(图中的Partial Dense Block),另一部分直接与Partial Dense Block输出进行concate。
下图是将CSP模型应用到ResNeXt或者ResNet中:

跟CSPDenseNet一样,将上一层分为两部分,Part1不进行操作直接concate,Part2进行卷积操作。
下面是实现的cfg文件可视化图,可视化的内容是csresnet50中的一个基本模块:

3. FPN设计¶

论文中列举了三种FPN:
第一个如(a)图所示,是最常见的FPN,在YOLOv3中使用。(ps: YOLOv3中的FPN跟原始FPN不同,其融合的方式是concate)
第二个如(b)图所示,是ThunderNet中提出的GFM, 之前的文章中有详解,直接将多个不同分辨率的特征进行融合,具体融合方式是相加。
第三个如(c)图所示,是EFM,也就是本文提出的融合方式,每两层之间特征进行融合,并且在原有FPN基础上再进行一次bottom-up的融合方式。
4. 实验¶
首先来看一下EFM的消融实验:

实验是基于MS COCO数据集的,PRN其实也是同一个团队在提出的和CSP相似的思想,被ICCV接收。

上图来自《Enriching Variety of Layer-wise Learning Information by Gradient Combination》,也就是RPN网络,也是将输入特征划分为两部分,一部分经过卷积,另一部分经过直接通过concate进行融合。
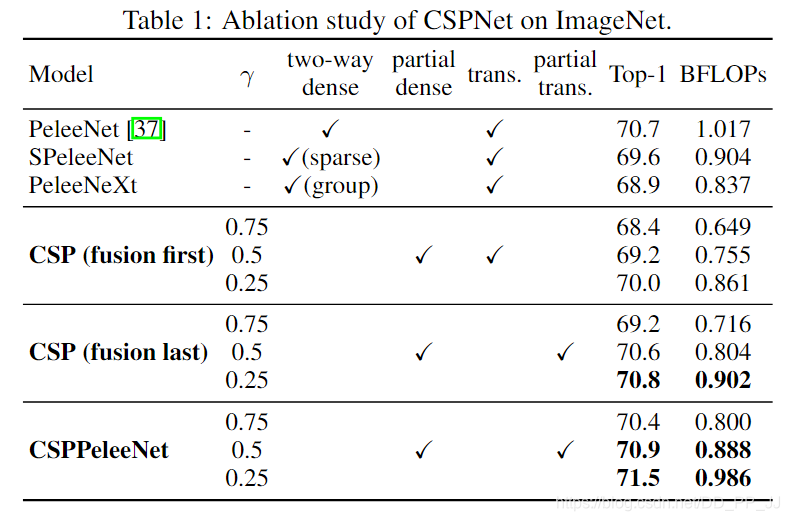
下表是CSPNet对特征融合方式所进行的消融实验:
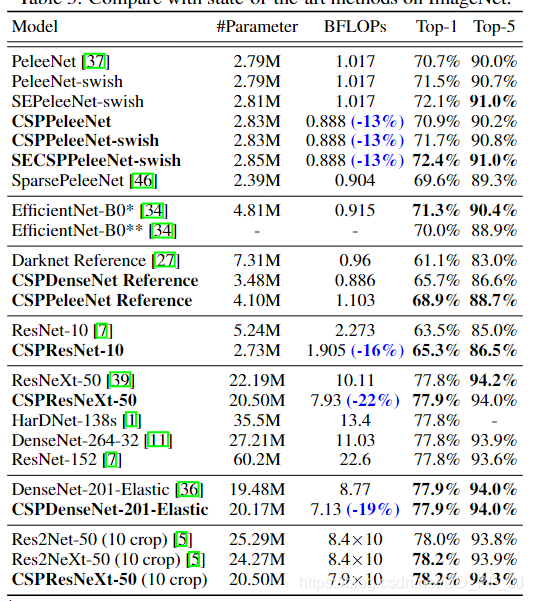
作者还做了非常多的实验来验证CSPNet的有效性,下图是在ImageNet中的一些SOTA模型:
作者还做了非常多的实验来验证CSPNet的有效性,下图是在分类网络中的对比试验:
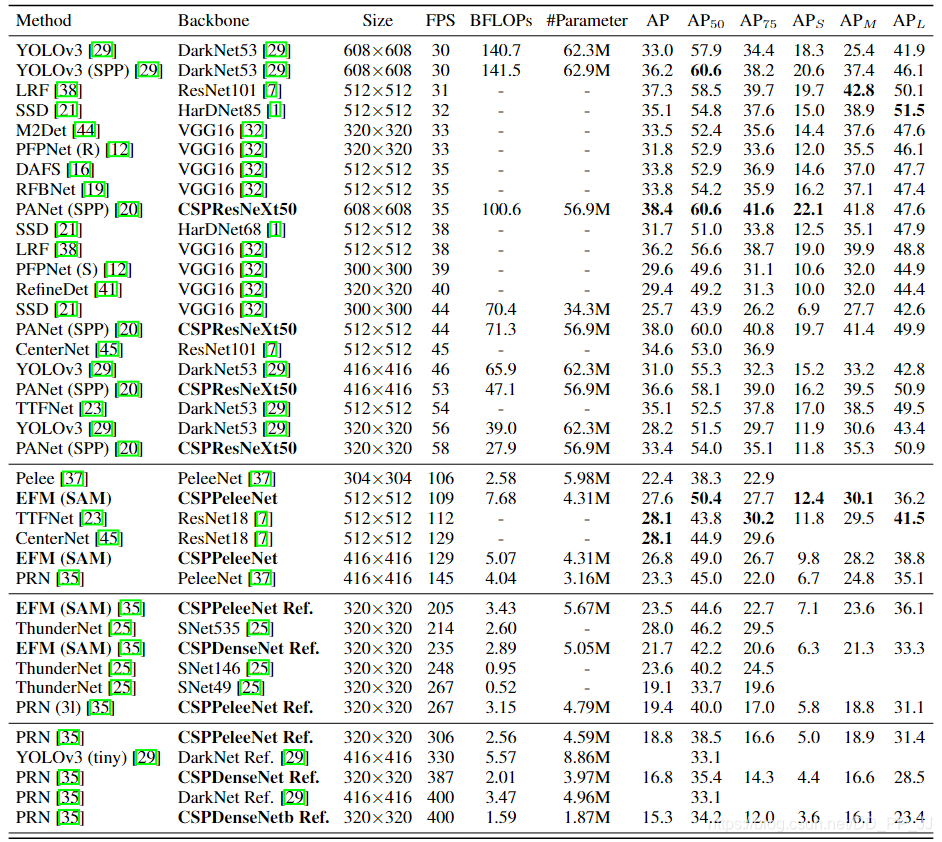
下图是在MS COCO数据集上的SOTA模型:
应用于移动端的分类模型也进行了实验:
值得一提的是,以上模型大部分都是基于AlexeyAB的Darknet进行的实验,也有一小部分是在ultralytics的yolov3上进行的实验,不过后者支持的并不是很完全。
总结¶
CSPNet和PRN都是一个思想,将feature map拆成两个部分,一部分进行卷积操作,另一部分和上一部分卷积操作的结果进行concate。
从实验结果来看,分类问题中,使用CSPNet可以降低计算量,但是准确率提升很小;在目标检测问题中,使用CSPNet作为Backbone带来的提升比较大,可以有效增强CNN的学习能力,同时也降低了计算量。
总体来说,CSPNet还是非常强的,也得到了AlexeyAB大神的认可,darknet中也提供了具体的实现:
[convolutional]
batch_normalize=1
filters=128
size=1
stride=1
pad=1
activation=leaky
# 1-1
[route]
layers = -1
group_id=0
groups=2
# 1-2
[route]
layers = -2
group_id=1
groups=2
或者
# 1-1
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=leaky
[route]
layers = -2
# 1-2
[convolutional]
batch_normalize=1
filters=64
size=1
stride=1
pad=1
activation=leaky
作者也在Github中公开了部分的cfg文件实现,可以配合AlexeyAB版的Darknet进行使用,Github链接如下:
https://github.com/WongKinYiu/CrossStagePartialNetworks
Reference¶
https://github.com/WongKinYiu/CrossStagePartialNetworks
https://arxiv.org/pdf/1911.11929.pdf
https://github.com/ultralytics/yolov3
PRN: Enriching Variety of Layer-wise Learning Information by Gradient Combination
本文总阅读量次