CVPR VISION 23挑战赛第1赛道亚军解决方案 - 数据高效缺陷检测
CVPR VISION 23挑战赛第1赛道亚军解决方案 - 数据高效缺陷检测¶
1. 摘要¶
CVPR VISION 23挑战赛第1赛道 "数据智能缺陷检测 "要求参赛者在数据缺乏的环境下对14个工业检测数据集进行实例分割。本论文的方法聚焦于在有限训练样本的场景下提高缺陷掩模的分割质量的关键问题。基于混合任务级联(HTC)实例分割算法,我们用受CBNetv2启发的复合连接将transformer骨干(Swin-B)连接起来以增强基准结果。此外,我们提出了两种模型集成方法来进一步增强分割效果:一种是将语义分割整合到实例分割中,另一种是采用多实例分割融合算法。最后,通过多尺度训练和测试时数据增强(TTA),我们在数据高效缺陷检测挑战赛的测试集上获得了高于48.49%的平均mAP@0.50:0.95和66.71%的平均mAR@0.50:0.95。 论文链接:https://arxiv.org/abs/2306.14116 代码链接:https://github.com/love6tao/
2. 背景补充¶
深度学习在视觉检测中的应用越来越广泛,这包括如无人机巡检电力设备、检测工业表面上的轻微划痕、识别深孔零件中的铜线缺陷以及检测芯片和玻璃表面上的导电微粒等工业缺陷检测任务。但是,在工业制造场景中获得标注的缺陷数据是困难、昂贵和耗时的,因此使得基于视觉的工业检测更具挑战性。为了解决这个问题,CVPR VISION 23挑战赛第1赛道 - 数据高效缺陷检测竞赛启动。
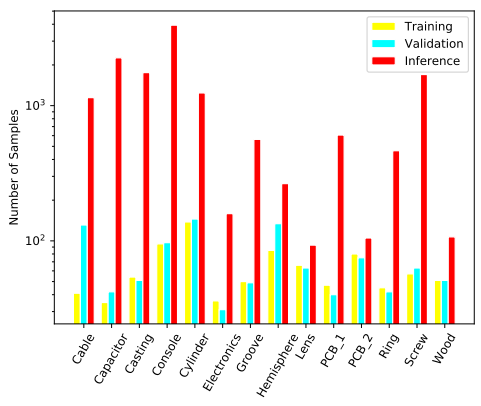
该竞赛数据集由14个来自真实场景的缺陷数据集组成,最显著的特点是测试样本数量远远超过训练样本数量。如上图所示,一些数据集如电容器和电子设备数据集仅包含不超过40个训练样本。此外,某些图像在数据集中存在显著的尺度变化。大多数框只覆盖图像的10%,而一些框可以覆盖整个图像。而且,14个数据集之间的背景和缺陷纹理形状存在显著差异,使得构建可以在每个数据集上都取得满意结果的统一算法框架是一个巨大的挑战。为了解决这些问题,我们训练了一个以Swin Transformer 和CBNetV2 为骨干的强大基准模型,然后采用两种模型集成方法来进一步提升分割性能。我们将在第2节中介绍我们的流程和详细组件。实验结果和消融研究显示在第3节中。
3. 方法介绍¶

在这一节中,我们提出了一个由三部分组成的有效流程。首先训练一个强大的单实例分割模型作为基准,使用混合任务级联,以Swin Transformer和CBNetV2作为其骨干,如上图所示。其次,使用Mask2Former 训练一个强大的语义分割模型来进一步提炼分割性能,将语义分割结果与实例分割结果融合。最后,融合三个实例分割模型的结果以进一步改进分割效果用于最终提交。
3.1 基础实例分割模型¶

我们的基础实例分割模型建立在混合任务级联(HTC) 检测器之上,使用CBSwinBase骨干和CBFPN 架构。HTC是一个用于实例分割任务的稳健的级联架构,它巧妙地混合了检测和分割分支进行联合多阶段处理,在每个阶段逐步提取更有区分性的特征。为避免需要额外的语义分割注释,我们从解决方案中删除了语义头部。最近的视觉Transformer的进步对各种视觉任务非常重要,因此我们采用Swin Transformer作为我们的骨干。Swin Transformer在分层特征架构中引入了一个高效的window注意力模块,其计算复杂度与输入图像大小呈线性关系。 在我们的工作中,我们采用在ImageNet-22k数据集上预训练的Swin-B网络作为我们的基本骨干。为进一步提高性能,我们受CBNetv2算法的启发,通过复合连接将两个相同的Swin-B网络组合在一起。如上图所示。
3.2 将语义分割整合到实例分割中¶
尽管单个模型可以取得很好的分割结果,但实例分割的结果通常不完整,特别是在设定IOU阈值过高时,这可能对mask mAP 产生负面影响。因此,我们使用语义分割模型的输出来补充实例分割模型的结果。
我们的语义分割模型基于Mask2Former,使用Swin-L作为骨干,其网络输入图像大小为512×512。预训练权重来自ADE20K数据集。为了训练语义分割网络,我们将多缺陷标签转换为表示背景和缺陷的二进制标签。
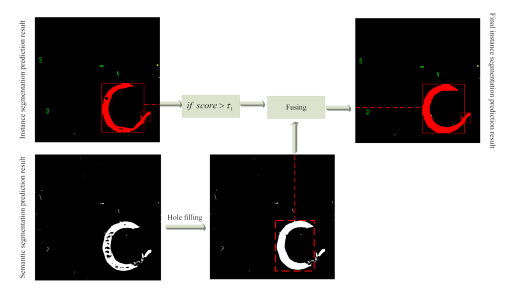
对于融合策略,我们在相同的像素位置组合实例分割结果和语义分割结果,生成新的实例分割结果,如上图所示。由于语义分割任务将像素划分为两类:缺陷和背景,所以实例分割任务中的预测边界框(bbox)类确定了像素的实际类。值得注意的是,只有预测实例与bbox置信度大于阈值\tau_1才会与语义分割结果进行融合。在竞赛中,我们将\tau_1设置为0.5以获得最佳的分割性能。
3.3 多个实例分割的融合¶

我们的实验结果表明,不同的实例分割骨干可以产生互补的结果。这意味着融合不同骨干的实例分割结果可以提高模型的召回率。但是,提高召回率往往以牺牲检测精度为代价。为解决这个问题,我们设计了一个融合策略,如上图所示。
在我们的实验中,我们将model-1、model-2和model-3分别称为HTC、Cascade Mask rcnn-ResNet50和Cascade Mask rcnn-ConvNext模型。这些模型的设计目的是在它们之间增加多样性。
Mask2Former是一个经过验证的高效语义分割架构,已经被证明在各种应用中都能实现最先进的结果,如语义、实例和全景分割。通过将语义分割与实例分割相结合,我们在测试数据集上取得了显着的48.38%的mask mAP。最后,通过平均模型包中这些模型的预测,我们的模型集成在竞赛中实现了卓越的性能,mAP达到48.49%,mAR达到66.71%。
4. 未来改进方向¶
半监督学习:在我们的实验中,我们仅关注在训练和验证集上训练实例分割模型。我们尝试使用基于soft-teacher的半监督学习方法来改进实例分割的性能。然而,由于数据集的差异,无法为半监督模型提供统一的训练策略。由于竞赛时间的限制,以后的研究将半监督方法作为一个更可行的方向。
SAM: Meta提出了通用分割模型(SAM)作为解决分割任务的基础模型。我们通过在线演示网站评估了其有效性,并确定该模型在工业数据上的泛化性能也很出色。但是,根据竞赛规则,我们不能使用SAM。尽管如此,大模型或基础模型仍有可能为工业缺陷检测带来重大变化,从而为未来工作提供了另一个改进方向。
5. 结论¶
在论文中,我们介绍了CVPR VISION 23挑战赛第1赛道亚军解决方案"数据高效缺陷检测"技术细节。作者的方法包括三个主要组成部分:基础实例分割模型、将语义分割整合到实例分割中的方法以及融合多个实例分割的策略。通过一系列实验,我们证明了我们的方法在测试集上的竞争力,在mAP@0.50:0.95上获得48.49%以上,在mAR@0.50:0.95上获得66.71%以上。
本文总阅读量次