前言¶
传统的卷积神经网络在提高性能时都是加深和加宽网络,但随着超参数数量的增加(如通道数,卷积核大小等)网络变得非常难调,且网络的计算开销和网络结构设计也变得越来越难,这一点我在介绍ResNet和DenseNet大型模型的时候已经提到过了。此外这些大模型针对性比较强,即在特定数据集上表现好的网络放到新数据集上就需要修改很多的参数才能工作良好,因此可扩展性比较一般。针对上述问题,Saining Xie, Ross Girshick, Kaiming He在CVPR2017上提出了ResNeXt。论文原文地址见附录。
贡献¶
- 网络结构更加简单和模块化。
- 大量减少了需要手动调节的超参数,扩展性更强。
- 和ResNet相比,相同的参数个数,结果更好。具体来说,一个101层的ResNeXt 网络,和 200 层的 ResNet 准确度差不多,但是计算量只有后者的一半。
方法¶
网络结构¶
ResNeXt的网络结构如Table1所示:
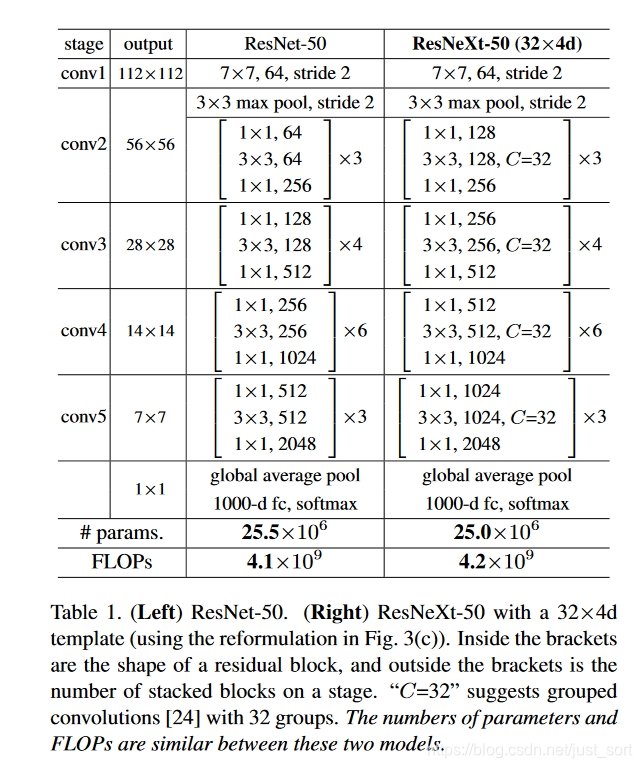
Table 1的左边网络为ResNet-50,Table 1的右边网络为ResNeXt-50,括号代表残差块,括号外面的数字代表残差块的堆叠次数,而C代表的ResNeXt引入的卷积分组数,同时我们可以看到这两个网络的FLOPs基本一致,也即是说模型复杂度一致。那ResNeXt有什么优点呢?这要先从分组来说起。
ResNeXt残差模块¶
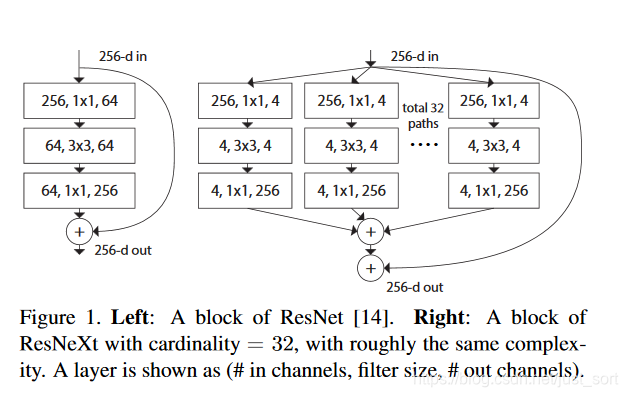
分组数在论文中又被称为基数(cardinality),是对GoogleNet中分立合并思想和VGG/ResNet中堆叠思想的一种结合,ResNet的残差模块和ResNeXt的残差模块如Figure1所示。可以看到ResNeXt残差模块有32个基数(分组数),并且每个被聚合的拓扑结构就完全一样,这里是1\times 1 + 3\times 3 + 1 \times 1的组件,这也是和Inception结构的最大区别。
然后论文从理论角度来分析了一下这个ResNeXt残差模块,用全连接层举例来讲,全连接层的公式可以表示为:
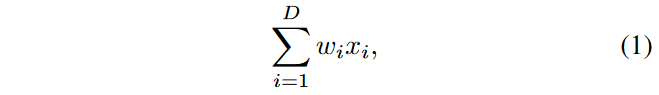
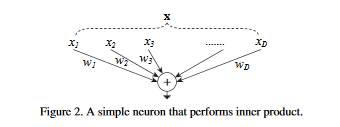
然后Figure2就清晰的展示了全连接层分离变化合并(split-transform-merge)的处理过程:
而ResNeXt残差模块实际上就是将其中的w_ix_i替换成了更一般的函数,用公式表示如下:
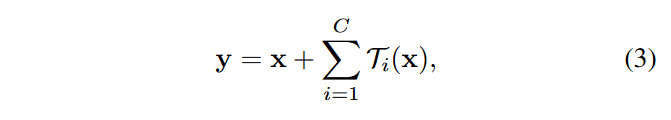
其中C就是上一节提到的分组数/基数,而T_i(x)代表的是相同的拓扑结构,在Figure1中就是1x1+3x3+1x1卷积堆叠。
等价模式¶
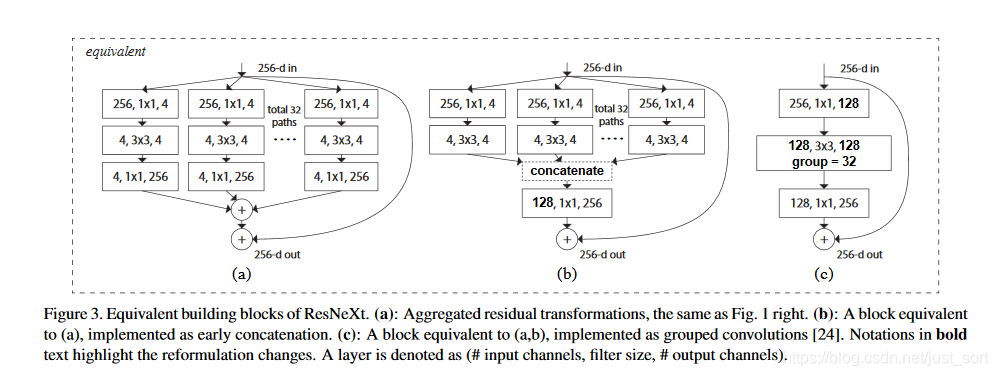
而Figure1中de ResNeXt残差模块有两种等价的模型,如Figure3所示。其中Figure3(a)前面已经讲过了。而Figure3(b)表示的是使用了两层卷积后concat,然后再卷积,比较类似于Inception-ResNet。Figure3(c)使用的是原始的组卷积,这个大家都比较熟悉了。论文指出这三种结构是完全等价的,并且最后做出来的实验结果完全一样,而在实验部分展示的是Figure3(c)的结果,因为Figure3(c)的结构比较简洁并且速度更快。
模型容量¶
下面的Table2说明了Figure1左右两个结构即ResNet结构和ResNeXt结构的参数量差不多,其中第二行的d表示每个路径的中间channel数量,而第三行代表整个模块的宽度,是第一行C和第二行d的乘积。关于这两个模型容量也就是FLOPs的计算就不再赘述了,感兴趣去看一下公式(4),我大概贴一下。

FLOPS计算公式如下,可以看到FLOPS基本相等。

实验¶
在实验中ResNeXt相比于ResNet区别仅仅是其中的block,其他都不变,作者的实验结果如Figure5所示。可以看到相同层数的ResNet和ResNeXt的对比:
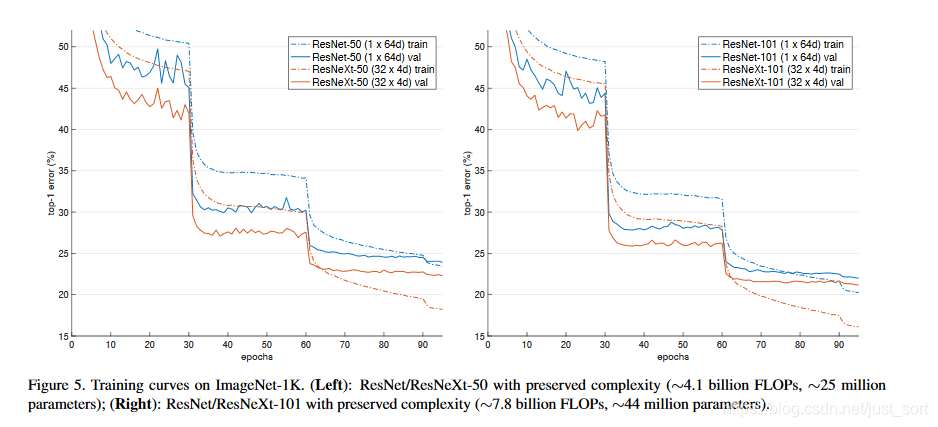
其中,32\times 4d表示的是有32个相同的路径,然后每个路径的宽度都为4,即如Figure3展示的那样。可以看到ResNeXt和ResNet的参数复杂度差不多,但是其训练误差和测试误差都降低了。
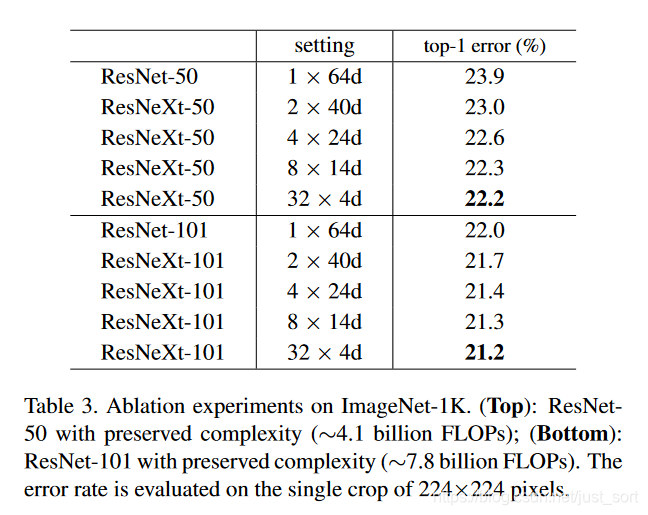
ResNet和ResNeXt在ImageNet上的对比结果如Table3所示:
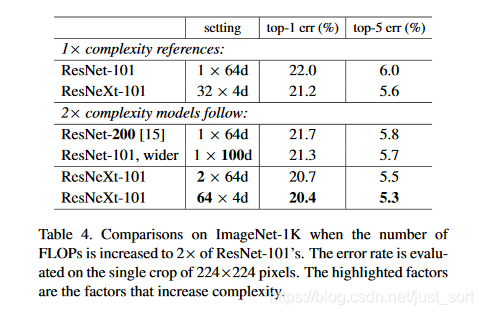
另外一个重要的实验结果如Table4所示,主要说明了增加基数/分组数和增加宽度和深度的区别。第一个是基准模型,增加深度和宽度分别是第三,第四个,可以看到Top1误差分别降低了0.3%和0.7%。同时第五个加倍了分组数Top1误差降低了1.3%,第六个则把分组数加到了64,Top1误差降低了1.6。由此可以看出,增加分组数比增加深度或宽度会更加有效。
结论¶
ResNeXt这篇论文提出了使用一种平行堆叠相同拓扑结构的残差模块来代替原始的残差模块,在不明显增加参数量的同时提升了模型的准确率,同时由于拓扑结构相同,需要自己调的超参数也减少因此更便于模型的扩展和移值。
附录¶
- 论文原文:https://arxiv.org/pdf/1611.05431.pdf
- 参考博客:https://blog.csdn.net/hejin_some/article/details/80743818
推荐阅读¶
- 快2020年了,你还在为深度学习调参而烦恼吗?
- 卷积神经网络学习路线(七)| 经典网络回顾之AlexNet
- 卷积神经网络学习路线(八)| 经典网络回顾之ZFNet和VGGNet
- 卷积神经网络学习路线(九)| 经典网络回顾之GoogLeNet系列
- 卷积神经网络学习路线(十)| 里程碑式创新的ResNet
- 卷积神经网络学习路线(十一)| Stochastic Depth(随机深度网络)
- 卷积神经网络学习路线(十二)| 继往开来的DenseNet
- 卷积神经网络学习路线(十三)| CVPR2017 Deep Pyramidal Residual Networks
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

本文总阅读量次