前言¶
R-FCN全称为Region-based Fully Convolutional Networks,是由微软的何凯明团队在NIPS 2016上提出来的,仍然是双阶段的目标检检测算法。论文地址和官方开源代码见文后。
背景¶
R-FCN论文的发表时间比YOLO,SSD出来的都晚一些,并且这个算法更像是针对Faster-RCNN的一种改进,并且扔属于two-stage算法。那个R-FCN具体要解决什么问题呢?我们不妨先来看看R-FCN之前的典型的two-stage算法分别是在解决什么?
- rcnn 证明cnn具有良好的特征提取能力,也是第一个将cnn用来做目标检测任务的算法。
- fast-rcnn提出ROI-Pooling将需要应用到多个候选框的骨干CNN网络进行共享,加快速度的同时也提升了准确率。
- faster-rcnn解决了候选框搜索耗时过多的问题,提出RPN全卷积网络用于学习提取候选框,速度更快且精度更高。
而Faster-RCNN的一个缺点在于在ROI Pooling之后全是全连接层,从而将ROI Pooling之后的特征图映射为分类和回归两个任务。而越来越多的基础CNN架构如GoogleNet,ResNet等全卷机网络证明不要全连接层,网络的效果不仅会更好并且还可以适应不同尺度的输入图片。因为着眼于Faster-RCNN的全连接层负载很重这一痛点,R-FCN出世了。
方法¶
R-FCN中主要有2个重要的点,第一个是将ROI Pooling后面的全连接层都用卷积层所代替,第二个是对ROI Pooling的魔改。
R-FCN整体结构¶
我们知道,对于Faster-RCNN是会对每一个候选框区域执行ROI Pooling操作之后单独跑后面的分类和回归分支的。因此R-FCN希望耗时的卷积都尽量移动到前面共享的网络中。基于此,和Faster-RCNN用ResNet做Backbone的处理方式不同(前面91层共享,然后插入ROIPooling,后面10层不共享),R-FCN把所有的101层都设置为共享网络,最后用来做预测的只有一个卷积层,大大减少了计算量。这一点参见Table1。

R-FCN可以分成以下四个部分:
- Backbone网络,如ResNet101网络。
- 一个区域建议网络(RPN)。
- 一个正例敏感的预测层。
- 最后的ROI Pooling+投票的决策层。
R-FCN的网络结构图如下所示:

可以看到整体结构和Faster-RCNN比较像,都有RPN网络来训练生成候选框,而ROI Pooling是不一样的,接下来就仔细讲讲。
R-FCN的ROIPooling¶
我们省略一下R-FCN和Faster-RCNN网络结构完全相同的部分,着眼于R-FCN的变化之处即ROIPooling,关键部分如论文中的Figure1所示。我们接下来就针对这张图来仔细分析。
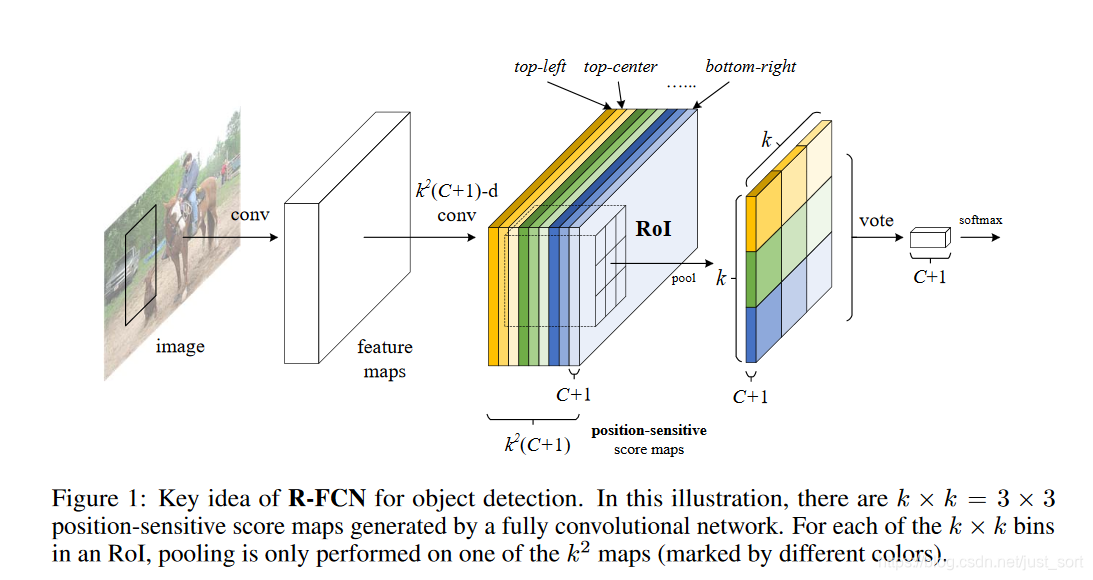
可以看到原始图像经过Backbone的卷积神经网络之后得到了最后一层特征图,接下来就应该是提取当前特征图的ROI区域了。这个地方ROIPooling不像Faster-RCNN那样直接提取,而是重新设计了一个位置敏感的ROIPooling:将Faster-RCNN中的ROI划分成k\times k大小,即是说将ROI区域分成k\times k个小区域(论文中取k=3,即将ROI区域分成9个部分)。然后假设目标检测数据集的目标类别一共有C类,同时加上一个背景类就是C+1类,最后我们希望网络对每个类别都有各自的位置响应。因此最后ROIPooling层的特征维度是k^2\times (C+1)代表每一个类别在某个位置(一共9个)的位置敏感度map,其中每个map的大小和ROIPooling前面那个Backbone网络得到的特征图尺寸完全一致。
那么具体是如何从位置敏感map得到最后那个C+1个通道,并且尺寸为k\times k的特征图呢?如下所示:

Figure3展示了在人这一类目标上是如何从位置敏感map得到最后输出图,这里k=3,那么位置敏感map可以用下面的表格来表示:

其中Pos_x^y代表位置为x(即3\times 3图中的左上,中上,右下,左中,中间,右中,左下,中下,右下9个位置)对应的类别集合为y的位置敏感map,每个表格的内容对应位置敏感map中一种颜色的部分特征图(C+1个通道),位置敏感map每C+1个通道分别从上到下,从左到右对应了上面的表格。这里假设Figure3中的Person类对应的是第一个分类,那么Figure3的处理过程就是对下表对应的特征图进行操作:

具体的操作流程表示为:
- 1、抽取特定类别(这里为人这个类别)对应的k\times k=3 \times3=9个位置的特征图,如Figure3中部所示。
- 2、对抽取出来的部分进行求均值,然后按照位置组成一个k\times k=3\times 3大小的矩阵。
- 3、对这个k\times k大小的矩阵求和,得到一个值。
- 4、对其他每个类别都执行1-3步骤,最终得到一个1\times (C+1)的向量。将这个向量进行
softmax,从而判别特征图上的这个ROI区域对应的目标类别是什么。
R-FCN的目标框回归¶
上面详细讲解了R-FCN提出的ROIPooling的改进之处以及对于目标分类的处理方法,不要忘记目标检测还有一个框回归的过程,所以这里来说一下如何微调ROI区域使得框更加精确,这部分和分类实际上是类似的。我们知道位置敏感map是有k^2(C+1)个通道的,我们依然从Backbone的最后一个特征层部分接触一个有4\times k^2个通道的特征图(和位置敏感map并列),用来做ROI框回归,如下面的表格所示:

然后执行和分类一样的步骤得到一个1\times 4的向量即代表ROI区域的x,y,w,h。计算损失函数和前面Faster-RCNN的一致,均为多任务损失联合训练,分类使用交叉熵,定位使用L1-smooth损失函数。
训练¶
- 训练的样本选择策略:使用OHEM策略,原理就是对样本按loss进行排序,选择前面loss较小的,这个策略主要用来对负样本进行筛选,使得正负样本更加平衡。
- 训练细节:
- SGD+带动量的优化方式,其中动量momentum = 0.9。
- 权重惩罚为0.0005。
- 单尺度训练,将图片min(height,width)设置为600。
- 8块GPU(土豪专区),每一块GPU训练一张图片并且随机选择128个ROI区域进行梯度下降。
- 在前20k次迭代,学习率为0.001,后面10k次迭代为0.0001。
- 使用和Faster-RCNN中一致的训练方式。
- 使用
atrous(hole)算法。增加感受野的同时降低下采样次数。并且使用了这一策略在VOC 2007上可以提升2个点的map。
实验结果¶
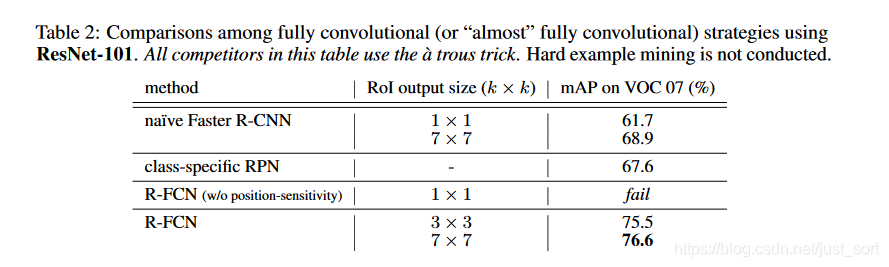 可以看到R-FCN在没有OHEM的策略下精度完全吊打了Faster-RCNN,其中
可以看到R-FCN在没有OHEM的策略下精度完全吊打了Faster-RCNN,其中fail表示的应该是当k=1的时候应该是模型无法收敛。
在PASCAL VOC数据集上的测试结果¶
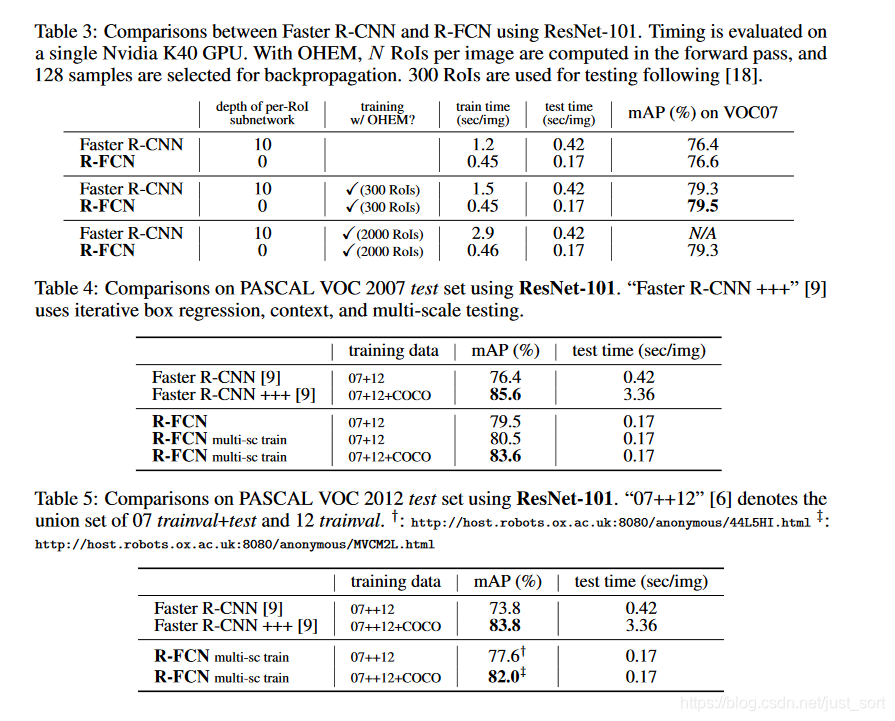
可以看到R-FCN使用ResNet101做特征提取网络,最终在VOC的测试集上获得了83.6%的map值,并且相比于Faster-RCNN测试时间加速了2倍以上。论文还给出了一些消融研究:
- 深度影响对比,可以看出ResNet-101表现最好。
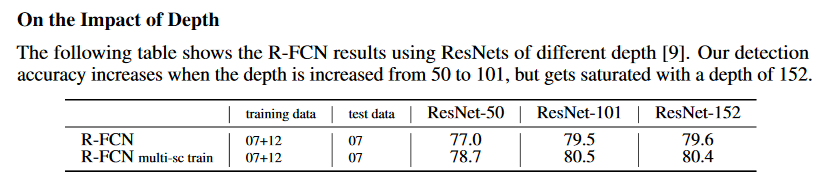
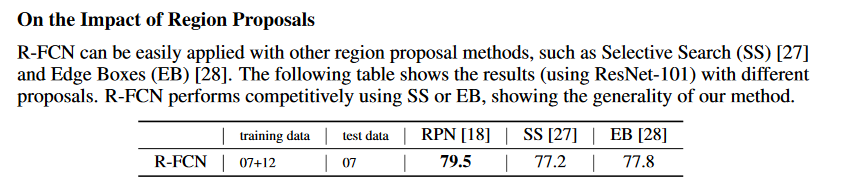
- 候选区域选择算法对比:RPN比SS,EB好。
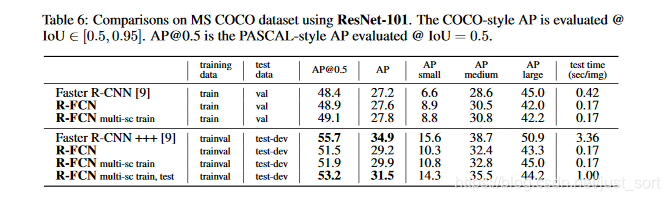
在MS COCO数据集的测试结果¶
可视化效果展示¶

总结¶
R-FCN在Faster-RCNN的基础上致力于解决全连接网络做分类和回归速度过慢的问题,将分类和回归分支换成了全卷积网络,并提出了一个位置敏感ROIPooling用于指定不同特征图是负责检测目标的不同位置,然后ROIPooling之后把不同位置得到的特征图进行组合就能复现原来的位置信息。不仅在精度上大幅度超越Faster-RCNN,并且速度是Faster-RCNN的2倍以上。
附录¶
论文原文:https://arxiv.org/pdf/1605.06409v2.pdf
官方源码复现:https://github.com/daijifeng001/r-fcn
参考资料1:https://www.cnblogs.com/shouhuxianjian/p/7710707.html
参考资料2:https://blog.csdn.net/tuzixini/article/details/78754618
欢迎关注我的微信公众号GiantPandaCV,期待和你一起交流机器学习,深度学习,图像算法,优化技术,比赛及日常生活等。
本文总阅读量次