最新SOTA!利用扩散模型精准识别UDC环境下的面部表情¶
论文标题:LRDif: Diffusion Models for Under-Display Camera Emotion Recognition
论文链接:https://browse.arxiv.org/abs/2402.00250
1. 论文摘要¶
本文提出了LRDif,这是一个基于扩散模型的新颖框架,专门用于屏下相机(UDC)环境中的面部表情识别(FER)。为了解决UDC图像退化带来的固有挑战,例如锐度降低和噪声增加,LRDif采用了两阶段的训练策略,集成了一个简化的预训练提取网络(FPEN)和一个灵活的变换器网络(UDCformer),有效地从UDC图像中识别出情绪标签。LRDif利用扩散模型(DMs)的强大分布映射能力和变换器的空间依赖建模能力,有效地克服了UDC环境中的噪声和失真障碍。LRDif在标准的FER数据集(包括RAF-DB、KDEF和FERPlus)上进行了全面的实验,展示了最先进的性能,突显了其在推进FER应用方面的潜力。这项工作不仅填补了文献中关于UDC挑战在FER领域的重要空白,也为未来的研究设定了一个新的基准。
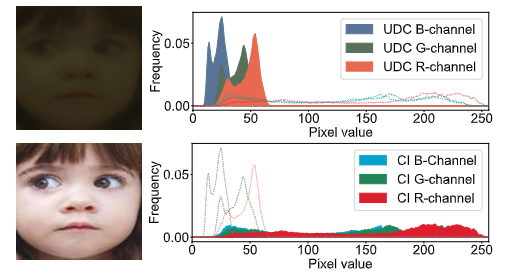
图1:上方:使用屏下相机(UDC)拍摄的图像,与普通相机相比,清晰度较低。下方:使用传统外置相机拍摄的图像,清晰度较高。
2. 背景介绍¶
面部表情识别(FER)在近年来取得了显著的进步。然而,在屏下相机(UDC)环境下实现情绪识别面临着独特的挑战。最根本的挑战在于图像的质量和清晰度。UDC图像通常比传统的外部相机拍摄的图像(如图1所示)具有更低的锐度、更高的噪声和更差的色彩保真度。这些质量限制源于相机镜头位于屏幕下方的事实,这可能以不可预测的方式阻挡光线。对于情绪识别算法,它们严重依赖于面部表情的细微差别,这可能导致准确度降低。 此外,UDC图像可能出现独特的伪影和光照不一致,进一步增加了任务的复杂性。用于情绪识别的机器学习模型需要针对UDC图像进行调整,确保它们能够有效地识别情绪状态,尽管存在额外的噪声和失真。以前关于FER的研究没有充分关注UDC图像带来的额外噪声和失真的影响。然而,解决这个问题对于提高全屏设备的现实应用是至关重要的。
目前,有几种方法可以解决情绪识别领域中的噪声学习问题。RUL通过根据相对难度对面部特征进行加权,解决了由于表情模糊和标签不一致导致的不确定性,提高了在噪声数据环境中的性能。EAC通过利用翻转的语义一致性和选择性擦除输入图像,解决了噪声标签的问题,防止了模型过度关注与噪声标签相关的特定特征。SCN通过采用自注意力机制对训练样本进行加权和重新标记机制对低排名样本的标签进行调整,减轻了大规模数据集中的不确定性,减少了对不确定面部图像的过拟合。然而,这些方法在应用于UDC图像时会遇到限制。具体来说,RUL和 EAC依赖于小损失的假设,这可能导致难样本和噪声样本之间的混淆,因为它们在训练过程中都倾向于表现出高损失值。因此,从噪声标签和图像中学习特征仍然是一项具有挑战性的任务。
为了解决这个问题,本文对噪声UDC图像采用了一个新颖的视角。与传统的基于损失值识别噪声样本的方法不同,本文提出了一种创新的观点,关注通过特征提取从噪声标签中学习。我们的目标是创建一个基于扩散模型的FER系统,利用扩散模型(DMs)的分布映射能力,有效地恢复噪声标签及其对应的图像。为此,我们提出了LRDif。考虑到变换器在捕获长距离像素依赖性方面的熟练程度,我们选择变换器块作为LRDif架构的基础组件。动态变换器块以U-Net风格层叠,构建了屏下相机变换器(UDCformer),旨在进行多层次的特征提取。UDCformer包括两个并行的网络:DTnetwork,它从多个层次的标签和UDC图像中提取潜在特征,以及DIL-network,它学习面部标志和UDC图像之间的相似性。LRDif遵循两阶段的训练过程:(1)最初,如图2(a)所示,我们构建了一个简化的预训练提取网络(FPEN),它从潜在的标签和UDC图像中提取情绪先验表示(EPR)。然后,这个EPR被用来指导UDCformer恢复标签。(2)随后,如图2(b)所示,扩散模型(DM)被训练来直接从UDC图像中推断出精确的EPR。由于EPR Z的轻量性质,DM可以实现高度准确的EPR预测,从而在几次迭代后显著提高测试精度。
3. 方法详解¶
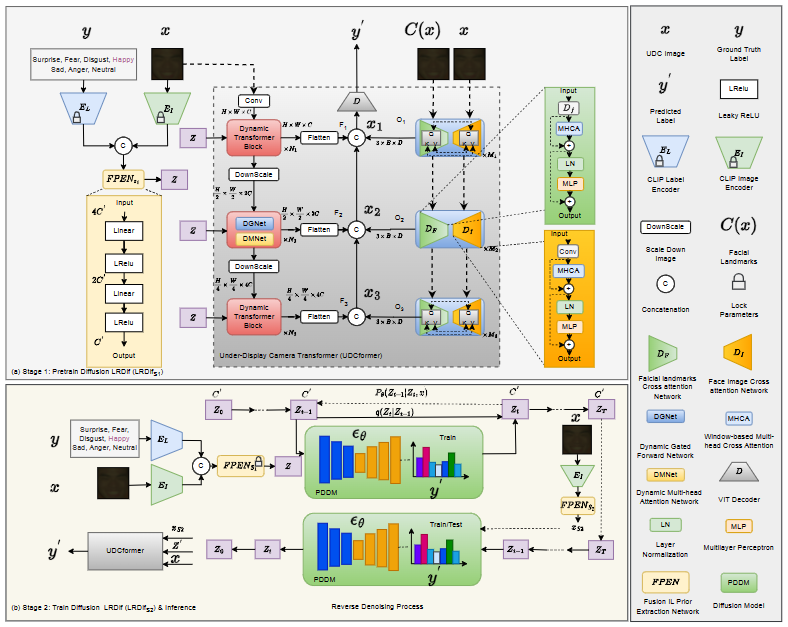
图2:本文提出的LRDif框架,包括UDCformer、FPEN和去噪网络。LRDif分为两个训练阶段:(a) 在第一阶段,FPEN S1对UDC图像和真实情绪标签进行处理,生成EPR Z,用于指导UDCformer恢复标签。(b) 在第二阶段,训练扩散LRDif (LRDif S2)并进行推理。
3.1. 预训练的DT网络¶
第一阶段包含两个基本网络:紧凑的初级提取网络(FPEN)和敏捷的转换器网络(DT网络)。如图2的黄色框所示,FPEN包含几个线性层来提取EPR。之后,DT网络利用这个EPR来恢复标签。 DT网络的架构如图2的红色框所示,包含动态多头转置注意力(DMNet)和门控前馈网络(DGNet)。 在预训练阶段,如图2(a)所示,FPEN_{S1}和DT网络一起训练。我们利用CLIP文本和图像编码器从标签和UDC图像中获得潜在特征,然后将其馈入FPEN_{S1}。FPEN_{S1}的输出是EPR Z \in \mathbb{R}^{C}。这个过程如公式(1)所示:

然后,Z被输入到DGNet和DMNet中,作为可学习的参数帮助标签恢复,如(公式2)所述。

其中,LN指代层规一化,W是全连接层的权重,\odot代表逐元素乘法。
接下来,在DMNet中,我们从整个图像中提取信息。我们使用卷积层将处理过的特征F'转换成三个新的向量,称为查询Q、键K和值V。然后,我们将Q重塑为R^{H''W''}\times C'',K重塑为R^{C''}\times H''W'',V重塑为R^{H''W''}\times C'' 到适合进一步计算的新格式。我们相乘Q和K,这有助于我们的模型理解图像的哪些部分需要关注,创建注意力映射A \in \mathbb{R}^{C''}\times C''。 DMNet中的整个步骤可以总结如下(公式3):
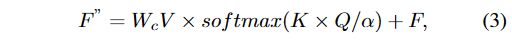
其中\alpha是训练期间的可调参数。 接下来,DGNet通过聚合来学习局部和相邻特征。我们使用一个非常小的Conv(1×1)来合并不同层面的细节,并使用一个略大的Conv(3×3)独立查看每个层,以收集附近像素的细节。 此外,我们使用一个特殊的门来确保捕获最有用的信息。 DGNet中的整个步骤可以概括为(公式4):
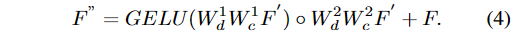
3.2. 动态图像和特征网络(DIL网络)¶
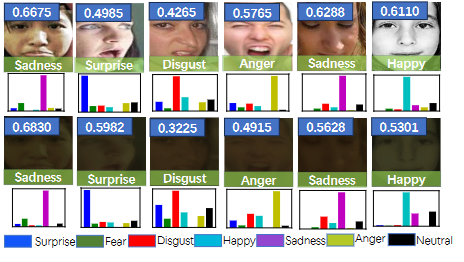
图3:RAF-DB和UDC-RAF-DB数据集中的样本图像。
在DIL网络中,我们采用基于窗口的交叉注意力机制来提取面部特征点和UDC图像的特征。 对于UDC图像特征表示为X_\text{udc} \in \mathbb{R}^{N\times D},我们最初将其分段为几个不同的、不重叠的段x_\text{udc} \in \mathbb{R}^{M\times D}。 对于面部特征点特征表示为X_\text{flm} \in \mathbb{R}^{C\times H \times W},我们缩减其大小以匹配这些段的大小,得到x_\text{flm} \in \mathbb{R}^{c\times h \times w},其中维度c等于D,h和w的乘积等于M。 这使我们能够使用N个注意头在面部特征点和UDC图像特征之间执行交叉注意,如(公式7)详细描述。
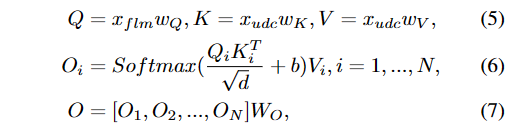
其中W_Q W_K W_V W_O是特征的权重矩阵,b是相关的位置偏差。
这种交叉注意力应用于UDC图像中的每个窗口,我们称之为基于窗口的多头交叉注意力(MHCA)。 LRDif的变压器编码器由以下方程描述(公式9):
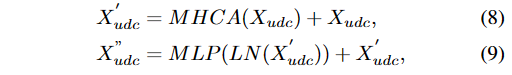
我们需要将来自DT网络的输出特征F与来自DIL网络的输出特征O进行合并,以获得融合的多尺度特征x_1、x_2和x_3,其中x_1 = \text{Concat}(F_1, O_1)、x_2 = \text{Concat}(F_2, O_2)和x_3 = \text{Concat}(F_3, O_3)。 然后,这些融合特征X将输入到vanilla变压器模块中进行进一步处理。
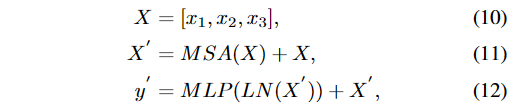
其中MSA是多头自注意力模块。LN是层标准化函数。训练误差定义如下(公式13):
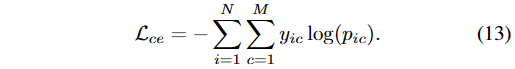
我们使用交叉熵误差训练我们的模型,其中N表示样本总数,M表示类的总数。在此上下文中,y_{ic}表示类c作为样本i的正确标签的存在或不存在(如果正确则为1,否则为0),而p_{ic}表示模型预测样本i属于类c的概率。
3.3. 标签恢复的弥散模型¶
在第二阶段(图2(b)),我们利用强大的DM能力来估计情感先验表示。 最初,我们利用预训练的FPEN_{S1}获得EPR Z \in \mathbb{R}^C。 随后,我们对Z应用弥散过程以生成样本Z_T \in \mathbb{R}^C,如公式(14)详细描述。

在此上下文中,T表示弥散步骤的总数,其中\alpha_t = 1 - \beta_t且\bar{\alpha}_T是从0到T的\alpha_i的累积乘积。术语\beta_t是预定义的超参数,\mathcal{N}(.)代表标准高斯分布。
在DM的反过程中,我们最初利用CLIP图像编码器E_I对输入UDC图像x进行编码(公式15)。 然后,编码后的特征被输入到FPEN_{S2}以从UDC图像中获得条件向量x_{S2} \in \mathbb{R}^C。

其中FPEN_{S2}与FPEN_{S1}共享类似的网络结构。唯一不同的是第一层的维度。去噪网络表示为\epsilon_\theta,它在每个时间步t估计噪声。它以当前嘈杂数据Z'_t、时间步t和条件向量x_{S2}作为输入,后者是通过第二阶段简化的初级提取网络FPEN_{S2}从UDC图像中导出的。然后在下面的方程中使用估计噪声\epsilon_\theta(\text{Concat}(Z'_t, t, x_{S2}))计算下一迭代的去噪数据Z'_{t-1}(公式16):

经过T次迭代后,得到最终估计的情感先验表达(EPR),表示为Z'_0。简化的初级提取网络(第二阶段)FPEN_{S2}、去噪网络和显示器下相机变压器(UDCformer)使用总损失函数L_\text{total}(公式18)进行联合训练。
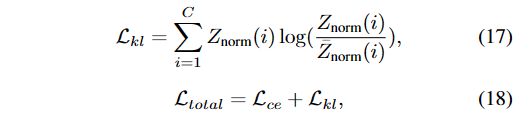
其中Z_\text{norm}(i)和\bar{Z}_\text{norm}(i)分别是由LRDif_{S1}和LRDif_{S2}提取的EPR,都使用softmax操作进行归一化。L_\text{kl}是一种Kullback-Leibler散度变体,在C维上计算。我们将Kullback-Leibler散度损失L_\text{kl}(公式17)和交叉熵损失L_\text{ce}(公式13)组合来计算总损失L_\text{total}(公式18)。 鉴于情感先验表达(EPR)包括通过CLIP编码的UDC图像特征和相关的情绪标签,LRDif第二阶段(LRDif_{S2})能够在有限次数的迭代内实现可靠的估计。 在推理阶段,LRDif不会在反向弥散过程中使用真值标签。
实验结果¶
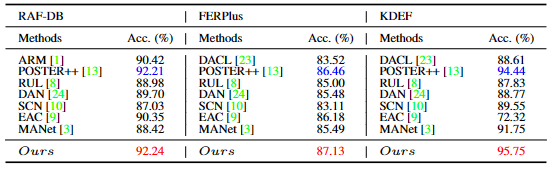
表1:本文提出的FER算法与与当前最先进的FER算法在RAF-DB、FERPlus和KDEF数据集上的准确率对比。

表2:本文提出的FER算法与在UDC-RAF-DB数据集上与最先进结果的准确率(%)对比。

表3:本文提出的FER算法与在UDC-FERPlus数据集上与最先进结果的准确率(%)对比。

表4:本文提出的FER算法与在UDC-KDEF数据集上与最先进结果的准确率(%)对比。

表5:本文提出的FER算法与在UDC-RAF-DB数据集上的准确率(%)。

图4:SCN和LRDif在RAF-DB数据集上训练得到的特征分布。
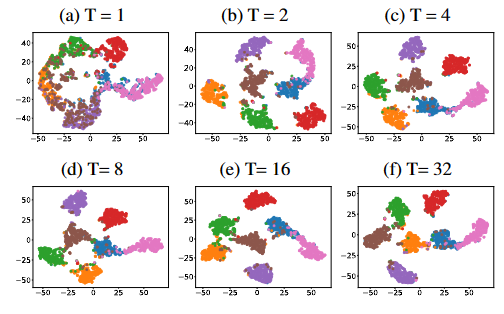
图5:在UDC-KDEF数据集上训练的DM的t-SNE特征可视化。
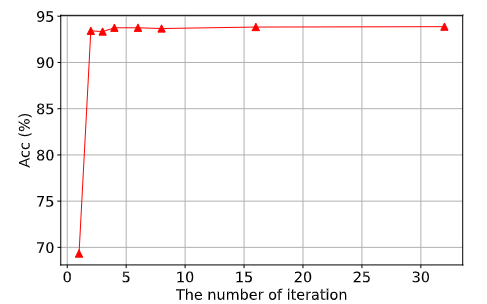
图6:扩散模型中迭代次数的研究。
结论¶
本文介绍了LRDif,用于UDC环境中的FER。LRDif通过两阶段的训练策略,集成了FPEN和UDCformer,克服了UDC图像退化的问题。这些模块使得从退化的UDC图像中有效地恢复情绪标签成为可能。实验结果表明,所提出的DRDif模型表现出优越的性能,在三个UDC面部表情数据集上达到了最新的水平。
本文总阅读量次