前言¶
这篇文章是何恺明组做的一个偏实验的工作,主要是探究ImageNet预训练的模型,在迁移到其他任务比如目标检测,分割等会不会比从头训练模型的要更好。可以总结一下就是 1. 在数据集充分的条件下,各个任务里,从头训练的效果并不比在ImageNet预训练过的要差 2. 从头训练的模型需要更多的迭代次数,才能追上预训练模型Finetune的结果 3. ImageNet预训练的作用更多的是加速模型收敛,但不意味最后模型表现的好 4. 当迁移数据量极少时,ImageNet预训练过的模型表现的要比从头训练的模型要好很多
摘要¶
如今各个任务上,使用ImageNet pretrain的骨干网络进行迁移学习已经是很常见的方法,但不见得用了pretrain的模型就在其他任务上表现的更好。通过我们大量的实验,我们得出了如下的结论 1. ImageNet预训练加快收敛速度,特别是在训练初期阶段。但是从头训练的模型可以通过更多的迭代次数追上来 2. ImageNet预训练不能给模型带来正则化的效果, 当迁移任务的数据量下降很多时,比如COCO的10%数据,我们需要重新调整原有的超参数。然而从头训练的模型在任何数据量情况下都可以以原始的超参数进行训练。 3. 当目标任务对空间更敏感时,ImageNet的预训练没有任何好处
实验方法¶
正则化手段¶
作者首先介绍了Normalization对训练阶段是非常有用的。本次实验只观察BatchNormalization, GroupNormalization, SyncBN(用于多卡)这几种方法
收敛¶
使用了ImageNet预训练的模型进行Finetune,和从零开始训练的模型。所使用的数据是不一样的。为了保证实验更公平,作者从图片数量,实例数量,像素量来做了个比较。
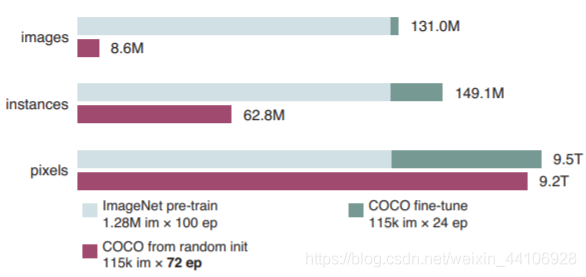
ImageNet预训练100Epoch + finetune 24Epoch的像素数据量级,十分接近于从头训练72个Epoch coco数据集的。
实验设置¶
整体结构¶
我们选用了以Resnet和Resnext+FPN为骨干网络的Mask R-CNN模型。归一化采用SyncBN和GN
学习率调整¶
原始预训练中,Mask RCNN训练90k迭代称为1个schedule,再比如180k称为2个schedule。以此类推,我们再最后60k和20k的iter时,减少十倍学习率。我们发现在第一个相对较大的学习率训练更长的时间,模型效果更好,在小学习率训练时间过长更容易导致模型过拟合
超参数设置¶
使用Warm-up让初始率为0.02, weightdecay=0.0001。使用Momentum优化器,每个GPU的mini batch为2张图片
实验结果与分析¶
从头训练模型¶
让我们惊讶的是,从头训练的模型最终准确率都能追上pretrain+finetuned模型。
比较GN和SyncBN¶
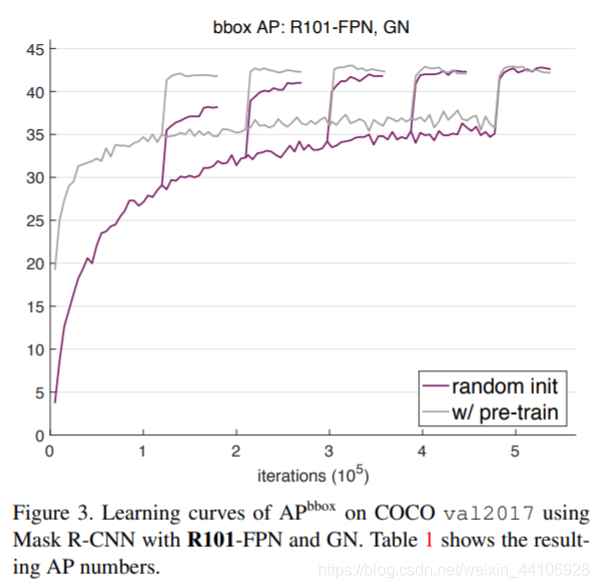
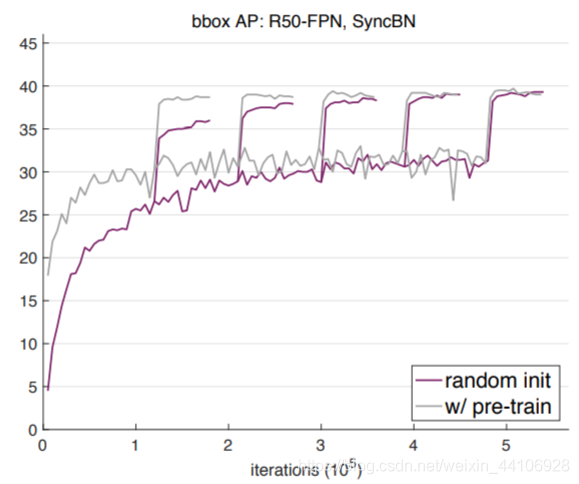
这个图分别是GN和SyncBN的结果。这个图出现的突然提升,就是我们不同schedule下的学习率策略,在不同的iter上调低了10倍学习率的结果。 从中我们可以总结出以下结论 1. 在更少的迭代次数上,ImagePretrain的收敛十分迅速,且效果也不差。而对于从0开始训练的模型,则需要更多的迭代学习 2. 在更多的迭代次数上,从0训练的模型可以追上pretrain+finetune的模型 在COCO数据集上,ImageNet的作用更多的是加速收敛。
多重测量指标¶
我们从锚框和分割这两种指标上,又进行了测试。可以看到从头训练的模型仍能追上Pretrain+Finetune的模型。
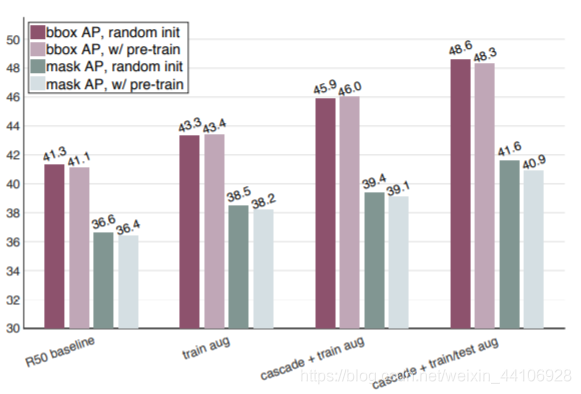
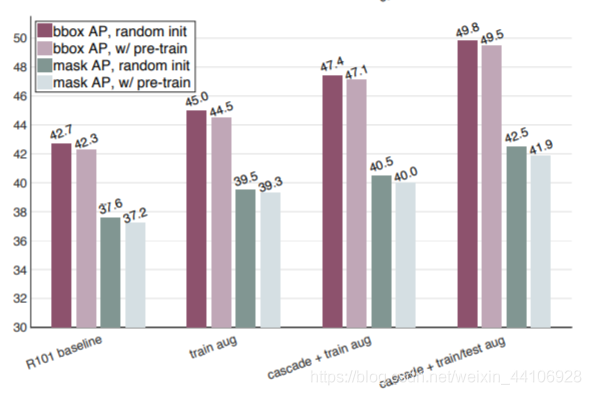
另外我们还使用其他手段对baseline做了增强
训练时图像增广¶
众所周知,图像增广能从数据多样性上增强模型性能,其代价是更多的迭代次数才能收敛。在这个情况下,两个模型都取得了性能上的提升,而从头训练的模型效果更好
Cascade R-CNN¶
Cascade增加了两个额外的阶段,针对不同的IOU阈值进行检测。这将有助于检测的准确性。从实验数据也能看到,从头训练的模型效果更好一点
test-time augumentation¶
这里是指对测试集的图片,做了不同的增广。将不同增广后的图片送入模型,然后取个平均值,作为一种正则化手段。结合了三个方法的模型性能提升尤为明显
更大的模型¶
我们又在更大的模型上Resnext152做了实验,结论还是与先前的一致,预训练并没有带来模型性能的提升
关键点检测¶
我们也使用了MaskRCNN训练了COCO数据集人体关键点检测任务。

在关键点检测任务上,从零训练的model能更快的追上pretrain的结果。因此ImageNet预训练对于关键点检测上提升不大
没有BN/GN的模型-VGG系列¶
Resnet系列的模型需要Normalization才能更好的收敛,而VGG系列可以在正确的初始化下,有不错的收敛效果。 因此我们替换了MaskRCNN的backbone为VGG系列 设定初始学习率为0.02, 学习率衰减10倍,weight decay为0.0001
即使是预训练过的模型,其收敛速度依然很缓慢。在更多的迭代次数上,从头训练的模型才勉强追上来。
因此加入合适的Normalization,对收敛速度提升帮助很大
在更少的数据上训练¶
我们依然在COCO数据集,从35K,10K, 1K的三个数据量级来做对比实验
35K images¶

首先我们保持之前超参不变,在35K数据集上训练。可以看到训练效果明显很差,这也说明ImageNet预训练不能防止过拟合。为了更好的baseline进行对比,我们使用grid search对超参进行搜索,再来做对比实验
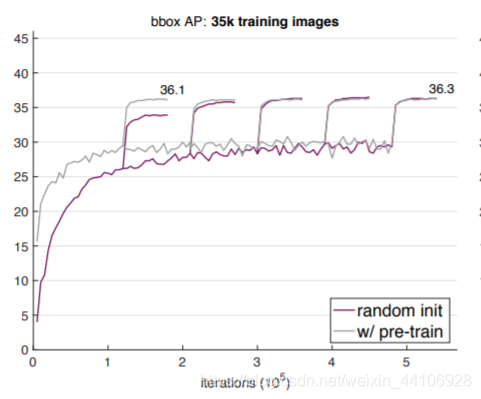
进行了超参调整后,在35K数据集上表现与之前的类似
10K images¶
跟35K 类似,我们重复了实验步骤,并且根据数据量,适当调小了迭代次数
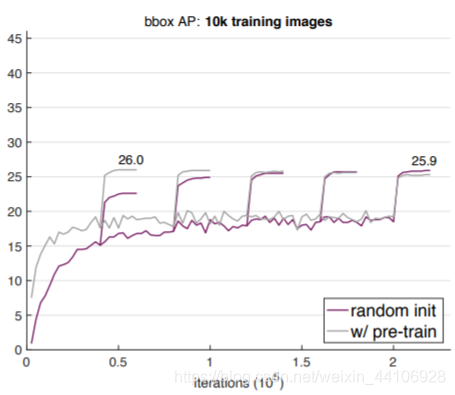
可以看到表现还是很接近的,甚至最后略有超过
断崖式下跌,1K images¶
实验在1K数据量级下,发生了极大的变化
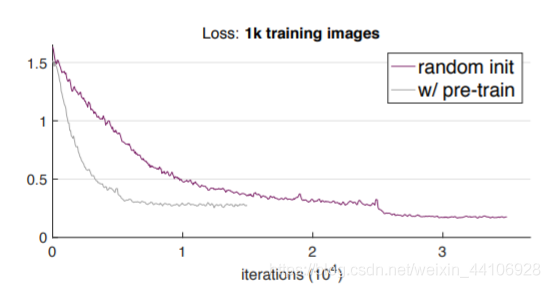
虽然在loss上,从零开始训练的模型loss也能下降到一个不错的值,但是最终评测指标表现十分差
预训练的模型是 9.9AP 而从零开始训练的模型是 3.5AP 由于缺少数据,导致了模型过拟合现象十分严重
同样的现象也出现在PASCAL VOC数据集上
ImageNet预训练模型和从零开始训练的模型的mAP分别是 82.7 和 77.6
讨论与总结¶
- 为了达到相同的性能,从头开始训练的模型需要更多的迭代次数
- 在没有架构更改情况下,可以对目标任务从头开始训练
- 只有在极少图片数目下,从头开始训练的模型性能才会出现明显下降
- ImageNet 预训练 加快模型收敛
- ImageNet不能缓解过拟合现象
- 当目标任务对空间位置更敏感时,ImageNet pretrain所起到的作用会比较小
在笔者看来,训练网络就跟人类学习行为很相似。当我们在相关领域打好基础(Imagenet pretrain),就能很快的学习掌握其他技能(快速收敛)。但是这些基础不一定适用所有课程(预训练不能缓解过拟合)。当我们从头开始学习的时候,需要更多的时间来去弥补基础,最后才能掌握更高难度的题目。如果一开始太专注于难题,去拟合答案(在训练早期就以很小的学习率去学习),我们反而没有完全掌握题目,只是在套公式套答案(模型性能下降)。
最近也有研究说人类的神经元记忆时间有一定时间限制,自监督是未来的主流方向。那么自监督是不是也能结合恺明这篇文章进行更多的延申呢?欢迎读者们进行留言探讨~
本文总阅读量次