SegGPT: Segmenting Everything In Context¶
1. 论文信息¶
标题:SegGPT: Segmenting Everything In Context
作者:Xinlong Wang, Xiaosong Zhang, Yue Cao, Wen Wang, Chunhua Shen, Tiejun Huang
原文链接:https://arxiv.org/pdf/2304.03284.pdf
代码链接:https://github.com/baaivision/Painter
2. 引言¶
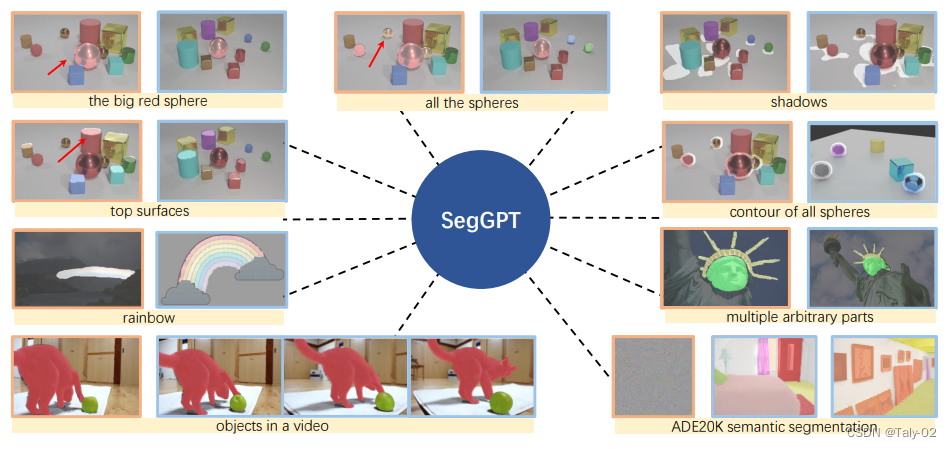
Segmenting是计算机视觉中最基本的问题之一,其目的是在像素级别定位和重新组织有意义的概念,例如前景、类别、对象实例等。近年来,我们见证了在开发更多 用于各种分割任务的准确和更快的算法。 然而,这些专业的分割模型仅限于特定的任务、类、粒度、数据类型等。在适应不同的设置时必须训练新模型,例如分割新概念或分割视频中的对象图像。 这需要昂贵的注释工作,并且对于大量的分割任务来说是不可持续的。
在这项工作中,作者的目标是训练一个能够解决多样化和无限分割任务的单一模型。 主要面临以下两个挑战:
-
在训练中整合那些非常不同的数据类型,例如部分、语义、实例、全景、人物、医学图像、航拍图像等;
-
设计一种不同于传统多任务学习的可泛化训练方案,该方案在任务定义上灵活,能够处理域外任务。
为了应对这些挑战,论文提出了 SegGPT,这是一种用于在上下文中分割所有内容的unify的模型。 我们将segmentation视为视觉感知的通用模式,并将不同的分割任务统一到一个通用的t in-context learning framework。 该framework通过将不同类型的分割数据转换为相同格式的图像来适应它们。而关于SegGPT 的训练过程则非常有意思,它被被定义为了context的coloring问题,每个数据样本具有随机颜色映射。 目的是仅根据上下文为相应区域(例如类、对象实例、部件等)着色。 通过使用随机着色方案,模型被迫参考上下文信息来完成分配的任务,而不是依赖于特定的颜色。 这允许采用更灵活和通用的训练方法。而训练框架也非常简单,就使用普通 ViT和简单的 smooth-ℓ1损失。经过训练后,SegGPT 能够通过上下文推理在给定几个示例的图像或视频中执行不同的分割任务,例如对象实例、内容、部分、轮廓、文本等。为了在上下文中有效地集成多个示例,我们提出 一种简单而有效的上下文集成策略,特征集成,可以帮助模型从多示例提示设置中受益。
3. 方法¶
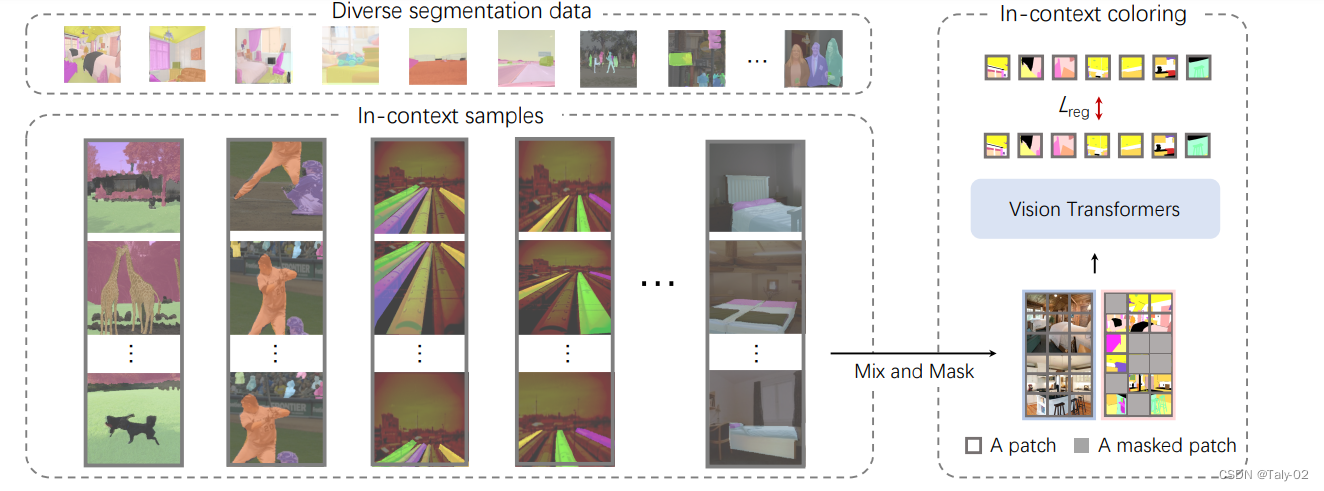
SegGPT 是 Painter框架的特殊版本,它可以使用generalist Painter 对所有内容进行分割,因此我们的模型名称为 SegGPT。 该训练框架将视觉任务的输出空间重新定义为“图像”,并将不同的任务统一为同一个图像修复问题,即随机mask任务输出图像并重建缺失的pixel。 为了保持简单性和通用性,作者没有对架构和损失函数进行修改,即vanilla ViT和简单的 smooth-ℓ1损失,但在上下文训练中设计了一种新的随机着色方案 更好的泛化能力。
3.1 In-Context Coloring¶
在Painter的传统框架中,每个任务的颜色空间都是预定义的,导致solution往往会collapse成为multi-task learning的任务。拟议的上下文内着色随机着色方案包括对另一张具有相似背景的图像进行采样,将颜色映射到随机颜色,并使用混合上下文训练来关注context而不是特定的颜色信息。分段数据集的统一允许根据特定任务制定一致的数据采样策略,为不同的数据类型(例如语义和实例分割)定义不同的上下文,并且使用相同的颜色来指代相同的类别或实例。

3.2 Context Ensemble¶
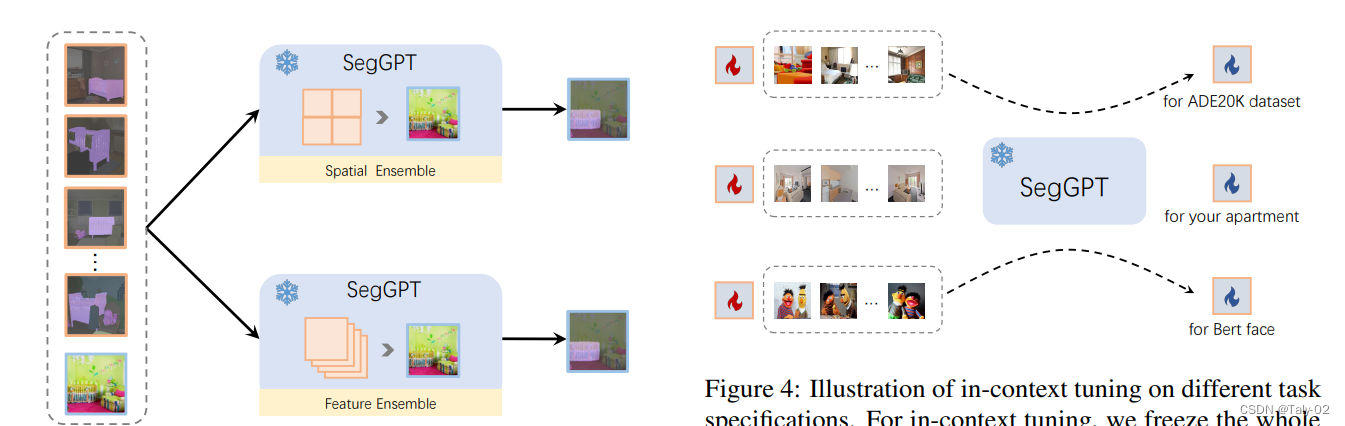
一旦训练完成,这种训练模式就可以在推理过程中释放出来。 SegGPT支持在上下文中进行任意分割,例如,使用单个图像及其目标图像的示例。 目标图像可以是单一颜色(不包括background),也可以是多种颜色,例如,在一个镜头中分割多个类别或感兴趣的对象。 具体来说,给定要测试的输入图像,我们将其与示例图像拼接并将其提供给 SegGPT 以获得相应的context的预测。 为了提供更准确和具体的上下文,可以使用多个示例。 一种称为空间的Ensemble,多个example连接在 n \times n 网格中,然后二次采样到与单个示例相同的大小。 这种方法符合上下文着色的直觉,并且可以在几乎没有额外成本的情况下在上下文中提取多个示例的语义信息。 另一种方法是特征集成。 多个示例在批次维度中组合并独立计算,除了查询图像的特征在每个注意层之后被平均。 通过这种方式,查询图像在推理过程中收集了有关多个示例的信息。
3.3 In-Context Tuning¶
SegGPT 能够在不更新模型参数的情况下适应独特的用例。 我们冻结整个模型并初始化一个可学习的图像张量作为输入上下文。 在训练期间只更新这个可学习的image的vector。其余的训练保持不变,例如,相同的损失函数。 tuning后,作者将学习到的image张量取出来,作为特定应用的即插即用的keys。
4.实验¶
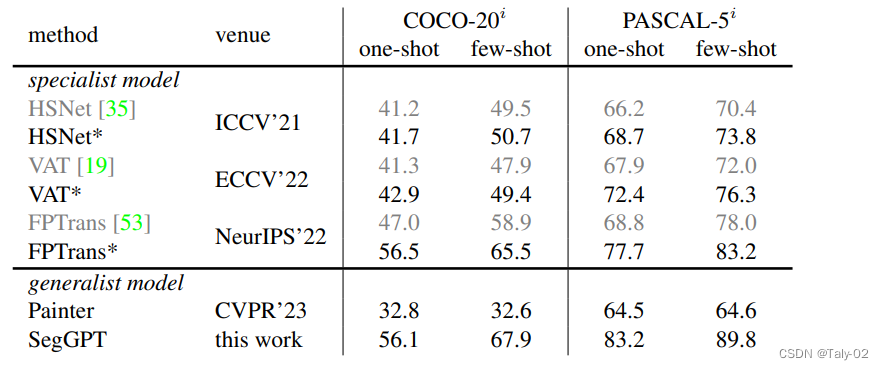
该论文使用了一组不同的分割数据集,包括部分、语义、实例、全景、人、视网膜血管和航空图像分割。作者使用 ADE20K 和 COCO 数据集进行评估。ADE20K 为 150 个语义类别提供分割标签,共有 25K 张图片,包括 20K 训练图像、2K 验证图像和 3K 测试图像。COCO 是一个广泛使用的视觉感知数据集,支持实例分割、语义分割和全景分割。

从可视化的效果也可以看出来本文提出方法的作用。本文介绍了用于图像和视频分割的SegGPT方法,该方法使用一种名为GPT的语言模型根据不同类型的上下文进行分割。作者在多项分割任务上对SegGPT进行了评估,并表明它在域内和域外目标上都表现良好。作者还认为,他们的方法有可能在图像和视频分割中实现更多样化的应用。总体而言,该论文的结果证明了SegGPT在一系列分割任务中的有效性。
5. 讨论¶
本文的贡献是提出了一种名为SegGPT的新方法用于图像和视频分割,该方法使用一种名为GPT的语言模型根据不同类型的上下文进行分割。作者在多项分割任务上对SegGPT进行了评估,并表明它在域内和域外目标上都表现良好。作者还认为,他们的方法有可能在图像和视频分割中实现更多样化的应用。
根据论文中提供的信息,SegGPT 的一些潜在局限性可能包括:
- 需要适当的训练计划才能在不同的分段任务中取得良好的表现。
- SegGPT 在某些类型的分段任务或某些设置中可能表现不佳。
- SegGPT 可能需要大量的计算资源或时间才能有效训练和使用。
- SegGPT 的评估仅限于一组特定的分段任务和数据集,可能无法推广到其他任务或数据集。
值得注意的是,这些限制是基于论文中提供的信息,可能还有其他与使用 SegGPT 相关的限制或挑战,而本文未对此进行讨论。
6. 结论¶
本文提出了一种名为SegGPT的新方法用于图像和视频分割,该方法使用一种名为GPT的语言模型根据不同类型的上下文进行分割。作者在多项分割任务上对SegGPT进行了评估,并表明它在域内和域外目标上都表现良好。作者还认为,他们的方法有可能在图像和视频分割中实现更多样化的应用。但是,作者指出,他们的方法可能有一些局限性,例如需要适当的训练计划,以及在某些类型的分段任务中表现可能较差。
本文总阅读量次