ACCV国际细粒度识别比赛复盘
【GiantPandaCV导语】工作之余参加了一下关于细粒度分类方面的比赛,就个人而言是第一次完整的参加比较大型比赛,虽结果不完美,但收货良多,故复盘总结。
一、背景¶
- 细粒度识别任务不同于普通的图像识别任务,类间差异更小,比如,想要识别狗和袋鼠这个属于普通的识别问题,如果要识别哈士奇和阿拉斯加,这个就是细粒度的范畴,所以对于模型的要求更高,难度更大。

- 本次比赛,是由南京理工大学、英国爱丁堡大学、南京大学、阿德莱德大学、日本早稻田大学等研究机构主办,极市平台提供技术支持的国际性赛事,数据集总共包含了55w训练数据(120G),10w测试数据,数据均来自于网上,包含大量的动物和植物,总计5000个类别,具体链接:https://www.cvmart.net/race。
二、数据分析¶
数据分析是无论是做比赛还是做项目都是非常重要的一个环节,对数据做可视化和量化对于后续的模型优化走向很有帮助,为此我们做了几个简单的分析如下:
1. 数据刚拿到的时候做了一个简单的reveiw,发现训练数据中有很多的噪声和脏样本,这一点对于后期模型的训练有很大的影响。
2. 由于数据是从网络中爬取下来的,做了url校对,发现有2w的图片出现在不同的类别中,大概6w左右具有二义性的图片(同一张图片,存在两个或者两个以上的label)。
3. 对训练数据和测试数据做了url的校验,发现没有存在重复的图片id。(ps:官方这方面做的还可以)
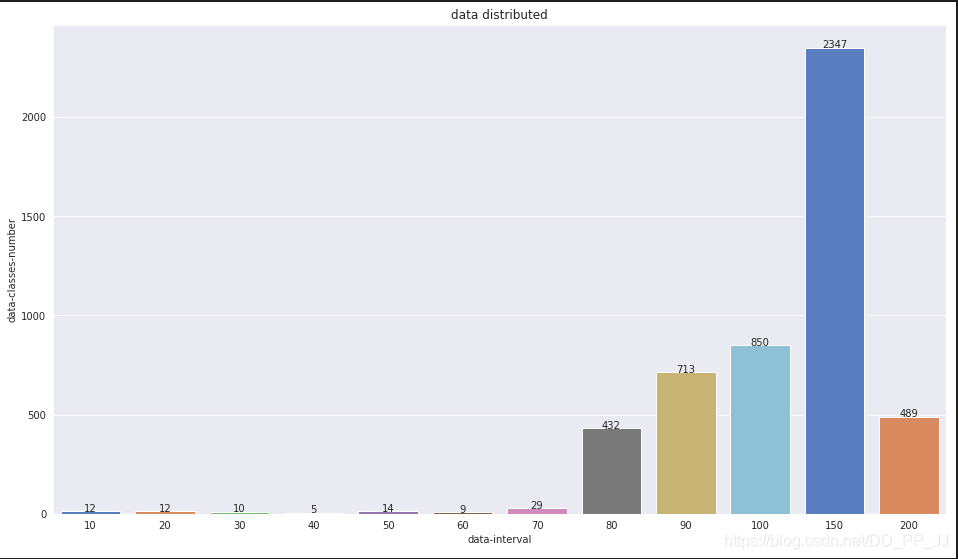
4. 对数据类别样本的占比进行了分析,属于长尾分布,每个类别超过200样本的占比不到10%,100-200样本的占比50%,80-100的占比是40%,剩余的部分是少于80张样本的类别。整体看来长尾分布不算很极端,数据集中在中部地区。
三、baseline¶
1. cub-baseline¶
为了先获取一些细粒度对应的baseline,先在cub-200-2011数据集上训练了几个模型(毕竟我没卡TT):
-
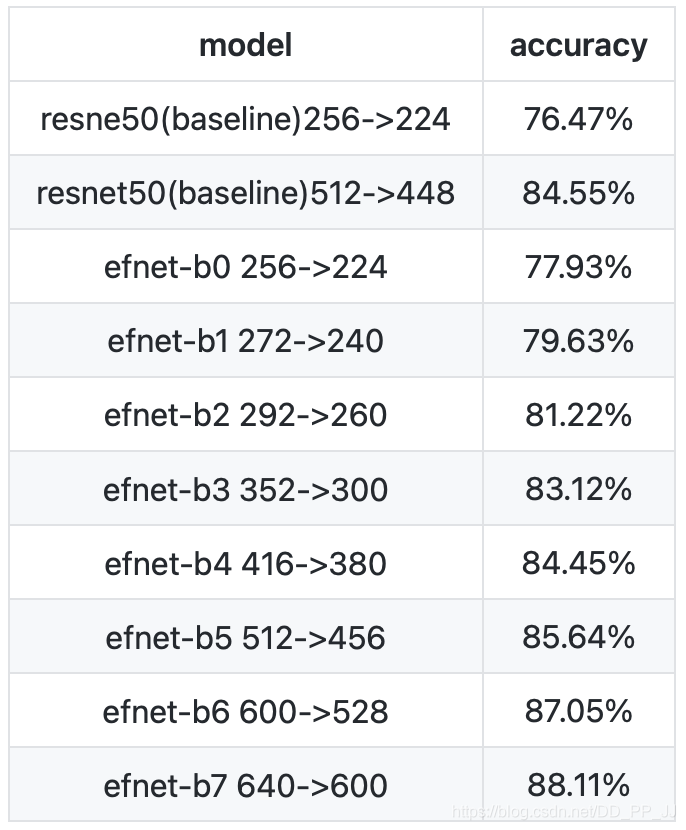
对齐了resnet50_448标准baseline的结果84.56。
-
训练了efnet一系列的模型,cub上的结果如下:
-
初步结论:
-
通过调整r50-448的模型,调好了第一个版本的数据增强的方法,随机crop,翻转,旋转,colorjitter。
- 对于同样的模型,使用448的分辨率效果远远好于224的分辨率。
- 模型越大,效果越好。
2. accv-baseline¶
有了上面的一个初步的结论,我先尝试了cub的数据增强方法,迁移到accv的数据上,在r50-448上得到了一个初步的结果,大概是42左右(小数点不记得了TT),然后有了下面的一系列的调参的工作:
- 使用全量数据进行训练,不进行train-val的划分,主要考虑的是验证数据和测试数据不是ddp的分布,而且缺部分数据会导致性能下降,使用最后一个或者是倒数第二个ckpt作为最终的ckpt。
- 先使用mixup后使用了cutmix,cutmix效果好于mixup。
- cutmix和labelsmooth配合一起使用。
- 训练epoch从25个调整为40个。
- 使用cosinelr来衰减学习率。
- 使用带有动量的sgd优化。
- 使用imagenet做初始化,去掉warmup,使用0.1的初始学习率,调大weight-decay为5e-5。 无效的尝试
- amsoftmax做feature的head,只进行了一次调试,没有效果就没有再继续尝试(理论上应该是有效的,主要因为没有时间和机器来调试)。
- FocalLoss,网上找了一些关于focalloss多类别的实现,效果不是很好,所以写了一个简单版本的,使用了发现没有涨点也没有掉点。
- 带有weights的celoss,weights的方法是采用了类别的samples占比的倒数,没有提升。
- autoagumenet,直接使用imagenet的policy的增强,没有提升。
最终,r50 baseline一顿操作以后达到了47-48这样的一个水平,有效的方法迁移到其他的模型。
四、优化方向¶
有了上面的一些数据分析和模型经验,排了一个优化方向的优先级以及一些实验:
1. 数据
无论什么任务数据都是最重要的一个环节,前面的数据分析已经知道了数九中存在大量的噪声和混淆,所以尝试了几种数据清洗的方法。
- 聚类,用模型获取feature后,对每个类别的feature进行聚类,聚2个类,哪个类别的数据量多就选哪个做为正例,同时按正负样本的比例进行少量负例采样(大概是10%)。
- 检索, 先找出来十几个噪声case,使用feature的余弦距离进行检索,设定阈值和检索最大数量。
- cleanup, 使用cleanup找noise样本和离群样本。
- 丢弃,直接丢弃小于48x48像素的图片,直接丢弃二义性的图片。
结论:检索和丢弃对于提升比较大,聚类和cleanup不好调整。

2. 模型
模型考虑是越大越好,越新越好,调参越少越好(再一次留下了贫穷的泪水TT),尝试了几个系列的模型。
- RegNet, regnety12GF, regnety32GF
- SeResNet, seresnet154
- EfficientNet, efficientnet-b4, efficientnet-b5
- resnest, resnest101, resnest200, resnest269
- inception,inception-v3(inaturelist pretrain)
结论:模型越大效果越好,成本越高(TT)。
3. 算法
算法是最后考虑优化的一个点,调研了很多细粒度方面的文章,基本上核心思想就是不单单要获取整图的feature还要获取各部分part的feature,带来的计算量很大,训练一个r50的时间都要非常久,对于比赛来说收益不高。
- pmg,跑了一下北邮的这个方法,花了一周的时间,效果没有r50-448的baseline效果好。
- Decoupling Representation and Classifier for Long-Tailed Recognition, 固定feature表达后,resample少量数据后进行finetune FC,可以提升一个点左右。
- LDAM-Loss,loss有超参,不太好调整,配合labelsmooth会nan。
- Pseudo-Label,把二义性的数据用模型打上了标签,进行训练,没有提升。
- MaxPool+AveargePool,两个pool的feature进行concat后接FC,没有显著提升。
- FixResolution,对比赛的数据提升不大,但是实际工作上有大概1个点的提升。
结论:比较work的方法基本上就是使用大的size进行finetue,其余的方法可以认为是误差导致没有提升或者微妙的提升。
4. 集成
集成是比较重要的一个环节,理论上单模型的精度越高,单模型之间的一致率越少,模型数量越多,集成的结果越好。
- vote,多个模型logits取众数,如果没有众数,取argmax最高的那个score的作为预测标签。
- mean,多个模型logits取均值,直接1:1加权。
- median,多个模型logits取中位数。
- size,同模型,同数据,不同的size预测结果的logits相加。
- concat, 固定feature,多个模型的feature做concat后,finetune新的FC。
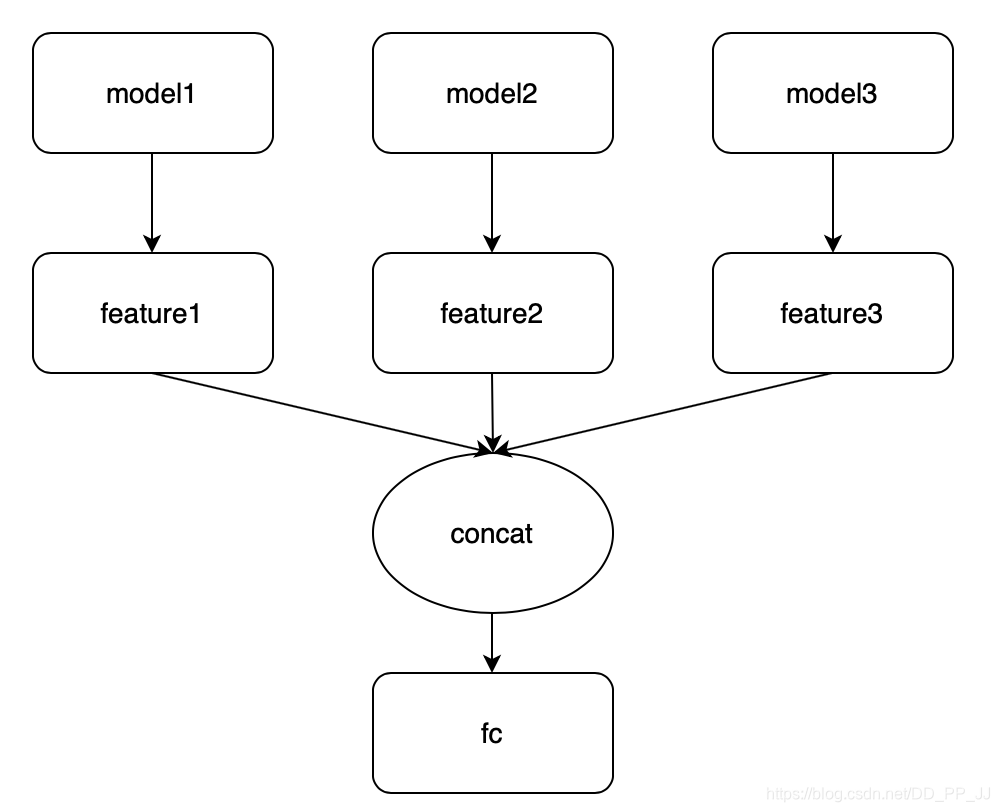
- bilinear,多个模型feature进行split后进行bilinearpool计算,不仅速度慢,还掉点了,emmm。
五、模型方案¶
-
前期就是baseline模型调参和一些算法实验
-
中期就是尝试各种算力范围内的模型,efnet系列,regnet系列,efnet-b5和regnet-12gf进行ensemble后在测试集上有55-56的准确率。
-
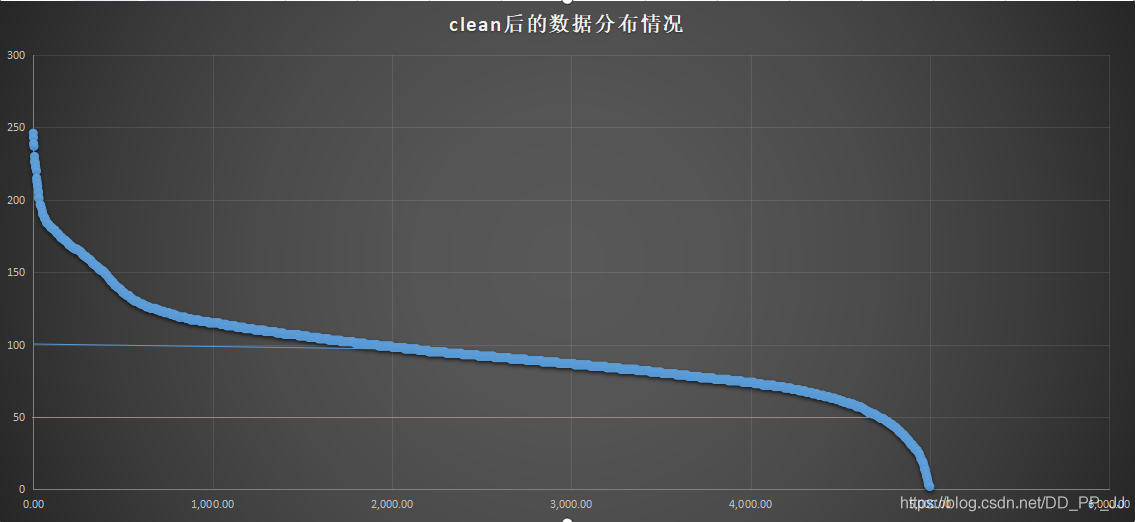
中后期尝试resnest200,efnet-b5,regnet12gf进行ensemble后再测试集上有58的准确率。然后开始使用r200模型来做数据清理的操作,检索一次,跑一次,“滚雪球”一样搞来搞去,搞了3次,大概清洗了1w左右的噪声样本,然后又祛除了二义性的样本,55w的训练数据变成了47w,数据分布情况如下:
-
后期基本上采用的就是resnest一系列的模型,使用最新清洗的训练数据训练了3个模型,resnest101-v3,resnest200-v3,resnest269-v3。同时使用resnest269模型训练了3个不同版本的训练数据,总计6个模型,三个同数据不同结构的模型,三个同结构不同训练数据的模型。
-
快结束了换了测试数据,所以全重新测了一遍,448训练对应的最好测试尺寸应该是512,所以做了一个448+512的集成,测试结果如下:
-
448 + 512 -> resnest269 60.895
- 448 + 512 -> resnest200 61.145
-
448 + 512 -> resnest101 58.17
-
把数据集成模型和不同结构集成模型最终做了一个集成,有63左右的准确率。对不同结构模型做tta处理后有将近64的准确率。
-
后面使用集成模型对测试数据的结果拿来做伪标签,重新训练三个模型,结果如下:
-
r101 448 + 512 -> 60.648
- r200 448 + 512 -> 61.692
-
r269 448 + 512 -> 62.397
-
最终集成的结果是64.587。
六、不足¶
- 模型大小直接影响结果,所以最开始不应该在小模型上进行实验,很多的算法小模型上work并不代表大模型也上work。
- 单模型没有训练饱和,我的训练方法是固定iter总数不变,调整训练的epoch和batchsize,使得,这个方法可以保证快速达到预期的效果,但是还是不能达到模型的上限。
- 使用的同一系列的模型结构,同系列的模型结构存在的问题是对于feature的关注能力是相似的只是量级不同,所以对于ensemble来说,收益不会很高(使用resnest系列存粹是因为我业务模型也用的这个,不想逃离舒适圈而已)。
- 没有使用更大的size进行从头训练,我都是用大的size来进行finetunefc或者最后一个stage,所以提升比较小,不过用更大的size耗费的时间更多。
- 没卡,没时间,没人力。
七、TODO¶
- 数据刚拿到的时候,存在部分数据的前景和背景难以分清,所以考虑用显著性检测的方法来先进行处理,得到mask以后把背景去掉,原图和前景一起输入网络进行训练,方案想好了,还没有尝试,主要没空。建议看一下poolnet的方法,个人感觉还是挺不错的。
- 考虑了把图片进行拼图处理,然后和原图一起输入网络,也没空跑。
- 下好了inature的数据集和butterfly的一个18w的数据集,准备想做无监督的训练,来获取一个细粒度的pretrain的feature,没卡跑。
- 考虑avgool接一个新的512维的fc来做一个constrast loss,结合ce训练,没空跑。
- 更大更强的模型,efficientnet-l2,emmm,跑不动。
- ensemble考虑使用xgboost和randomforest进行二次集成,实在是累了就没做。
- 伪标签,自蒸馏滚雪球,嫌麻烦就做了一次。
八、结束语¶
中后期我还是top-3左右,后面就被大佬们刷测试集给刷没影了,时间,人力还有机器对于结果的导向是显而易见的,预估一下最后的排名大概15名前后吧。不过相比于结果,过程更加重要,在不耽误正常工作的情况下,参加这个比赛,还是锻炼了自己的“炼丹水平”,也对部分知识进行了扩展性学习,受益匪浅。最后附上训练代码的https://github.com/FlyEgle/cub_baseline,欢迎大家交流和指教,有打比赛的也可以找我~。
本文总阅读量次