论文原文¶
https://arxiv.org/pdf/1606.00915.pdf
介绍¶
DeepLabV2是在DeepLab的基础上进行了改进,DeepLab论文请看:https://blog.csdn.net/just_sort/article/details/95354212 。DeepLab使用了空洞卷积增大感受野,CRF条件随机场细化结果,多次度预测的3大Trick使得语义分割模型更加的Dense。而DeepLab V2在Deep Lab的基础上,通过多尺度输入处理或者多孔空间金字塔池化,可以更好的分割样本。
FCN改进¶
FCN进行语义分割时是用500\times500大小的图片,在第一层卷积层conv1_1上使用了大小为100的padding,最终在fc7层得到了一个16\times16的score map。这样的处理稍显粗糙,FCN是第一层将CNN用到图像分割领域,并且是端到端的,在当时也取得了state-of-art的成绩。 DeepLab是将VGG网络的pool4和pool5层的步长由2改成1,这样的改动使得vgg网络总的步长由原来的32变为8,进而使得输入图像变为514\times514,正常padding时能得到67\times67的score map,比FCN得到的要大很多。这种调整又使得要想继续使用vgg model进行fine tuning,会导致感受野发生变化,作者使用空洞卷积解决这个问题。
空洞卷积¶
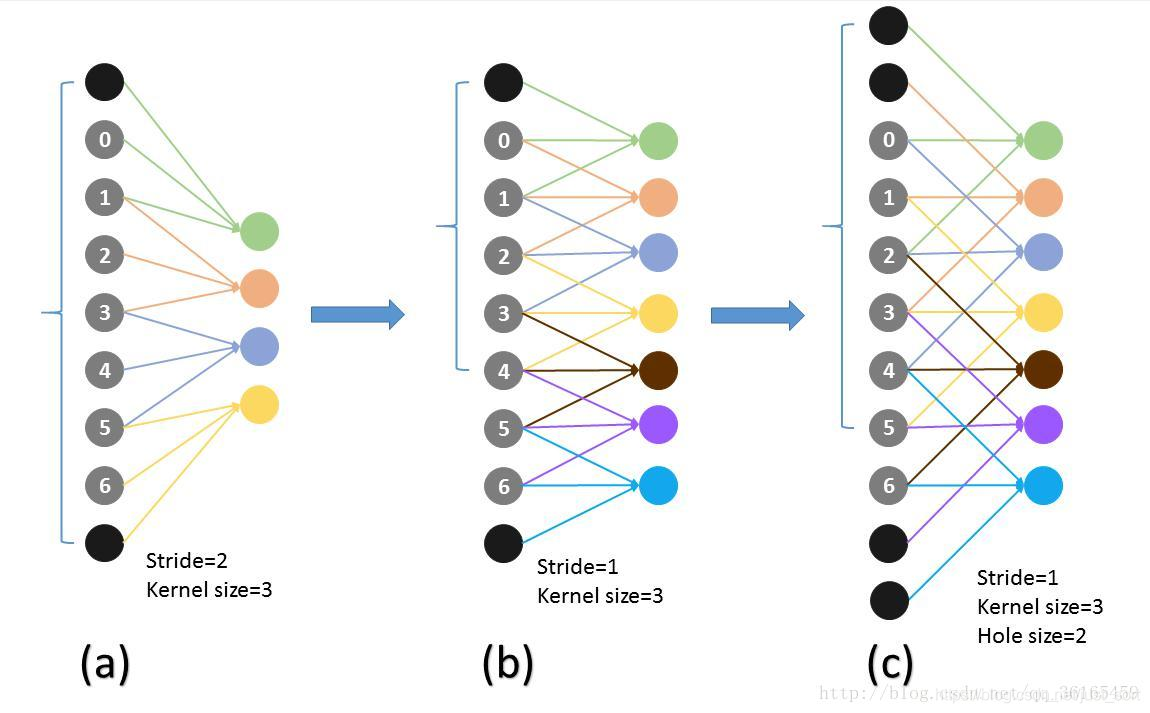
在以前的标准卷积和pooling中,一个filter中相邻的权重作用在feature map上的位置都是物理连续的。Kernel size表示卷积核的大小,Stride表示滑动步长。现在为了保证感受野不发生变化。某一层的stride由2变成1后,后面的层需要采用hole算法,具体来说就是将连续的连接关系根据hole size变成跳连接的。即kernel size的大小虽然还是3,但是这3个是经过hole size跳连接构成的。pool4的stride由2变成1,则紧接着的conv5_1,conv5_2和conv5_3中的hole size为2.接着pool5由2变成1,则后面的fc6中hole size为4。
多孔金字塔池化¶
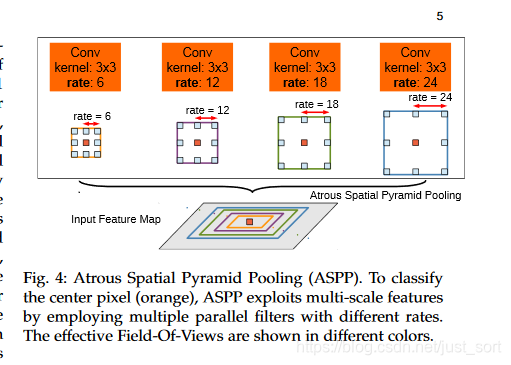
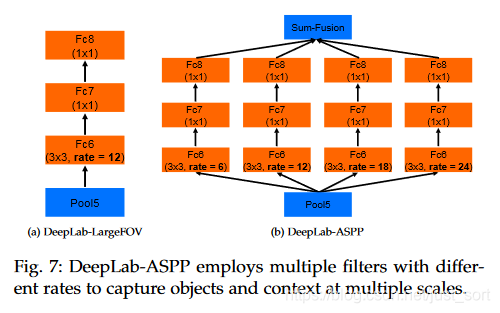
传统方法是把图像强行resize成相同的尺寸,但是这样会导致某些特征扭曲或者消失,这里联想到SIFT特征提取的时候用到过图像金字塔,将图像放缩到不同的尺度,再提取的SIFT特征点具有旋转,平移不变性。因此这里也是借鉴这种方式使用空间金字塔的方法,来实现对图像大小和不同长宽比的处理。这样产生的新的网络,叫做SPP-Net,可以不论图像的大小产生相同大小长度的表示特征。ASPP(多孔金字塔池化)就是通过不同的空洞卷积来对图像进行不同程度的缩放,得到不同大小的输入特征图,因为DeepLab的ASPP拥有不同rate的滤波器,再把子窗口的特征进行池化就生成了固定长度的特征表示。之前需要固定大小的输入图像的原因是全连接层需要固定大小。现在将SPP层接到最后一个卷机后面,SPP层池化特征并且产生固定大小的输出,它的输出再送到全连接层,这样就可以避免在网络的入口处就要求图像大小相同。
CRF¶
见:https://blog.csdn.net/just_sort/article/details/95354212
实验结果¶
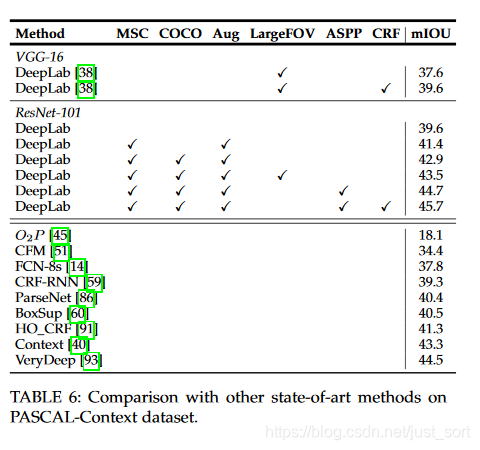
- 通过以下表格数据对比,可以看到CRF 对准确率有较大提升。

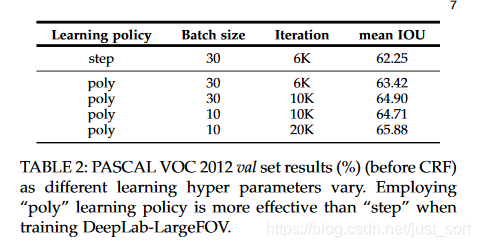
- 通过以下表格数据对比,可以看到较小的batch_size 能够更好的拟合模型,虽然训练次数会增加,因为小的batch_size 学习的过程比较缓慢,迭代次数多一些。
- 通过以下表格数据对比,可以看到ASPP 对于准确率提升是有贡献的。其中ASSP-L 的效果最好。

- 通过以下表格数据对比,可以看到在ResNet-101 网络上的效果比在vgg16上的效果要更好一些,可见VGG16 网络也不是万能的。
代码实现¶
https://github.com/SoonminHwang/caffe-segmentation/tree/master/prototxt
参考博客¶
https://blog.csdn.net/qq_36165459/article/details/78340094 https://zhuanlan.zhihu.com/p/54911894
本文总阅读量次