前言¶
我们前面分享了PCA,Fisher Face,LBPH三种传统的人脸识别算法,Dlib人脸检测算法。今天我们开始分享一下MTCNN算法,这个算法可以将人脸检测和特征点检测结合起来,并且MTCNN的级联结构对现代的人脸识别也产生了很大的影响。上篇为大家介绍MTCNN的算法原理和训练技巧,下篇为大家解析MTCNN算法的代码和进行demo演示。论文地址为:https://arxiv.org/ftp/arxiv/papers/1604/1604.02878.pdf
原理¶
MTCNN是英文Multi-task Cascaded Convolutional Neural Networks的缩写,翻译过来就是多任务级联卷积神经网络。该网络在诞生之初是表现最优的,虽然当前表现已经不是最优的了,但该网络具有很大的意义,第一次将人脸检测和人脸特征点定位结合起来,而得到的人脸特征点又可以实现人脸校正。该算法由3个阶段组成:
- 第一阶段,通过CNN快速产生候选框体。
- 第二阶段,通过更复杂一点的CNN精炼候选窗体,丢弃大量的重叠窗体。
- 第三阶段,使用更强大的CNN,实现候选窗体去留,同时回归5个面部关键点。
第一阶段是使用一种叫做PNet(Proposal Network)的卷积神经网络,获得候选窗体和边界回归向量。同时,候选窗体根据边界框进行校准。然后利用非极大值抑制去除重叠窗体。
第二阶段是使用R-Net(Refine Network)卷积神经网络进行操作,将经过P-Net确定的包含候选窗体的图片在R-Net中训练,最后使用全连接网络进行分类。利用边界框向量微调候选窗体,最后还是利用非极大值抑制算法去除重叠窗体。
第三阶段,使用Onet(Output Network)卷积神经网络进行操作,该网络比R-Net多一层卷积层,功能与R-Net类似,只是在去除重叠候选窗口的同时标定5个人脸关键点位置。
MTCNN网络在经过3个卷积网络处理之前,先进行了多尺度变换,将一幅人脸图像缩放为不同尺寸的图片,这样就构成了图像金字塔。然后这些不同尺度的图像作为3个阶段的输入数据进行训练,这样可以令MTCNN检测到不同尺寸的人脸。MTCNN三个阶段所做的事情如下图:
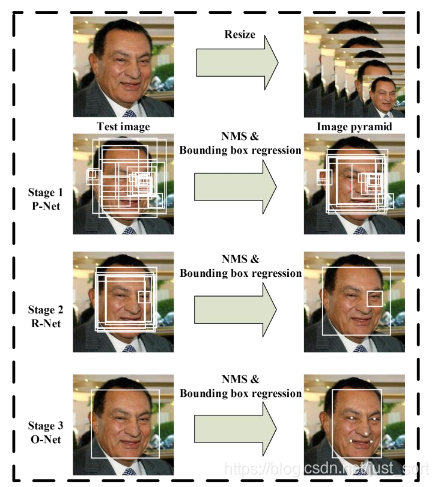
网络结构¶
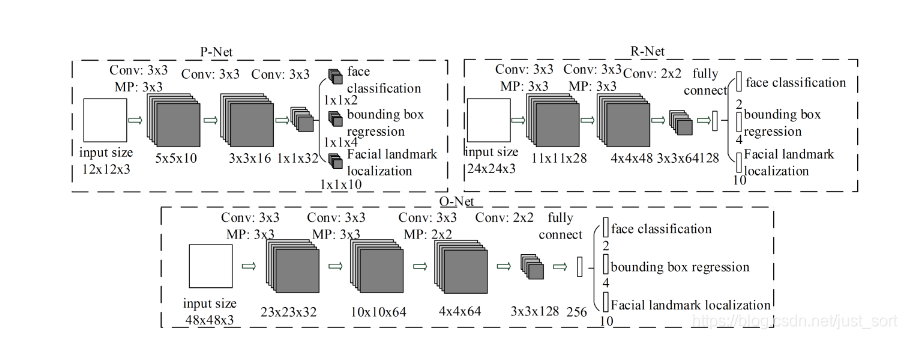
训练¶
MTCNN的训练是一件极为复杂的事,没有真正训练过的人是难以体会其中的困难的。我也只能从理论方面说明一下,有兴趣可以去参与训练一下。
损失函数¶
MTCNN特征描述子主要包括3个部分,分别是人脸-非人脸二分类器、边界框回归、以及人脸特征点。下面分别介绍这3个部分的损失函数。首先要对人脸进行分类,即判断该区域是否包含人脸的二分类器。人脸分类的交叉熵损失函数如下:
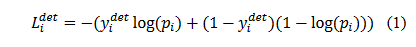
其中,p_i为人脸出现的概率,y_i^{det}为该区域真实标签。 除了判断该区域是否存在人脸之外,我们还希望人脸圈定出来的区域尽可能准确,这自然是一个回归问题,MTCNN使用常见的边界框回归(bounding box regression)来实现。边界框回归采用欧氏距离作为距离度量的损失函数,如下式:
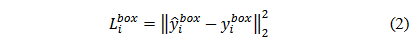
其中,\hat{y}为通过网络预测得到的边框坐标,y为实际的边框坐标,即一个表示矩形区域的四元组,具体形式如下:(X_{left}, Y_{left},Width,Height)
和边界回归过程相同,人脸关键点定位也是一个回归问题,该步骤的损失函数仍然是计算经过预测的关键点位置和实际位置之间的偏差,距离度量使用欧氏距离。关键点定位过程中的损失函数如下:
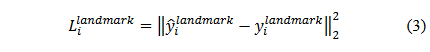
其中,\hat{y_i}^{landmark}为预测结果,{y_i}^{landmark}为实际关键点位置。由于一共需要预测5个人脸关键点,每个点2个坐标值,所以y是10元组。
最终MTCNN要优化的损失为:

其中,N为训练样本数量,\alpha_j表示任务的重要性,\beta_i^j为样本标签,L_i^j为上面的损失函数。作者在训练pnet和rnet的时候,并没有加入landmark回归的任务,分类和人脸框回归的loss_weight之比为1:0.5,onet加入landmark回归,分类、人脸框回归和关键点回归的loss_weight之比为1:0.5:0.5。
在训练过程中,为了取得较好的结果,MTCNN作者每次只反向传播前70%样本的梯度,用以保证传递的都是有效数据。
训练MTCNN复现结果¶
论文中作者主要使用了Wider_face 和CelebA数据库,其中Wider_face主要用于检测任务的训练,CelebA主要用于关键点的训练。训练集分为四种:负样本,正样本 ,部分样本,关键点样本. 三个样本的比例为3: 1: 1: 2。Wider_face包含人脸边框标注数据,大概人脸在20万,CelebA包含边框标注数据和5个点的关键点信息.对于三个网络,提取过程类似,但是图像尺寸不同。
训练包含三大任务,即是:
- 人脸分类任务:利用正样本和负样本进行训练
- 人脸边框回归任务:利用正样本和部分样本进行训练
- 关键点检测任务:利用关键点样本进行训练
正负样本,部分样本,关键点样本提取¶
- 从Wider_face随机选出边框,然后和标注数据计算IOU,如果大于0.65,则为正样本,大于0.4小于0.65为部分样本,小于0.4为负样本。
- 计算边框偏移.对于边框,(x1,y1)为左上角坐标,(x2,y2)为右下角坐标,新剪裁的边框坐标为(xn1,yn1),(xn2,yn2),width,height。则offset_x1 = (x1 - xn1)/width,同上,计算另三个点的坐标偏移。
- 对于正样本,部分样本均有边框信息,而对于负样本不需要边框信息。
- 从celeba中提取关键点样本,可以根据标注的边框,在满足正样本的要求下,随机裁剪出图片,然后调整关键点的坐标。
Caffe训练Loss修改¶
由于训练过程中需要同时计算3个loss,但是对于不同的任务,每个任务需要的loss不同。所有在整理数据中,对于每个图片进行了15个label的标注信息。具体如下:
1.第1列:为正负样本标志,1正样本,0负样本,2部分样本,3关键点信息 2.第2-5列:为边框偏移,为float类型,对于无边框信息的数据,全部置为-1 3.第6-15列:为关键点偏移,为floagt类型,对于无边框信息的数据,全部置为-1
所以,我们需要修改softmax_loss_layer.cpp增加判断,只对于1,0计算loss值,修改euclidean_loss_layer.cpp 增加判断,对于置为-1的不进行loss计算。
困难样本选择¶
论文中作者对与人脸分类任务,采用了在线困难样本选择,实现过程如下:修改softmax_loss_layer.cpp,根据计算出的loss值,进行排序,只对于70%的值较低的数据。
MTCNN训练自己的数据¶
这一部分已经有非常多的开源代码了,可以白用,推荐下面这一个:https://github.com/dlunion/mtcnn。训练非常方便,并且有一个配套的纯c++版本的mtcnn-light,非常利于进行源码理解,我的MTCNN算法详解下篇即会深入到该代码中进行源码解析。
后记¶
虽然MTCNN当时取得了人脸检测的最高SOAT结果,但是技术的发展是非常快的,当前在人脸检测权威数据集WIDER FACE上,MTCNN的前列已经有比较多了。WIDER FACE的官方地址如下:http://mmlab.ie.cuhk.edu.hk/projects/WIDERFace/WiderFace_Results.html,我们从下面的PR曲线看出这点。(这三张图像分别代表针对不同难度的样本的PR曲线)可以看出DFS算法真的很棒啊,有机会看一看?
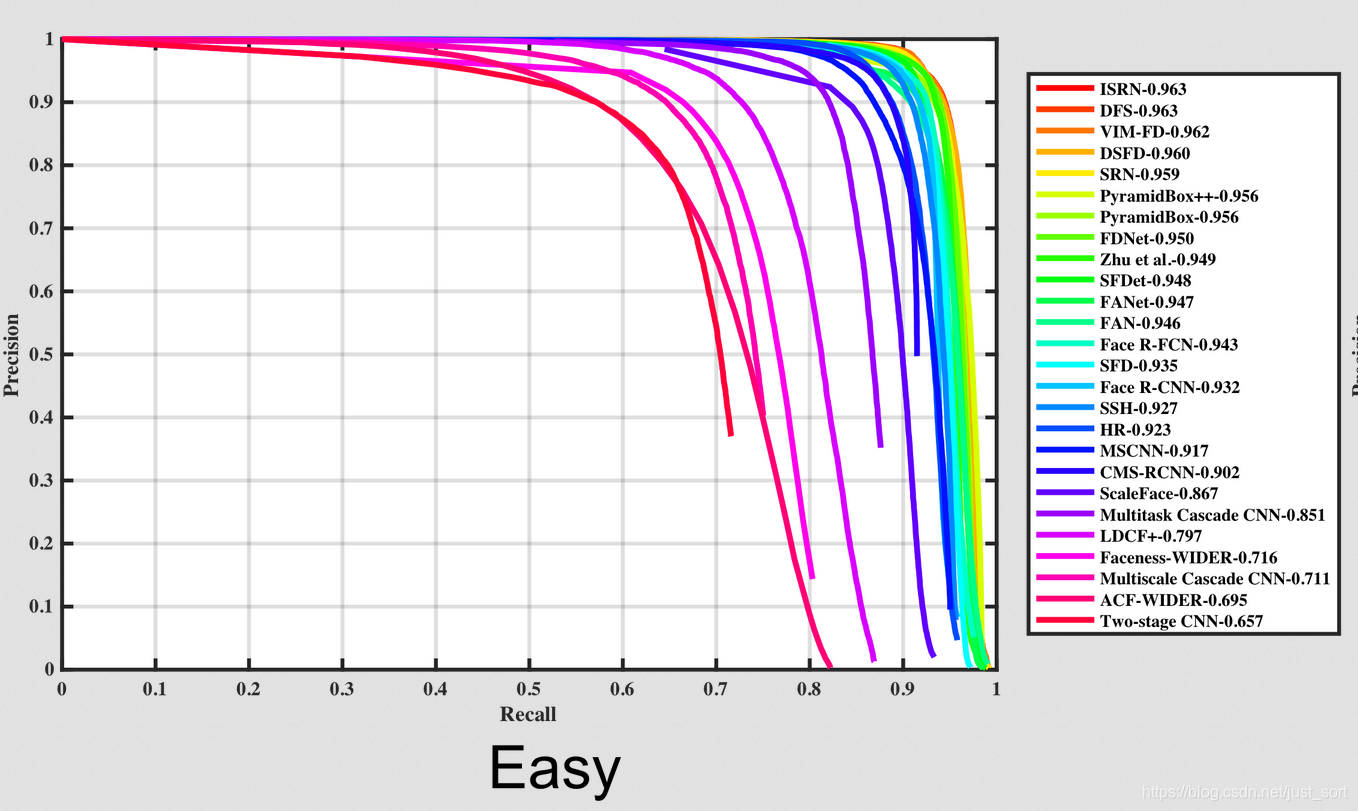
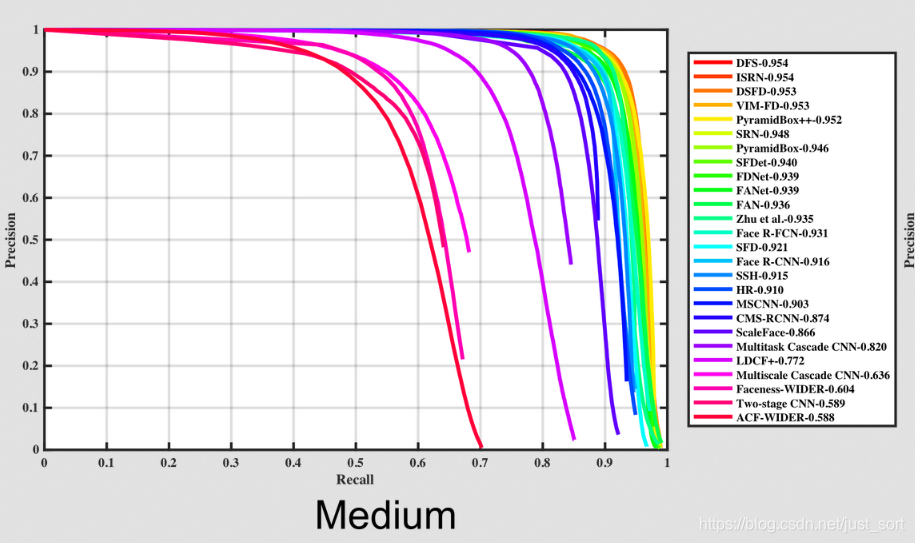
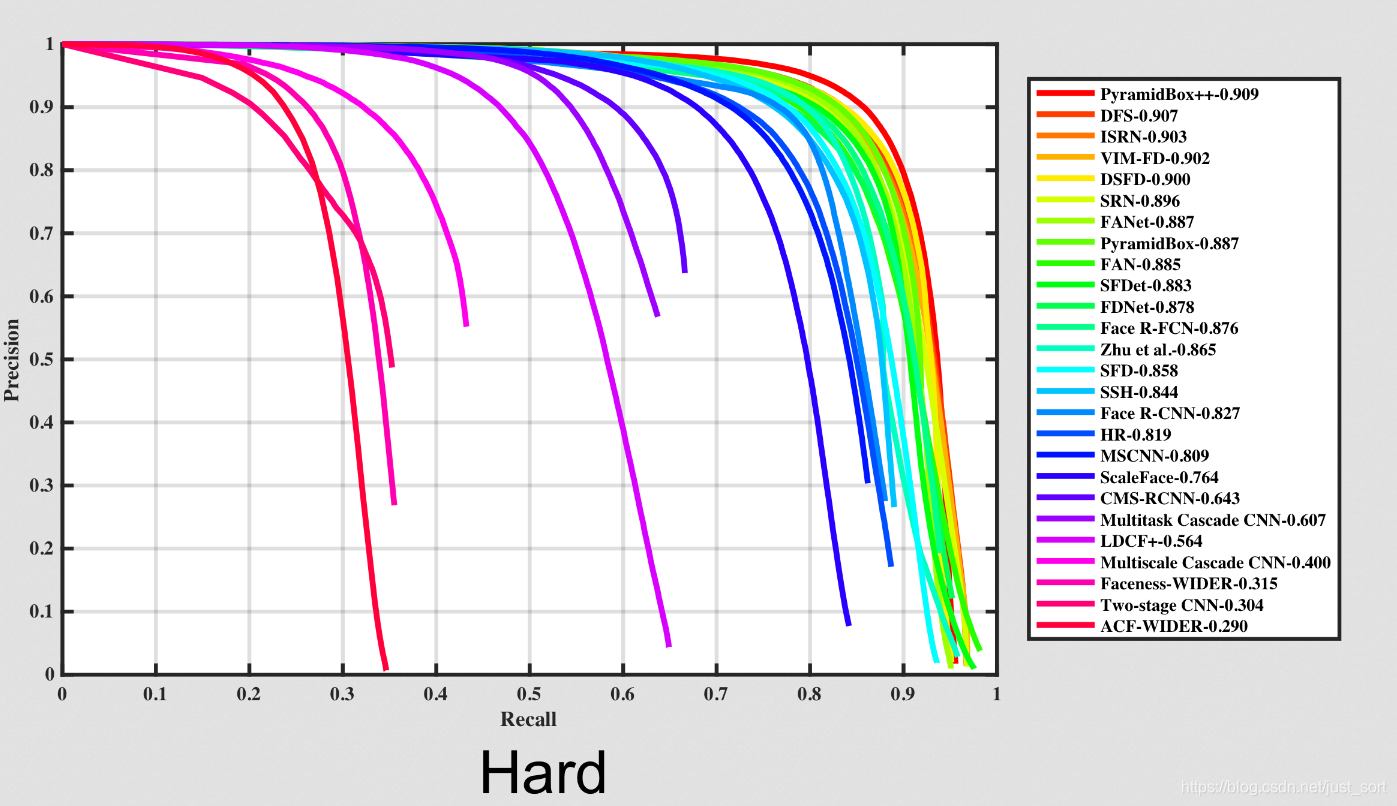 ---------------------------------------------------------------------------
---------------------------------------------------------------------------
欢迎关注我的微信公众号GiantPadaCV,期待和你一起交流机器学习,深度学习,图像算法,优化技术,比赛及日常生活等。
本文总阅读量次