【知识蒸馏】Knowledge Review¶
【GiantPandaCV引言】 知识回顾(KR)发现学生网络深层可以通过利用教师网络浅层特征进行学习,基于此提出了回顾机制,包括ABF和HCL两个模块,可以在很多分类任务上得到一致性的提升。
摘要¶
知识蒸馏通过将知识从教师网络传递到学生网络,但是之前的方法主要关注提出特征变换和实施相同层的特征。
知识回顾Knowledge Review选择研究教师与学生网络之间不同层之间的路径链接。
简单来说就是研究教师网络向学生网络传递知识的链接方式。
代码在:https://github.com/Jia-Research-Lab/ReviewKD
KD简单回顾¶
KD最初的蒸馏对象是logits层,也即最经典的Hinton的那篇Knowledge Distillation,让学生网络和教师网络的logits KL散度尽可能小。
随后FitNets出现开始蒸馏中间层,一般通过使用MSE Loss让学生网络和教师网络特征图尽可能接近。
Attention Transfer进一步发展了FitNets,提出使用注意力图来作为引导知识的传递。
PKT(Probabilistic knowledge transfer for deep representation learning)将知识作为概率分布进行建模。
Contrastive representation Distillation(CRD)引入对比学习来进行知识迁移。
以上方法主要关注于知识迁移的形式以及选择不同的loss function,但KR关注于如何选择教师网络和学生网络的链接,一下图为例:

(a-c)都是传统的知识蒸馏方法,通常都是相同层的信息进行引导,(d)代表KR的蒸馏方式,可以使用教师网络浅层特征来作为学生网络深层特征的监督,并发现学生网络深层特征可以从教师网络的浅层学习到知识。
教师网络浅层到深层分别对应的知识抽象程度不断提高,学习难度也进行了提升,所以学生网络如果能在初期学习到教师网络浅层的知识会对整体有帮助。
KR认为浅层的知识可以作为旧知识,并进行不断回顾,温故知新。如何从教师网络中提取多尺度信息是本文待解决的关键:
-
提出了Attention based fusion(ABF) 进行特征fusion
-
提出了Hierarchical context loss(HCL) 增强模型的学习能力。
Knowledge Review¶
形式化描述¶
X是输入图像,S代表学生网络,其中\left(\mathcal{S}_{1}, \mathcal{S}_{2}, \cdots, \mathcal{S}_{n}, \mathcal{S}_{c}\right)代表学生网络各个层的组成。
Ys代表X经过整个网络以后的输出。\left(\mathbf{F}_{s}^{1}, \cdots, \mathbf{F}_{s}^{n}\right)代表各个层中间层输出。
那么单层知识蒸馏可以表示为:
M代表一个转换,从而让Fs和Ft的特征图相匹配。D代表衡量两者分布的距离函数。
同理多层知识蒸馏表示为:
以上公式是学生和教师网络层层对应,那么单层KR表示方式为:
与之前不同的是,这里计算的是从j=1 to i 代表第i层学生网络的学习需要用到从第1到i层所有知识。
同理,多层的KR表示为:
Fusion方式设计¶
已经确定了KR的形式,即学生每一层回顾教师网络的所有靠前的层,那么最简单的方法是:
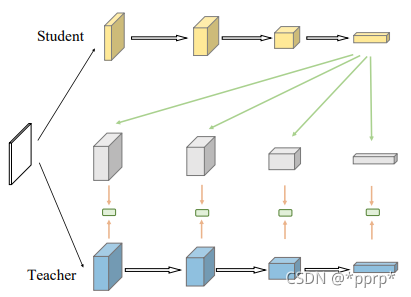
直接缩放学生网络最后一层feature,让其形状和教师网络进行匹配,这样\mathcal{M}_s^{i,j}可以简单使用一个卷积层配合插值层完成形状的匹配过程。这种方式是让学生网络更接近教师网络。
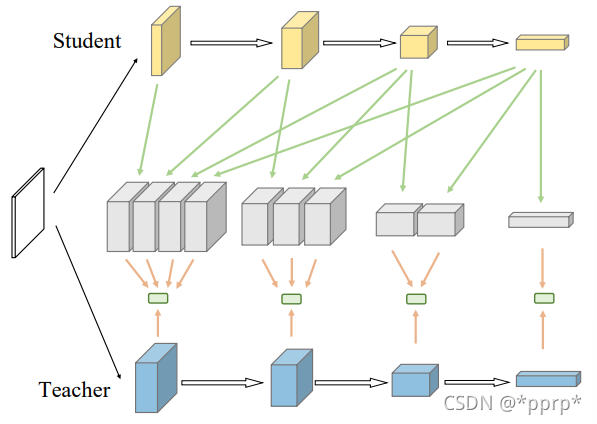
这张图表示扩展了学生网络所有层对应的处理方式,也即按照第一张图的处理方式进行形状匹配。
这种处理方式可能并不是最优的,因为会导致stage之间出现巨大的差异性,同时处理过程也非常复杂,带来了额外的计算代价。
为了让整个过程更加可行,提出了Attention based fusion $\mathcal{U} $, 这样整体蒸馏变为:
如果引入了fusion的模块,那整体流程就变为下图所示:
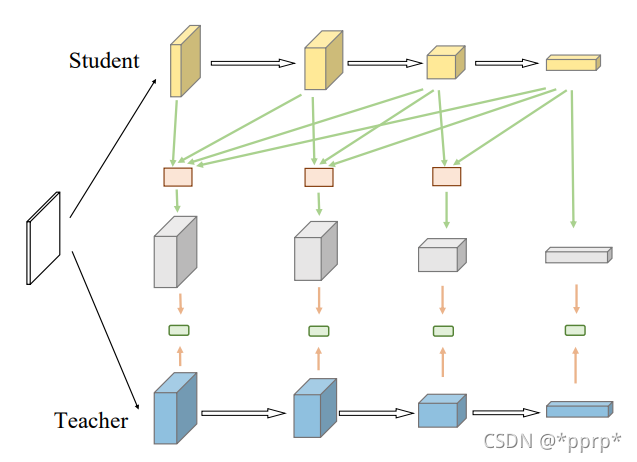
但是为了更高的效率,再对其进行改进:

可以发现,这个过程将fusion的中间结果进行了利用,即\mathbf{F}_{s}^{j} \text { and } \mathcal{U}\left(\mathbf{F}_{s}^{j+1}, \cdots, \mathbf{F}_{s}^{n}\right), 这样循环从后往前进行迭代,就可以得到最终的loss。
具体来说,ABF的设计如下(a)所示,采用了注意力机制融合特征,具体来说中间的1x1 conv对两个level的feature提取综合空间注意力特征图,然后再进行特征重标定,可以看做SKNet的空间注意力版本。
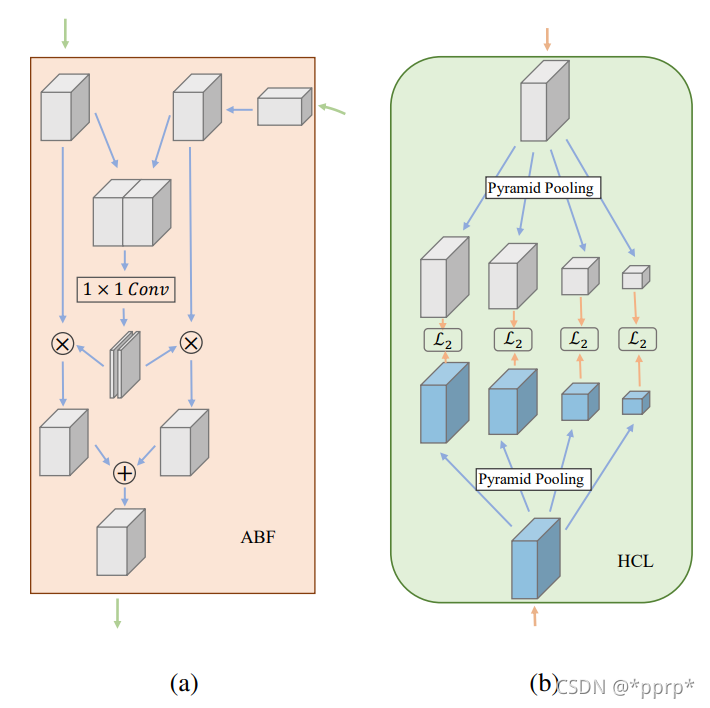
而HCL Hierarchical context loss 这里对分别来自于学生网络和教师网络的特征进行了空间池化金字塔的处理,L2 距离用于衡量两者之间的距离。
KR认为这种方式可以捕获不同level的语义信息,可以在不同的抽象等级提取信息。
实验¶
实验部分主要关注消融实验:
第一个是使用不同stage的结果:
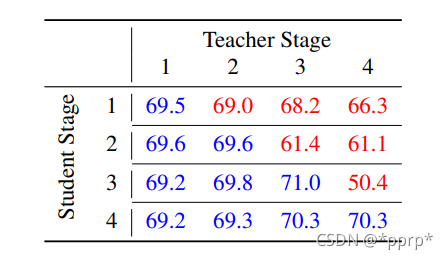
蓝色的值代表比baseline 69.1更好,红色代表要比baseline更差。通过上述结果可以发现使用教师网络浅层知识来监督学生网络深层知识是有效的。
第二个是各个模块的作用:
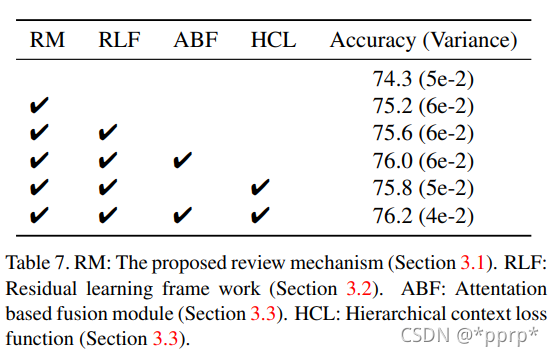
源码¶
主要关注ABF, HCL的实现:
ABF实现:
class ABF(nn.Module):
def __init__(self, in_channel, mid_channel, out_channel, fuse):
super(ABF, self).__init__()
self.conv1 = nn.Sequential(
nn.Conv2d(in_channel, mid_channel, kernel_size=1, bias=False),
nn.BatchNorm2d(mid_channel),
)
self.conv2 = nn.Sequential(
nn.Conv2d(mid_channel, out_channel,kernel_size=3,stride=1,padding=1,bias=False),
nn.BatchNorm2d(out_channel),
)
if fuse:
self.att_conv = nn.Sequential(
nn.Conv2d(mid_channel*2, 2, kernel_size=1),
nn.Sigmoid(),
)
else:
self.att_conv = None
nn.init.kaiming_uniform_(self.conv1[0].weight, a=1) # pyre-ignore
nn.init.kaiming_uniform_(self.conv2[0].weight, a=1) # pyre-ignore
def forward(self, x, y=None, shape=None, out_shape=None):
n,_,h,w = x.shape
# transform student features
x = self.conv1(x)
if self.att_conv is not None:
# upsample residual features
y = F.interpolate(y, (shape,shape), mode="nearest")
# fusion
z = torch.cat([x, y], dim=1)
z = self.att_conv(z)
x = (x * z[:,0].view(n,1,h,w) + y * z[:,1].view(n,1,h,w))
# output
if x.shape[-1] != out_shape:
x = F.interpolate(x, (out_shape, out_shape), mode="nearest")
y = self.conv2(x)
return y, x
HCL实现:
def hcl(fstudent, fteacher):
# 两个都是list,存各个stage对象
loss_all = 0.0
for fs, ft in zip(fstudent, fteacher):
n,c,h,w = fs.shape
loss = F.mse_loss(fs, ft, reduction='mean')
cnt = 1.0
tot = 1.0
for l in [4,2,1]:
if l >=h:
continue
tmpfs = F.adaptive_avg_pool2d(fs, (l,l))
tmpft = F.adaptive_avg_pool2d(ft, (l,l))
cnt /= 2.0
loss += F.mse_loss(tmpfs, tmpft, reduction='mean') * cnt
tot += cnt
loss = loss / tot
loss_all = loss_all + loss
return loss_all
ReviewKD实现:
class ReviewKD(nn.Module):
def __init__(
self, student, in_channels, out_channels, shapes, out_shapes,
):
super(ReviewKD, self).__init__()
self.student = student
self.shapes = shapes
self.out_shapes = shapes if out_shapes is None else out_shapes
abfs = nn.ModuleList()
mid_channel = min(512, in_channels[-1])
for idx, in_channel in enumerate(in_channels):
abfs.append(ABF(in_channel, mid_channel, out_channels[idx], idx < len(in_channels)-1))
self.abfs = abfs[::-1]
self.to('cuda')
def forward(self, x):
student_features = self.student(x,is_feat=True)
logit = student_features[1]
x = student_features[0][::-1]
results = []
out_features, res_features = self.abfs[0](x[0], out_shape=self.out_shapes[0])
results.append(out_features)
for features, abf, shape, out_shape in zip(x[1:], self.abfs[1:], self.shapes[1:], self.out_shapes[1:]):
out_features, res_features = abf(features, res_features, shape, out_shape)
results.insert(0, out_features)
return results, logit
参考¶
https://zhuanlan.zhihu.com/p/363994781
https://arxiv.org/pdf/2104.09044.pdf
https://github.com/dvlab-research/ReviewKD
本文总阅读量次