 @[toc]
@[toc]
前言¶
这是卷积神经网络学习路线的第16篇文章,介绍ICLR 2017的SqueezeNet。近些年来深层卷积网络的主要方向集中于提高网络的准确率。而对于相同的正确率,更小的CNN架构可以提供如下优势:
(1)在分布式训练中,与服务器通信需求更小。
(2)参数更少,从云端下载模型的数据量少。
(3)更适合在FPGA等内存受限的设备上部署。
基于这些优点,这篇论文提出了SqueezeNet。它在ImageNet上实现了和AlexNet相同的准确率,但是只使用了AlexNet\frac{1}{50}的参数。更进一步,使用模型压缩技术,可以将SqueezeNet压缩到0.5M,这是AlexNet的\frac{1}{510}。
SqueezeNet细节¶
结构设计技巧¶
- (1)使用1\times 1卷积代替3\times 3卷积:参数减少为原来的1/9。
- (2)减少输入通道数量:这一部分使用
squeeze层来实现。 - (3)将下采样操作延后,可以给卷积层提供更大的特征图:更大的激特征图保留了更多的信息,可以获得更高的分类准确率
- 其中,(1)和(2)可以显著减少参数数量,(3)可以在参数数量受限的情况下提高准确率。
FIRE MODULE¶
Fire Module是SqueezeNet中的基础构建模块,Fire Module如Figure1所示 :
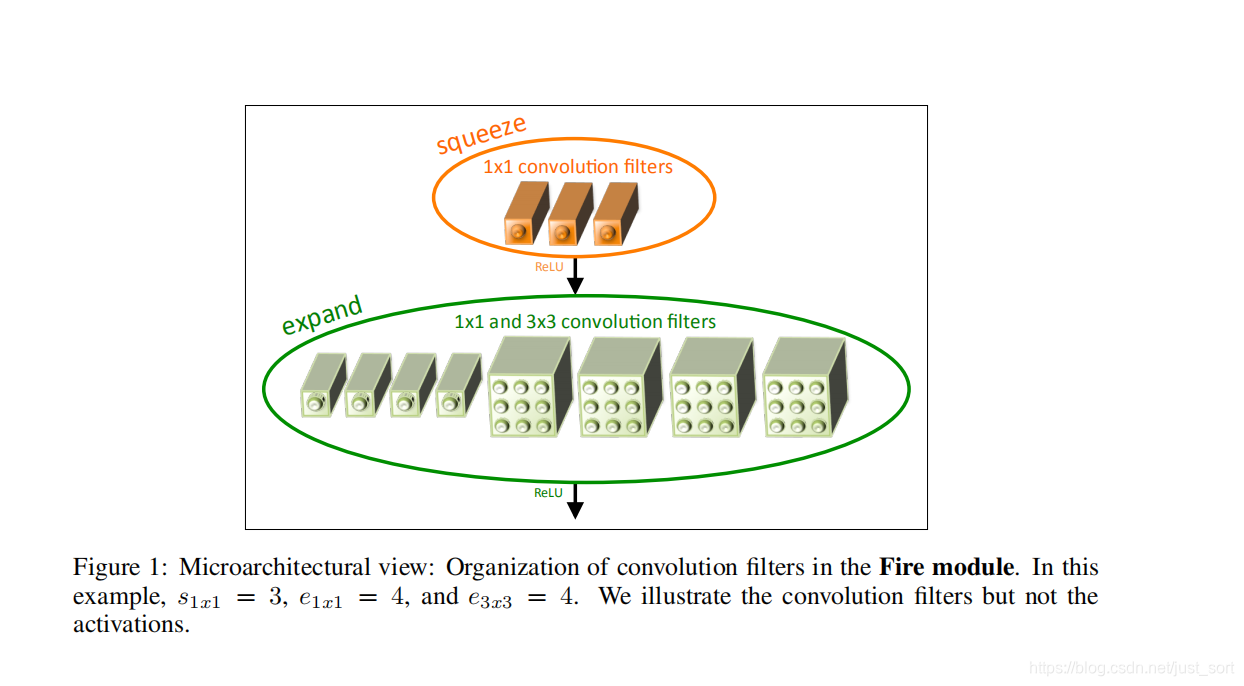
squeeze convolution layer:只使用1\times1卷积核,即上面提到的策略(1)。expand layer:使用1\times1和3\times3卷积核的组合。- Fire module中有
3个可调的超参数:s_{1\times 1}(squeeze convolution layer中1\times 1 卷积核的个数),e_{1\times 1}(expand layer中1\times 1卷积核的个数),e_{3\times 3}(expand layer中3\times 3卷积核的个数) - 使用Fire Module的过程中,令s_{1\times 1} < e_{1\times 1}+e_{3\times 3},这样
squeeze layer可以限制输入通道数量,即结构设计技巧提到的技巧(2)。
网络结构¶
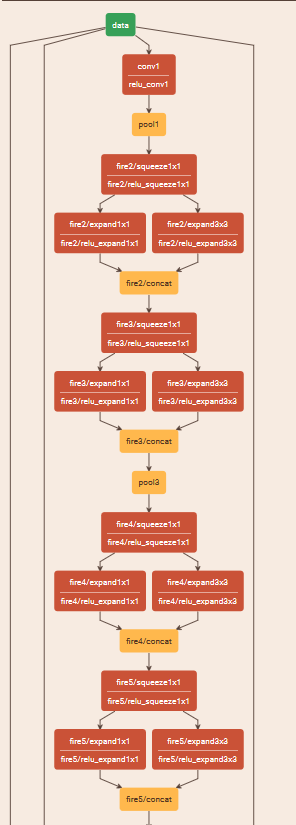
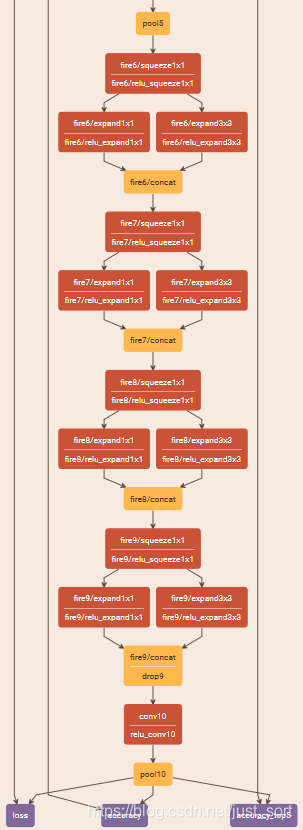
SqueezeNet以卷积层conv1开始,接着使用8个Fire modules (fire 2-9),最后以卷积层conv10结束。每个Fire Module中的Filter数量逐渐增加,并且在conv1,fire4,fire8, 和 conv10这几层之后使用步长为2的Max-Pooling,即将池化层放在相对靠后的位置,这使用了以上的策略(3)。
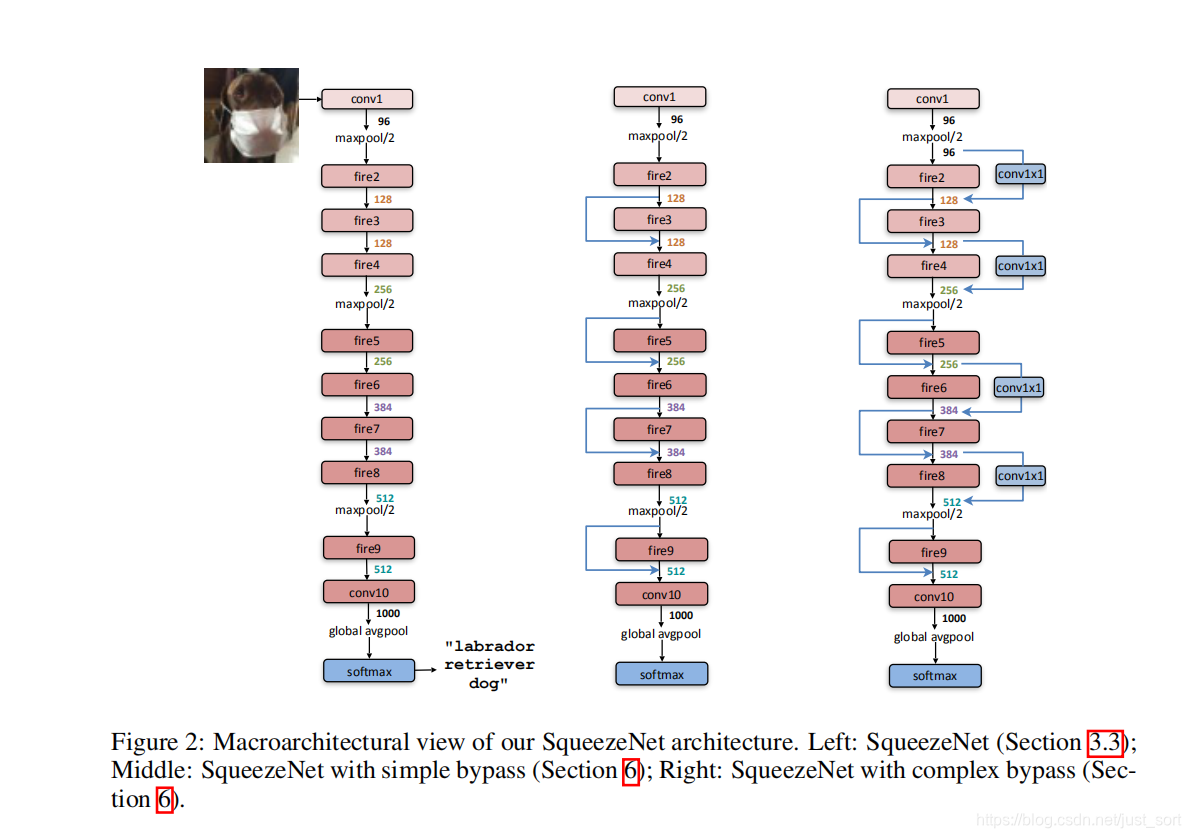
如图,左边为原始版本的SqueezeNet,中间为包含简单跳跃连接的改进版本,最右侧为使用复杂跳跃连接的改进版本。更加具体的细节如Table1所示:
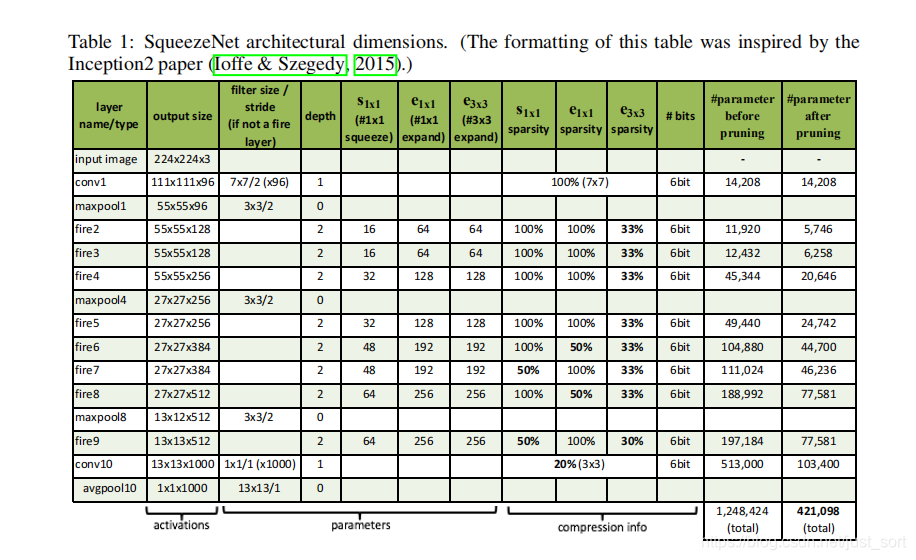
这里有一些细节,例如我们看fire2这个模块在剪枝前的参数是11920,这个参数是怎么计算得到的呢?fire2之前的maxpool1层的输出是55*55*96,之后接着的Squeeze层有16个1*1*96的卷积filter,注意这里是多通道卷积,为了避免与二维卷积混淆,在卷积尺寸末尾写上了通道数。这一层的输出尺寸为55*55*16,之后将输出分别送到expand层中的1*1*16(64个)和3*3*16(64个)进行处理,注意这里不对16个通道进行切分(就是说这里和MobileNet里面的那种深度可分离卷积不一样,这里就是普通的卷积)。为了得到大小相同的输出,对3\times 3\times 16的卷积输入进行尺寸为1的zero padding。分别得到55\times 55\times 64和55\times 55\times 64的大小相同的特征图。将这两个特征图concat到一起得到55\times 55\times 128大小的特征图,加上bias参数,这样总参数为(1\times 1\times 96+1)\times 16+(1\times 1\times 16+1)\times 64+(3\times 3\times 16+1)\times 64=(1552+1088+9280)=11920。
可以看到Fire Module中先通过squeeze层的1\times 1卷积来降维和降低参数,之后的expand层使用不同尺寸的卷积核来提取特征同时进行升维。这里3\times 3\times 16的卷积核参数较多,远大于1\times 1卷积的参数,所以作者对3\times 3\times 16卷积又进行了卷积操作和降维操作以减少参数量。从网络整体来看,特征图的尺寸不断减小,通道数不断增加,最后使用平均池化将输出维度转换成1\times 1\times 1000完成分类任务。
其他细节¶
SqueezeNet还有以下的一些细节:
- 为了使1\times 1和3\times 3卷积核输出的特征图尺寸相同,在
expand模块中,给3\times 3卷积核的原始输入添加一个像素的边界(zero-padding)。 squeeze layer和expand layer都是用ReLU作为激活函数。- 在
fire9模块之后,使用Dropout,比例取50%。 - 注意到
SqueezeNet中没有全连接层,这借鉴了Network in Network的思想。 - 训练过程中,初始学习率设置为
0.04,,在训练过程中线性衰减学习率。 - 由于
caffe中不支持使用2个不同尺寸的卷积核,所以expand layer实际上是使用了2个单独的卷积层(1\times 1卷积和3\times 3卷积核),最后将这两层的输出连接在一起,这在数值上等价于使用单层但包含2个不同尺寸卷积核的方式。
实验结果¶
SqueezeNet和AlexNet以及其他压缩算法比较的结果如Table2所示:
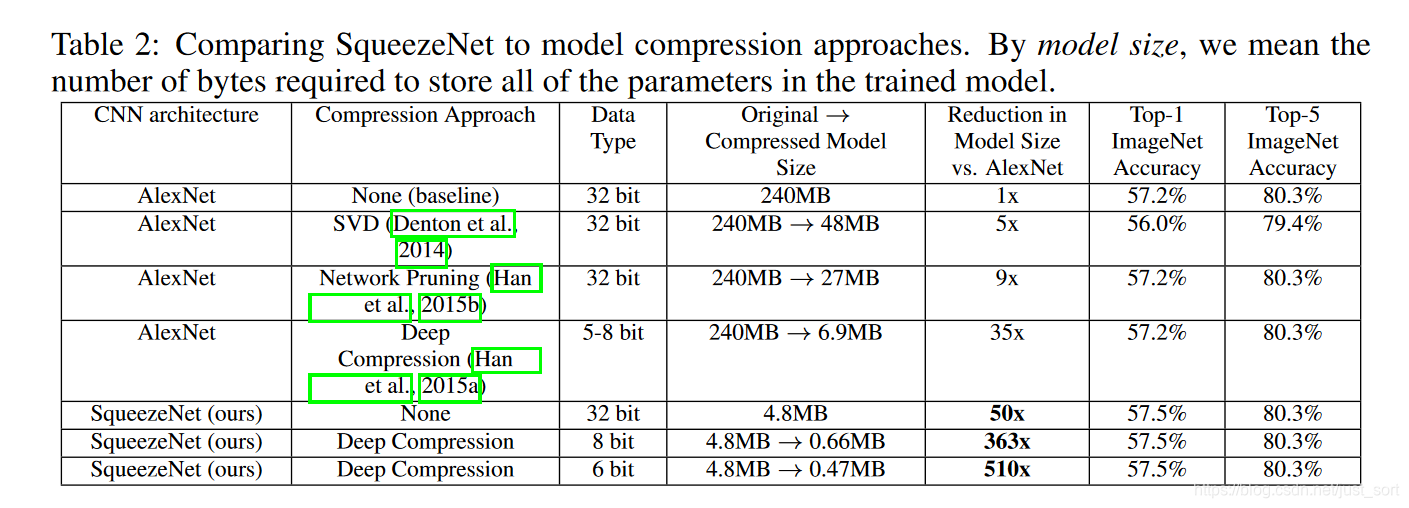
可以看到,SVD方法能将预训练的AlexNet模型压缩为原来的\frac{1}{5},top1和top5正确率几乎不变。模型压缩能将AlexNet压缩到原来的\frac{1}{35},正确率基本不变。SqueezeNet的压缩倍率可以达到50倍以上,并且准确率还有略微的提升。注意到即使使用float32数值来表示模型参数,SqueezeNet也比之前压缩率最高的模型更小,同时表现更好。
如果将模型压缩策略用在SqueezeNet上,使用33%的稀疏表示和int8量化,会得到一个仅有0.66M的模型。进一步,如果使用6比特量化,会得到仅有0.47MB的模型,同时准确率不变。此外,结果表明模型压缩不仅对包含庞大参数参数量的CNN网络起作用,对于较小的网络,例如SqueezeNet也是有用的。将SqueezeNet的网络结构和模型压缩结合起来可以将原模型压缩到\frac{1}{510}。
SqueezeNet微观空间结构¶
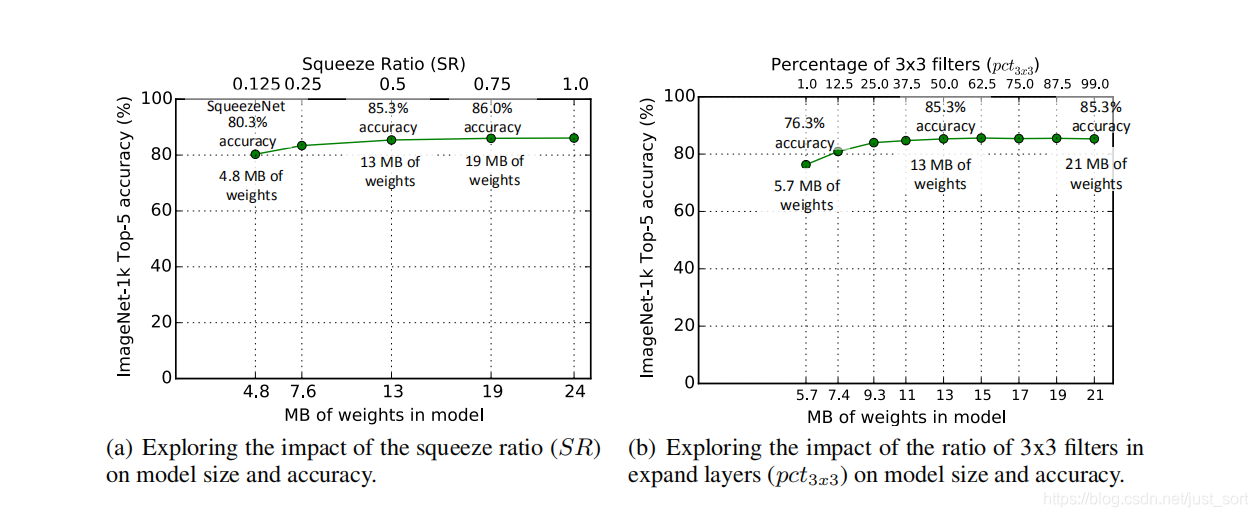
在SqueezeNet中,每一个Fire Module有3个的超参数,即s_{1\times 1},e_{1\times 1}和e_{3\times 3}。SqueezeNet一共有8个Fire modules,即一共有24个超参数,下面将讨论其中一些重要的超参数影响。为方便讨论,定义如下参数:
- base_{e}:表示Fire module中
expand filter个数。 - freq:每隔多少个Fire module个数增加
expand filter个数。 - incre_c:在每freq个Fire Module之后增加的
expand filter个数。 - SR:压缩比,为
squeeze layer中filter个数除以Fire module中filter总个数得到的一个比例。 - pct_{3\times 3}:在
expand layer中有1\times 1和3\times 3两种卷积,这里定义的参数是3\times 3卷积个数占expand layer中卷积核总个数的比例。 - 下图为实验结果:
SqueezeNet宏观结构设计¶
受ResNet启发,这里探索跳跃连接(bypass conection)的影响。在Figure 2中展示了三种不同的网络架构。下表给出了实验结果:

可以看到使用跳跃连接后,准确率有一定的提高。
SqueezeNet++¶
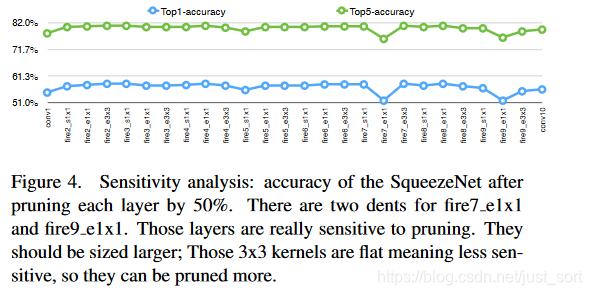
从Figure4中发现fire7_e1x1和fire9_e1x1在精度图中都有一个凹痕,因此特别敏感。所以论文增加了fire7_e1x1和fire9_e1x1中通道的数量,并把这个模型叫做“SqueezeNet++”。
同时从Table5可以发现,从稀疏模型中提高密集进行再训练可以提高精度,也就是说与密集的CNN Basline相比,dense->sparse->dense (DSD)训练可以产生更高的准确性。

Caffe可视化¶
后记¶
这篇推文简单介绍了移动端卷积神经网络模型SqueezeNet,其核心是采用模块的卷积组合,然后做了一些Trick同时结合深度模型压缩技术。SqueezeNet算是结合了小模型的两个研究方向即:结构优化和模型压缩。并且SqueezeNet有v1.0和v1.1两个版本,SqueezeNet v1.1的计算量比v1.0少2.4倍,而且没有牺牲精度,一共有3个pool,v1.1的pool靠前了。
附录¶
- 论文原文:https://arxiv.org/pdf/1602.07360v3.pdf
- Caffe官方代码实现:Caffe:https://github.com/DeepScale/SqueezeNet
推荐阅读¶
- 快2020年了,你还在为深度学习调参而烦恼吗?
- 卷积神经网络学习路线(七)| 经典网络回顾之AlexNet
- 卷积神经网络学习路线(八)| 经典网络回顾之ZFNet和VGGNet
- 卷积神经网络学习路线(九)| 经典网络回顾之GoogLeNet系列
- 卷积神经网络学习路线(十)| 里程碑式创新的ResNet
- 卷积神经网络学习路线(十一)| Stochastic Depth(随机深度网络)
- 卷积神经网络学习路线(十二)| 继往开来的DenseNet
- 卷积神经网络学习路线(十三)| CVPR2017 Deep Pyramidal Residual Networks
- 卷积神经网络学习路线(十四) | CVPR 2017 ResNeXt(ResNet进化版)
- 卷积神经网络学习路线(十五) | NIPS 2017 DPN双路网络
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

本文总阅读量次