0. 前言¶

今天给大家介绍一篇百度的论文PyramidBox人脸检测器,这是一款上下文内容辅助的人脸检测器。我自己在比赛中对图像预处理,截取人脸也经常用这个模型去做,效果十分不错。
1. 概述¶
近几年来人脸检测发展十分迅速,现在主要的挑战是小人脸,模糊人脸,人脸遮挡。我们提出了一款基于上下文辅助的人脸检测器来解决上述的挑战,基于上下文我们做了以下三点工作
- 我们设计了一种名为PyramidAnchor,这个上下文锚框,通过半监督方法来监督高级上下文特征学习
- 我们提出了一种低层次特征金字塔网络(Feature Pyramid Network),将高层级语义特征和低层级面部特征相结合,使得PyramidBox能一次(one-shot)预测所有尺度的面孔
- 我们提出了一种上下文敏感(context sensitive)结构来提高预测精度
相关代码开源在https://github.com/PaddlePaddle/models/tree/release/1.8/PaddleCV/face_detection。
2. 想法提出¶
YOLO,R-CNN,SSD相关工作提出了一种很有效的方式去连接锚框和CNN网络,但这些工作没有关注人物背景信息,导致在一些极端情况下出现人脸漏检的情况,比如下图

我们单看左边的小图很难判断是否有人脸,但随着背景信息的加入,比如帽子,手臂,衣服,裤子等,这些都能帮助我们去推断人脸的位置。
- 网络不仅需要识别人脸,还需要识别背景信息,这就需要额外的标注信息,这里我们对背景信息采取半监督的方法去生成近似的label
- 在FPN基础上改造结构得到LFPN
- 对于预测网络需要充分利用我们新加的背景特征,就有了CPM(Context-sensitive prediction module)背景感知模块
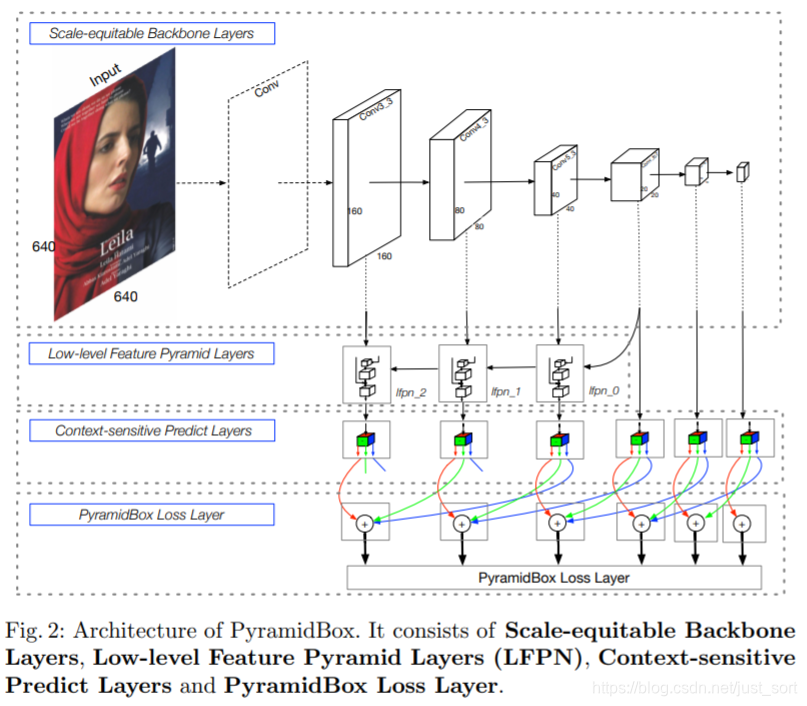
3. PyramidBox¶
3.1 网络架构¶
- 骨干网络上继续沿用VGG16网络
- 在骨干网络后接入LFPN模块
- 对于每个金字塔预测层,接入CPM模块得到最终的输出
3.2 Low-Level Feature Pyramid Layers低层级特征金字塔¶
传统的FPN都是从最顶层进行特征融合,但是我们有以下几个观点
- 不同大小的,模糊的人脸具有不同的纹理特征,直接简单粗暴的将高层语义特征拿来融合效果并不好
- 高语义特征提取自面部纹理较少的区域,可能引入噪声信息
因此我们构建了一个低层级的特征金字塔层
我们选择感受野接近输入尺寸一半的卷积层,进行特征融合
具体结构形式如下
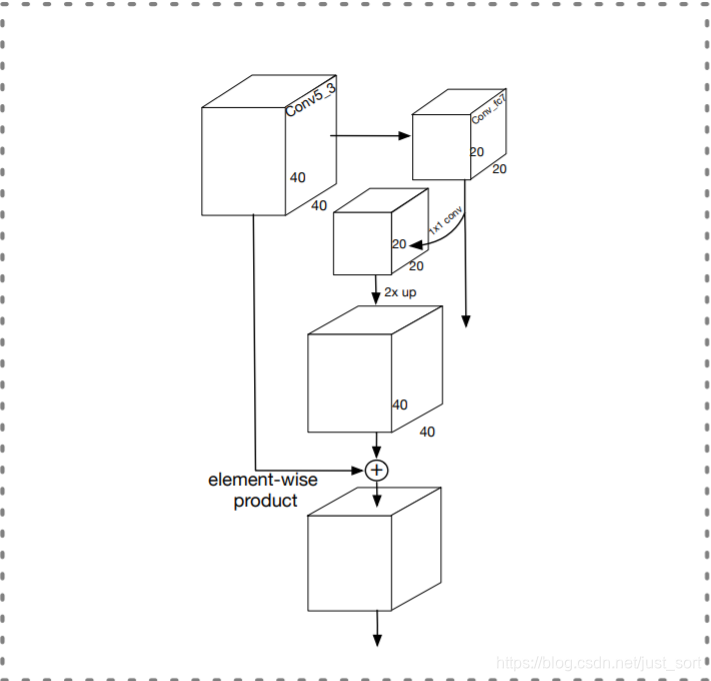
- 首先是对原尺寸特征图做一次下采样
- 下采样后的特征图进行1x1卷积缩放通道数
- 再将特征图上采样至原尺寸
- 最后进行element-wise 相乘(不要被图例欺骗了
3.3 PyramidDetectionLayer金字塔检测层¶
我们从整个网络选取了lfpn_2, lfpn_1, lfpn_0, conv_fc 7, conv 6_2, conv 7_2作为预测层
锚框大小设置为16, 32, 64, 128, 256, 512
采取类似SSD算法来进行目标检测
3.4 PredictLayer预测层¶
每个预测层后面都跟了一个CPM模块,形式如下
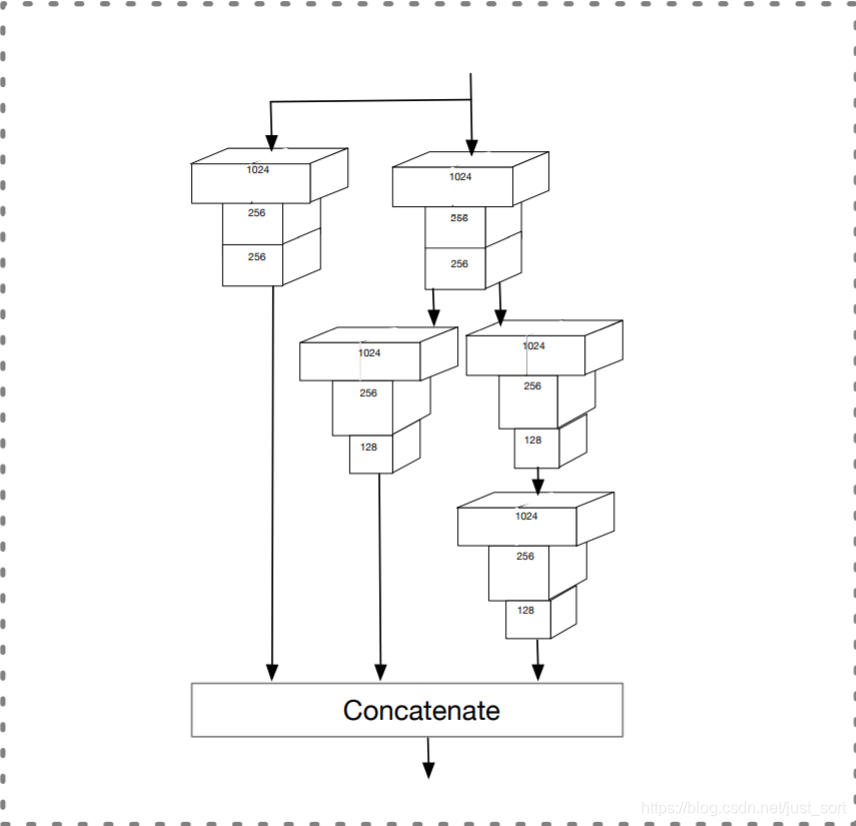

个人认为CPM模块设计吸收了GoogleNet的加宽网络的思想,将多层级特征进行级联
CPM模块的输出用于监督pyramid锚框
第L个CPM输出尺寸是
w_l *h_l * c_l
通道尺寸c_l 为20
其中每个通道的特征用于分类,人脸,头部,身体锚框回归
人脸分类需要4个通道(cp_{l}+cn_{l})=4。
其中cp_{l},cn_{l}是前景和背景的max-in-out标签,其中的p和n分别代表positive(正类), negative(负类)
通道分配遵循下图规则
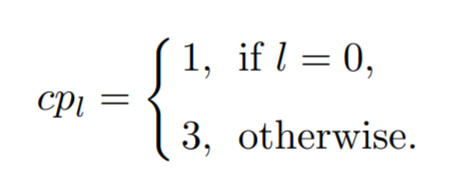
此外,头部和身体的分类各需要两个通道,面部,头部和身体的定位各需要4个通道
下面解释为什么第0层特征层是1, 3,而其他特征层是3,1?

我们可以从这两幅图很清晰的看到,大Anchor框住物体概率更高,小Anchor更加精细,同时错误率也会提高
因此在第0层只设置1个正类预测,而其他层设置3个
3.5 Max-in-out¶
Max-in-out是对在小尺寸人脸检测上发力的S3FD中的Max-out的改进,S3FD为了加强对小目标的划分,他做了如下的操作
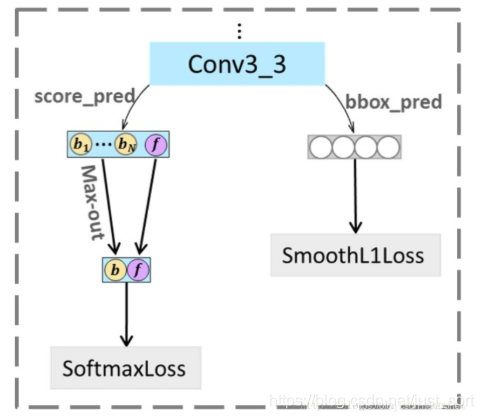
Maxout选择负样本锚框中可能性最大的负锚框,作为最终预测为negative anchor的打分
而Max-in-out是对正负样本锚框做上述处理
3.6 PyramidBox loss Layers¶
我们使用一系列pyramid anchors来监督分类和锚框回归
- 对于分类我们采用softmax损失函数
- 对于回归我们采用Smooth L1损失函数
4. PyramidAnchor¶
设计多尺度锚框有利于人脸检测,但是由于锚框只是设计检测人脸而忽略了多尺度之间的背景信息
PyramidAnchors生成一系列锚框,针对大区域人脸包括更多背景信息,如头部,肩部,身体部分
我们通过区域大小来对应调整锚框大小
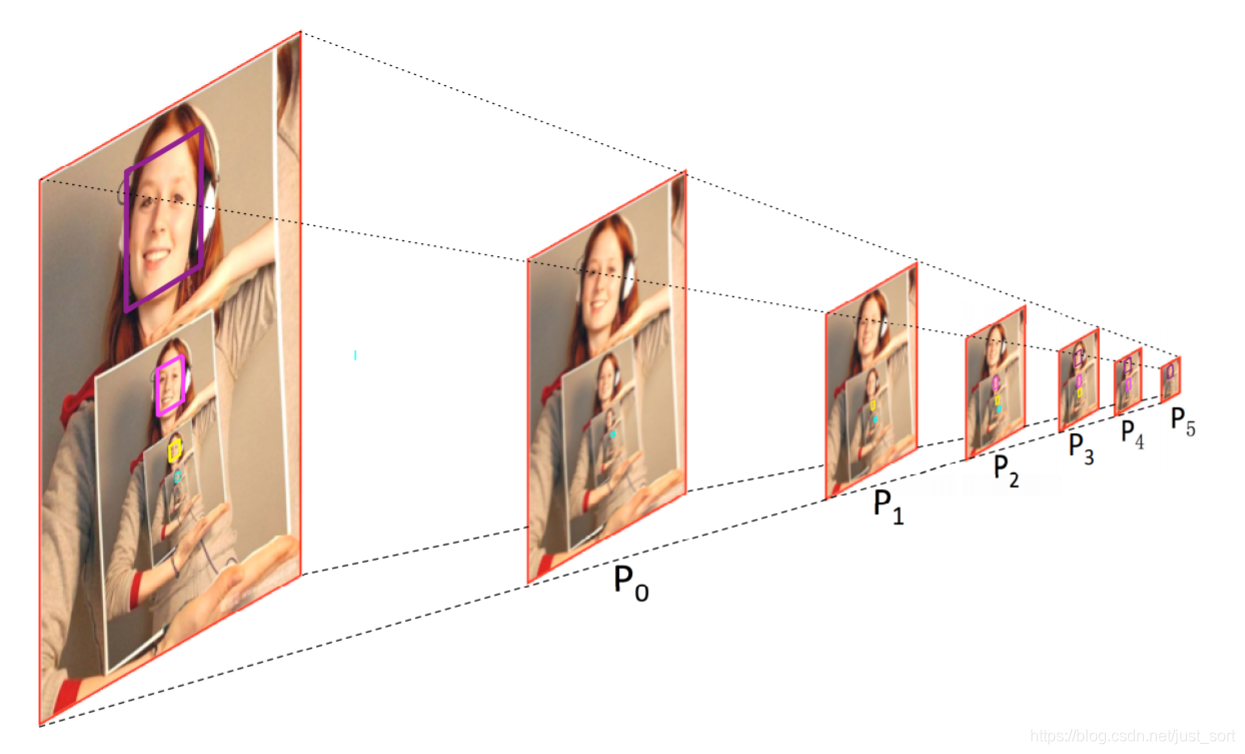
比如图中最大的紫色框框住的人脸,这个pyramid anchor 来自P3 P4 P5
我们放大图仔细看
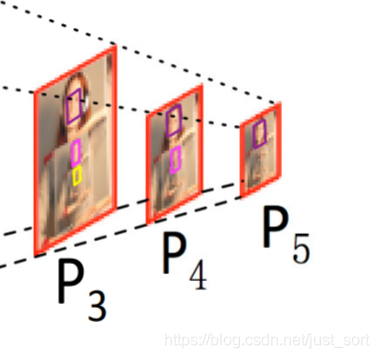
其中P3是通过conv_fc7预测标注的人脸确定的,P4是通过conv6_2预测标注的头部部分确定的,P5则是由conv7_2标注的身体中的脸部部分
首先我们是固定的一个锚框
P3 P4 P5图的分辨率是逐渐减小的,而锚框不变,因此锚框框住的相对区域于是越来越大的
比如P3图中我们可以直接框住人脸,那么P4图分辨率减小,因此框住头部(更大的区域),P5图分辨率继续减小,因此框住的是部分身体
采取的是自监督方式生成label,遵循下面公式

通过计算锚框与目标区域的iou,根据阈值进行标记,文中设置相关参数如下
- threshold = 0.35
- K = 2
- S_{pa} = 2
其中K=2表示从0到2分别标注人脸,头部,身体这三个label
5. 实验结果¶
因为PyramidBox是基于S3FD改造的,所以以此为baseline进行对比
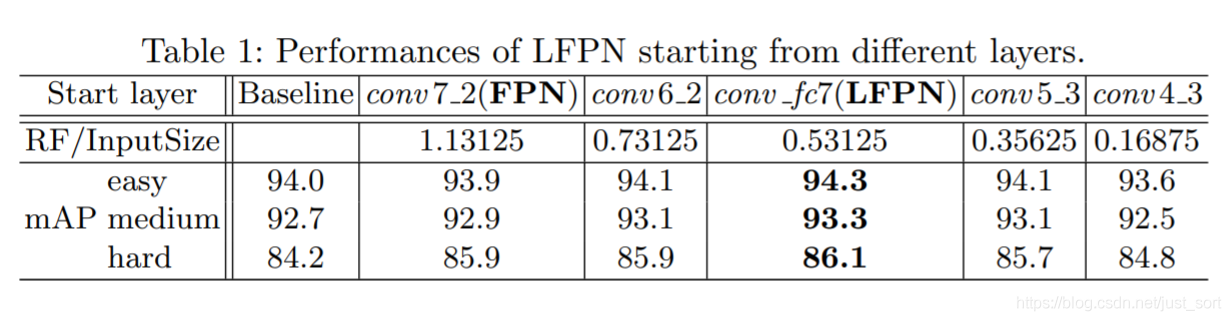
可以看到LFPN放置的位置对检测性能有一定程度上影响,在conv_fc7这里放置能取得更好的效果
6. 总结¶
百度的文章创新点还是很丰富的,把自监督引入人脸检测,通过Pyramid Anchor获取相关背景信息,辅助人脸检测。而且提点不是光靠改网络结构,选择了最朴素的Vgg16进行一定程度加深。也进一步证明了Pyramid Box和CPM对模型性能的提升。
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。

本文总阅读量次