【GiantPandaCV导语】本文主要介绍label assign问题在检测方向的具体应用和当前发展情况。
为什么要写这个¶
检测方向发展到现在,很多的学者是尝试从不同的角度发力来提高检测的精度和速度,例如新的backbone,不管是基于nas的还是手工设计的;例如训练策略的合理选择,例如YOLOv4的试验部分展示的;当然也有一部分人,是将着眼点放在了正负样本的不平衡现象优化上,并沿着这个方向有了实质性的工作。
什么是正负样本不平衡现象¶
正负样本不平衡现象,用小编自己的理解就是,检测网络推理得到特征图后,定位头和分类头需要从特征图上找到目标的位置并判定类别。这个时候就需要告诉网络它预测的结果bbox中,哪些是对的,哪些是错的。假设当前输入图上只有一个目标,而检测算法生成了1000个预测结果,对刚开始训练的网络,很难使得其预测的1000个目标框都在目标上,那么这1000个可能随机分布的预测结果中将大部分都是负样本,网络就只能获取很少量的待检测目标特征的分布情况,这样就造成了正负样本的不平衡,导致的结果就是训练模型的精度不够高。
正负样本不平衡问题和label assign的关系¶
label assign就是划分正负样本的步骤。例如,在anchor based类算法内,对当前模型的预测结果划分正负样本主要是通过判断预测的bbox和Ground Truth的IOU值,当该值大于正样本阈值时为正样本,在正样本阈值和负样本阈值区间内的为负样本,其余不考虑。而对anchor free类检测算法,例如FCOS,是当前像素位置落在Ground Truth内,则认为当前像素位置定位的bbox为正样本,再剔除掉一些明显尺寸预测不合规的bbox,其余的为负样本。
label assign在检测方向的当前发展¶
anchor free类检测算法,相对anchor based类算法在label assign上更优的表现,有学者研究认为是因为其扩充了正样本数量,从而改善了正负样本的不平衡问题。那么是不是说通过改善anchor based类检测算法的label assign 方式,就可以提高其检测精度达到和anchor free一致的程度呢?《Bridging the Gap Between Anchor-based and Anchor-free Detection via Adaptive Training Sample Selection》的作者就研究了这一问题并提出了ATSS来进行正负样本的重筛选,作者在retinanet上的试验也证明了该思路的正确性。但是ATSS结构中依然有超参数的存在,《From VanillaDet to AutoAssign》的作者就尝试将该assign过程自动化,其试验对比也证明该方案相较于之前的label assign方案有更优的检测精度。
个人思考¶
首先我们看autoAssign论文中的一张图:
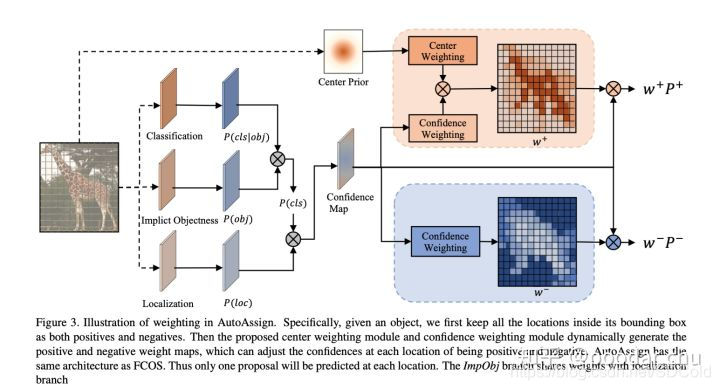
如图为autoassign的网络流程图中的创新部分,我们可以看到作者所设计的网络通过其结构可以让网络学习到目标框中物体的分布函数,看到这个步骤,再结合作者的说法,我们不难联想到centernet网络所采用的高斯核函数,在centernet中,作者采用高斯核函数就是假设输入的待检测样本均为一个类似圆的分布情况,越靠近其中心点的像素位置的预测结果越可能为正样本,但是我们知道在实际检测中,类似雨伞、甜甜圈等都不能简单的用高斯分布来描述,autoassign中就是通过自动化的学习来得到对目标的合理描述,而这种分布的描述是直接影响到正负样本划分的。我们再联想FCOS的centerness分支,FCOS作者说在实际训练时候,网络会预测很多离目标中心较远的目标框,而这些目标框如果采用和靠近目标中心的框同样的权重明显是不合适的。所以通过centerness分支来计算当前图像上每个位置可能是目标中心点的概率值来调整权重,其本质也是在学习目标的分布情况。如此我们就将FCOS和centernet中的label assign和auto assign串起来了。
最后附上作者知乎的帖子(https://zhuanlan.zhihu.com/p/158907507
本文总阅读量次