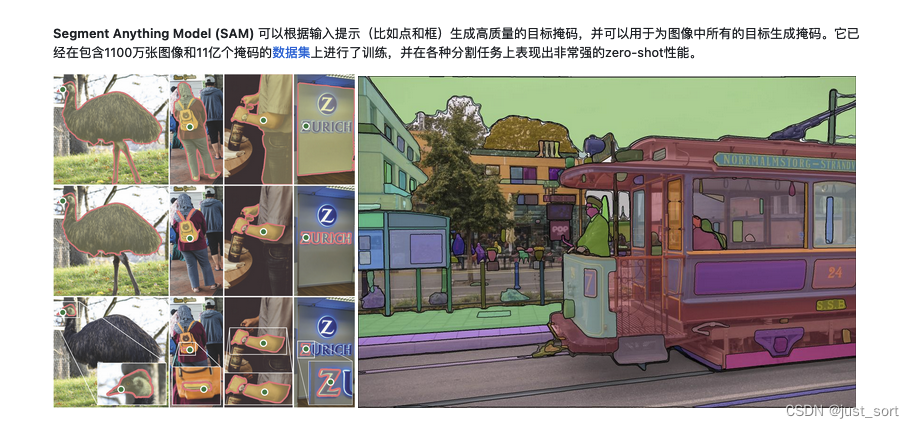
0x0. 前言¶
上个月Meta提出的Segment Anything Model(SAM)希望在视觉领域通过Prompt+基础大模型的套路来解决目标分割的问题。经过实测,在大多数场景中SAM的表现都足够惊艳,并且基于SAM的各种二创工作也爆发了比如 检测一切的Grounded-Segment-Anything(https://github.com/IDEA-Research/Grounded-Segment-Anything),将Segment Anything扩展到医学图像领域 。但目前中文社区似乎并没有怎么对SAM的模型做细致的解析,所以这里 fork了SAM仓库并且对模型实现部分做了详细的代码解析,fork仓库的地址如下:https://github.com/Oneflow-Inc/segment-anything 。
本文会对照论文的结构图和fork的SAM仓库中的代码注释尝试梳理一下SAM模型部分的代码。最后,我也会介绍一下如果你想用oneflow来跑SAM应该怎么做,实际上在预测脚本里面加2行代码就可以了:
import oneflow.mock_torch as mock
mock.enable(lazy=True, extra_dict={"torchvision": "flowvision"})
最后汇总一下这个fork的SAM仓库做的事情: - 对 https://github.com/Oneflow-Inc/segment-anything/tree/main/notebooks 下面的推理脚本进行汉化。 - 对 https://github.com/Oneflow-Inc/segment-anything/blob/main/README_zh.md 进行汉化。 - 对 https://github.com/Oneflow-Inc/segment-anything/tree/main/segment_anything/modeling SAM的模型实现进行全面解析,为每个函数代码实现添加中文注释。 - 基于oneflow的mock torch技术一键切换 oneflow 后端运行SAM模型推理,方便基于oneflow做二次开发以及性能优化。
欢迎点击star: https://github.com/Oneflow-Inc/segment-anything
0x1. 模型+代码解析¶
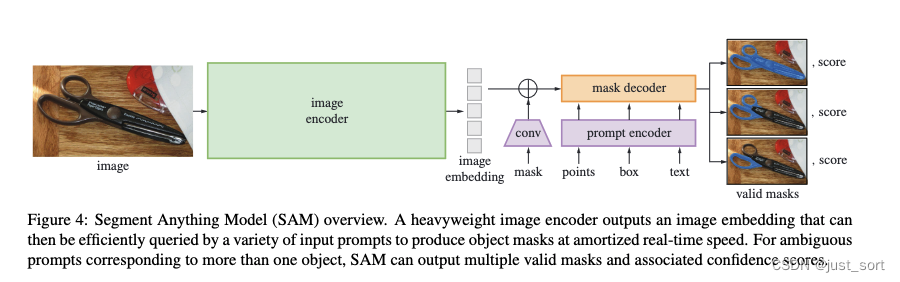 实际上模型实现部分就对应了这张图。
实际上模型实现部分就对应了这张图。
其中绿色部分表示将原始图像编码为向量,SAM中使用VIT来实现图像编码器。原始图像被等比和 padding 的缩放到1024大小(对应https://github.com/Oneflow-Inc/segment-anything/blob/main/segment_anything/modeling/sam.py#L131),然后采用kernel size 为16,stride也为16的卷积将图像离散化为batch_size x 64x64X768的向量(对应 https://github.com/Oneflow-Inc/segment-anything/blob/main/segment_anything/modeling/image_encoder.py#L482-L518,),向量在W和C上被顺序展平(https://github.com/Oneflow-Inc/segment-anything/blob/main/segment_anything/modeling/image_encoder.py#L208)后再进入多层的transformer encoder,vit输出的向量再通过两层的卷积(kernel size分别为1和3,每层输出接LayerNorm2d)压缩到特征维度为256(https://github.com/Oneflow-Inc/segment-anything/blob/main/segment_anything/modeling/image_encoder.py#L98-L114)。
image encoder部分的详细代码细节的解释请查看:https://github.com/Oneflow-Inc/segment-anything/blob/main/segment_anything/modeling/image_encoder.py
接下来紫色部分表示prompt encoder,prompt encoder的输出包括对点,box和text进行编码组成的sparse_embeddings以及对输入mask进行编码的dense_embeddings (对应https://github.com/Oneflow-Inc/segment-anything/blob/main/segment_anything/modeling/prompt_encoder.py#L251)。最后,sparse_embeddings的输出shape是batch_sizexNx(embed_dim=256),其中N由输入的点和框的个数决定。而dense_embeddings的输出shape是batch_sizex(embed_dim=256)x(embed_H)x(embed_W),其中embed_H和embed_H都等于64。(https://github.com/Oneflow-Inc/segment-anything/blob/main/segment_anything/build_sam.py#L73)。注意图上的对mask的卷积操作对应 https://github.com/Oneflow-Inc/segment-anything/blob/main/segment_anything/modeling/prompt_encoder.py#L64-L71 。
prompt encoder部分的详细代码细节的解释请查看:https://github.com/Oneflow-Inc/segment-anything/blob/main/segment_anything/modeling/prompt_encoder.py
最后我们看一下 Mask Decoder部分,也就是图中的橙色部分。Mask Decoder的细节可以用下图来表示:
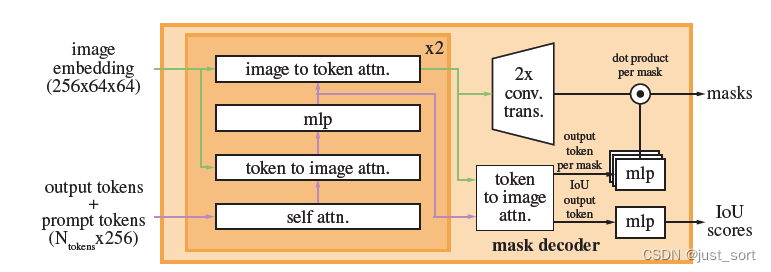
这里的image embedding(256x64x64)就是上面的image decoder的输出,因为输入到Mask Decoder的时候是对batch维度进行遍历然后处理,所以这里的维度没有Batch。然后左下角的output tokens+prompt tokens(N_{tokens}\times 256)分别表示iou token embedding和3个分割结果 token的embedding(sparse_embeddings+dense_embeddings)。(对应:https://github.com/Oneflow-Inc/segment-anything/blob/main/segment_anything/modeling/mask_decoder.py#LL171C9-L173C1)。这里还需要注意的一个细节是prompt embedding部分的dense embedding直接叠加到了image embedding上。(对应https://github.com/Oneflow-Inc/segment-anything/blob/main/segment_anything/modeling/mask_decoder.py#L175-L177C18)。
接着在 Transformer 实现中每一层都做 - token embedding 做self attention 计算。 - token embedding 和src 之间做cross attention 计算。 - src 和 token embedding 之间做 cross attention 计算。 - 第 2 和 3 之间有前馈 MLP 网络;cross attention的结果通过残差方式相加并norm。
这个Transformer 块里面的右上角有一个 x2 ,这里的意思是Transformer的层数为2。然后这里的紫色和绿色的箭头表示当前的Attention模块的query, key, value的来源,每层有1个self attention和2个cross attention模块。transform最终输出前,token embedding 还需要和src 做一次cross attention,也就是图中的token to image attn。
最后,Transformer 返回的3个 mask token 的 embedding 经过3层mlp后,与对齐后的图像embedding点积得到 3 个最终的分割结果;iou token 经过mlp得到3个分割结果置信度得分。(对应:https://github.com/Oneflow-Inc/segment-anything/blob/main/segment_anything/modeling/mask_decoder.py#L182-L199)
0x2. 切换SAM的后端¶
SAM的推理脚本默认是使用PyTorch运行,如果你想使用oneflow来执行并尝试获得推理加速,可以在运行脚本之前加上:
import oneflow.mock_torch as mock
mock.enable(lazy=True, extra_dict={"torchvision": "flowvision"})
OneFlow版本需要安装nightly,这样就可以用上OneFlow作为后端来推理SAM了。关于mock torch 黑魔法可以查看 https://docs.oneflow.org/master/cookies/oneflow_torch.html 这个官方文档。
oneflow nightly版本的安装方法如下:https://github.com/Oneflow-Inc/oneflow#install-with-pip-package
遗憾的是,我们还未来得及做调优工作,如果对使用OneFlow对SAM做推理加速感兴趣的读者可以自行尝试活着联系我本人一起讨论和实施。
0x3. 总结¶
本文介绍了 https://github.com/Oneflow-Inc/segment-anything 做的一些事情并解析了SAM的结构和代码实现。对于SAM来说,相比于模型更重要的是最数据进行处理,关于这方面大家可以参考:https://zhuanlan.zhihu.com/p/620355474
0x4. 后续工作¶
后面有时间的话会继续汉化onnx导出的jupyet notebook,并且做一下相关的性能调优工作以及剩余的SamAutomaticMaskGenerator的解析。
本文总阅读量次