NID-SLAM:动态环境中基于神经隐式表示的RGB-D SLAM¶
论文标题:NID-SLAM: NEURAL IMPLICIT REPRESENTATION-BASED RGB-D SLAM IN DYNAMIC ENVIRONMENTS
论文链接:https://arxiv.org/abs/2401.01189
1. 原文摘要¶
神经隐式表示已经被探索用于增强视觉SLAM掩码算法,特别是在提供高保真的密集地图方面。现有的方法在静态场景中表现出强大的鲁棒性,但却难以应对移动物体造成的干扰。在本文中,我们提出了NID-SLAM,它显著地提高了神经SLAM掩码在动态环境中的性能。我们提出了一种新的方法来增强语义掩码中不准确的区域,特别是在边缘区域。利用深度图像中存在的几何信息,这种方法能够准确地移除动态物体,从而降低了相机漂移的概率。此外,我们还引入了一种针对动态场景的关键帧选择策略,它提高了相机跟踪对大尺度物体的鲁棒性,并提高了建图的效率。在公开的RGB-D数据集上的实验表明,我们的方法在跟踪精度和建图质量方面优于竞争的神经SLAM方法。

图1. NID-SLAM在我们采集的大型动态场景上的三维重建结果。
2. 方法提出¶
视觉同时定位与地图建构(SLAM)在各种应用中发挥着关键作用,如机器人导航、增强现实(AR)和虚拟现实(VR)。视觉SLAM算法利用传感器(如单目、立体和RGB-D相机)收集的数据来估计先前未知环境中相机的姿态,并逐步构建周围场景的地图。在各种视觉传感器中,RGB-D相机同时记录颜色和深度数据,为三维环境信息的获取提供了更有效和精确的基础。这增强了大多数SLAM算法的三维重建性能。
最近的方法已经将神经隐式表示引入到SLAM中。最典型的例子就是神经辐射场(NeRF),它将场景颜色和体素密度编码到神经网络的权重中,直接从数据中学习场景细节的高频信息,极大地增强了建图的平滑性和连续性。结合基于体积表示的渲染方法,通过训练,NeRF可以重新合成输入图像,并推广到相邻未见的视点。但是,这些神经SLAM算法是基于静态环境的假设,其中一些可以处理合成场景中的小动态物体。在真实的动态场景中,这些算法可能会由于动态物体的存在而在稠密重建和相机跟踪精度方面出现显着的性能下降。这可能在很大程度上是由于动态物体导致的数据关联不正确,严重破坏了跟踪过程中的姿态估计。此外,动态物体的信息通常会合并到地图中,妨碍其长期适用性。
语义信息已经在许多研究中被引入到动态场景中的视觉SLAM算法中。其主要思想是将语义信息与几何约束相结合以消除场景中的动态物体。然而,一方面,由于场景中静态信息的减少,这些算法中的地图质量和内在联系较差。另一方面,由于缺乏对未观测区域的合理几何预测能力,这些算法通常存在恢复背景中可观的空洞。
为了解决这个问题,我们提出了神经隐式动态SLAM(NID-SLAM)。我们整合精度提高的深度信息与语义分割以检测和移除动态物体,并通过将静态地图投影到当前帧中以填补这些物体遮挡的背景。
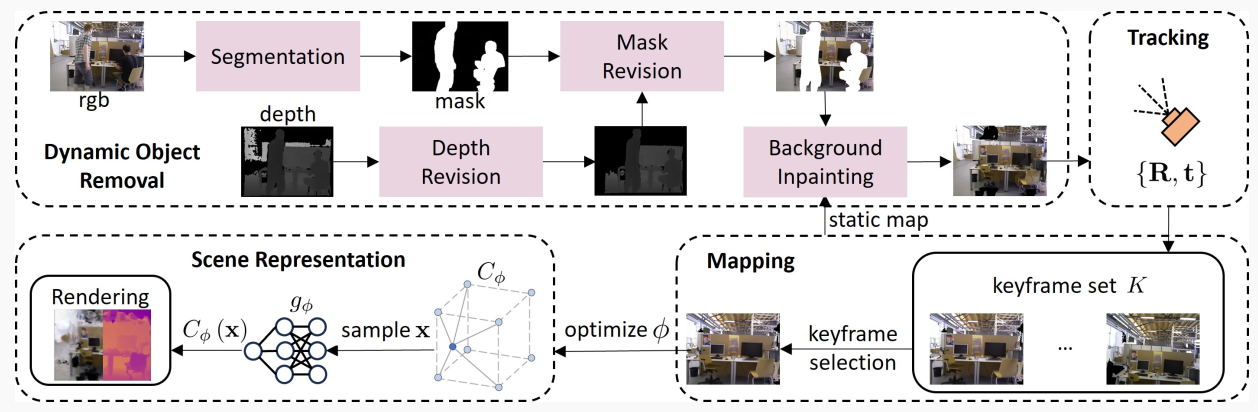
图2. 系统概览。1) 动态物体移除:通过使用语义分割和掩码修正,精确地消除RGB-D图像中的动态物体,然后彻底恢复被遮挡的背景。2) 跟踪:通过最小化损失来优化相机姿态{R, t}。3) 建图:采用基于掩码的策略来选择关键帧,用于优化特征网格场景表示。4) 场景表示:通过表面聚焦的点采样,实现预测的颜色和深度值的高效渲染。
3. 方法详解¶
图2展示了NID-SLAM的总体框架。给定RGB-D图像流作为输入,我们首先使用专门的动态处理过程移除动态物体。随后,我们通过联合优化相机姿势和神经场景表示来完成跟踪和建图。利用语义先验和深度信息,消除动态物体,并通过静态地图修复这些物体遮挡的背景。在每次建图迭代中,选择关键帧以优化场景表示和相机姿态。渲染是通过对查看射线进行采样并在这些射线上各点处集成预测值来执行的。
3.1 动态物体移除¶
深度修正:由于深度相机的局限性,物体与相机之间距离增加时的深度估计精度会降低。存在显著误差的深度信息可能导致不正确的数据关联,破坏相机跟踪的稳定性。在高度动态环境中,这些不准确性变得更加明显,增加相机漂移的概率。此外,由于深度信息中的错误,构建的地图可能会出现分层现象,其中本应位于相同深度的图像块在地图上表示为不同深度。因此,我们检测并删除不准确的深度信息。具体来说,我们计算深度图的图像梯度,并将这些梯度用作评估深度信息准确性的指标。 当图像的水平或垂直梯度超过预定义阈值\tau_1时,说明深度存在显著变化,我们将梯度方向上后续像素点的深度设置为零,以减轻深度误差。
基于深度的语义分割:为了检测动态物体,我们采用基于边界框的网络进行输入图像的语义分割,在我们的实验中使用YOLO算法。 该网络以RGB原始图像为输入,并输出图像中潜在动态或可移动物体的二进制掩码。 语义掩码存在两个主要缺点。 首先,它们可能无法完全覆盖动态物体,有时会并入环境中的其他物体。 其次,掩码在边界区域容易出错。 因此,我们利用深度信息细化掩码。 对于原始掩码的每个边界点,我们检查以其为中心的五像素半径区域,计算该区域内掩码中像素的深度值范围。 对于此区域内的掩码部分,我们计算所有像素的深度值范围。 对于此区域外掩码的像素,其深度值在计算的范围内的像素被认为是掩码的一部分,并随后被整合。
背景修复:对于移除的动态物体,我们使用从以前的视点获得的静态信息来修复被遮挡的背景,合成一个没有动态物体的逼真图像。 修复后的图像包含更多的场景信息,使地图的外观更准确,增强了相机跟踪的稳定性。 利用先前帧和当前帧的已知位置,我们将一系列先前关键帧投影到当前帧的RGB和深度图像的分割区域。 由于这些区域要么尚未出现在场景中,要么已经出现但没有有效的深度信息,因此仍有一些区域保留未填充。 图1展示了我们自制数据集中用作输入的三帧和最终重建的场景。 可以注意到,动态物体被成功删除,大多数分割部分修复良好。
3.2 基于掩码的关键帧选择¶
对于跟踪的输入帧,我们选择一组关键帧,表示为K。我们对关键帧的偏好倾向于:1) 动态物体比率较低的帧; 2)与前一关键帧重叠率较低的帧。我们使用 I_R^d 和I_R^o 分别表示输入帧I的两个比率。当这两个比率之和小于阈值 \tau_2 时,我们将当前帧插入关键帧集。为了解决背景修复中的不准确性和遗漏信息,我们减少关键帧中的动态物体比例。这种方法确保整合更多可靠的信息,增强相机跟踪的准确性和稳定性。同时,关键帧之间的重叠更小可以使关键帧集包含更多场景信息。在静态场景中,此策略默认为基于重叠比的选择。
从K中选择关键帧以优化场景表示时,我们在基于覆盖的和基于重叠的策略之间交替,旨在在优化效率和质量之间取得平衡。基于覆盖的策略倾向于覆盖最大场景区域的帧,确保场景边缘区域的全面优化。但是,这种方法通常需要大量迭代才能优化相对较小的边缘区域,降低了整体优化效率。它还会导致重复的选择结果,因为帧的覆盖面积是恒定的,覆盖面积大的帧保持更高的优先级。基于重叠的策略涉及从与当前帧视觉上重叠的关键帧中随机选择。为避免过度关注边缘区域并反复优化相同区域,我们首先使用基于覆盖的策略优化整个场景,然后多次使用基于重叠的策略,定期重复此过程。
3.3 场景表示和图像渲染¶
场景表示:对于场景表示,我们采用多分辨率几何特征网格 G_\alpha=\{G_\alpha^l\}_{l=1}^L 和颜色特征网格 C_\phi,其中 l\in\{0,1,2\} 表示粗糙,中等和细节层次的场景细节。 通过三线性插值查询每个采样点x处的特征向量G_\alpha(x)和C_\phi(x)。 每个特征网格对应一个MLP解码器,其中几何解码器表示为f^l,颜色解码器表示为g。 几何解码器输出预测的占用率 o_x 如下:

我们还对颜色信息进行编码,允许我们渲染RGB图像,这为跟踪提供了额外的信号。 颜色解码器预测颜色值c_x如下:
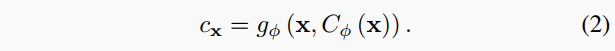
其中\theta=\{\alpha,\phi\}是几何和颜色特征网格的可学习参数。
图像渲染:给定相机姿态,我们可以计算每个像素坐标处的视线方向r。我们对每个像素采样光线,然后沿每个光线采样 M 个点 x_i=o+d_ir,其中 i\in\{1,...,M\},o 表示相机原点,d_i 表示 x_i 的深度值。对于每个采样点,在获得预测颜色 c_i 后,可以渲染颜色和深度为:
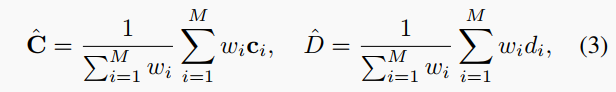
其中w_i=o_{x_i}\prod_{j=1}^{i-1}(1-o_{x_j})是沿射线计算的权重。
对于逐光线采样,除了M_{strat}用于分层采样的点之外,我们还使用表面采样,特别针对与表面距离小于阈值\tau_3的M_{surf}点。总共对每个射线采样M=M_{strat}+M_{surf}点。然后,我们验证这些采样点是否落在有效的特征网格内。网格外的点将被排除,因为它们不会为渲染过程提供价值,提高渲染效率。
3.4 建图和跟踪¶
在建图过程中,我们从所选关键帧中采样 N 个像素来优化场景表示。随后,我们采用分阶段的方法来优化,旨在最小化几何和光度损失。
几何损失和光度损失分别应用为颜色和深度的预测值与真实值之间的L_1损失,如下所示:
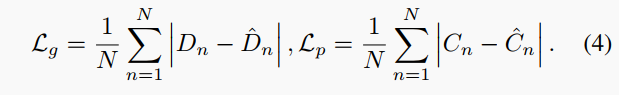
我们联合优化特征\theta和所选关键帧集K中相机外在参数\{R_i,t_i\}:

其中\lambda_p是损失权重因子。
同时,我们运行跟踪过程,从当前帧中采样N_t像素来优化当前帧的相机姿态\{R,t\}:
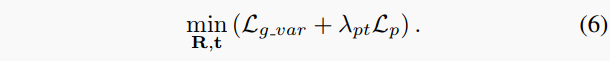
4. 实验¶
本方法在公开的RGB-D数据集上进行了实验,包括TUM RGB-D数据集和Replica数据集,并与现有的方法进行了比较。实验结果表明,该方法在动态环境中的跟踪精度和建图质量方面都优于其他的神经SLAM方法。

表1. TUM RGB-D数据集上的相机跟踪结果。评估指标为ATE RMSE。 代表相应文献中没有提到对应的数值。

表2. TUM数据集上的平移RPE RMSE结果。
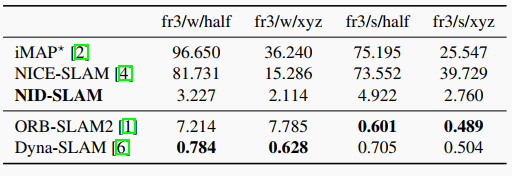
表3. TUM数据集上的旋转RPE RMSE结果。

图3. TUM RGB-D数据集上的重建结果。红框标出有动态物体的区域。

图4. Replica数据集上的重建结果。红框标出改进的区域。
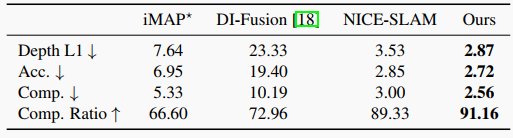
表4. Replica数据集上的重建结果(8个场景的平均值)。
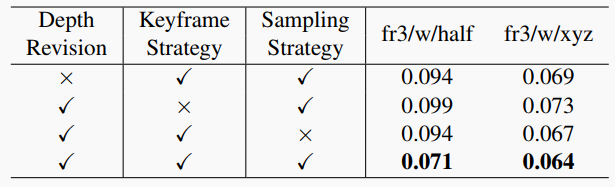
表5. 消融实验结果。
5. 结论¶
我们介绍了NID-SLAM,这是一种动态RGB-D神经SLAM方法。我们证明神经SLAM能够在动态场景中实现高质量的建图和可信的孔填充。 利用动态物体移除,我们的方法实现了稳定的相机跟踪并创建可重复使用的静态地图。 准确获得的无动态物体图像也可以在进一步的应用中使用,如机器人导航。
本文总阅读量次