
开篇的这张图代表ILSVRC历年的Top-5错误率,我会按照以上经典网络出现的时间顺序对他们进行介绍,同时穿插一些其他的经典CNN网络。
前言¶
这是卷积神经网络学习路线的第八篇文章,我们来回顾一下经典网络中的ZF-Net和VGGNet。
稳中求胜-ZFNet¶
ZFNet是ImageNet分类任务2013年的冠军,其在AlexNet的结构上没有做多大改进。首先作者Matthew D Zeiler提出了一种新的可视化技术,该技术可以深入了解中间特征图的功能和分类器的操作。这一点我在卷积神经网络学习路线(一)| 卷积神经网络的组件以及卷积层是如何在图像中起作用的?详细介绍过。最终基于特征图的可视化结果发现以下两点:
- AlexNet第一层中有大量的高频(边缘)和低频(非边缘)信息的混合,却几乎没有覆盖到中间的频率信息。
- 由于第一层卷积用的步长为4,太大,导致了有非常多的混叠情况,学到的特征不是特别好看,不像是后面的特征能看到一些纹理、颜色等。
因此作者针对第一个问题将AlexNet的第一层的卷积核大小从11\times 11改成7\times 7。同时针对第二个问题将第一个卷积层的卷积核滑动步长从4改成2。
同时,ZFNet将AlexNet的第3,4,5卷积层变为384,384,256。然后就完了,可以看到ZFNet并没有特别出彩的地方,因此这一年的ImageNet分类竞赛算是比较平静的一届。
ZFNet的详细网络结构如下图:
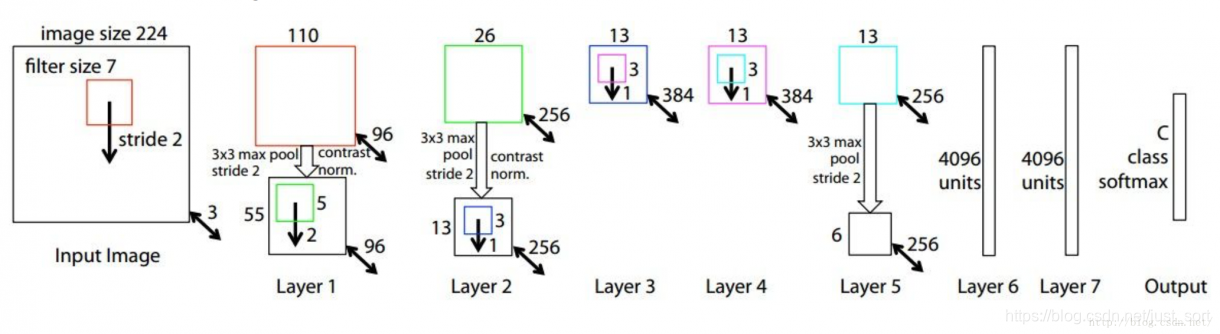
ZFNet的代码实现如下:
def ZF_Net():
model = Sequential()
model.add(Conv2D(96,(7,7),strides=(2,2),input_shape=(224,224,3),padding='valid',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
model.add(Conv2D(256,(5,5),strides=(2,2),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
model.add(Conv2D(384,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(384,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(3,3),strides=(2,2)))
model.add(Flatten())
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1000,activation='softmax'))
return model
越来越深-VGGNet¶
在2014年的ImageNet挑战赛上,牛津大学的VGG(Visual Geometry Group)Net赢得了定位任务的关娟和分类任务的亚军。VGGNet相比于前面的AlexNet,仍然沿用了卷积加全连接的结构,但深度更深。VGGNet的论文全名为:Very Deep Convolutional Networks for Large-Scale Visual Recognition》。
我们来看一下VGGNet的具体网络结构:
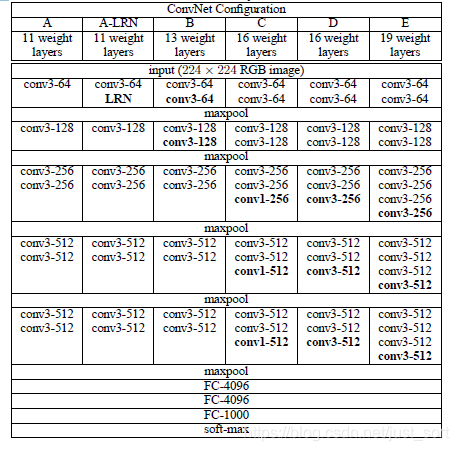
这个表格有意思了啊,他分为A,A-LRN,B,C,D,E 5种网络。这是因为当时为了解决初始化权重的问题,VGG使用的是预训练的方式,即先训练一部分小网络,然后确保这部分网络收敛之后再在这个基础上逐渐加深。并且当网络在D阶段(VGG-16)效果是最好的,E阶段(VGG-19)次之。VGG-16指的是网络的卷积层和全连接层的层数为16。接下来我们仔细看一下VGG-16的结构图:
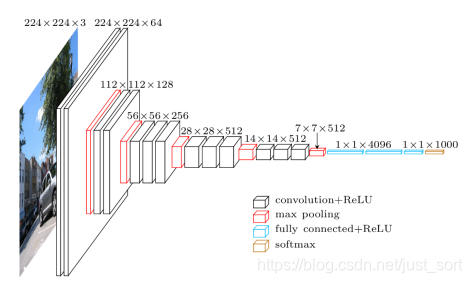
从上图可以看到网络的第一个卷积层的通道数为64,然后每一层Max Pooling之后卷积层的通道数都成倍的增加,最后接看三分全连接层完成分类任务。总的来说VGGNet的贡献可以概括如下两点:
- 所有隐藏层都使用了ReLU激活函数,而不是LRN(Local Response Normalization),因为LRN浪费了更多了内存和时间并且性能没有太大提升。
- 使用更小的卷积核和更小的滑动步长。和AlexNet相比,VGG的卷积核大小只有3\times 3和1\times 1两种。卷积核的感受野很小,因此可以把网络加深,同时使用多个小卷积核使得网络总参数量也减少了。
其中3\times 3卷积核相比于一个大尺寸的卷积核有更多的非线性函数,使得模型更有判别性。同时,多个3\times 3层比一个大的卷积核参数更少,例如假设卷积层的输出特征图和输出特征图的大小分别是C_1,C_2,那么三个3\times 3卷积核的参数为3\times 3\times 3\times C_1\times C_2=27C_1C_2。而一个7\times 7的卷积核参数为7\times 7\times C_1\times C_2。而至于为什么3个3\times 3卷积核可以代替一个7\times 7卷积核,这是因为这两者的感受野是一致的,并且多个3\times 3小卷积核非线性更多,效果更好。
而1\times 1卷积的引入是在不影响输入输出维数的情况下,对输入进行线性形变,然后通过Relu进行非线性处理,增加网络的非线性表达能力。
VGG-16的代码实现如下:
def VGG_16():
model = Sequential()
model.add(Conv2D(64,(3,3),strides=(1,1),input_shape=(224,224,3),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(64,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(128,(3,2),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(128,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(256,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(Conv2D(512,(3,3),strides=(1,1),padding='same',activation='relu',kernel_initializer='uniform'))
model.add(MaxPooling2D(pool_size=(2,2)))
model.add(Flatten())
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(4096,activation='relu'))
model.add(Dropout(0.5))
model.add(Dense(1000,activation='softmax'))
return model
后记¶
今天讲解了经典网络ZFNet和VGGNet,让我们至少明白了一个东西,神经网络在2014年这个时期是在往更深的角度去发展。同时小卷积核的堆叠可以取代大卷积核。
卷积神经网络学习路线往期文章¶
欢迎关注我的微信公众号GiantPandaCV,期待和你一起交流机器学习,深度学习,图像算法,优化技术,比赛及日常生活等。
本文总阅读量次