【GiantPandaCV导语】这篇文章是学习了比较久然后按照自己的理解步骤重新总结了下来,主要是MLIR Toy Tutorials第3,4篇文章的内容。这里主要讲解了如何在MLIR中自定义Pass,这里主要以消除连续的Transpose操作和Reshape操作,内联优化Pass,形状推导Pass 4个例子来介绍了在MLIR中定义Pass的各种技巧,实际上也并不难理解。但要入门MLIR掌握这些Pass实现的技巧是有必要的。我在从零开始学习深度学习编译器的过程中维护了一个project:https://github.com/BBuf/tvm_mlir_learn ,主要是记录学习笔记以及一些实验性代码,目前已经获得了150+ star,对深度学习编译器感兴趣的小伙伴可以看一下,能点个star就更受宠若惊了。
前言¶
在【从零开始学深度学习编译器】十一,初识MLIR 和 【从零开始学深度学习编译器】十二,MLIR Toy Tutorials学习笔记一 这两篇文章中,我们已经初步了解了MLIR为何物,并且讲到了Toy语言从源文件生成MLIR的具体过程,以及在这个过程中MLIR中的MLIRGen,Dialect,Operation以及TableGen这几个MLIR的核心组成部分以及它们是如何相互作用的。
这篇笔记将基于Toy Tutorials总结MLIR中的表达式变形是如何实现的。
Chapter3: MLIR中的表达式变形(如何写Pass)¶
在Chapter2中我们已经生成了初级的合法MLIR表达式,但MLIR表达式一般还可以被进一步处理和简化,可以类比于TVM的Pass对Relay IR的优化。这里我们来看看要对初级的MLIR表达式进行变形是如何做的?在MLIR中是基于表达式匹配和重写来完成MLIR表达式变形的。这个教程中分别介绍使用C++模板匹配和重写以及基于DRR框架(https://mlir.llvm.org/docs/DeclarativeRewrites/)来定义表达式重写规则,然后使用ODS框架来自动生成代码。
使用C++模式匹配和重写的方法优化转置(Transpose)操作¶
这里的目标是要消除两个具有相互抵消效果的转置序列:transpose(transpose(X)) -> X,即对同一个输入进行连续的Transpose操作肯定存在冗余的操作。该操作对应的源码如下(在mlir/test/Examples/Toy/Ch3/transpose_transpose.toy中):
def transpose_transpose(x) {
return transpose(transpose(x));
}
如果不使用任何优化Pass,我们看下这个Toy源程序生成的MLIR表达式是什么样子的,使用下面的命令产生MLIR:./toyc-ch3 ../../mlir/test/Examples/Toy/Ch3/transpose_transpose.toy -emit=mlir。
func @transpose_transpose(%arg0: tensor<*xf64>) -> tensor<*xf64> {
%0 = toy.transpose(%arg0 : tensor<*xf64>) to tensor<*xf64>
%1 = toy.transpose(%0 : tensor<*xf64>) to tensor<*xf64>
toy.return %1 : tensor<*xf64>
}
可以看到生成的MLIR表达式中对x进行了两次真正的transpose操作,并且返回了两次transpose之后的Tensor。但实际上这两次transpose是不必要的,因为输出的结果其实就是传入的x。所以为了优化这种情况,我们先使用C++方式来写出表达式匹配和重写的代码(在mlir/examples/toy/Ch3/mlir/ToyCombine.cpp中):
/// This is an example of a c++ rewrite pattern for the TransposeOp. It
/// optimizes the following scenario: transpose(transpose(x)) -> x
struct SimplifyRedundantTranspose : public mlir::OpRewritePattern<TransposeOp> {
/// We register this pattern to match every toy.transpose in the IR.
/// The "benefit" is used by the framework to order the patterns and process
/// them in order of profitability.
SimplifyRedundantTranspose(mlir::MLIRContext *context)
: OpRewritePattern<TransposeOp>(context, /*benefit=*/1) {}
/// This method attempts to match a pattern and rewrite it. The rewriter
/// argument is the orchestrator of the sequence of rewrites. The pattern is
/// expected to interact with it to perform any changes to the IR from here.
mlir::LogicalResult
matchAndRewrite(TransposeOp op,
mlir::PatternRewriter &rewriter) const override {
// Look through the input of the current transpose.
mlir::Value transposeInput = op.getOperand();
TransposeOp transposeInputOp = transposeInput.getDefiningOp<TransposeOp>();
// Input defined by another transpose? If not, no match.
if (!transposeInputOp)
return failure();
// Otherwise, we have a redundant transpose. Use the rewriter.
rewriter.replaceOp(op, {transposeInputOp.getOperand()});
return success();
}
};
可以看到在matchAndRewrite函数中,首先获取当前操作的操作数,然后判断当前位置的操作数对应的操作是否为转置,如果是就将表达式重写为内层转置操作的操作数,不然就不需要进行优化,保持现状。
接下来,需要在归范化框架(Canonicalization Framework)中注册刚刚创建的匹配重写模式,使得框架可以调用它。对于Canonicalization 更多的介绍请看https://mlir.llvm.org/docs/Canonicalization/,注册的代码如下(代码仍在:mlir/examples/toy/Ch3/mlir/ToyCombine.cpp):
/// Register our patterns as "canonicalization" patterns on the TransposeOp so
/// that they can be picked up by the Canonicalization framework.
void TransposeOp::getCanonicalizationPatterns(RewritePatternSet &results,
MLIRContext *context) {
results.add<SimplifyRedundantTranspose>(context);
}
在我们将表达式重写规则添加到了规范化框架后,我们还需要修改一下定义Operator的td文件,启用规范化框架,同时在定义Operator添加一个“无副作用的”(NoSideEffect)新特征,现在Transpose操作的定义如下:
def TransposeOp : Toy_Op<"transpose", [NoSideEffect]> {
let summary = "transpose operation";
let arguments = (ins F64Tensor:$input);
let results = (outs F64Tensor);
let assemblyFormat = [{
`(` $input `:` type($input) `)` attr-dict `to` type(results)
}];
// Enable registering canonicalization patterns with this operation.
let hasCanonicalizer = 1;
// Allow building a TransposeOp with from the input operand.
let builders = [
OpBuilder<(ins "Value":$input)>
];
// Invoke a static verify method to verify this transpose operation.
let verifier = [{ return ::verify(*this); }];
}
最后,我们需要在主程序中将基于规范化框架的优化添加到运行流程里,这部分代码在mlir/examples/toy/Ch3/toyc.cpp中的dumpMLIR函数里面。如下图的红框部分:
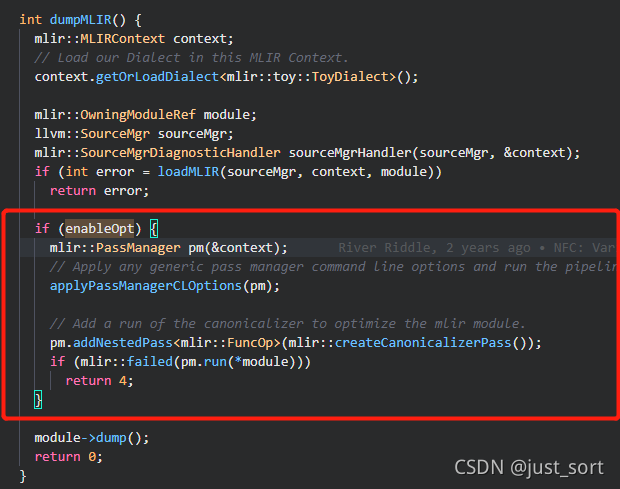
至此,我们就完成了基于C++的MLIR表达式匹配和重写,我们可以通过下面的命令来看下经过上面transpose表达式的重写后产生的MLIR表达式是否已经去掉了transpose。命令为:./toyc-ch3 ../../mlir/test/Examples/Toy/Ch3/transpose_transpose.toy -emit=mlir -opt。结果为:
func @transpose_transpose(%arg0: tensor<*xf64>) -> tensor<*xf64> {
toy.return %arg0 : tensor<*xf64>
}
可以看到优化后的MLIR表达式已经去掉了transpose操作了,达到了优化效果。
使用 DRR 优化张量变形(Reshape)操作¶
MLIR还提供了一种表达式重写的方法,是基于DDR规则的方式来自动生成表达式匹配和重写函数,代码生成的部分仍然基于ODS框架实现。DRR(Declarative, Rule-based Pattern-match and Rewrite):声明性、基于规则的模式匹配和重写方法。它是一种基于 DAG 的声明性重写器,提供基于表格的模式匹配和重写规则的句法。
这里以消除MLIR表达式中冗余的张量reshape操作为例,对应的Toy源文件如下(在mlir/test/Examples/Toy/Ch3/trivial_reshape.toy中):
def main() {
var a<2,1> = [1, 2];
var b<2,1> = a;
var c<2,1> = b;
print(c);
}
./toyc-ch3 ../../mlir/test/Examples/Toy/Ch3/trivial_reshape.toy -emit=mlir
module {
func @main() {
%0 = toy.constant dense<[1.000000e+00, 2.000000e+00]> : tensor<2xf64>
%1 = toy.reshape(%0 : tensor<2xf64>) to tensor<2x1xf64>
%2 = toy.reshape(%1 : tensor<2x1xf64>) to tensor<2x1xf64>
%3 = toy.reshape(%2 : tensor<2x1xf64>) to tensor<2x1xf64>
toy.print %3 : tensor<2x1xf64>
toy.return
}
}
很明显a,b,c的shape和值都是一样的,这些reshape操作是多余的。下面我们要基于DDR框架来定义表达式匹配和重写规则。这里要分几种情况考虑(这里的代码实现都在mlir/examples/toy/Ch3/mlir/ToyCombine.td)。
- 解决
Reshape(Reshape(x)) = Reshape(x)产生的冗余代码。
// Reshape(Reshape(x)) = Reshape(x)
def ReshapeReshapeOptPattern : Pat<(ReshapeOp(ReshapeOp $arg)),
(ReshapeOp $arg)>;
即将ReshapeOp(ReshapeOp $arg)替换为 ReshapeOp $arg。对于多次相同的张量变形操作,执行一次即可。
- 当reshape的参数和结果的类型是一样的,就说明这个整型操作是没用的,因此直接返回输入参数即可,即
Reshape(x) = x。
// Reshape(x) = x, where input and output shapes are identical
def TypesAreIdentical : Constraint<CPred<"$0.getType() == $1.getType()">>;
def RedundantReshapeOptPattern : Pat<
(ReshapeOp:$res $arg), (replaceWithValue $arg),
[(TypesAreIdentical $res, $arg)]>;
即当0.getType()与1.getType()相同时即为冗余,使用操作数$arg代替。
接下来我们就可以使用 ODS 框架和定义好的 ToyCombine.td 文件,自动化生成代码文件 ToyCombine.inc。使用下面的命令:
$ cd llvm-project/build
$ ./bin/mlir-tblgen --gen-rewriters ${mlir_src_root}/examples/toy/Ch3/mlir/ToyCombine.td -I ${mlir_src_root}/include/
当然构建工程的时候也可以将这个生成过程配置在cmakelists.txt中:mlir/examples/toy/Ch3/CMakeLists.txt。如下:
set(LLVM_TARGET_DEFINITIONS mlir/ToyCombine.td)
mlir_tablegen(ToyCombine.inc -gen-rewriters)
add_public_tablegen_target(ToyCh3CombineIncGen)
最后,我们可以执行./toyc-ch3 ../../mlir/test/Examples/Toy/Ch3/trivial_reshape.toy -emit=mlir -opt生成经过这些Pass优化的MLIR表达式:
module {
func @main() {
%0 = toy.constant dense<[[1.000000e+00], [2.000000e+00]]> : tensor<2x1xf64>
toy.print %0 : tensor<2x1xf64>
toy.return
}
}
Chapter4: 实现泛化的表达式转化¶
在Chapter3里面我们学到了如何在MLIR里面实现表达式重写,但上面也有一个非常明显的问题:我们为Toy语言实现的Pass在其它的Dialect抽象中没办法重用,因为这里只是针对Toy语言的一些Operation的特化操作,如果为每种Dialect实现每种转化会导致大量重复代码。所以,这一节以两个例子为例讲解如何在MLIR中实现泛化的表达式。
本文使用下面的例子进行介绍(在mlir/test/Examples/Toy/Ch5/codegen.toy):
def multiply_transpose(a, b) {
return transpose(a) * transpose(b);
}
def main() {
var a<2, 3> = [[1, 2, 3], [4, 5, 6]];
var b<2, 3> = [1, 2, 3, 4, 5, 6];
var c = multiply_transpose(a, b);
var d = multiply_transpose(b, a);
print(d);
}
我们先看一下它对应的MLIR表达式./toyc-ch4 ../../mlir/test/Examples/Toy/Ch4/codegen.toy -emit=mlir:
module {
func private @multiply_transpose(%arg0: tensor<*xf64>, %arg1: tensor<*xf64>) -> tensor<*xf64> {
%0 = toy.transpose(%arg0 : tensor<*xf64>) to tensor<*xf64>
%1 = toy.transpose(%arg1 : tensor<*xf64>) to tensor<*xf64>
%2 = toy.mul %0, %1 : tensor<*xf64>
toy.return %2 : tensor<*xf64>
}
func @main() {
%0 = toy.constant dense<[[1.000000e+00, 2.000000e+00, 3.000000e+00], [4.000000e+00, 5.000000e+00, 6.000000e+00]]> : tensor<2x3xf64>
%1 = toy.reshape(%0 : tensor<2x3xf64>) to tensor<2x3xf64>
%2 = toy.constant dense<[1.000000e+00, 2.000000e+00, 3.000000e+00, 4.000000e+00, 5.000000e+00, 6.000000e+00]> : tensor<6xf64>
%3 = toy.reshape(%2 : tensor<6xf64>) to tensor<2x3xf64>
%4 = toy.generic_call @multiply_transpose(%1, %3) : (tensor<2x3xf64>, tensor<2x3xf64>) -> tensor<*xf64>
%5 = toy.generic_call @multiply_transpose(%3, %1) : (tensor<2x3xf64>, tensor<2x3xf64>) -> tensor<*xf64>
toy.print %5 : tensor<*xf64>
toy.return
}
}
这个是没有优化前的MLIR表达式,我们可以看到在实例化Tensor之前Tensor的形状是未知的,即表达式中的tensor<*xf64>。这样会对后续的Pass,比如我们在Chapter3中定义的形状相关的Pass造成影响,导致优化不到位。所以我们希望在执行Reshape相关的Pass之前可以知道每个Tensor的形状,所以这里会介绍一个Shape推断Pass的实现。另外,还介绍了一个内联Pass,来降低函数调用的开销。
内联Pass¶
观察上面的代码我们可以发现multiply_transpose这种小函数被频繁调用,这个时候函数调用本身的开销就不容忽视。所以这里定义一个内联Pass希望把multiply_transpose这个函数变成内联函数以提高运行效率。
第一步¶
MLIR提供了一个处理内联的通用接口DialectInlinerInterface ,它包含一组Dialect可以重写的虚拟钩子,我们要基于这个类为Toy Operation定义内联的接口和表达式重写规则。代码实现在:mlir/examples/toy/Ch5/mlir/Dialect.cpp:
/// This class defines the interface for handling inlining with Toy operations.
/// We simplify inherit from the base interface class and override
/// the necessary methods.
struct ToyInlinerInterface : public DialectInlinerInterface {
using DialectInlinerInterface::DialectInlinerInterface;
/// This hook checks to see if the given callable operation is legal to inline
/// into the given call. For Toy this hook can simply return true, as the Toy
/// Call operation is always inlinable.
bool isLegalToInline(Operation *call, Operation *callable,
bool wouldBeCloned) const final {
return true;
}
/// This hook checks to see if the given operation is legal to inline into the
/// given region. For Toy this hook can simply return true, as all Toy
/// operations are inlinable.
bool isLegalToInline(Operation *, Region *, bool,
BlockAndValueMapping &) const final {
return true;
}
/// This hook is called when a terminator operation has been inlined. The only
/// terminator that we have in the Toy dialect is the return
/// operation(toy.return). We handle the return by replacing the values
/// previously returned by the call operation with the operands of the
/// return.
void handleTerminator(Operation *op,
ArrayRef<Value> valuesToRepl) const final {
// Only "toy.return" needs to be handled here.
auto returnOp = cast<ReturnOp>(op);
// Replace the values directly with the return operands.
assert(returnOp.getNumOperands() == valuesToRepl.size());
for (const auto &it : llvm::enumerate(returnOp.getOperands()))
valuesToRepl[it.index()].replaceAllUsesWith(it.value());
}
};
这部分代码为Toy Operation定义了内联的接口和表达式变形的规则,两个isLegalToInline重载函数是两个钩子。第一个钩子用来检查给定的可调用操作callable内联到给定调用call中是否合法,检查是否可以内联。第二个钩子用来检查给定的操作是否合法地内联到给定的区域。handleTerminator函数只是处理toy.return,将返回操作的操作数it.index()直接用返回值it.value()代替(这里没太懂QAQ)。
第二步¶
接着,需要在Toy Dialect的定义中添加上面的表达式变形规则,位置在mlir/examples/toy/Ch5/mlir/Dialect.cpp。
/// Dialect initialization, the instance will be owned by the context. This is
/// the point of registration of types and operations for the dialect.
void ToyDialect::initialize() {
addOperations<
#define GET_OP_LIST
#include "toy/Ops.cpp.inc"
>();
addInterfaces<ToyInlinerInterface>();
}
这里的addInterfaces<ToyInlinerInterface>()就是注册内联Pass的过程,其中ToyInlinerInterface就是我们定义的表达式变形规则。
第三步¶
再接着,我们需要让内联器inliner知道IR中toy.generic_call表示的是调用一个函数。MLIR提供了一个Operation接口CallOpInterface可以将某个Operation标记为调用。添加上述操作需要在Toy Dialect的定义(mlir/examples/toy/Ch5/include/toy/Ops.td)文件中加入include "mlir/Interfaces/CallInterfaces.td"这行代码。
然后在Dialect定义部分添加一个新的Operation,代码如下所示:
def GenericCallOp : Toy_Op<"generic_call",
[DeclareOpInterfaceMethods<CallOpInterface>]> {
let summary = "generic call operation";
let description = [{
Generic calls represent calls to a user defined function that needs to
be specialized for the shape of its arguments. The callee name is attached
as a symbol reference via an attribute. The arguments list must match the
arguments expected by the callee. For example:
```mlir
%4 = toy.generic_call @my_func(%1, %3)
: (tensor<2x3xf64>, tensor<2x3xf64>) -> tensor<*xf64>
This is only valid if a function named "my_func" exists and takes two
arguments.
}];
// The generic call operation takes a symbol reference attribute as the
// callee, and inputs for the call.
let arguments = (ins FlatSymbolRefAttr:$callee, Variadic<F64Tensor>:$inputs);
// The generic call operation returns a single value of TensorType.
let results = (outs F64Tensor);
// Specialize assembly printing and parsing using a declarative format.
let assemblyFormat = [{
$callee `(` $inputs `)` attr-dict `:` functional-type($inputs, results)
}];
// Add custom build methods for the generic call operation.
let builders = [
OpBuilder<(ins "StringRef":$callee, "ArrayRef<Value>":$arguments)>
];
}
解释:我们使用了DeclareOpInterfaceMethods在CallOpInterface的声明中声明所用的接口方法。DeclareOpInterfaceMethods这个特征说明程序会识别generic_call操作(在原始的MLIR表达式中对应toy.generic_call),并在该位置调用接口函数。
然后在mlir/examples/toy/Ch5/mlir/Dialect.cpp中实现了GenericCallOp的功能,代码如下:
/// Return the callee of the generic call operation, this is required by the
/// call interface.
CallInterfaceCallable GenericCallOp::getCallableForCallee() {
return getAttrOfType<SymbolRefAttr>("callee");
}
/// Get the argument operands to the called function, this is required by the
/// call interface.
Operation::operand_range GenericCallOp::getArgOperands() { return inputs(); }
上面的GenericCallOp::getCallableForCallee() {...} 返回泛化调用Operation的被调用方。而GenericCallOp::getArgOperands(){...}用来获取被调用函数的参数操作数。
第四步¶
下面需要在Dialect定义中添加cast操作并设置调用的接口。为什么需要添加cast操作呢?这是因为在函数调用时,输入张量的类型是确定的。但在函数定义的时候,输入张量的类型是不确定的(泛化类型,这一点可以从上面的原始版本MLIR表达式中看出来)。因此在调用的时候就需要一个隐藏的数据类型转换,否则无法进行内联操作,因此这里引入了一个cast。cast操作可以将确定的数据类型转换为函数期望的数据类型。下面在mlir/examples/toy/Ch5/include/toy/Ops.td中添加cast操作:
def CastOp : Toy_Op<"cast", [
DeclareOpInterfaceMethods<CastOpInterface>,
DeclareOpInterfaceMethods<ShapeInferenceOpInterface>,
NoSideEffect,
SameOperandsAndResultShape
]> {
let summary = "shape cast operation";
let description = [{
The "cast" operation converts a tensor from one type to an equivalent type
without changing any data elements. The source and destination types must
both be tensor types with the same element type. If both are ranked, then
shape is required to match. The operation is invalid if converting to a
mismatching constant dimension.
}];
let arguments = (ins F64Tensor:$input);
let results = (outs F64Tensor:$output);
let assemblyFormat = "$input attr-dict `:` type($input) `to` type($output)";
}
我们使用了DeclareOpInterfaceMethods在CallOpInterface的声明中声明所用的接口方法。DeclareOpInterfaceMethods这个特征说明程序会识别cast操作。
接下来还需要重写cast op的areCastCompatible方法(在mlir/examples/toy/Ch5/mlir/Dialect.cpp中):
/// Returns true if the given set of input and result types are compatible with
/// this cast operation. This is required by the `CastOpInterface` to verify
/// this operation and provide other additional utilities.
bool CastOp::areCastCompatible(TypeRange inputs, TypeRange outputs) {
if (inputs.size() != 1 || outputs.size() != 1)
return false;
// The inputs must be Tensors with the same element type.
TensorType input = inputs.front().dyn_cast<TensorType>();
TensorType output = outputs.front().dyn_cast<TensorType>();
if (!input || !output || input.getElementType() != output.getElementType())
return false;
// The shape is required to match if both types are ranked.
return !input.hasRank() || !output.hasRank() || input == output;
}
这个方法用来判断是否需要进行类型转换,如果inputs和outputs的类型是兼容的泽返回真,否则需要进行类型转换(cast)返回假。
另外我们还需要重写ToyInlinerInterface 上的钩子,即materializeCallConversion函数:
struct ToyInlinerInterface : public DialectInlinerInterface {
....
/// Attempts to materialize a conversion for a type mismatch between a call
/// from this dialect, and a callable region. This method should generate an
/// operation that takes 'input' as the only operand, and produces a single
/// result of 'resultType'. If a conversion can not be generated, nullptr
/// should be returned.
Operation *materializeCallConversion(OpBuilder &builder, Value input,
Type resultType,
Location conversionLoc) const final {
return builder.create<CastOp>(conversionLoc, resultType, input);
}
};
这个函数是内联Pass的入口。
第五步¶
将内联Pass添加到优化pipline中,在mlir/examples/toy/Ch5/toyc.cpp中:
if (enableOpt) {
mlir::PassManager pm(&context);
// Apply any generic pass manager command line options and run the pipeline.
applyPassManagerCLOptions(pm);
// Inline all functions into main and then delete them.
pm.addPass(mlir::createInlinerPass());
...
}
经过pm.addPass(mlir::createInlinerPass());这一行,优化pipline里面就有了内联Pass了。
我们看一下经过内联优化Pass过后原始的MLIR表达式变成什么样子了:
func @main() {
%0 = "toy.constant"() {value = dense<[[1.000000e+00, 2.000000e+00, 3.000000e+00], [4.000000e+00, 5.000000e+00, 6.000000e+00]]> : tensor<2x3xf64>} : () -> tensor<2x3xf64>
%1 = "toy.constant"() {value = dense<[[1.000000e+00, 2.000000e+00, 3.000000e+00], [4.000000e+00, 5.000000e+00, 6.000000e+00]]> : tensor<2x3xf64>} : () -> tensor<2x3xf64>
%2 = "toy.cast"(%1) : (tensor<2x3xf64>) -> tensor<*xf64>
%3 = "toy.cast"(%0) : (tensor<2x3xf64>) -> tensor<*xf64>
%4 = "toy.transpose"(%2) : (tensor<*xf64>) -> tensor<*xf64>
%5 = "toy.transpose"(%3) : (tensor<*xf64>) -> tensor<*xf64>
%6 = "toy.mul"(%4, %5) : (tensor<*xf64>, tensor<*xf64>) -> tensor<*xf64>
toy.print %6 : tensor<*xf64>
toy.return
}
现在MLIR表达式只有一个主函数,之前的transpose函数被内联了,并且可以看到toy.cast实现的功能。
Shape推断 Pass¶
上面内联Pass实现了将确定类型的Tensor转换成了泛化类型的Tensor,进而使得内联操作得以完成。然后接下来,我们需要根据形状确定的Tensor来推导那些泛化Tensor的形状。这里需要利用ODS框架来生成自定义的Operation接口来推导泛化Tensor的形状。整个Shape推断的过程也会和inline一样抽象成一个Pass作用在MLIR表达式上。
第一步:使用ODS框架定义Shape推断Operation接口¶
代码实现在mlir/examples/toy/Ch5/include/toy/ShapeInferenceInterface.td
def ShapeInferenceOpInterface : OpInterface<"ShapeInference"> {
let description = [{
Interface to access a registered method to infer the return types for an
operation that can be used during type inference.
}];
let methods = [
InterfaceMethod<"Infer and set the output shape for the current operation.",
"void", "inferShapes">
];
}
ShapeInferenceOpInterface接口继承了OpInterface,该继承接收要赋予生成的 C++ 接口类的名称"ShapeInference"作为模板参数。description字段提供了Operation的简要说明,而methods字段定义Operation将需要提供的接口方法。
第二步:将特征添加到必要的 Toy Operation定义中¶
以Toy语言的Mul Operation为例,实现在mlir/examples/toy/Ch5/include/toy/Ops.td:
def MulOp : Toy_Op<"mul",
[NoSideEffect, DeclareOpInterfaceMethods<ShapeInferenceOpInterface>]> {
let summary = "element-wise multiplication operation";
let description = [{
The "mul" operation performs element-wise multiplication between two
tensors. The shapes of the tensor operands are expected to match.
}];
let arguments = (ins F64Tensor:$lhs, F64Tensor:$rhs);
let results = (outs F64Tensor);
// Specify a parser and printer method.
let parser = [{ return ::parseBinaryOp(parser, result); }];
let printer = [{ return ::printBinaryOp(p, *this); }];
// Allow building a MulOp with from the two input operands.
let builders = [
OpBuilder<(ins "Value":$lhs, "Value":$rhs)>
];
}
上面的代码中,DeclareOpInterfaceMethods<ShapeInferenceOpInterface>为Mul Operation添加了形状推导的特征,和内联Pass里面的将CallOpInterface特征添加到cast Operation类似。
第三步:定义对应Operation的形状推导函数¶
需要进行形状推导的每个Operation,都需要定义对应的inferShapes()函数,比如Mul Operation,结果的形状就是输入的形状(因为是elementwise操作)。代码实现在mlir/examples/toy/Ch5/mlir/Dialect.cpp:
/// Infer the output shape of the MulOp, this is required by the shape inference
/// interface.
void MulOp::inferShapes() { getResult().setType(getOperand(0).getType()); }
第四步:实现形状推导Pass¶
这一步是介绍形状推导Pass的具体实现,前面几步是这一步的前置条件。这一步定义一个形状推导Pass类来实现Shape推断算法,并会基于这个Pass类来创建一个Shape推断的Pass。代码实现在mlir/examples/toy/Ch5/mlir/ShapeInferencePass.cpp。
class ShapeInferencePass
: public mlir::PassWrapper<ShapeInferencePass, FunctionPass> {
public:
void runOnFunction() override {
auto f = getFunction();
// Populate the worklist with the operations that need shape inference:
// these are operations that return a dynamic shape.
llvm::SmallPtrSet<mlir::Operation *, 16> opWorklist;
f.walk([&](mlir::Operation *op) {
if (returnsDynamicShape(op))
opWorklist.insert(op);
});
// Iterate on the operations in the worklist until all operations have been
// inferred or no change happened (fix point).
while (!opWorklist.empty()) {
// Find the next operation ready for inference, that is an operation
// with all operands already resolved (non-generic).
auto nextop = llvm::find_if(opWorklist, allOperandsInferred);
if (nextop == opWorklist.end())
break;
Operation *op = *nextop;
opWorklist.erase(op);
// Ask the operation to infer its output shapes.
LLVM_DEBUG(llvm::dbgs() << "Inferring shape for: " << *op << "\n");
if (auto shapeOp = dyn_cast<ShapeInference>(op)) {
shapeOp.inferShapes();
} else {
op->emitError("unable to infer shape of operation without shape "
"inference interface");
return signalPassFailure();
}
}
// If the operation worklist isn't empty, this indicates a failure.
if (!opWorklist.empty()) {
f.emitError("Shape inference failed, ")
<< opWorklist.size() << " operations couldn't be inferred\n";
signalPassFailure();
}
}
/// A utility method that returns if the given operation has all of its
/// operands inferred.
static bool allOperandsInferred(Operation *op) {
return llvm::all_of(op->getOperandTypes(), [](Type operandType) {
return operandType.isa<RankedTensorType>();
});
}
/// A utility method that returns if the given operation has a dynamically
/// shaped result.
static bool returnsDynamicShape(Operation *op) {
return llvm::any_of(op->getResultTypes(), [](Type resultType) {
return !resultType.isa<RankedTensorType>();
});
}
};
} // end anonymous namespace
/// Create a Shape Inference pass.
std::unique_ptr<mlir::Pass> mlir::toy::createShapeInferencePass() {
return std::make_unique<ShapeInferencePass>();
}
ShapeInferencePass继承了FunctionPass,重写其runOnFunction()接口,实现Shape推断算法。首先会创建一个输出返回值为泛化Tensor的Operation列表,然后遍历列表寻找输入的操作数时类型确定的Tensor的Operarion,如果没有找到退出循环,否则把该Operation从循环中删除并调用相应的inferShape()函数推断该Operation的输出返回Tensor的shape。如果Operation列表为空,则算法结束。
第五步:把形状推导Pass加到优化pipline¶
和内联Pass类似,需要把形状推导Pass加到优化pipline里面去。上面内联Pass那里已经展示过了,不再重复贴代码。
至此,我们就完成了内联Pass和形状推导Pass的实现,让我们看看经过这两个Pass优化之后的MLIR表达式长什么样子吧。执行./toyc-ch4 ../../mlir/test/Examples/Toy/Ch4/codegen.toy -emit=mlir -opt 获得了优化后的MLIR表达式:
module {
func @main() {
%0 = toy.constant dense<[[1.000000e+00, 2.000000e+00, 3.000000e+00], [4.000000e+00, 5.000000e+00, 6.000000e+00]]> : tensor<2x3xf64>
%1 = toy.transpose(%0 : tensor<2x3xf64>) to tensor<3x2xf64>
%2 = toy.mul %1, %1 : tensor<3x2xf64>
toy.print %2 : tensor<3x2xf64>
toy.return
}
}
参考文章¶
- https://zhuanlan.zhihu.com/p/106472878
- https://www.zhihu.com/people/CHUNerr/posts
- https://mlir.llvm.org/docs/Tutorials/Toy/Ch-4/
本文总阅读量次