多面体模型设计初衷是更智能的在深度学习编译器内,对多种算子进行很好的融合(fuse),以及优化
场景引入¶
我们举一个简单的场景,下面是一段伪代码,代码分别做了以下三个事情
- 量化操作
- 卷积操作
- ReLU激活操作
for(h=0;h<H;h++)
for(w=0;w<W;w++)
A[h][w] = Quant(A[h][w]) /*S0*/
for(h=0;h<H;h++)
for(w=0;w<W;w++){
C[h][w] = 0; /*S1*/
for(kh=0;kh<kH;kh++)
for(kh=0;kh<kH;kh++)
C[h][w] += A[h+kh][w+kw]*B[kh][kw]; /*S2*/ 这里就是在做一个卷积操作
}
for(h=0;h<H;h++)
for(w=0;w<W;w++)
C[h][w] = ReLU(C[h][w]) /*S3*/ 这里在做ReLU激活
我们可以把上述的操作,分成四个阶段,从S0开始到S3
可以发现不同阶段的代码是有先后顺序的
第一阶段,我们需要先对A数组做一个量化操作。
第二阶段,需要对特征图数组做初始化,才能允许后面卷积正常执行。
第三阶段是做卷积操作,依赖于前两个阶段的完成。
第四阶段是读取特征图数组,做ReLU激活。
根据读写顺序,我们可以抽象出一个依赖关系
我们给每个语句,做一个时间戳处理
[S0(h, w)->(0, h, w);S1(h, w)->(1, h, w, 0, 0);S2(h, w, kh, kw)->(1, h, w, 1, kh, kw);S3(h, w)->(2,h,w)]
X - > Y,右边Y是一个最大为6维的时间节点
比如我们看第一个S0和第二个S1
按照字典序,第一个0小于第二个的1。因此S0是要在S1之前做的
然后看S1第四个数值是0,而S2第四个数值为1,因此S1需要在S2之前做。
这里我们是跟原始程序的运行顺序是一致的,只不过是换了种表示方式。
多面体模型要做的就是根据原始的调度顺序,求解出一个新的,更优的指令调度顺序

这个是新的调度结果,这个调度顺序会有更好的并行性能,后面我们会讲解。
初步优化¶
首先我们看S3,这是个RELU语句,我们完全可以在卷积的那个循环里,就做RELU激活,因此S3的循环是可以放到S1, S2那部分的

我们现在暂时少去了一个循环,优化了访存性能
补充说明:¶
可以观察到第一个S0由两个for循环,变成了四个for循环。
这实际上是做了个分块处理
放到GPU里是怎么做的?¶
GPU里面是有两个层级的并行硬件
一个是Block,一个是Thread
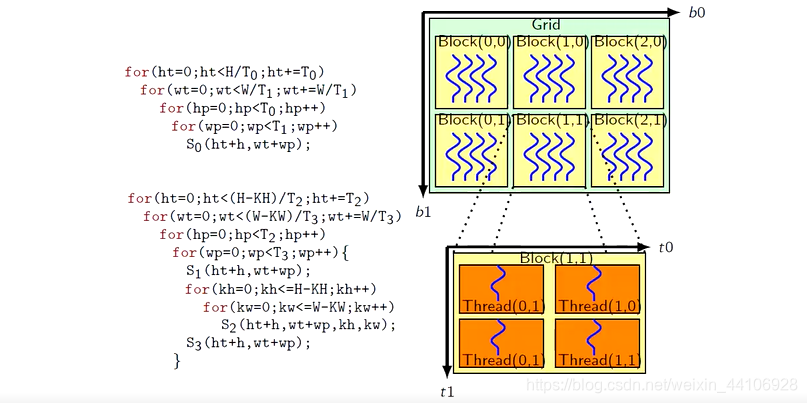
如果将指令映射到对应的节点上,那么我们程序就会获得并行性能
前面我们讲到了S0的四层分块循环,我们就可以很好的指令分散到Block和Thread两种并行硬件
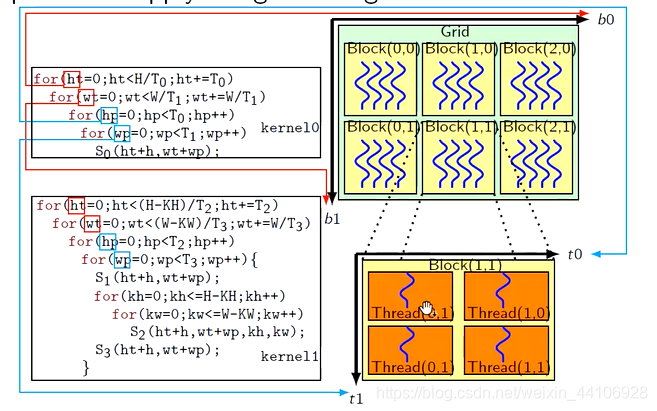
前面两个分块的for循环分配到了Grid,后面两个for循环被分配到了Block上
数据交换发生¶
S0这部分做完以后,数据是放在GPU显存上的。
由于后面S1 S2 S3需要用到这部分,所以GPU的数据要出来,放到CPU的主存上,让后面的指令来取数据。
这里就发生了数据交换
所以我们在想,能不能把S0和后面的S1,S2,S3给合并,这样我们数据一次都不需要取,减少了访存消耗。
数据空间的冲突¶
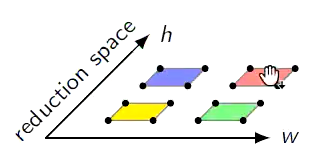
上述的操作有量化和卷积,我们可以作为一个二维空间进行展示

在分块之前,整个操作都是一个二维空间(我们先只关心最外2层的for循环)
为什么我们不能合并操作呢?主要是数据空间上发生了冲突
我们假设对量化的部分做分块,是4x4大小。对卷积的部分做分块,是2x2大小,那么效果如下
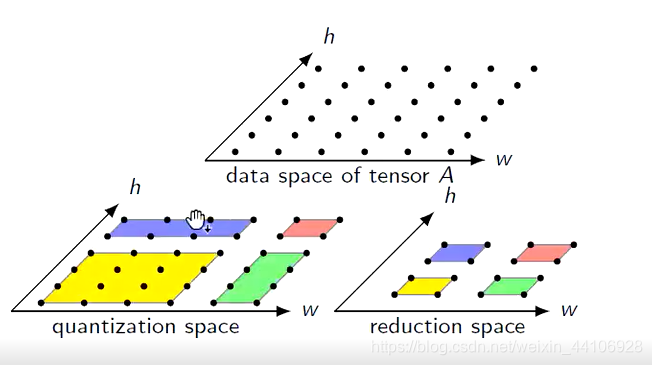
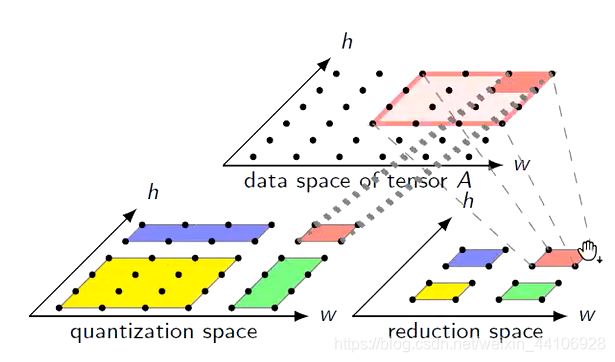
如果能融合,就需要保证相同分块,所访问到的数据是一致的
但在这个例子里,两个空间的红色方块对应的数据空间是不一致的,也就导致为什么无法融合
转换下分块思维¶
我们不同时对两个空间做分块,只考虑卷积部分做分块
进而,我们可以得知需要多少数据量

可以看到每一个块需要的是4x4数据空间,其中有数据交叉部分,这也是有一定的性能损耗原因
通过这个数据空间的情况,我们再逆推S0的空间分块

可以看到逆推的结果跟之前的不一样,同样存在数据交叉的情况
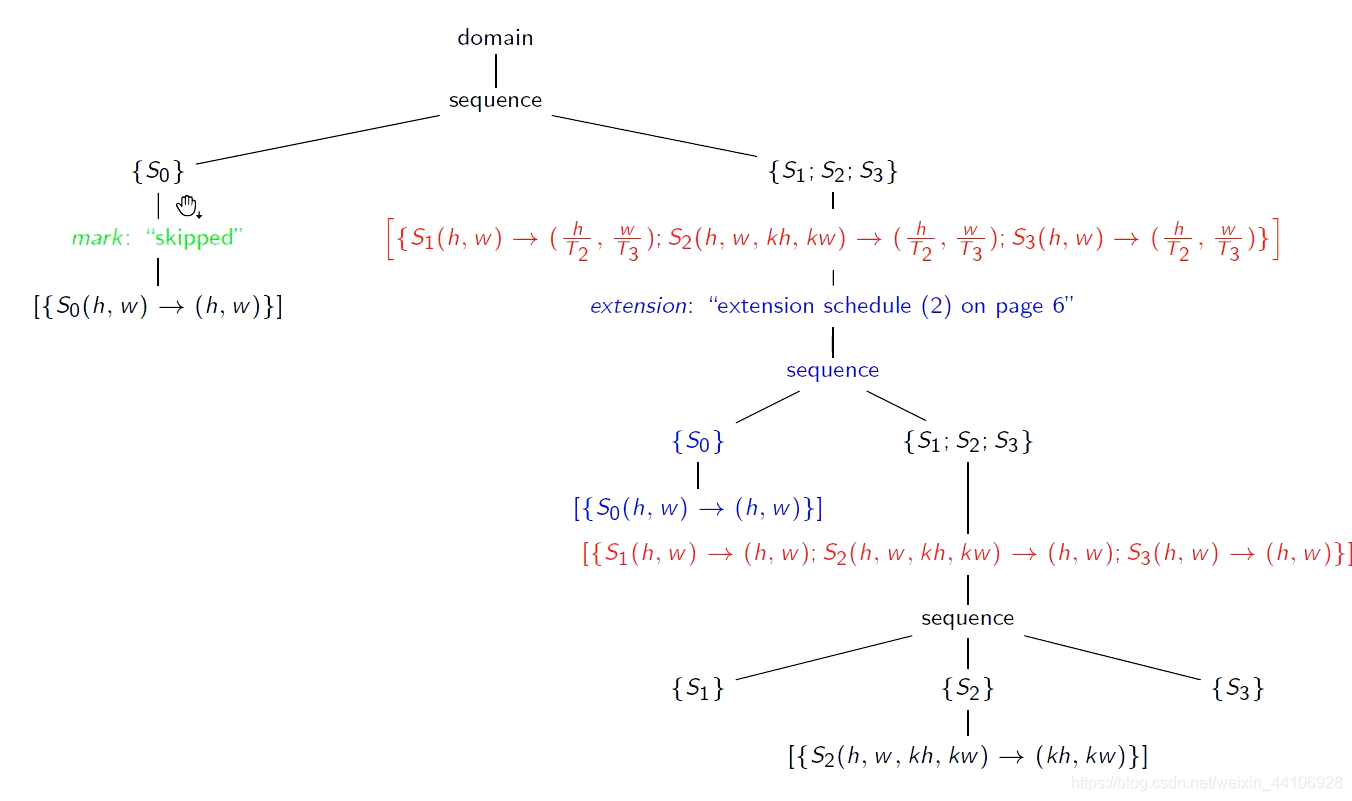
调度树¶
我们可以将调度方式,以一个树的形式来描述
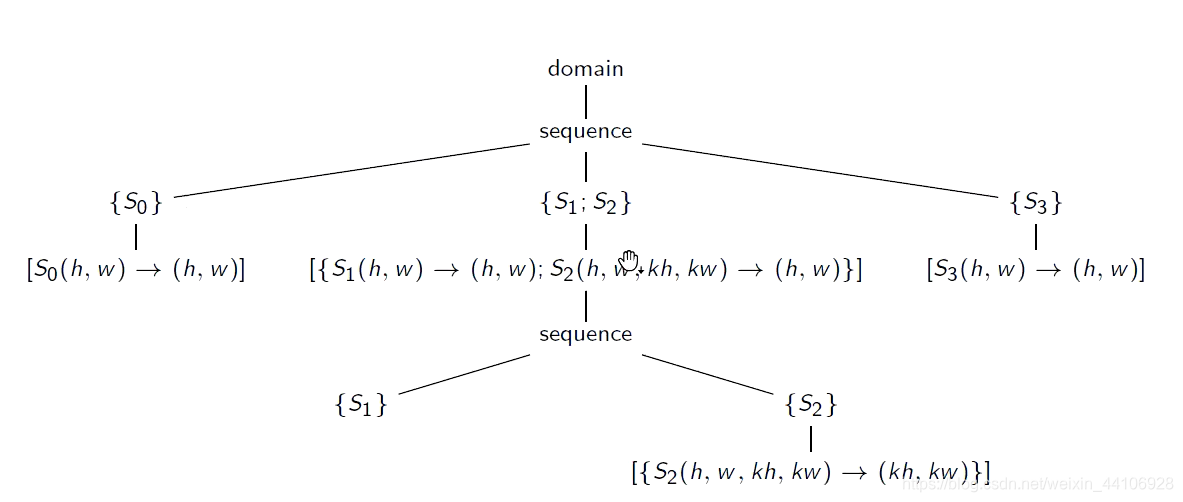
这样我们优化的就是树结构,不需要看原始代码
如何做fusion融合操作?¶
原始的树结构为
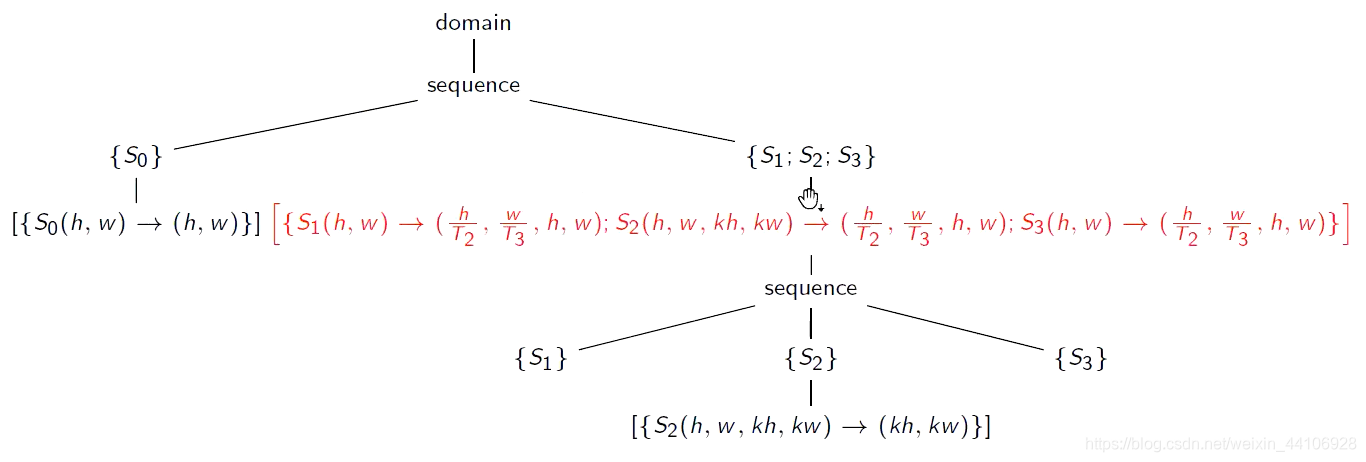
首先我们对S1,S2,S3做一个分块
这就是我们前面提到的对外层两层for循环做分块
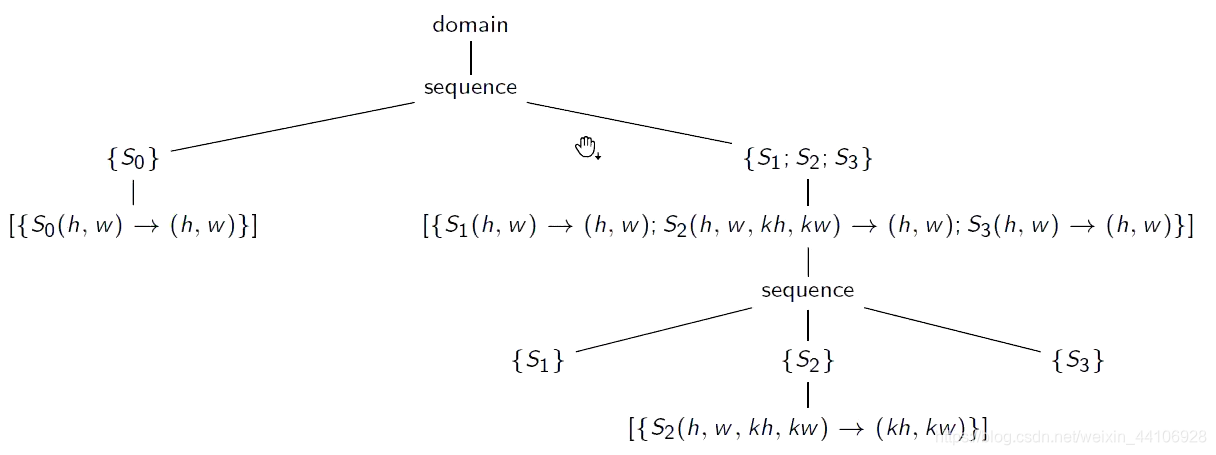
接着是对内循环优化
我们先将S0节点拷贝过来

右边S1,S2,S3子树是没有S0的,现在为了让S1,S2,S3认识S0,我们将其当作一个节点复制过来
叫 extension 节点
这样根据前面推导我们完成了融合,但是左边的树还存在S0,显然调度两次是不正确的,因此我们给左边的S0标记一个skipped,告诉编译器跳过
最终代码对应结果¶

本文总阅读量次