MLSys 15_884 Course Introduction
本来是在找一些有趣的关于mlsys的paper,突然发现,相比我刚刚读Ph.D.那会,这个domain变得越来越火了,包括MLSys2022,OSDI2022好多这方面的paper,目测9月开WLK前,我都有大把的时间来搞这些东西,所以,这次肯定是能够把坑填完的。同时也发现爱丁堡的麦络老师也写了一本不错的关于mlsys的书籍:
机器学习系统:设计和实现 - 机器学习系统:设计和实现 1.0.0 documentation
推荐初学的小伙伴可以同时通过阅读此书籍来掌握mlsys的一些基本知识。这个系列的文章, 准备主打CMU的machine learning systems课程,上catalyst的web搜了下,有两门课:15-849和884。zhihao jia的15-849其实和tianqi chen的15-884有很多相同的成分,所以这个系列的blog,我会选取这两个课程的并集,将所有涵盖的slides,和paper reading都根据自己的理解讲一遍,由于本人也是一个mlsys的菜狗,如果有什么错误和我理解不到位的地方,欢迎大家一起交流学习。我写东西比较详(啰)细(嗦),为了后续能给大家带来更好的体验,有什么建议和意见,都可以告诉我!
本讲对应课程的第一节slides:

机器学习,尤其深度学习已经变得非常成功了,包括计算机视觉,自动加速,机器翻译,游戏体育很多东西都离不开ML的影子。像目标检测中的1-stage,2-stage的detector,自动驾驶中的道路线检测和3D vision等等。
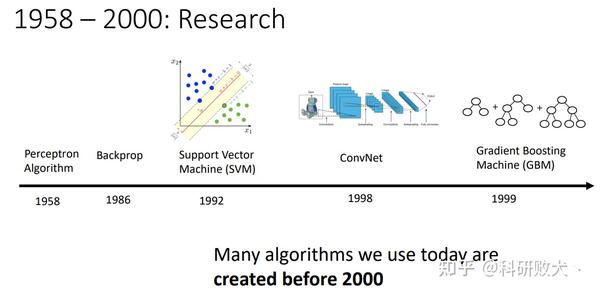
从时间轴,我们可以看出,从1958年感知器算法的问世,再到1986反向传播算法的出现,92年SVM的诞生,98年的第一个卷积神经网络到99年基于梯度上升的GBM。那一个简单的问题就是:ML算法的研究其实很早就开始了,为什么真正到了2000年以后才这么成功?

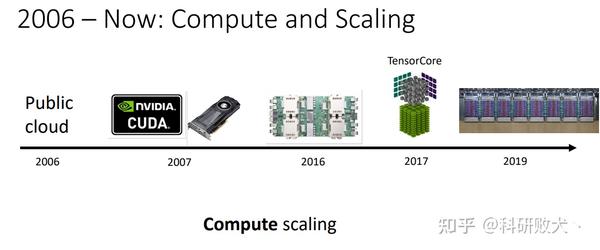
这其实就要从ML的三驾马车开始谈起:1)ML算法,2)数据集,3)硬件算力。2010年ImageNet数据集的开源,催生了alexnet到resnet等一系列牛逼的backbone网络,在image classification,objection detection,segmentation上都刷到了前所未有的成绩。当然这一切更离不开底层算力的更新,从最早的必须在两块GTX 580上同时进行backend来merge梯度信息才能把一个仅仅只有几层的AlexNet训起来,再到基于Volta,Turing,Ampere架构不同算力的GPU可以随便训练一百多层的网络。所以,ML算法的繁荣真正离不开越来越多的数据集和可以为不同算法提供算力的硬件平台。
那MLSys本质是在研究什么问题呢?
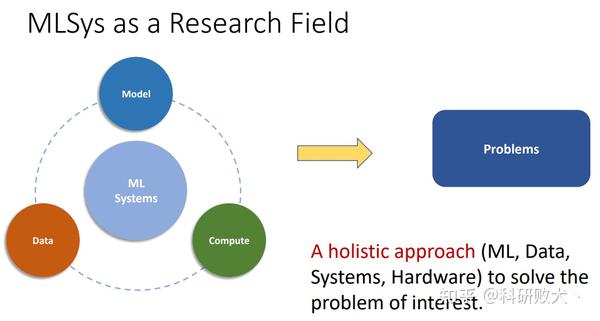
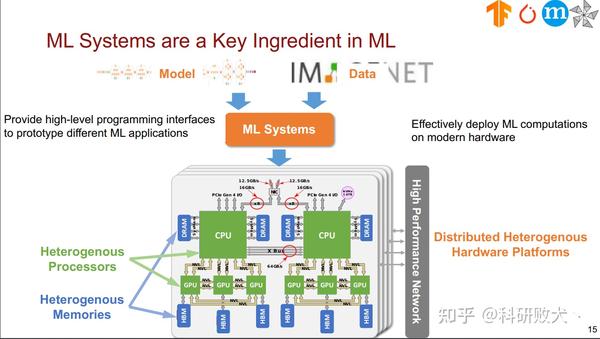
其实要想知道确切的答案通过上面这两张图就能看出来,你也可以通过查询MLSys的官网,从call for paper的topic就知道mlsys究竟是想要去解决什么样的问题:

从mlsys的官网,我们可以看出,对mlsys的解释,就是去研究machine+system的交叉领域。接下来,我将根据个人的理解对我所了解的领域做个简单的介绍:
- Efficient model training, inference, and serving: 研究的就是如何在多机多卡,单机多卡,单机单卡上更快的训练模型,同时研究一些新的算法,比如量化,剪枝,蒸馏或者编译技术去加速模型的推理。
- ML programming models and abstractions: 研究如何更好的去定义ML算法,设计不同的abstraction层次,更好的根据不同的hardware来描述我们的ML算法。
- Programming languages for machine learning: 研究如何定义一个DSL来描述我们需要加速的算力,当然这就涉及到了很多PL的知识,包括如何将Python的AST映射到你设计的DSL的AST,在到你设计的IR,到MLIR/LLVM IR再到一个device上能跑的指令的过程。
- Specialized hardware for machine learning: 研究如何针对训练和推理所需要的不同算力和访存去设计专有的ASIC,比如google的TPU,华为的昇腾,阿里的平头哥,百度的昆仑,寒武纪,地平线的各种板子。
- Machine Learning for Systems: 又叫ML4Sys, 我的理解就是通过设计高效的ML算法来帮助系统的设计,比如最为常见的就是在tvm中,通过设计一个cost model+search算法,来帮我们在一个design space中找到一组最优的configuration来帮助我们在不同的hardware platform上做高效的inference。
- Systems for Machine Learning: 又叫做Sys4ML,它的意思就是通过build一个可以work的系统来帮助机器学习算法高效的运行。最经典的例子就是各种帮助我们训练模型的深度学习框架,比如pytorch,tensorflow,caffe等。
- Distributed and parallel learning algorithms: 这部分的内容就比较经典了,因为他和高性能计算有很大的重合,本质就是研究如何通过一个集群来高效的把你的大模型更快更好的训出来的问题,而parallel computing目前也成为mlsys中的一个重要成分,包括这几年如何去探索inter-,intra-operator并行的话题已经在inference和training中都得到了落地,这部分我将在今后作为单独的一个blog好好聊聊。
- ML compilers and runtime: 这应该是我最擅长的一个话题了(毕竟整个Ph.D.都得靠水这个方向来混饭吃),ASPLOS 2021上,chris lattner已经宣告未来是编译器研究的黄金时期,当然并不排除其他原因才让他这样说的。比较流行的ml compiler包括google的xla(貌似现在已经合并到了jax里?),octoml的tvm,以及通过mlir构建的各种以polyhedral compilation为主的编译器,等等。当然光光有compiler还不够,因为compiler能做的仅仅是一个codegen的过程,针对不同的硬件平台生成所谓的tensor program,或者更为底层的指令集。在硬件上真正能跑起来的,还必须是一套完整的runtime system。那么,关于codegen和runtime的构建就变得难舍难分了,为了能够将一段程序或者神经网络中的一个op高效的map到特定硬件(DSA)上,很多work都是靠compiler来完成的。
- Hardware-efficient ML methods: 这部分研究的内容其实就比较偏向设计算法来高效结合硬件落地的话题,比如binary network,addernet,以及任意bit的量化,网络的重参数化(RepVGG, RepLKNet) 等。
- all in all:都别急,以上这些topic我都会伴随这门课程的各个章节穿插对其进行深入讲解,希望大家能够一键三连啊 (收藏+点赞+关注)
综上,如果你是即将踏入MLSys的新人,或者是一个已经征战沙场的老兵,我觉得只要从上面这些topic来找到一个适合自己兴趣的来研究,都很有可能做出非常棒的工作。这门课的目的就是为了让同学们去学习mlsys里的基础概念,通过阅读学术界比较前沿和solid的paper来加深对于mlsys的理解,知道其中各个成分之间是如何交互的。

第一讲的主要内容其实已经完结了,zhihao jia附带了一个“How to read paper”的教程,我觉得其实还蛮有意思的。链接如下:
https://www.cs.cmu.edu/~zhihaoj2/papers/HowtoReadPaper.pdf
其实,在阅读paper的过程中,就是在了解别人怎么整理work,怎么阐述work的过程,这对于一个出色的researcher是必须要具备的能力。

总价下来就是:
- 我们必须要知道这篇paper在尝试解决一个什么问题?
- 这篇paper的motivation是什么?
- 为什么先前的方法都不能解决该问题?
- 这篇paper的novelty是什么?
- 实验结果是否powerful?
仔细想想,我们在review同行的paper的过程中,高素质的reviewer也基本遵循着这样的规则。
那么在关于这门课给出的paper,我也会将所有的这些paper按照同样的方式来整理:

- 首先给出paper的high-level idea?
- 然后说明他要解决一个什么样的问题?
- 为什么这是一个值得我们去关注的问题?
- paper中用到的关键技术都有哪些?

- 这篇paper的主要contribution有哪些,该paper如果中了,在community会不会变得popular?
- 当前的一些limitation有哪些?
- 我们该怎么提升这些缺陷?
OK,第一讲的内容就先讲这么多。关于第二讲,我会继续按照课程的schedule来讲述一些常见的DNN和帮助我们搭建DNN的深度学习框架。
本文总阅读量次