OpenAI/Triton MLIR 第一章: Triton DSL¶
本文首发于GiantPandaCV,未经作者允许不得转载¶
前言¶
上一章的反响还不错,很多人都私信催更想看Triton的具体优化有哪些,为什么它能够得到比cuBLAS更好的性能。大家不用急,这也是我为什么要写这一系列文章的初衷,来带着大家从Triton的DSL前端一步一步到最终的machine code生成有一个清晰的理解,从而为大家展示编译在高性能计算中所起到的作用。先来看看openai对Triton所打的广告:
"An open-source python-like programming language which enables researchers with no CUDA experience to write highly efficient GPU code -- most of the time on par with what an expert would be able to produce"
确实宣传的很强,Triton作为一个完全开源的编译流,提供了python-based的前端,我们这里把它称为DSL,也就是这篇文章要介绍的主要内容。DSL的全称是Domain Specific Language,为什么要设计DSL?其实设计DSL的目的就是为了能够让使用该套工具的人能够以一个低成本的入门代价来体验到该套工具或者软件栈能够带来的性能提升。类比PyTorch,TensorFlow,MXNet,Taichi,TVM等,其都是给使用这些工具的人提供了一套比较清晰的python api,然后用户只需要花一定的时间学习下这些python api的使用规范以及常用的python开发流程,就能够在不摸清软件或者框架的底层细节的同时带来极致的开发体验。当然,这里多讲讲有关DSL的设计理念,以我这些年对于软件系统的开发和实战经验来看,DSL的设计最注重的是灵活性,也即一些关于编程语言设计的论文中经常提到的flexibility,灵活的编程方式能够给用户带来不一样的使用体验。对于深度学习算法从业者来说,最常见的例子其实就是pytorch的出现,对于caffe和tensorflow 1.x 所带来的编程方式的颠覆,前者则是以imperative的编程范式为用户提供一个简单易控制的开发体验,方便用户的调试和已有代码的交互,可以在model构建的过程中,随时可视化和运行已有的部分计算图,将更多的优化细节进行隐藏。而后者则是以declarative的编程范式,让用户首先通过特定的placeholder api去构建一个完整的计算图,然后对该计算图进行全局范围的优化,这样做的好处自然而然带来了更多的优化空间。但是,它所带来的问题也显而易见,那就是对于一些经验不是很足的用户,一旦出现编程中的bug,很难去快速的定位到具体的问题。那么,再次回到Triton,Triton给我们提供了一个什么样的编程范式呢?
Triton给我们提供的更像是一种imperative的编程范式,但是Triton每次可以操作的粒度却是一个Block级别。有些同学可能会问,什么是Block呢?这里Block的概念和CUDA编程中的thread-Block是具有相同的概念,也即是说,当我们在编写CUDA代码的过程中,需要对thread-Block中的每个thread进行精确的编程。说的深入一些,其实目前像tvm这样的代码生成工具,或者cutlass这样的模板库在做for-loop tiling的过程,对于inter-level级别,也就是thread-Block的concurrently运行这个层面的优化来说,做的已经很不错了。但是对于每个thread-Block内部的intra-level级别的并行来说,还是有很多优化的空间包括memory coalescing, 共享内存的sync以及bank conflict的处理,在包括更加细粒度的register-level的tensor core的调度上。上面这些优化,如果你不是一个经验十分老道的高性能工程师,对于GPU的架构和CUDA的设计没有比较深入的研究和经验,是很难在段时间内写出媲美cuBLAS的高性能算子库的。同时,我们可以像写pytorch一样,通过Triton给予的DSL就可以完美的定义出自己想要的算子,然后通过将其嵌入到其他已有的框架的后端中,作为一个codegen来使用。所以,关于Triton的定位,我更更倾向于将其定位成一个以python DSL来生成高性能GPU算子的瑞士军刀。当然,Triton的使用是具有一定门槛的,假如你先前从来没有写过类似CUDA或者OpenCL这类编程GPU加速器的语言,直接让你通过学习Triton就写出能够一定程度媲美cuBLAS的代码,我觉得还是有一定的难度的。这里以NV的显卡为例,感觉Triton的定位更像是先前对于CUDA的优化有一定的基础,并且想通过隐藏更多的高级优化细节,仅仅通过python层面的描述将整个算法的流程定义清楚,同时将编译与高级的优化细节交给codegen帮你去做的用户。
说了这么多, 总结下来,Triton DSL能够帮助用户做什么样的事情?
- Embedded In Python: 使用python的装饰器来定义需要优化的kernel
- Pointer Arithmetics: 使用pointer arithmetic的方式去操作DRAM上的多维数据
- Optimizing Compiler:以Block为粒度的编程方式,为用户隐藏更多的优化细节,将这些优化工作交给编译器
Triton DSL基础¶
Triton官方对于DSL并没有像pytorch,tf或者tvm那些工具一样有一个比较详细的说明和介绍,对于新手入门还是稍微有一些门槛的,官方关于DSL的文档如下地址所示:
triton.language - Triton documentationtriton-lang.org/main/python-api/triton.language.html
由于我在使用Triton进行二次开发的过程中,发现有些东西可能已经过时,文档还没来得及更新,我们就以目前Triton的main分支的代码进行介绍。有关Triton这门编程语言的大部分东西都位于/python/triton的目录下,该目录下的compiler,language,runtime是定义有关Triton DSL描述对应具体workload,到中间代码的生成,以及最终通过自动调优将最优的实现找到的过程。要使用Triton的DSL,在最开始的时候,我们需要通过如下代码将Triton引入我们的开发环境中,这就类似以前写pytorch时候使用的import torch
import triton
import triton.language as tl
那么接下来,一旦tl被我们import进来了,就可以开始使用Triton DSL来构建各种各样的workload了。关于tl的所有操作,可以在python/triton/language/init.py中的__all__下查到,总共定义了95个常用的操作。
__all__ = [
"abs",
"advance",
"arange",
"argmin",
"argmax",
"atomic_add",
"atomic_and",
"atomic_cas",
"atomic_max",
"atomic_min",
"atomic_or",
"atomic_xchg",
"atomic_xor",
"bfloat16",
"block_type",
"broadcast",
"broadcast_to",
"builtin",
"cat",
"cdiv",
"constexpr",
"cos",
"debug_barrier",
"device_assert",
"device_print",
"dot",
"dtype",
"exp",
"expand_dims",
"extra",
"fdiv",
"float16",
"float32",
"float64",
"float8e4",
"float8e5",
"full",
"function_type",
"int1",
"int16",
"int32",
"int64",
"int8",
"ir",
"math",
"load",
"log",
"make_block_ptr",
"max",
"max_contiguous",
"maximum",
"min",
"minimum",
"multiple_of",
"num_programs",
"pair_uniform_to_normal",
"philox",
"philox_impl",
"pi32_t",
"pointer_type",
"program_id",
"rand",
"rand4x",
"randint",
"randint4x",
"randn",
"randn4x",
"ravel",
"reduce",
"reshape",
"sigmoid",
"sin",
"softmax",
"sqrt",
"static_range",
"static_assert",
"static_print",
"store",
"sum",
"swizzle2d",
"tensor",
"trans",
"triton",
"uint16",
"uint32",
"uint32_to_uniform_float",
"uint64",
"uint8",
"umulhi",
"view",
"void",
"where",
"xor_sum",
"zeros",
"zeros_like",
]
那么,关于triton的所有操作,可以在/python/triton/init.py下进行查看,总共定义了19个常用的操作。
__all__ = [
"autotune",
"cdiv",
"CompilationError",
"compile",
"Config",
"heuristics",
"impl",
"jit",
"JITFunction",
"KernelInterface",
"language",
"MockTensor",
"next_power_of_2",
"ops",
"OutOfResources",
"reinterpret",
"runtime",
"TensorWrapper",
"testing",
"program_ids_from_grid",
]
接下来,我们就来讲讲如何通过这95+19中的常用操作来定义一个完整的关于“矩阵乘法”的优化流程
Triton DSL做矩阵乘法¶
首先,和编写CUDA的kernel的流程类似,首先定义需要进行运算的输入tensor和输出tensor,然后launch kernel进行计算,最终对计算结果和golden data进行比较进行单元测试。
0x0 定义kernel准备工作¶
def matmul(a, b):
# Check constraints.
assert a.shape[1] == b.shape[0], "Incompatible dimensions"
assert a.is_contiguous(), "Matrix A must be contiguous"
assert b.is_contiguous(), "Matrix B must be contiguous"
M, K = a.shape
K, N = b.shape
# Allocates output.
c = torch.empty((M, N), device=a.device, dtype=a.dtype)
# 1D launch kernel where each block gets its own program.
grid = lambda META: (
triton.cdiv(M, META['BLOCK_SIZE_M']) * triton.cdiv(N, META['BLOCK_SIZE_N']),
)
matmul_kernel[grid](
a, b, c,
M, N, K,
a.stride(0), a.stride(1),
b.stride(0), b.stride(1),
c.stride(0), c.stride(1),
ACTIVATION=activation
)
return c
上述代码片段中,我们可以看到,唯一比较陌生的应该就是如下关于grid和matmul_kernel的定义
grid = lambda META: (
triton.cdiv(M, META['BLOCK_SIZE_M']) * triton.cdiv(N, META['BLOCK_SIZE_N']),
)
matmul_kernel[grid](
a, b, c,
M, N, K,
a.stride(0), a.stride(1),
b.stride(0), b.stride(1),
c.stride(0), c.stride(1),
ACTIVATION=activation
)
这里完全可以类比到CUDA编程中在main函数中所写到的关于怎么去launch一个kernel的环节,类比如下代码
dim3 block(BLOCK_SIZE_M, BLOCK_SIZE_N);
dim3 grid((M + BLOCK_SIZE_M - 1) / BLOCK_SIZE_M, (N + BLOCK_SIZE_N - 1) / BLOCK_SIZE_N);
matmul_kernel<<<grid,block>>>(Ad, Bd, Cd, M, N, K);
其中,grid表示的是每个grid中所含有的thread-Blocks的个数,block表示的则是每个thread-Blocks所启动的threads的个数。在上述Triton的程序中,在matmul_kernel<<< >>>的后面,我们本质是将"BLOCK_SIZE_M"和"BLOCK_SIZE_N"这两个维度进行了合并,也即后面准备通过一组id进行访问, triton.cdiv表示来做除法操作。接下来,我们就来看看最为关键的matmul_kernel是如何定义的。
0x1 Triton Kernel的编写¶
@triton.jit
def matmul_kernel(
# Pointers to matrices
a_ptr, b_ptr, c_ptr,
# Matrix dimensions
M, N, K,
# The stride variables represent how much to increase the ptr by when moving by 1
# element in a particular dimension. E.g. `stride_am` is how much to increase `a_ptr`
# by to get the element one row down (A has M rows).
stride_am, stride_ak,
stride_bk, stride_bn,
stride_cm, stride_cn,
# Meta-parameters
BLOCK_SIZE_M: tl.constexpr, BLOCK_SIZE_N: tl.constexpr, BLOCK_SIZE_K: tl.constexpr,
GROUP_SIZE_M: tl.constexpr,
ACTIVATION: tl.constexpr,
):
"""Kernel for computing the matmul C = A x B.
A has shape (M, K), B has shape (K, N) and C has shape (M, N)
"""
# -----------------------------------------------------------
# Map program ids `pid` to the block of C it should compute.
# This is done in a grouped ordering to promote L2 data reuse.
# See above `L2 Cache Optimizations` section for details.
pid = tl.program_id(axis=0)
num_pid_m = tl.cdiv(M, BLOCK_SIZE_M)
num_pid_n = tl.cdiv(N, BLOCK_SIZE_N)
num_pid_in_group = GROUP_SIZE_M * num_pid_n
group_id = pid // num_pid_in_group
first_pid_m = group_id * GROUP_SIZE_M
group_size_m = min(num_pid_m - first_pid_m, GROUP_SIZE_M)
pid_m = first_pid_m + (pid % group_size_m)
pid_n = (pid % num_pid_in_group) // group_size_m
# ----------------------------------------------------------
# Create pointers for the first blocks of A and B.
# We will advance this pointer as we move in the K direction
# and accumulate
# `a_ptrs` is a block of [BLOCK_SIZE_M, BLOCK_SIZE_K] pointers
# `b_ptrs` is a block of [BLOCK_SIZE_K, BLOCK_SIZE_N] pointers
# See above `Pointer Arithmetics` section for details
offs_am = (pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)) % M
offs_bn = (pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)) % N
offs_k = tl.arange(0, BLOCK_SIZE_K)
a_ptrs = a_ptr + (offs_am[:, None] * stride_am + offs_k[None, :] * stride_ak)
b_ptrs = b_ptr + (offs_k[:, None] * stride_bk + offs_bn[None, :] * stride_bn)
# -----------------------------------------------------------
# Iterate to compute a block of the C matrix.
# We accumulate into a `[BLOCK_SIZE_M, BLOCK_SIZE_N]` block
# of fp32 values for higher accuracy.
# `accumulator` will be converted back to fp16 after the loop.
accumulator = tl.zeros((BLOCK_SIZE_M, BLOCK_SIZE_N), dtype=tl.float32)
for k in range(0, tl.cdiv(K, BLOCK_SIZE_K)):
# Load the next block of A and B, generate a mask by checking the K dimension.
# If it is out of bounds, set it to 0.
a = tl.load(a_ptrs, mask=offs_k[None, :] < K - k * BLOCK_SIZE_K, other=0.0)
b = tl.load(b_ptrs, mask=offs_k[:, None] < K - k * BLOCK_SIZE_K, other=0.0)
# We accumulate along the K dimension.
accumulator += tl.dot(a, b)
# Advance the ptrs to the next K block.
a_ptrs += BLOCK_SIZE_K * stride_ak
b_ptrs += BLOCK_SIZE_K * stride_bk
# You can fuse arbitrary activation functions here
# while the accumulator is still in FP32!
c = accumulator.to(tl.float16)
# -----------------------------------------------------------
# Write back the block of the output matrix C with masks.
offs_cm = pid_m * BLOCK_SIZE_M + tl.arange(0, BLOCK_SIZE_M)
offs_cn = pid_n * BLOCK_SIZE_N + tl.arange(0, BLOCK_SIZE_N)
c_ptrs = c_ptr + stride_cm * offs_cm[:, None] + stride_cn * offs_cn[None, :]
c_mask = (offs_cm[:, None] < M) & (offs_cn[None, :] < N)
tl.store(c_ptrs, c, mask=c_mask)
上述代码则对应了matmul_kernel的具体实现细节,我们可以将上述代码分成三个部分来进行学习。
第一个部分,先来看看matmul_kernel的输入参数有哪些?首先在Triton中定义一个kernel的时候,需要使用@triton.jit对其进行装饰。a_ptr, b_ptr, c_ptr指的是输入tensor和输出tensor所对应的首地址,M,N,K则表示需要计算的tensor的维度分别为[M, K] x [K, N]。stride_am, stride_ak, stride_bk, stride_bn, stride_cm, stride_cn则表示的是分别针对a,b,c这三个tensor来说,访问一个元素所需要移动的步长。而后面的BLOCK_SIZE_M, BLOCK_SIZE_N等被定义为tl.constexpr的变量都属于是自动调优系统中可以被枚举的knob,如果你用过autotvm的话,应该不会很陌生。
第二部分,则是将id对应到输出tensor的每个block上,这块的内容在tutorial中讲到是为了提高L2 Cache的命中率。在文中,openai使用了一个叫做"super-grouping"的名字来表示一个block中所含有的block的个数。其实super-grouping的原理很简单,看下图所示
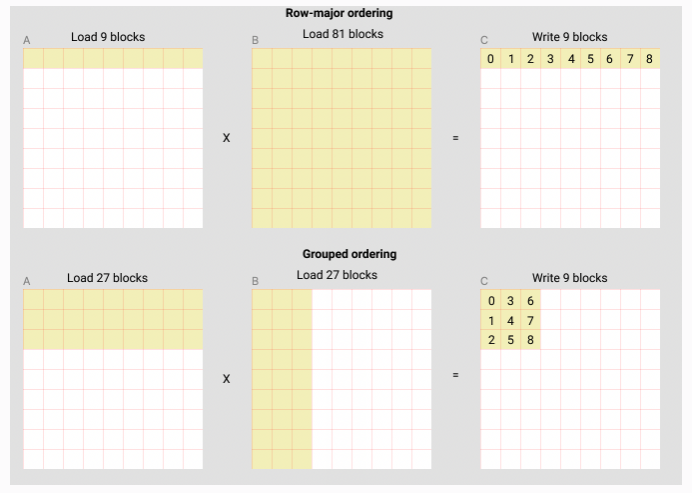
编辑切换为居中
添加图片注释,不超过 140 字(可选)
当我们在进行AxB=C的时候,如果在load A的数据的时候,以行优先的方式,一次性读取9个block,那么如果要得到C矩阵的第一行结果,并且C的存储方式也是以行优先的方式进行,总共需要进行9+81=90次对block的load的操作,9次对block的write的操作才能得到所要的结果。但是,如果我们采用了“super-grouping”的方式,也就是说同样为了得到得到C矩阵中的9次block的write操作,那么对于A矩阵来说,进行93次load操作,B矩阵也同样进行93次的load操作,对block总的load操作则为27+27=54次。前后对比下,第一种方式则总共进行了90次load+9次write,而第二种采用了super-grouping技术则进行了54次load和9次write。并且openai还在备注中说明了可以在A100上由220TFLOPS提升到245TFLOPS。等后面可以对该技术专门写一个章节进行介绍和测试。
第三部分,则比较常规,对应到CUDA编程中,其实就是在探索如何通过Triton DSL去访问每个block,然后通过一个accumulator变量来记录tl.dot(a, b)的结果,mask的作用是来判断迭代的过程中,是否越界,如果超过了界限的范围,就将对应的block置为0。最终再将结果按位写会到对应的c矩阵则完成了对应的操作。
0x2 单元测试¶
单元测试的编写就显而易见了,为的是比较通过Triton生成的代码和通过pytorch的torch.mm算出的结果是否对齐
torch.manual_seed(0)
a = torch.randn((512, 512), device='cuda', dtype=torch.float16)
b = torch.randn((512, 512), device='cuda', dtype=torch.float16)
triton_output = matmul(a, b)
torch_output = torch.matmul(a, b)
print(f"triton_output={triton_output}")
print(f"torch_output={torch_output}")
if torch.allclose(triton_output, torch_output, atol=1e-2, rtol=0):
print("✅ Triton and Torch match")
else:
print("❌ Triton and Torch differ")
Triton的自动调优¶
这里不会对Triton的自动调优技术进行过多的解读,仅仅通过一些小的实验来表明,定义不同的搜索空间还是可以很大程度上提高matmul最终的TFLOPS的。那么,对于Triton的自动调优以及到底应该如何定义一个高效的搜索空间将会在后面的内容中进行详细的讲解。所有实验都是在NV 3090 GPU上,batch = 1, datatype = fp16.
在openai给出的默认自动调优空间下
@triton.autotune(
configs=[
triton.Config({'BLOCK_SIZE_M': 128, 'BLOCK_SIZE_N': 256, 'BLOCK_SIZE_K': 64, 'GROUP_SIZE_M': 8}, num_stages=3, num_warps=8),
triton.Config({'BLOCK_SIZE_M': 64, 'BLOCK_SIZE_N': 256, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=4, num_warps=4),
triton.Config({'BLOCK_SIZE_M': 128, 'BLOCK_SIZE_N': 128, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=4, num_warps=4),
triton.Config({'BLOCK_SIZE_M': 128, 'BLOCK_SIZE_N': 64, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=4, num_warps=4),
triton.Config({'BLOCK_SIZE_M': 64, 'BLOCK_SIZE_N': 128, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=4, num_warps=4),
triton.Config({'BLOCK_SIZE_M': 128, 'BLOCK_SIZE_N': 32, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=4, num_warps=4),
triton.Config({'BLOCK_SIZE_M': 64, 'BLOCK_SIZE_N': 32, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=5, num_warps=2),
triton.Config({'BLOCK_SIZE_M': 32, 'BLOCK_SIZE_N': 64, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=5, num_warps=2),
],
key=['M', 'N', 'K'],
)
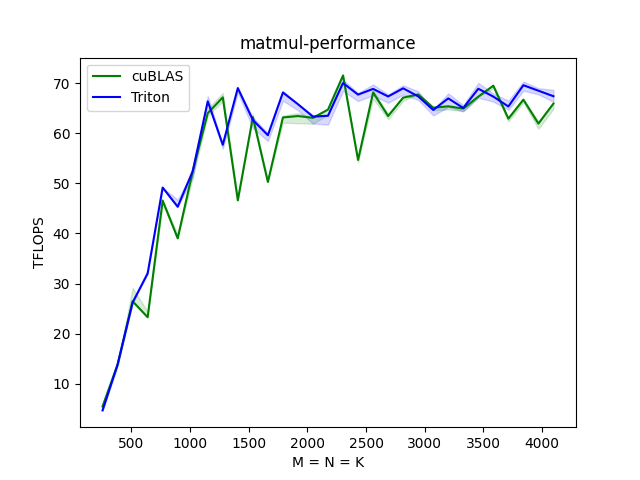
当我们去调整对应的调优空间
@triton.autotune(
configs=[
triton.Config({'BLOCK_SIZE_M': 32, 'BLOCK_SIZE_N': 64, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=5, num_warps=2),
],
key=['M', 'N', 'K'],
)
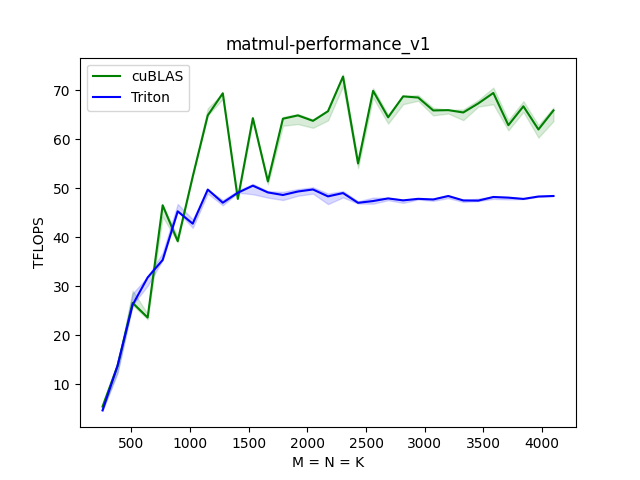
编辑切换为居中
添加图片注释,不超过 140 字(可选)
当我们继续对搜索空间进行调整
@triton.autotune(
configs=[
triton.Config({'BLOCK_SIZE_M': 64, 'BLOCK_SIZE_N': 32, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=5, num_warps=2),
],
key=['M', 'N', 'K'],
)

进一步的进行修改
@triton.autotune(
configs=[
triton.Config({'BLOCK_SIZE_M': 64, 'BLOCK_SIZE_N': 256, 'BLOCK_SIZE_K': 32, 'GROUP_SIZE_M': 8}, num_stages=4, num_warps=4),
],
key=['M', 'N', 'K'],
)
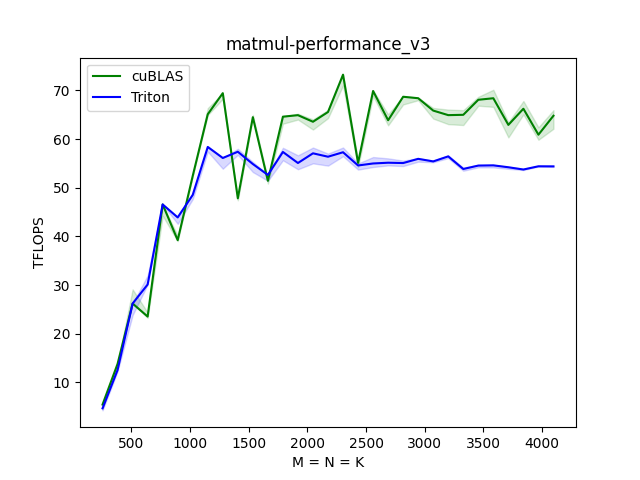
通过上面简单的实验,可以看出,要想得到一个比较好的TFLOPS的数值,对于"BLOCK_SIZE_M", "BLOCK_SIZE_N", "BLOCK_SIZE_K", "num_stages", "num_warps"都需要一个很好的调整,才能够得到一个媲美甚至超过cuBLAS的性能上界。
总结¶
通过上述对于Triton DSL的解读,以及通过Triton DSL来完成矩阵乘法的操作,我们可以看到,用户只需要懂一些基础的python语法和写pytorch,然后将先前使用CUDA的经验拿过来,使用一些和pytorch很像的api,就可以在NV的显卡上,使用Triton就可以很轻松的生成性能媲美cuBLAS的高性能算子。如果你能够通过triton熟练的写出matmul和flashAttention的话,那么像深度学习中的大部分算子你都可以轻松的通过Triton来帮你cover,后面的教程中,我会将重点放在Triton在使用MLIR进行重构的过程中,所采取的一些工程上的组织以及Triton本身的内部设计使得其能够生成媲美NV的cublas的高性能算法库。
本文总阅读量次