本文首发于我的知乎:https://zhuanlan.zhihu.com/p/111399987
0. 前言¶
接上一期 海思NNIE之Mobilefacenet量化部署 文章。
关于上述内容,还是得到了一些认可,索性把人脸全家福奉上了,Github地址如下:
https://github.com/hanson-young/nniefacelib
nniefacelib是一个在海思35xx系列芯片上运行的人脸算法库,目前集成了mobilefacenet和retinaface。 后期也会融合一些其他经典的模型,目的也是总结经验,让更多人早日脱离苦海。欢迎关注!
这篇的话,就讲下RetinaFace的量化和部署吧!相信很多同学在转换的时候吃了苦头,那我们就来宣泄一下吧!
RetinaFace是目前非常优秀的开源人脸检测算法
https://github.com/deepinsight/insightface/tree/master/RetinaFace
实测效果确实很棒,鲁棒性强,关键点准,能够识别比较复杂场景下的人脸,甚至于比我采用私有数据集训练的mtcnn某些方面还要强,有全局感受野的模型在复杂人脸上的检测效果会有很大优势。很多同学在海思上也有往mtcnn方向下功夫的,其实可以走得通,但现实是,海思弱鸡的CPU算力还是留给其他业务逻辑吧,直接用one-stage的方法也是很香的。另外one stage模型优化起来也是很粗暴的。天下武功,唯快不破,tracking也可以告别光流,而去使用sort,甚至一些场景直接用deepsort去解决switch IDs。综上,将RetinaFace这类模型放上海思的板子上是有巨大的优势。
我参考的代码和模型来自于
https://github.com/Charrin/RetinaFace-Cpp
1. 特殊层Crop¶
在nnie上,有的层是不支持的,这个官方SDK里有专门的章节描述,其中retinaface就有一个Crop层是不支持的,需要手动写插件,但这当然是不能接受的,毕竟一想到将计算量转移部分到CPU上就觉得不踏实,后期肯定会给自己带来麻烦。那么对于这个问题,我们首先要做的就是明白这个层的作用。
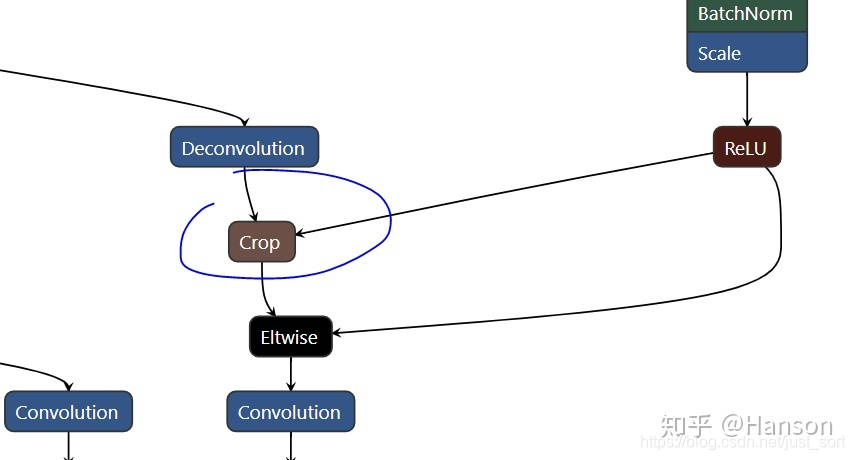
Caffe中crop_layer描述是这样的:
数据以blobs形式存在,blob是一个四维结构的Tensor(batch size, channels, height, width),假设crop_layer的输入(bottom)有两个,A和B,输出(top)为C
- A——要进行裁剪的bottom,假设A的size为(20,50,512,512)
- B——裁剪的参考输入,size为(20,10,256,256)
- C——输出top,它是在A的基础上按照B的size裁剪而来,所以输出C的size和B是一样的
layer {
name: "crop0"
type: "Crop"
bottom: "A"
bottom: "B"
top: "C"
}
知道Crop的原理和模型训练的流程就能明白,作者利用Crop的原理其实就是解决多尺度输入的问题,可以在比赛或实验中去利用多尺度提升性能,但实际在跑视频流或者做应用的时候并不需要每一次都跑尺寸不同的图像,一般都是根据需要,设定单一尺度。
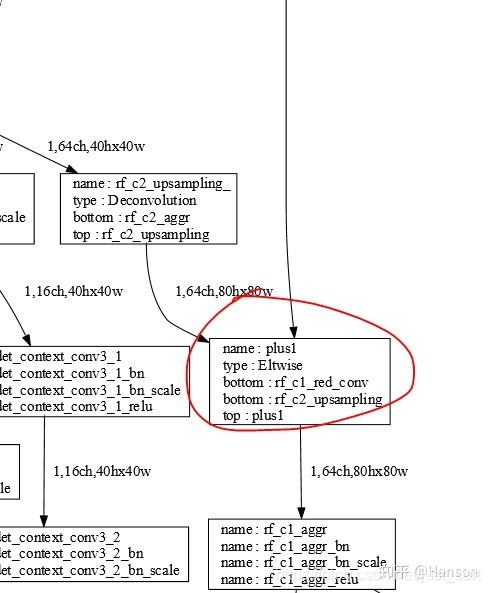
所以我采取了比较暴力的做法,就是直接在mnet.prototxt中两处地方去除了Crop层(Fig.2.2,Fig.2.3),然后寻找几组固定的输入比如512x512、640x640、768x768、1024x1024等,只要保证在Crop操作之前两个层的维度是一致的就没有什么问题!
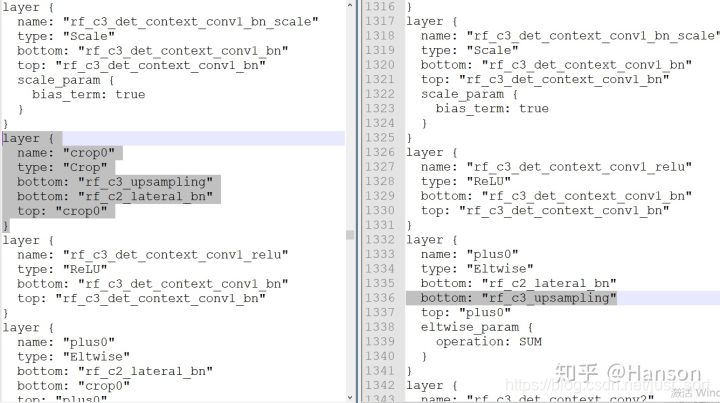
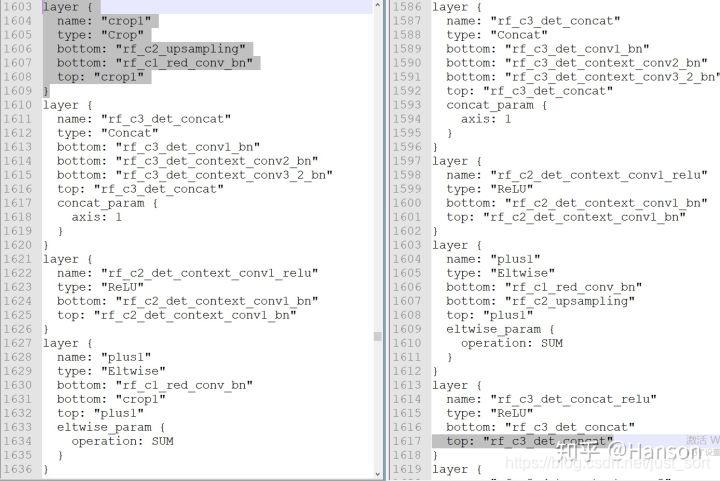
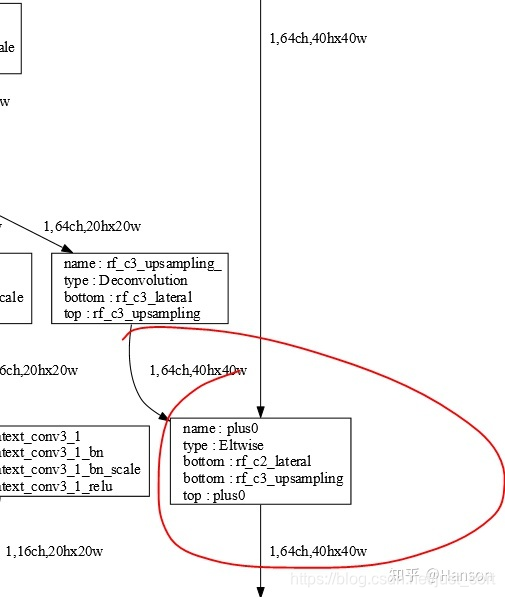
然后去掉prototxt里的两处crop后,结构图如下:

修改完prototxt后就可以直接在RuyiStudio中使用Marker进行模型拓扑图像的观测,调节data的输入尺度,可以测试出几组能满足条件的size,这样之后的转换问题应该就不会很大了!如Figure2.4和Figure2.5所示。
3. ReShape¶
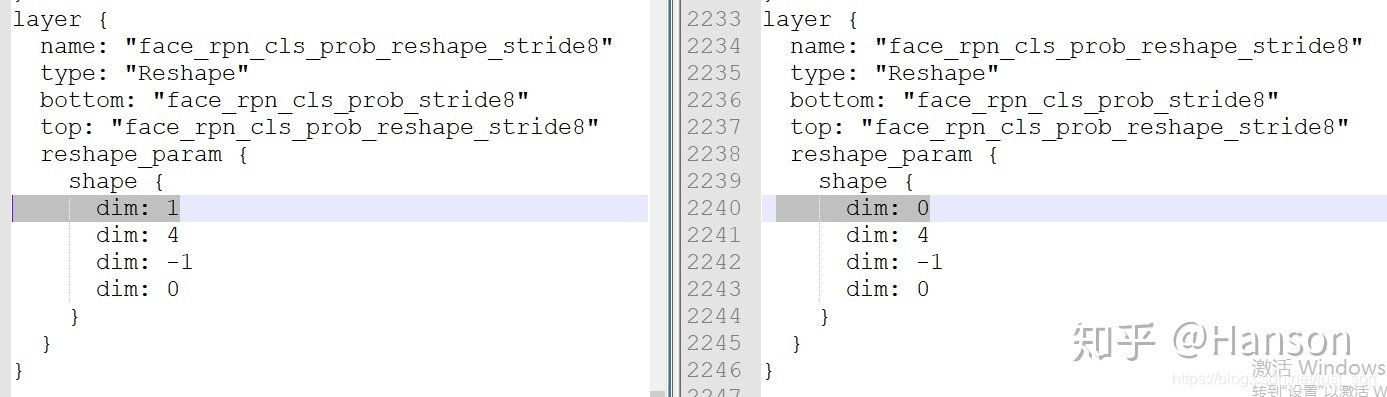
prototxt中存在多处reshape的地方,如下图,需要将dim: 1改成dim: 0,原因很简单,在量化的时候会报一个错误,就是只能设置CHW三个维度,没有N,这个维度的设定应该是为了让NNIE多张输入的时候方便操作四维数据,可以参考样例中fasterRCNN中的写法,进行必要调整。
4. 小雷区¶
还有一个地方比较坑,也是CNN_convert_bin_and_print_featuremap.py代码的问题,因为这个代码里面没有将BGR转化为RGB,而cfg里写的并没有用到,之前测试的图像是agedb中的图像,刚好是一张三通道一致的灰度图,因此需要在读取图像的时候注意一下,加上这句代码
img = cv2.cvtColor(img, cv2.COLOR_BGR2RGB)

5. 大雷区¶
开开心心的走到了这一步,那其实最大的问题才刚刚抵达战场。就是前方这个错误,让人魂牵梦萦的Error。最后的解决方案也让人无法入睡。
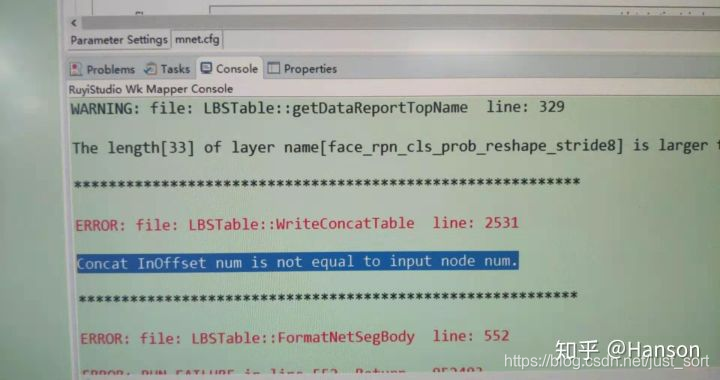
其实解决方法就是改变prototxt中layer的顺序,对你没听过。修改过后的prototxt已经被放在nniefacelib了
其中有几个点是目前还想不明白的,非常希望得到大佬的指点:
- pycaffe上运行确实是没问题的,结果也正确。NNIE mapper工具可以生成inst.mk,生成过程中没有如上错误,但是在板端测试的时候输出是错误的;NNIE mapper工具也无法生成func.mk,但可以生成mapper_quant,生成过程中有如上错误。
- 有的地方batchnorm层之前精度还是很高的,过batchnorm后精度就完全对不上了,有的地方没问题,本以为是batchnorm里的参数有问题,但和mxnet版本的model param进行了对比后并没有发现任何异常。最后输出层的结果却也是精损极小,意料之中。这个问题在转其他模型的时候也遇到过。(PS:要不直接merge bn吧,这个问题就可以跳过了)
- 经过逐层的调试虽然解决了模型生成的问题,但是也仅仅改变了prototxt layer的顺序,按道理说并不应该出现这样的情况。
虽然存在一些不可告知的问题,但是也给了我们一个调试经验,在遇到输出不对的时候不要慌,先从对的那一层开始,修改prototxt,删除之后的layer开始调试,直到查明原因为止。如果还是没办法,重新训练也是个好方法。
5. 量化仿真¶
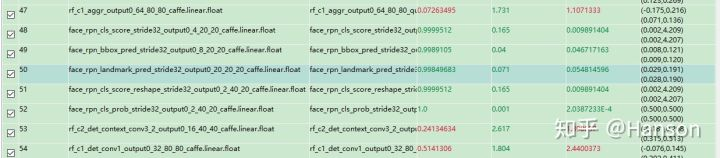
做完了上面的步骤就可以进行量化了,目前做的测试显示,低精度的量化在landmarks和bbox的回归上精度还是偏低的,但够用,部署起来输出的误差也就像素级误差,而高精度模式下自然也不用担心,只是效率会稍微降低一点,我也给出一个在3516DV300上的大概结果吧!图像尺寸640x640,算上后处理,高精度大概40ms,低精度20多ms。

如果对文章有什么不理解或者疑惑的地方,欢迎到文章开头的知乎文章的讨论区给我留言哦。
本文总阅读量次