用于ARM Cortex-M系列的芯片的神经网络推理库CMSIS-NN详解
CMSIS_NN走读¶
论文题目:《CMSIS-NN: Effificient Neural Network Kernels for Arm Cortex-M CPUs》, 2018年
单位:ARM
0.导言¶
CMSIS-NN是用于ARM Cortex-M系列的芯片的神经网络推理库,用于低性能芯片/架构的神经网络部署。
1.Convolution(卷积)与Matrix Multiplication(矩阵乘法)¶
使用的16 bit的乘加SMID即SMLAD
1.1__SXTB16 数据扩展¶
大部分NNFunctions使用的是16bit的MAC指令,所以在送进去SIMD之前需要把8-bit的数据拓展为16-bit,CMSIS_NN提供了函数*arm_q7_to_q15。
实现有两步骤:
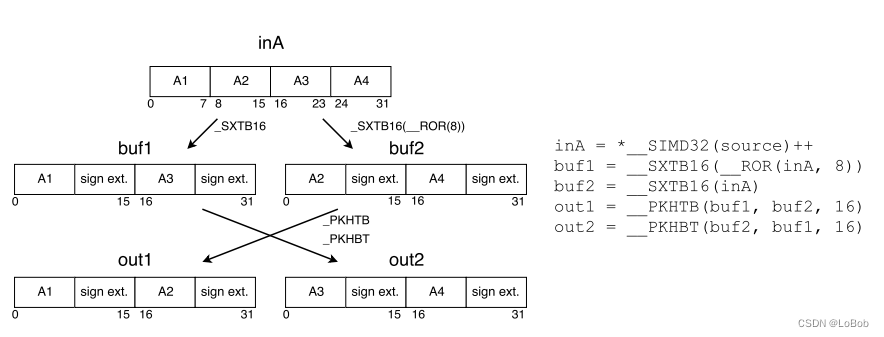
1、使用有符号的扩展指令即__SXTB16来扩展;
2、把扩展后的数据重排一下。数据重排主要__SXTB16扩展指令导致的。如图所示:
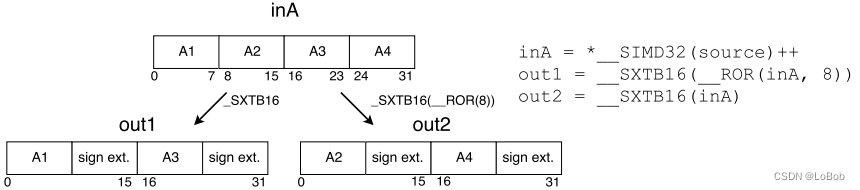
扩展成16-bit是必不可少的,但数据重排不一定。假设可以忽略扩展成16-bit的数据后的重排操作的话,流程如下图:
1.2 Matrix Multiplication¶
把矩阵乘法分成2×2,这样可以让部分数据可以重复使用进而减少加载数据的指令。累加器是int32(q_31_t)数据类型,加数和被加数都是int32(q_15_t)数据类型。给累加器的初始化是bias的数据,也就是先把bias加上去,计算是使用__SMLAD指令。
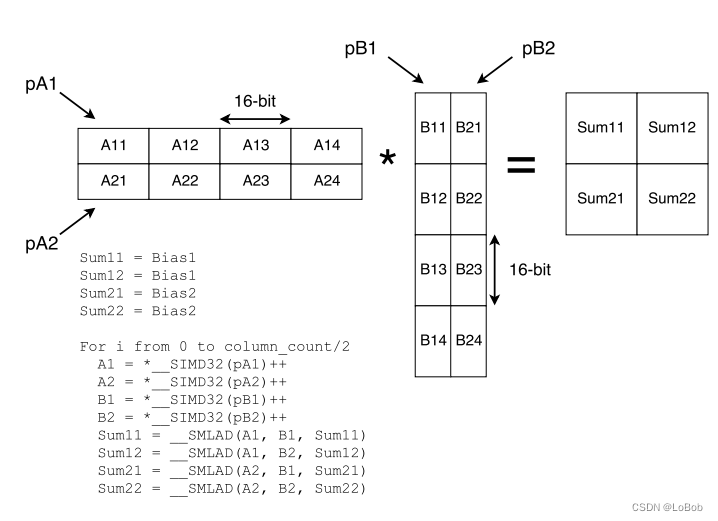
这个图很清楚的看到,对于A×B,把A和B两个矩阵分成了2×2的块,那么具体的运算是:
累加器: sum11/sum12/sum21/sum22
sum11 += A11×B11
sum12 += A11×B21
sum21 += A21×B11
sum22 += A21×B21
sum11 += A12×B12
sum12 += A12×B22
sum21 += A22×B12
sum22 += A22×B22
sum11 += A13×B13
sum12 += A13×B23
sum21 += A23×B13
sum22 += A23×B23
sum11 += A14×B14
sum12 += A14×B24
sum21 += A24×B14
sum22 += A24×B24
sum11 = A11×B11 + A12×B12 + A13×B13 + A14×B14 = (A11, A12, A13, A14)×(B11, B12, B13, B14).Transpose
sum12 = A11×B21 + A12×B22 + A13×B23 + A14×B24 = (A11, A12, A13, A14)×(B21, B22, B23, B24).Transpose
sum21 = A21×B11 + A22×B12 + A23×B13 + A24×B14 = (A21, A22, A23, A24)×(B11, B12, B13, B14).Transpose
sum22 = A21×B21 + A22×B22 + A23×B23 + A24×B24 = (A11, A12, A13, A14)×(B21, B22, B23, B24).Transpose
假设输入或者网络权重是int8的数据类型时,需要扩展为int16;
假设输入和网络权重都是int8的数据类型时,需要扩展为int16,但不需要数据重排;
假设是int8的权重和int16的输入,那么weight可以提前转换格式,即如图所示
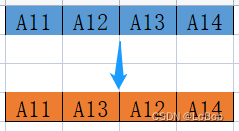
那么在扩展的时候就会变成顺序,就不需要重排了。
关于Dense/fully-connect,是matrix-vector的乘法,采用1×2的方法,这个2可以变大,比如1×4,但这个受限与寄存器的数量。Arm Cortex-M系列有16个寄存器。
另外,网络权重可以重排一下内存,这样可以减少寻址和cache miss。
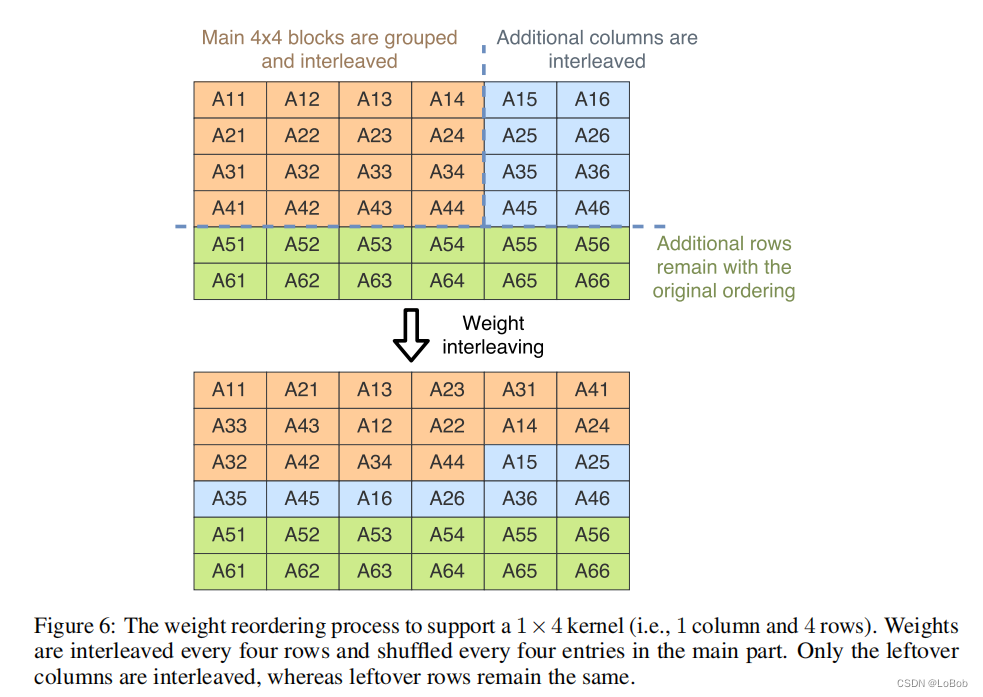
根据数据扩展指令_SXTB16,即可图6-1。我把需要重排的都画了图(图6-2)。
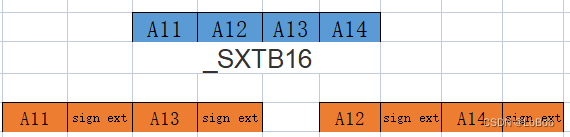
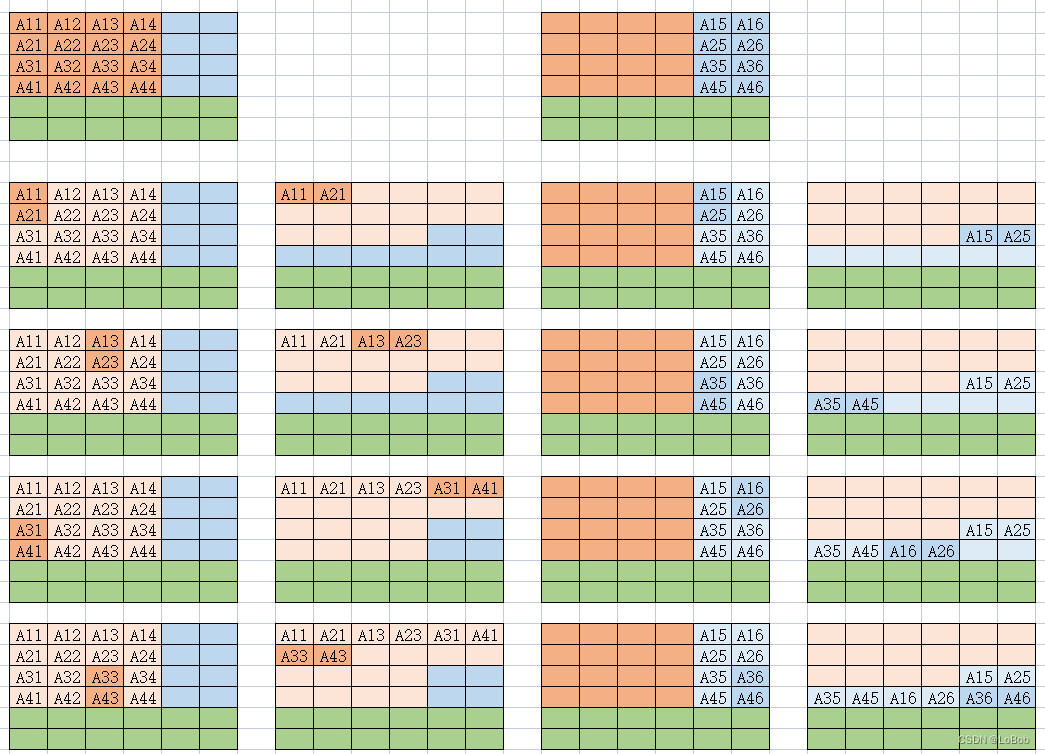
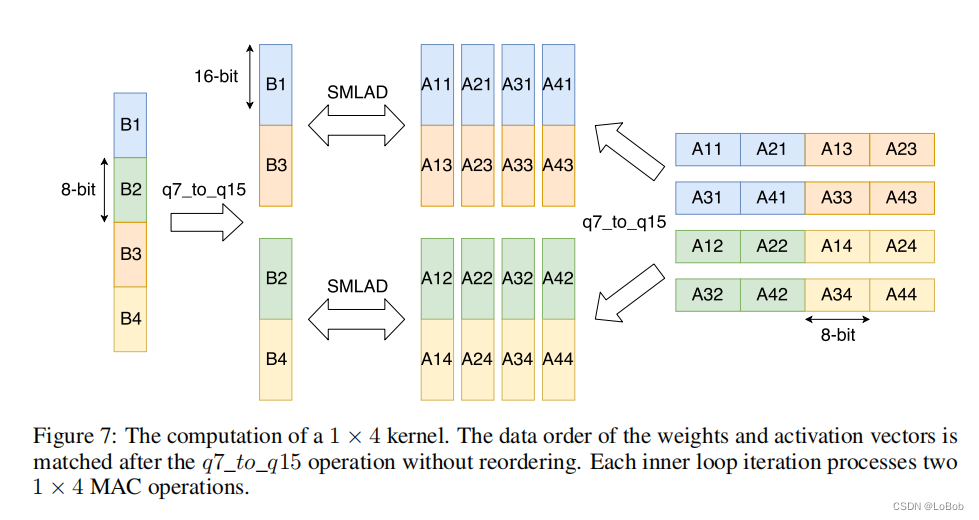
图7展示的是1×4的数据扩展。扩展的数据顺序跟上面提到的都一样。
1.3 Convolution¶
partial im2col
卷积先要做im2col,如图所示。另外还能看看我之前的写的知乎再次理解im2col - 知乎 (zhihu.com)。
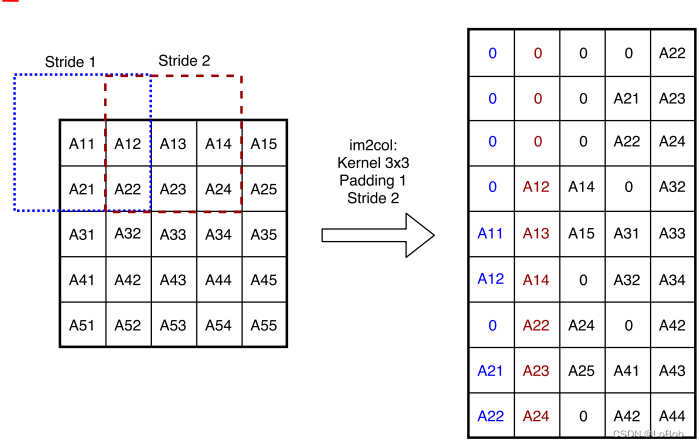
但是im2col是用空间换时间的方法,Arm Cortex-M系列的内存比较限制。作为trade-off,采用 partial im2col,限制column的数量。
HWC数据排放方式:
论文的分析其实比较废话,作者做了测试,HWC的im2col比CHW快,原因是减少了寻址。但为什么NCNN、MNN之类的layout是NCHW的,而CMSIS-NN要用NHWC呢?难道是NCNN他们设计得不好吗?并不是,我目前的理解是:因为Cortex-M系列的乘加只能是4个数,即res += a[0]×b[0] + a[1]×b[1] + a[2]×b[2] + a[3]×b[3], 而且Cortex-M的DSP的向量运算目前我只查到是int16×int16的乘法单元(有查到int8×int8的朋友们教教我哈)。所以CMSIS-NN要先把int8扩展成int16,再做乘法。另外我个人对“为什么不提供int8×int8的矩阵乘法单元”的理解是:int8×int8的累加结果在int32的数据类型,而“+=”的操作,累加的次数多了非常容易溢出,int16×int16的累加存在了int64,溢出的概率就低了很多。
2.Pooling¶
pool有两种实现方式: Split x-y pooling 和 Window-based pooling。
2.1 Window-based pooling¶
Window-based是非常直觉的实现方法,把一个pool窗口一直滑动,其实这个方法笔者第一次写的也是这种,据说caffe也是这种方法。这种方法访存就比较一般了,因为HWC的layout,而pool是在HW上面做,当然也可以并行C维度来一起做,这样就能缓解访存的一些耗时。
/**
* @brief Q7 max pooling function
* @param[in, out] Im_in pointer to input tensor
* @param[in] dim_im_in input tensor dimention
* @param[in] ch_im_in number of input tensor channels
* @param[in] dim_kernel filter kernel size
* @param[in] padding padding sizes
* @param[in] stride convolution stride
* @param[in] dim_im_out output tensor dimension
* @param[in,out] bufferA Not used
* @param[in,out] Im_out pointer to output tensor
*/
int16_t i_ch_in, i_x, i_y;
int16_t k_x, k_y;
for (i_ch_in = 0; i_ch_in < ch_im_in; i_ch_in++){
for (i_y = 0; i_y < dim_im_out; i_y++) {
for (i_x = 0; i_x < dim_im_out; i_x++) {
int max = -129;
// 下面两个就是一个pool的窗口,比如2×2
for (k_y = i_y * stride - padding; k_y < i_y * stride - padding + dim_kernel; k_y++) {
for (k_x = i_x * stride - padding; k_x < i_x * stride - padding + dim_kernel; k_x++) {
if (k_y >= 0 && k_x >= 0 && k_y < dim_im_in && k_x < dim_im_in) {
if (Im_in[i_ch_in + ch_im_in * (k_x + k_y * dim_im_in)] > max) {
max = Im_in[i_ch_in + ch_im_in * (k_x + k_y * dim_im_in)];
}
}
}
}
Im_out[i_ch_in + ch_im_in * (i_x + i_y * dim_im_out)] = max;
}
}
}
2.2 Split x-y pooling¶
CMSIS-NN使用的就是这个方法,我看论文是看不懂的,只能去代码理解了。
简单的说就是:一次对pool的对比的时候是取一个C维度的数据,然后直接对比C维度的数据,并且把对比结果存在输出矩阵中。另外一个重点就是,先比x方向的,在比y方向的。这么做的好处是:C维度取值是连续的,可以向量化。
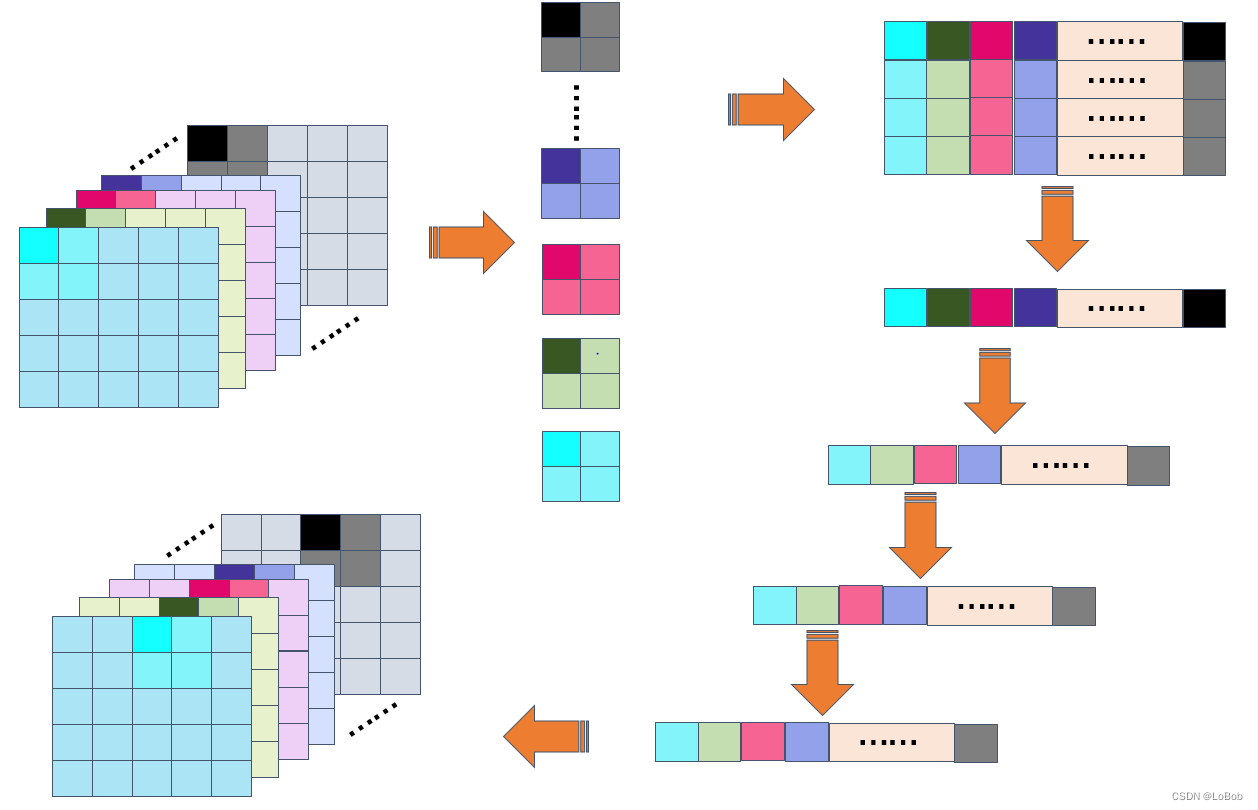
看看图,假设H=5,W=5,Pool=(2,2),pool stride=2。layout是NHWC的,即C通道在内存上是连续的,那么:
1、一次性取C的数,进行处理(Max/Average), 直接memcry或者用向量化加载数据;
2、4个数 一起比,这样可以向量化处理,即一个cycle出4个数的对比结果;
3、继续对比下一个,Pool=(2,2),那么总共对比4次,每次是C组数。
问题来了,这个方法怎么体现,先x-pooling,再y-pooling呢?
这个函数arm_max_pool_s8实际上是先2次x方向的pool,再2次y方向的pool。 CMSIS-NN还有arm_maxpool_q7_HWC这个实现,他是先做整个HW的x方向的pool,再做整个HW的y方向的pool,这个函数我是看懂了,但我发现tflie micro并没有使用这个函数,我就不画图了。有一点点区别。
//tfile micro的max pool
TfLiteStatus MaxEvalInt8(TfLiteContext* context, const TfLiteNode* node,
const TfLitePoolParams* params, const OpData& data,
const TfLiteEvalTensor* input,
TfLiteEvalTensor* output) {
RuntimeShape input_shape = micro::GetTensorShape(input);
RuntimeShape output_shape = micro::GetTensorShape(output);
const int depth = MatchingDim(input_shape, 3, output_shape, 3);
cmsis_nn_dims input_dims;
input_dims.n = 1;
input_dims.h = input_shape.Dims(1);
input_dims.w = input_shape.Dims(2);
input_dims.c = depth;
cmsis_nn_dims output_dims;
output_dims.n = 1;
output_dims.h = output_shape.Dims(1);
output_dims.w = output_shape.Dims(2);
output_dims.c = depth;
cmsis_nn_pool_params pool_params;
pool_params.stride.h = params->stride_height;
pool_params.stride.w = params->stride_width;
pool_params.padding.h = data.reference_op_data.padding.height;
pool_params.padding.w = data.reference_op_data.padding.width;
pool_params.activation.min = data.reference_op_data.activation_min;
pool_params.activation.max = data.reference_op_data.activation_max;
cmsis_nn_dims filter_dims;
filter_dims.n = 1;
filter_dims.h = params->filter_height;
filter_dims.w = params->filter_width;
filter_dims.c = 1;
cmsis_nn_context ctx;
ctx.buf = nullptr;
ctx.size = 0;
if (data.buffer_idx > -1) {
ctx.buf = context->GetScratchBuffer(context, data.buffer_idx);
}
TFLITE_DCHECK_EQ(
arm_max_pool_s8(&ctx, &pool_params, &input_dims,
micro::GetTensorData<int8_t>(input), &filter_dims,
&output_dims, micro::GetTensorData<int8_t>(output)),
ARM_CMSIS_NN_SUCCESS);
return kTfLiteOk;
}
举个MaxPooling的例子来说明:
CMSIS-NN有两个实现,在\CMSIS\NN\Source\PoolingFunctions\arm_max_pool_s8.c和CMSIS\NN\Source\PoolingFunctions\arm_pool_q7_HWC.c。
先来分析一下arm_max_pool_s8.c。
arm_cmsis_nn_status arm_max_pool_s8(const cmsis_nn_context *ctx,
const cmsis_nn_pool_params *pool_params,
const cmsis_nn_dims *input_dims,
const q7_t *src,
const cmsis_nn_dims *filter_dims,
const cmsis_nn_dims *output_dims,
q7_t *dst)
{
const int32_t input_y = input_dims->h;
const int32_t input_x = input_dims->w;
const int32_t output_y = output_dims->h;
const int32_t output_x = output_dims->w;
const int32_t stride_y = pool_params->stride.h;
const int32_t stride_x = pool_params->stride.w;
const int32_t kernel_y = filter_dims->h;
const int32_t kernel_x = filter_dims->w;
const int32_t pad_y = pool_params->padding.h;
const int32_t pad_x = pool_params->padding.w;
const int32_t act_min = pool_params->activation.min;
const int32_t act_max = pool_params->activation.max;
const int32_t channel_in = input_dims->c;
(void)ctx;
q7_t *dst_base = dst;
for (int i_y = 0, base_idx_y = -pad_y; i_y < output_y; base_idx_y += stride_y, i_y++){// H维度
for (int i_x = 0, base_idx_x = -pad_x; i_x < output_x; base_idx_x += stride_x, i_x++) {// W维度
/* Condition for kernel start dimension: (base_idx_<x,y> + kernel_<x,y>_start) >= 0 */
const int32_t ker_y_start = MAX(0, -base_idx_y);
const int32_t ker_x_start = MAX(0, -base_idx_x);
/* Condition for kernel end dimension: (base_idx_<x,y> + kernel_<x,y>_end) < dim_src_<width,height> */
const int32_t kernel_y_end = MIN(kernel_y, input_y - base_idx_y);
const int32_t kernel_x_end = MIN(kernel_x, input_x - base_idx_x);
int count = 0;
for (int k_y = ker_y_start; k_y < kernel_y_end; k_y++){// 这部分是对比一个pool,每次就是一组C维的数据送进去对比
for (int k_x = ker_x_start; k_x < kernel_x_end; k_x++){
const q7_t *start = src + channel_in * (k_x + base_idx_x + (k_y + base_idx_y) * input_x);
if (count == 0){
arm_memcpy_q7(dst, start, channel_in);
count++;
}else{
compare_and_replace_if_larger_q7(dst, start, channel_in);
}
}
}
/* 'count' is expected to be non-zero here. */
dst += channel_in;
}
}
clamp_output(dst_base, output_x * output_y * channel_in, act_min, act_max);//这个是在做截断
return ARM_CMSIS_NN_SUCCESS;
}
__STATIC_FORCEINLINE void arm_memcpy_q7(q7_t *__RESTRICT dst, const q7_t *__RESTRICT src, uint32_t block_size)
{
memcpy(dst, src, block_size);
}
static void clamp_output(q7_t *source, int32_t length, const int32_t act_min, const int32_t act_max){
union arm_nnword in;
int32_t cnt = length >> 2;
while (cnt > 0l){
in.word = arm_nn_read_q7x4(source);
in.bytes[0] = MAX(in.bytes[0], act_min);
in.bytes[0] = MIN(in.bytes[0], act_max);
in.bytes[1] = MAX(in.bytes[1], act_min);
in.bytes[1] = MIN(in.bytes[1], act_max);
in.bytes[2] = MAX(in.bytes[2], act_min);
in.bytes[2] = MIN(in.bytes[2], act_max);
in.bytes[3] = MAX(in.bytes[3], act_min);
in.bytes[3] = MIN(in.bytes[3], act_max);
arm_nn_write_q7x4_ia(&source, in.word);
cnt--;
}
cnt = length & 0x3;
while (cnt > 0l)
{
int32_t comp = *source;
comp = MAX(comp, act_min);
comp = MIN(comp, act_max);
*source++ = (int8_t)comp;
cnt--;
}
}
其中
if (count == 0){
arm_memcpy_q7(dst, start, channel_in);
count++;
}
arm_memcpy_q7是封装了memcpy(dst, src, block_size),就是在一个pool窗口内我只inplace拿一组数,这组数的长度是input/output channel。
取完数之后,就拿去对比即compare_and_replace_if_larger_q7(dst, start, channel_in) 这个函数。我把理解写到注释里面。
static void compare_and_replace_if_larger_q7(q7_t *base, const q7_t *target, int32_t length)
{
q7_t *dst = base;
const q7_t *src = target;
union arm_nnword ref_max;
union arm_nnword comp_max;
int32_t cnt = length >> 2; // 因为每次都是处理4个数,所以直接左移2位
while (cnt > 0l) // 0L long,cnt是length/4的整数部分
{
ref_max.word = arm_nn_read_q7x4(dst);
comp_max.word = arm_nn_read_q7x4_ia(&src);
if (comp_max.bytes[0] > ref_max.bytes[0]) ref_max.bytes[0] = comp_max.bytes[0];
if (comp_max.bytes[1] > ref_max.bytes[1]) ref_max.bytes[1] = comp_max.bytes[1];
if (comp_max.bytes[2] > ref_max.bytes[2]) ref_max.bytes[2] = comp_max.bytes[2];
if (comp_max.bytes[3] > ref_max.bytes[3]) ref_max.bytes[3] = comp_max.bytes[3];
arm_nn_write_q7x4_ia(&dst, ref_max.word);// 对比完就覆盖arm_memcpy_q7取出来的数据的那个内存位置,属于inplace操作,这样节省内存
cnt--;
}
cnt = length & 0x3; // 0x3即 0011,即取length%4,处理尾部
while (cnt > 0l)
{
if (*src > *dst){
*dst = *src;
}
dst++; src++; cnt--;
}
}
3 Activation Functions¶
3.1 Relu
最朴素的做法是:遍历一遍,少于0的置为0。
void arm_relu_q7(q7_t *data, uint16_t size){
/* Run the following code as reference implementation for cores without DSP extension */
uint16_t i;
for (i = 0; i < size; i++){
if (data[i] < 0)
data[i] = 0;
}
}
为了可以向量化,用位运算来做Relu。
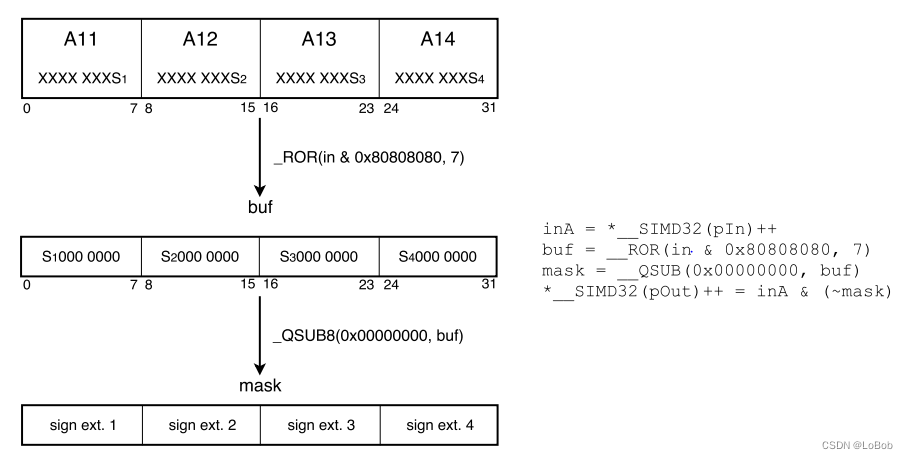
步骤:
1、提取4个数的最高位,即符号位,所以是每个数与运算0x80,然后循环右移7位,记为buf。
2、假设最高位是1,那么表示这个数是负数,要mask成0,用mask = 0减去buf,假设是负数,那么mask就会等于 -1即0xFF;假设是正数,那么mask = 0即0x00;
3、对mask取反,~(0xFF) = 0x00, ~(0x00)=0xFF,所以假设这个数是负数,那么直接与0x00结果就是0,假设这个数是正数,直接与0xFF,那么不会改变数值。
void arm_relu_q7(q7_t *data, uint16_t size) {
/* Run the following code for M cores with DSP extension */
uint16_t i = size >> 2;
q7_t *input = data;
q7_t *output = data;
q31_t in;
q31_t buf;
q31_t mask;
while (i)
{
in = arm_nn_read_q7x4_ia((const q7_t **)&input);
/* extract the first bit */
buf = (int32_t)__ROR((uint32_t)in & 0x80808080, 7);
/* if MSB=1, mask will be 0xFF, 0x0 otherwise */
mask = __QSUB8(0x00000000, buf);
arm_nn_write_q7x4_ia(&output, in & (~mask));
i--;
}
i = size & 0x3;
while (i) {
if (*input < 0) {
*input = 0;
}
input++; i--;
}
}
3.2 sigmoid/Tanh
对于这两个激活函数,采用查表的方式,查表比较常见,此处就略过了。
4 实验和结果¶
其实CMSIS-NN属于一个从0到1的工作,这里我不敢说开创性是因为caffe/tflite可能是鼻祖,当ARM官方根据Cortex-M系列这种低性能的架构/处理器的指令情况给出了一个可行性的方法,还开源了,不管如何都是属于良心。当然也有给自己的架构开拓市场的收益啦,但开源就是良心!!
看看结果:
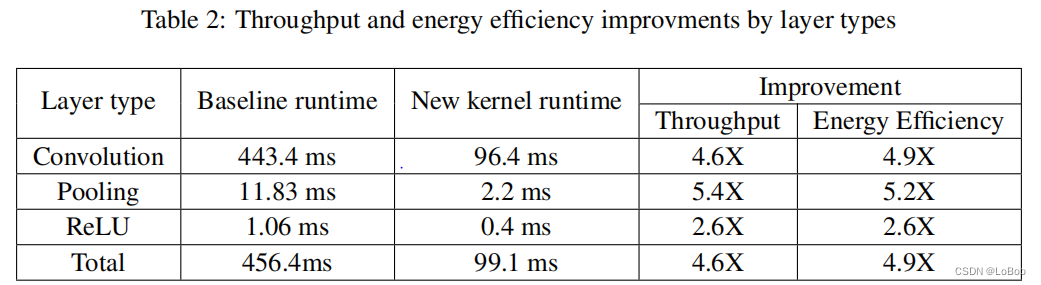
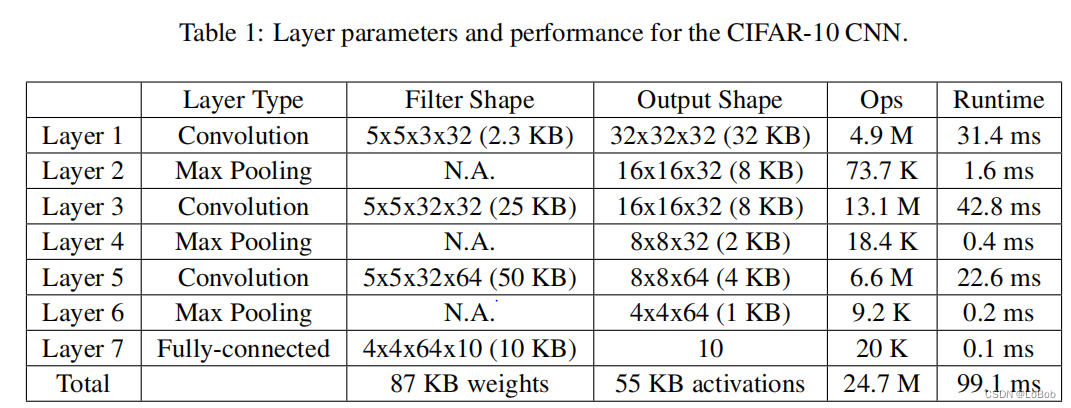
最后我总结了一下conv、pool、relu三者CMSIS-NN做的优化情况:
| Layer | Speed Up |
|---|---|
| Convolution | - |
| Pool | 4.5X |
| Relu | 4X |
本文总阅读量次