如何使用“LoRa”的方式加载Onnx模型:StableDiffusion相关模型 的C++推理
如何使用“LoRa”的方式加载Onnx模型:StableDiffusion相关模型的C++推理¶
本文主要干了以下几个事:
1.基于 onnxruntime,将 StableDiffusionInpaintPipeline、StableDiffusionControlNetImg2ImgPipeline(stablediffusion + controlnet + LoRa) C++工程化;
2.输出一个 C++版本的 ddim-schduler 库;
3.提供一种“LoRa”的 onnx 模型加载方式;
4.所有相关代码、模型开源
StableDiffusionInpaint¶
模型导出¶
StableDiffusionInpaint 的 onnx 导出非常简单,optimum 已经做好了集成,支持命令行直接导出,具体参考可参考optimum-cli:
optimum-cli export onnx —task stable-diffusion —model stable-diffusion-inpainting stable-diffusion-inpainting-onnx
这样得到了四个 onnx 模型(unet、 vae encoder、decoder 和 text encoder)。
tokenizer&scheduler¶
与检测、分类等传统 cv 方法不同,我们如果想在 c++中串起整个 pipeline,还缺少 c++版本的 tokenizer 和 scheduler。有很多优秀的开源 C++版本的 tokenizer,这里我选用了tokenizers_cpp,地址:https://github.com/mlc-ai/tokenizers-cpp。tokenizers-cpp 接口简单,并且可直接使用 🤗hugging face 中开源的的 tokenizer.json 配置文件。
auto tokenizer = Tokenizer::FromBlobJSON(
LoadBytesFromFile("./tokenizers/tokenizer.json"));
std::string startoftext = "<|startoftext|>";
std::string endoftext = "<|endoftext|>";
std::string prompt = startoftext + "a lovely girl" + endoftext;
std::vector<int> text_input_ids = tokenizer->Encode(prompt);
而对于 scheduler,目前没找到很好用的 c++版本,所以作者实现了一个 C++版本的 ddim_scheduler,并做了开源ddim_scheduler_cpp,rep地址:https://github.com/TalkUHulk/ddim_scheduler_cpp。ddim_scheduler_cpp 底层基于 Eigen 实现,与 diffusers 接口保持一致,可直接替换。
// init from json
auto scheduler = DDIMScheduler("scheduler_config.json");
// set num_inference_steps
scheduler.set_timesteps(10);
// get timesteps
std::vector<int> timesteps;
scheduler.get_timesteps(timesteps);
// random init for example
std::vector<float> sample(1 * 4 * 64 * 64);
std::vector<float> model_output(1 * 4 * 64 * 64);
for(int i = 0; i < 4 * 64 * 64; i++){
sample[i] = distribution(generator);
model_output[i] = distribution(generator);
}
// step
std::vector<float> pred_sample;
for(auto t: timesteps){
scheduler.step(model_output, {1, 4, 3, 3}, sample, {1, 4, 3, 3}, pred_sample, t);
}
C++推理¶
目前,我们将所有必须的 C++物料都集齐了。借助作者之前开源的一个开源工具AiDB(rep地址),只需要简单配置,直接可以使用 C++加载并推理 onnx 模型。
auto scheduler = Scheduler::DDIMScheduler("scheduler_config.json");
auto tokenizer = Tokenizer::FromBlobJSON(
LoadBytesFromFile("tokenizer.json"));
std::string startoftext = "<|startoftext|>";
std::string endoftext = "<|endoftext|>";
std::string prompt = startoftext + "A cute cat" + endoftext;
std::vector<int> text_input_ids = tokenizer->Encode(prompt);
std::string uncond_tokens = startoftext + "" + endoftext;
std::vector<int> uncond_input = tokenizer->Encode(uncond_tokens);
auto text_enc = AIDB::Interpreter::createInstance("text_encoder", "onnx");
std::vector<std::vector<float>> prompt_embeds;
std::vector<std::vector<int>> prompt_embeds_shape;
text_enc->forward(text_input_ids.data(), 77, 0, 0, prompt_embeds, prompt_embeds_shape);
std::vector<std::vector<float>> negative_prompt_embeds;
std::vector<std::vector<int>> negative_prompt_embeds_shape;
text_enc->forward(uncond_input.data(), 77, 0, 0, negative_prompt_embeds, negative_prompt_embeds_shape);
std::vector<float> prompt_embeds_cat(2 * 77 * 768, 0);
memcpy(prompt_embeds_cat.data(), negative_prompt_embeds[0].data(), 77 * 768 * sizeof(float));
memcpy(prompt_embeds_cat.data() + 77 * 768, prompt_embeds[0].data(), 77 * 768 * sizeof(float));
auto num_inference_steps = 10;
scheduler.set_timesteps(num_inference_steps);
std::vector<int> timesteps;
scheduler.get_timesteps(timesteps);
auto vae_enc = AIDB::Interpreter::createInstance("sd_inpaint_vae_encoder", "onnx");
auto vae_dec = AIDB::Interpreter::createInstance("sd_inpaint_vae_decoder", "onnx");
auto unet = AIDB::Interpreter::createInstance("sd_inpaint_unet", "onnx");
std::vector<float> latents(1 * 4 * 64 * 64);
AIDB::Utility::randn(latents.data(), latents.size());
auto image = cv::imread("dog.png");
auto mask = cv::imread("dog_mask.png", 0);
// 图像预处理
int target = 512;
float src_ratio = float(image.cols) / float(image.rows);
float target_ratio = 1.0f;
int n_w, n_h, pad_w = 0, pad_h = 0;
float _scale_h, _scale_w;
if(src_ratio > target_ratio){
n_w = target;
n_h = floor(float(n_w) / float(image.cols) * float(image.rows) + 0.5f);
pad_h = target - n_h;
_scale_h = _scale_w = float(n_w) / float(image.cols);
} else if(src_ratio < target_ratio){
n_h = target;
n_w = floor(float(n_h) / float(image.rows) * float(image.cols) + 0.5f);
pad_w = target - n_w;
_scale_h = _scale_w = float(n_h) / float(image.rows);
} else{
n_w = target;
n_h = target;
_scale_h = _scale_w = float(n_w) / float(image.cols);
}
cv::resize(image, image, cv::Size(n_w, n_h));
cv::copyMakeBorder(image, image, 0, pad_h, 0, pad_w, cv::BORDER_CONSTANT, cv::Scalar(255, 255, 255));
cv::resize(mask, mask, cv::Size(n_w, n_h));
cv::copyMakeBorder(mask, mask, 0, pad_h, 0, pad_w, cv::BORDER_CONSTANT, cv::Scalar(255, 255, 255));
cv::threshold(mask, mask, 127.5, 1, cv::THRESH_BINARY);
cv::cvtColor(image, image, cv::COLOR_BGR2RGB);
image.convertTo(image, CV_32F);
image = image / 127.5 - 1.0;
cv::Mat mask_image = cv::Mat::zeros(image.rows, image.cols, CV_32FC3);
image.copyTo(mask_image, 1 - mask);
cv::Mat blob;
cv::Mat blob_mask;
cv::dnn::blobFromImage(mask_image, blob);
cv::dnn::blobFromImage(mask, blob_mask, 1.0f, cv::Size(64, 64));
std::vector<std::vector<float>> masked_image_latents;
std::vector<std::vector<int>> masked_image_latents_shape;
vae_enc->forward(blob.data, 512, 512, 3, masked_image_latents, masked_image_latents_shape);
auto scaling_factor = 0.18215f;
std::for_each(masked_image_latents.begin(), masked_image_latents.end(),
[=](std::vector<float>& masked_image_latent) {
std::for_each(masked_image_latent.begin(), masked_image_latent.end(), [=](float &item){ item *= scaling_factor;});
}
);
auto init_noise_sigma = scheduler.get_init_noise_sigma();
std::for_each(latents.begin(), latents.end(), [=](float &item){item*=init_noise_sigma;});
auto guidance_scale = 7.5f;
int step = 0;
// 循环处理
for(auto t: timesteps){
auto tic = std::chrono::system_clock::now();
std::vector<float> latent_model_input(2 * 9 * 64 * 64, 0);
memcpy(latent_model_input.data(), latents.data(), 4 * 64 * 64 * sizeof(float));
memcpy(latent_model_input.data() + 4 * 64 * 64, blob_mask.data, 1 * 64 * 64 * sizeof(float));
memcpy(latent_model_input.data() + 5 * 64 * 64, masked_image_latents[0].data(), 4 * 64 * 64 * sizeof(float));
memcpy(latent_model_input.data() + 9 * 64 * 64, latent_model_input.data(), 9 * 64 * 64 * sizeof(float));
std::vector<std::vector<float>> noise_preds;
std::vector<std::vector<int>> noise_preds_shape;
std::vector<void *> input;
std::vector<std::vector<int>> input_shape;
input.push_back(latent_model_input.data());
input_shape.push_back({2, 9, 64, 64});
std::vector<long long> timestep = {(long long)t};
input.push_back(timestep.data());
input_shape.push_back({1});
input.push_back(prompt_embeds_cat.data());
input_shape.push_back({2, 77, 768});
unet->forward(input, input_shape, noise_preds, noise_preds_shape);
// noise_preds [2,4,64,64] noise_pred_uncond | noise_pred_text
std::vector<float> noise_pred(1 * 4 * 64 * 64, 0);
for(int i = 0; i < noise_pred.size(); i++){
noise_pred[i] = noise_preds[0][i] + guidance_scale * (noise_preds[0][i + 4 * 64 * 64] - noise_preds[0][i]);
}
std::vector<float> pred_sample;
scheduler.step(noise_pred, {1, 4, 64, 64}, latents, {1, 4, 64, 64}, pred_sample, t);
latents.clear();
latents.assign(pred_sample.begin(), pred_sample.end());
auto toc = std::chrono::system_clock::now();
std::chrono::duration<double> elapsed = toc - tic;
// 计算并输出进度百分比
std::cout << "\rStep " << step++ << " " <<std::fixed << std::setprecision(1) << float(step) / timesteps.size() * 100
<< "% " << std::fixed << std::setprecision(3) << 1.0f / elapsed.count() << "b/s"
<< " [" << std::setw(float(step) / (float)timesteps.size() * 30) << std::setfill('=') << '>' << ']';
std::flush(std::cout);
}
std::for_each(latents.begin(), latents.end(), [=](float &item){item /= scaling_factor;});
std::vector<std::vector<float>> sample;
std::vector<std::vector<int>> sample_shape;
vae_dec->forward(latents.data(), 64, 64, 4, sample, sample_shape);
cv::Mat sd_image;
AIDB::Utility::stable_diffusion_process(sample[0].data(), sample_shape[0][2], sample_shape[0][3], sample_shape[0][1], sd_image);
cv::imwrite("stable_diffusion_inpainting.jpg", sd_image);

至此,我们已经成功搭建起 stablediffusioninpaint 的 C++ pipeline,但更常用、更有趣的是 controlnet 和 lora 与 stablediffusion 的结合。下面我们尝试搭建 StableDiffusionControlNetImg2ImgPipeline 的 C++推理代码,并支持 LoRa 加载。
StableDiffusionControlNetImg2ImgPipeline¶
模型导出¶
目前 optimum 还未提供 stablediffusion + controlnet +LoRa 的 onnx 模型导出选项,所以这里我们先将模型导出。 这里我们有两种导出方案,分别导出 controlNet 和 Unet,以及将二者合并为一个模型。
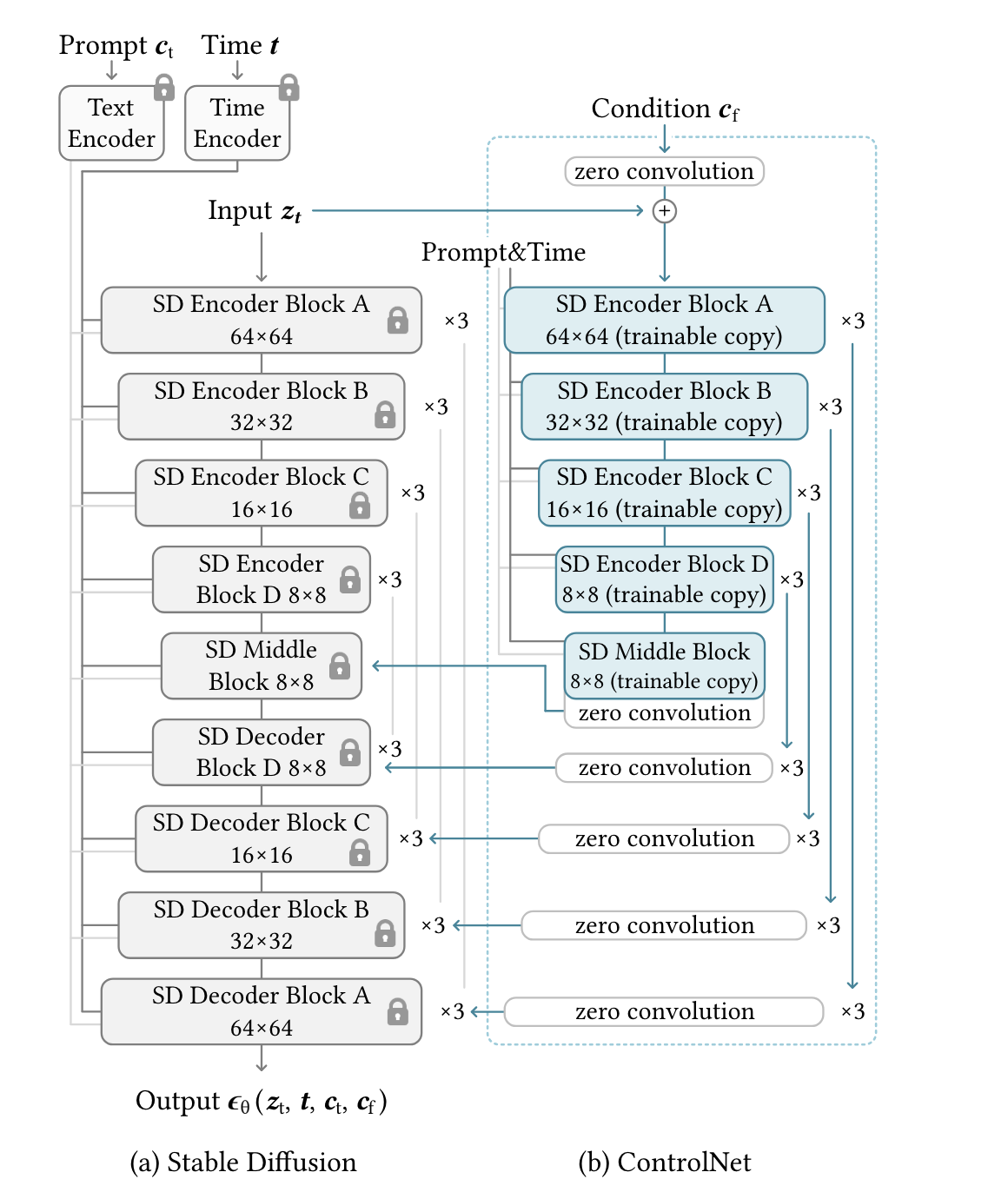
先看一下 controlNet 的整体架构,controlNet 和 Unet 的耦合比较深,如果我们分开导出,两个模型的输出和输入数量都会非常多,比入 Unet 部分有 down_block_res_sample_0 ~ down_block_res_sample_11、mid_block_res_sample 等 16 个输入,这样在写 inference 代码的时候就会比较繁琐。所以我们选择将两个模型合并为一个。但这样也有有另一个问题,比如我首先使用 controlNet-canny 导出了 onnx 模型,同时又想使用 controlNet-hed,那 unet 部分是不是要重复导出?这里有几个方法解决,我们后面再说明。
此处使用Yoji Shinkawa Style LoRA(🤗 https://civitai.com/models/12324/yoji-shinkawa-style-lora)
导出代码:
from diffusers import (
ControlNetModel,
StableDiffusionControlNetImg2ImgPipeline,
)
from diffusers.models.attention_processor import AttnProcessor
is_torch_less_than_1_11 = version.parse(version.parse(torch.__version__).base_version) < version.parse("1.11")
is_torch_2_0_1 = version.parse(version.parse(torch.__version__).base_version) == version.parse("2.0.1")
class UNetControlNetModel(torch.nn.Module):
def __init__(
self,
unet,
controlnet: ControlNetModel,
):
super().__init__()
self.unet = unet
self.controlnet = controlnet
def forward(
self,
sample,
timestep,
encoder_hidden_states,
controlnet_cond,
conditioning_scale,
):
for i, (_controlnet_cond, _conditioning_scale) in enumerate(
zip(controlnet_cond, conditioning_scale)
):
down_samples, mid_sample = self.controlnet(
sample,
timestep,
encoder_hidden_states=encoder_hidden_states,
controlnet_cond=_controlnet_cond,
conditioning_scale=_conditioning_scale,
return_dict=False,
)
# merge samples
if i == 0:
down_block_res_samples, mid_block_res_sample = down_samples, mid_sample
else:
down_block_res_samples = [
samples_prev + samples_curr
for samples_prev, samples_curr in zip(down_block_res_samples, down_samples)
]
mid_block_res_sample += mid_sample
noise_pred = self.unet(
sample,
timestep,
encoder_hidden_states=encoder_hidden_states,
down_block_additional_residuals=down_block_res_samples,
mid_block_additional_residual=mid_block_res_sample,
return_dict=False,
)[0]
return noise_pred
def onnx_export(
model,
model_args: tuple,
output_path: Path,
ordered_input_names,
output_names,
dynamic_axes,
opset,
use_external_data_format=False,
):
output_path.parent.mkdir(parents=True, exist_ok=True)
with torch.inference_mode(), torch.autocast("cuda"):
if is_torch_less_than_1_11:
export(
model,
model_args,
f=output_path.as_posix(),
input_names=ordered_input_names,
output_names=output_names,
dynamic_axes=dynamic_axes,
do_constant_folding=True,
use_external_data_format=use_external_data_format,
enable_onnx_checker=True,
opset_version=opset,
)
else:
export(
model,
model_args,
f=output_path.as_posix(),
input_names=ordered_input_names,
output_names=output_names,
dynamic_axes=dynamic_axes,
do_constant_folding=True,
opset_version=opset,
)
with torch.no_grad():
dtype = torch.float32
device = "cpu"
# init controlnet
controlnet = ControlNetModel.from_pretrained("sd-controlnet-canny", torch_dtype=dtype).to(device)
if is_torch_2_0_1:
controlnet.set_attn_processor(AttnProcessor())
pipeline = StableDiffusionControlNetImg2ImgPipeline.from_pretrained(
"stable-diffusion-v1-5", controlnet=controlnet, torch_dtype=dtype, safety_checker=None
).to(device)
pipeline.load_lora_weights("stable-diffusion-v1-5/LoRa/", "shinkawa_youji_offset")
output_path = Path("exp_lora")
if is_torch_2_0_1:
pipeline.unet.set_attn_processor(AttnProcessor())
pipeline.vae.set_attn_processor(AttnProcessor())
# # TEXT ENCODER
num_tokens = pipeline.text_encoder.config.max_position_embeddings
text_hidden_size = pipeline.text_encoder.config.hidden_size
text_input = pipeline.tokenizer(
"A sample prompt",
padding="max_length",
max_length=pipeline.tokenizer.model_max_length,
truncation=True,
return_tensors="pt",
)
onnx_export(
pipeline.text_encoder,
# casting to torch.int32 until the CLIP fix is released: https://github.com/huggingface/transformers/pull/18515/files
model_args=(text_input.input_ids.to(device=device, dtype=torch.int32)),
output_path=output_path / "text_encoder" / "model.onnx",
ordered_input_names=["input_ids"],
output_names=["last_hidden_state", "pooler_output"],
dynamic_axes={
"input_ids": {0: "batch", 1: "sequence"},
},
opset=14,
)
del pipeline.text_encoder
## VAE ENCODER
vae_encoder = pipeline.vae
vae_in_channels = vae_encoder.config.in_channels
vae_sample_size = vae_encoder.config.sample_size
# need to get the raw tensor output (sample) from the encoder
vae_encoder.forward = lambda sample: vae_encoder.encode(sample).latent_dist.sample()
onnx_export(
vae_encoder,
model_args=(torch.randn(1, vae_in_channels, vae_sample_size, vae_sample_size).to(device=device, dtype=dtype),),
output_path=output_path / "vae_encoder" / "model.onnx",
ordered_input_names=["sample"],
output_names=["latent_sample"],
dynamic_axes={
"sample": {0: "batch", 1: "channels", 2: "height", 3: "width"},
},
opset=14,
)
# # UNET
unet_controlnet = UNet2DConditionControlNetModel(pipeline.unet, controlnet)
unet_in_channels = pipeline.unet.config.in_channels
unet_sample_size = pipeline.unet.config.sample_size
num_tokens = pipeline.text_encoder.config.max_position_embeddings
text_hidden_size = pipeline.text_encoder.config.hidden_size
img_size = 8 * unet_sample_size
unet_path = output_path / "unet" / "model.onnx"
onnx_export(
unet_controlnet,
model_args=(
torch.randn(2, unet_in_channels, unet_sample_size, unet_sample_size).to(device=device, dtype=dtype),
torch.tensor([1.0]).to(device=device, dtype=dtype),
torch.randn(2, num_tokens, text_hidden_size).to(device=device, dtype=dtype),
torch.randn(2, 3, img_size, img_size).to(device=device, dtype=dtype),
torch.tensor([1.0]).to(device=device, dtype=dtype),
),
output_path=unet_path,
ordered_input_names=[
"sample",
"timestep",
"encoder_hidden_states",
"controlnet_cond",
"conditioning_scale",
],
output_names=["noise_pred"], # has to be different from "sample" for correct tracing
dynamic_axes={
"sample": {0: "2B", 2: "H", 3: "W"},
"encoder_hidden_states": {0: "2B"},
"controlnet_cond": {0: "2B", 2: "8H", 3: "8W"},
},
opset=14,
use_external_data_format=True, # UNet is > 2GB, so the weights need to be split
)
unet_model_path = str(unet_path.absolute().as_posix())
unet_opt_graph = onnx.load(unet_model_path)
onnx.save_model(
unet_opt_graph,
unet_model_path,
save_as_external_data=True,
all_tensors_to_one_file=True,
location="model.onnx_data",
convert_attribute=False,
)
del pipeline.unet
# VAE DECODER
vae_decoder = pipeline.vae
vae_latent_channels = vae_decoder.config.latent_channels
# forward only through the decoder part
vae_decoder.forward = vae_encoder.decode
onnx_export(
vae_decoder,
model_args=(
torch.randn(1, vae_latent_channels, unet_sample_size, unet_sample_size).to(device=device, dtype=dtype),
),
output_path=output_path / "vae_decoder" / "model.onnx",
ordered_input_names=["latent_sample"],
output_names=["sample"],
dynamic_axes={
"latent_sample": {0: "batch", 1: "channels", 2: "height", 3: "width"},
},
opset=14,
)
这里有几个点需要注意。
OP 问题¶
pytorch2.0 以上,需要做以下设置才可以成功导出
pipeline.unet.set_attn_processor(AttnProcessor())
pipeline.vae.set_attn_processor(AttnProcessor())
controlnet.set_attn_processor(AttnProcessor())
具体可以参考 diffusers->models->attention_processor.py 中的相关代码。Pytorch2.0 以上 scaled dot-product attention 计算会默认使用torch.nn.functional.scaled_dot_product_attention,而 onnx 导出时不支持该 OP。
torch.onnx.errors.UnsupportedOperatorError: Exporting the operator 'aten::scaled_dot_product_attention' to ONNX opset version 14 is not supported.
因此需要做替换,diffusers 很贴心的把相关代码实现好,我们直接使用即可。
模型大小>2GB¶
ONNX 模型本质就是一个 Protobuf 序列化后的二进制文件,而 Protobuf 的文件大小限制为 2GB。因此对于 Unet 相关模型来说,存储大小已经超过了限制。onnx 给出的方案是单独存储 weights、bias 这些权重。 这里做下详细说明。 先来看下onnx.proto(文件地址:https://github.com/onnx/onnx/blob/main/onnx/onnx.proto)中的定义:
message TensorProto {
....
repeated int64 dims = 1;
optional int32 data_type = 2;
....
// Data can be stored inside the protobuf file using type-specific fields or raw_data.
// Alternatively, raw bytes data can be stored in an external file, using the external_data field.
// external_data stores key-value pairs describing data location. Recognized keys are:
// - "location" (required) - POSIX filesystem path relative to the directory where the ONNX
// protobuf model was stored
// - "offset" (optional) - position of byte at which stored data begins. Integer stored as string.
// Offset values SHOULD be multiples 4096 (page size) to enable mmap support.
// - "length" (optional) - number of bytes containing data. Integer stored as string.
// - "checksum" (optional) - SHA1 digest of file specified in under 'location' key.
repeated StringStringEntryProto external_data = 13;
// Location of the data for this tensor. MUST be one of:
// - DEFAULT - data stored inside the protobuf message. Data is stored in raw_data (if set) otherwise in type-specified field.
// - EXTERNAL - data stored in an external location as described by external_data field.
enum DataLocation {
DEFAULT = 0;
EXTERNAL = 1;
}
// If value not set, data is stored in raw_data (if set) otherwise in type-specified field.
optional DataLocation data_location = 14;
}
我们可以通过 data_location 来判断某个参数的位置,然后读取 external_data 参数加载权重,接下来我们在代码中手动加载:
import onnx
from onnx.external_data_helper import _get_all_tensors
onnx_model = onnx.load("unet/model.onnx", load_external_data=False)
for tensor in _get_all_tensors(onnx_model):
if tensor.HasField("data_location") and tensor.data_location == onnx.TensorProto.EXTERNAL:
info = {}
for item in tensor.external_data:
info[item.key] = item.value
with open(info["location"], "rb") as data_file:
data_file.seek(info["offset"])
tensor.raw_data = data_file.read(info["length"])
摘出其中一个 tensor 的 external_data 详细说明:
[ key: "location"
value: "model.onnx_data"
, key: "offset"
value: "0"
, key: "length"
value: "46080"
]
location 记录了权重存储的文件名,offset 是该权重在文件中的偏移量,length 是权重的长度。有了以上信息,onnx 内部就可以直接 load 权重,解决 2GB 限制问题。
仔细的同学会观察到,导出的 uent 目录下有,除了.onnx 模型,还有非常非常多的 weight/bias 等文件。这其实就是每一个权重数据。如此碎片化,我们使用或者版本管理起来非常不方便。我们使用以下代码,将所有的权重合并到一个文件中:
unet_opt_graph = onnx.load(unet_model_path)
onnx.save_model(
unet_opt_graph,
unet_model_path,
save_as_external_data=True,
all_tensors_to_one_file=True,
location="model.onnx_data",
convert_attribute=False,
)
这样所有的权重就会保存到一个 model.onnx_data 文件里。
C++推理¶
与上文类似,借助 AiDB,使用 C++串起整个 pipeline
std::vector<float> noise(1 * 4 * 64 * 64);
AIDB::Utility::randn(noise.data(), noise.size());
auto strength = 1.0f; // 0~1 之间重绘比例。越低越接近输入图片。
auto scheduler = Scheduler::DDIMScheduler("scheduler_config.json");
auto scaling_factor = 0.18215f;
auto tokenizer = Tokenizer::FromBlobJSON(
LoadBytesFromFile("tokenizer.json"));
std::string startoftext = "<|startoftext|>";
std::string endoftext = "<|endoftext|>";
std::string trigger = argv[1];
std::string prompt = startoftext + trigger + endoftext;
std::vector<int> text_input_ids = tokenizer->Encode(prompt);
std::string uncond_tokens = startoftext + "longbody, lowres, cropped, worst quality, low quality, multiple people" + endoftext;
std::vector<int> uncond_input = tokenizer->Encode(uncond_tokens);
auto text_enc = AIDB::Interpreter::createInstance("text_encoder", "onnx");
std::vector<std::vector<float>> prompt_embeds;
std::vector<std::vector<int>> prompt_embeds_shape;
text_enc->forward(text_input_ids.data(), 77, 0, 0, prompt_embeds, prompt_embeds_shape);
std::vector<std::vector<float>> negative_prompt_embeds;
std::vector<std::vector<int>> negative_prompt_embeds_shape;
text_enc->forward(uncond_input.data(), 77, 0, 0, negative_prompt_embeds, negative_prompt_embeds_shape);
std::vector<float> prompt_embeds_cat(2 * 77 * 768, 0);
memcpy(prompt_embeds_cat.data(), negative_prompt_embeds[0].data(), 77 * 768 * sizeof(float));
memcpy(prompt_embeds_cat.data() + 77 * 768, prompt_embeds[0].data(), 77 * 768 * sizeof(float));
auto num_inference_steps = 10;
scheduler.set_timesteps(num_inference_steps);
std::vector<int> timesteps;
scheduler.get_timesteps(timesteps);
// Figuring initial time step based on strength
auto init_timestep = min(int(num_inference_steps * strength), num_inference_steps);
auto t_start = max(num_inference_steps - init_timestep, 0);
timesteps.assign(timesteps.begin() + t_start, timesteps.end());
num_inference_steps = timesteps.size();
auto image = cv::imread("portrait.png");
int target = 512;
float src_ratio = float(image.cols) / float(image.rows);
float target_ratio = 1.0f;
int n_w, n_h, pad_w = 0, pad_h = 0;
float _scale_h, _scale_w;
if(src_ratio > target_ratio){
n_w = target;
n_h = floor(float(n_w) / float(image.cols) * float(image.rows) + 0.5f);
pad_h = target - n_h;
_scale_h = _scale_w = float(n_w) / float(image.cols);
} else if(src_ratio < target_ratio){
n_h = target;
n_w = floor(float(n_h) / float(image.rows) * float(image.cols) + 0.5f);
pad_w = target - n_w;
_scale_h = _scale_w = float(n_h) / float(image.rows);
} else{
n_w = target;
n_h = target;
_scale_h = _scale_w = float(n_w) / float(image.cols);
}
cv::resize(image, image, cv::Size(n_w, n_h));
cv::copyMakeBorder(image, image, 0, pad_h, 0, pad_w, cv::BORDER_CONSTANT, cv::Scalar(255, 255, 255));
auto low_threshold = 150;
auto high_threshold = 200;
cv::Mat canny;
cv::Canny(image, canny, low_threshold, high_threshold);
std::vector<cv::Mat> bgr_channels{canny, canny, canny};
cv::merge(bgr_channels, canny);
image.convertTo(image, CV_32F);
image = image / 127.5 - 1.0;
cv::Mat blob;
cv::dnn::blobFromImage(image, blob);
canny.convertTo(canny, CV_32F);
cv::Mat blob_canny;
cv::dnn::blobFromImage(canny, blob_canny, 1.0f / 255.0f);
auto vae_enc = AIDB::Interpreter::createInstance("sd_vae_encoder_with_controlnet", "onnx");
auto vae_dec = AIDB::Interpreter::createInstance("sd_vae_decoder_with_controlnet", "onnx");
auto unet = AIDB::Interpreter::createInstance2("sd_unet_with_controlnet_with_lora", "shinkawa", "onnx");
// Prepare latent variables
std::vector<std::vector<float>> image_latents;
std::vector<std::vector<int>> image_latents_shape;
vae_enc->forward(blob.data, 512, 512, 3, image_latents, image_latents_shape);
auto latents = image_latents[0];
std::for_each(latents.begin(), latents.end(), [=](float &item){item *= scaling_factor;});
auto latent_timestep = timesteps[0];
std::vector<float> init_latents;
scheduler.add_noise(latents, {1, 4, 64, 64}, noise, {1, 4, 64, 64}, latent_timestep, init_latents);
auto guidance_scale = 7.5f;
std::vector<float> controlnet_keep(timesteps.size(), 1.0);
float controlnet_conditioning_scale = 0.5f; // 0~1 之间的 ControlNet 约束比例。越高越贴近约束。
int step = 0;
for(auto t: timesteps){
auto tic = std::chrono::system_clock::now();
double cond_scale = controlnet_conditioning_scale * controlnet_keep[step];
std::vector<float> latent_model_input(2 * 4 * 64 * 64, 0);
memcpy(latent_model_input.data(), init_latents.data(), 4 * 64 * 64 * sizeof(float));
memcpy(latent_model_input.data() + 4 * 64 * 64, init_latents.data(), 4 * 64 * 64 * sizeof(float));
std::vector<std::vector<float>> down_and_mid_blok_samples;
std::vector<std::vector<int>> down_and_mid_blok_samples_shape;
std::vector<void*> input;
std::vector<std::vector<int>> input_shape;
// sample
input.push_back(latent_model_input.data());
input_shape.push_back({2, 4, 64, 64});
// t ✅
std::vector<float> timestep = {(float)t};
input.push_back(timestep.data());
input_shape.push_back({1});
// encoder_hidden_states ✅
input.push_back(prompt_embeds_cat.data());
input_shape.push_back({2, 77, 768});
std::vector<float> controlnet_cond(2 * 3 * 512 * 512, 0);
memcpy(controlnet_cond.data(), blob_canny.data, 3 * 512 * 512 * sizeof(float));
memcpy(controlnet_cond.data() + 3 * 512 * 512, blob_canny.data, 3 * 512 * 512 * sizeof(float));
// controlnet_cond ✅
input.push_back(controlnet_cond.data());
input_shape.push_back({2, 3, 512, 512});
// conditioning_scale ✅
std::vector<float> cond_scales = {(float)(cond_scale)};
input.push_back(cond_scales.data());
input_shape.push_back({1});
std::vector<std::vector<float>> noise_preds;
std::vector<std::vector<int>> noise_preds_shape;
unet->forward(input, input_shape, noise_preds, noise_preds_shape);
// noise_preds [2,4,64,64] noise_pred_uncond | noise_pred_text
std::vector<float> noise_pred(1 * 4 * 64 * 64, 0);
for(int i = 0; i < noise_pred.size(); i++){
noise_pred[i] = noise_preds[0][i] + guidance_scale * (noise_preds[0][i + 4 * 64 * 64] - noise_preds[0][i]);
}
std::vector<float> pred_sample;
scheduler.step(noise_pred, {1, 4, 64, 64}, init_latents, {1, 4, 64, 64}, pred_sample, t);
init_latents.clear();
init_latents.assign(pred_sample.begin(), pred_sample.end());
auto toc = std::chrono::system_clock::now();
std::chrono::duration<double> elapsed = toc - tic;
std::cout << "\rStep " << step++ << " " <<std::fixed << std::setprecision(1) << float(step) / timesteps.size() * 100
<< "% " << std::fixed << std::setprecision(3) << 1.0f / elapsed.count() << "b/s"
<< " [" << std::setw(float(step) / (float)timesteps.size() * 30) << std::setfill('=') << '>' << ']';
std::flush(std::cout);
}
std::for_each(init_latents.begin(), init_latents.end(), [=](float &item){item /= scaling_factor;});
std::vector<std::vector<float>> sample;
std::vector<std::vector<int>> sample_shape;
vae_dec->forward(init_latents.data(), 64, 64, 4, sample, sample_shape);
cv::Mat sd_image(sample_shape[0][2], sample_shape[0][3], CV_8UC3);
AIDB::Utility::stable_diffusion_process(sample[0].data(), sample_shape[0][2], sample_shape[0][3], sample_shape[0][1], sd_image);
cv::imwrite("stable_diffusion_controlnet_img2img_" + trigger + ".jpg", sd_image);

LoRA 方式加载¶
回到上文提到的问题,以上例子使用 controlNet-canny 导出 onnx 模型,如果我们又想使用 controlNet-hed,或者使用更多的 LoRa 呢?是否一定必须重新导出整个模型, 是否可以用“LoRa”的方式加载模型呢。答案是肯定的,查看 onnruntime 的接口,官方提供了如下接口:
SessionOptions& SessionOptions::AddExternalInitializers(const std::vector<std::string>& names,const std::vector<Value>& ort_values)
利用此接口,我们可以实现“LoRa 方式”的模型加载。这里以“LoRa”举例,controlNet 同理。
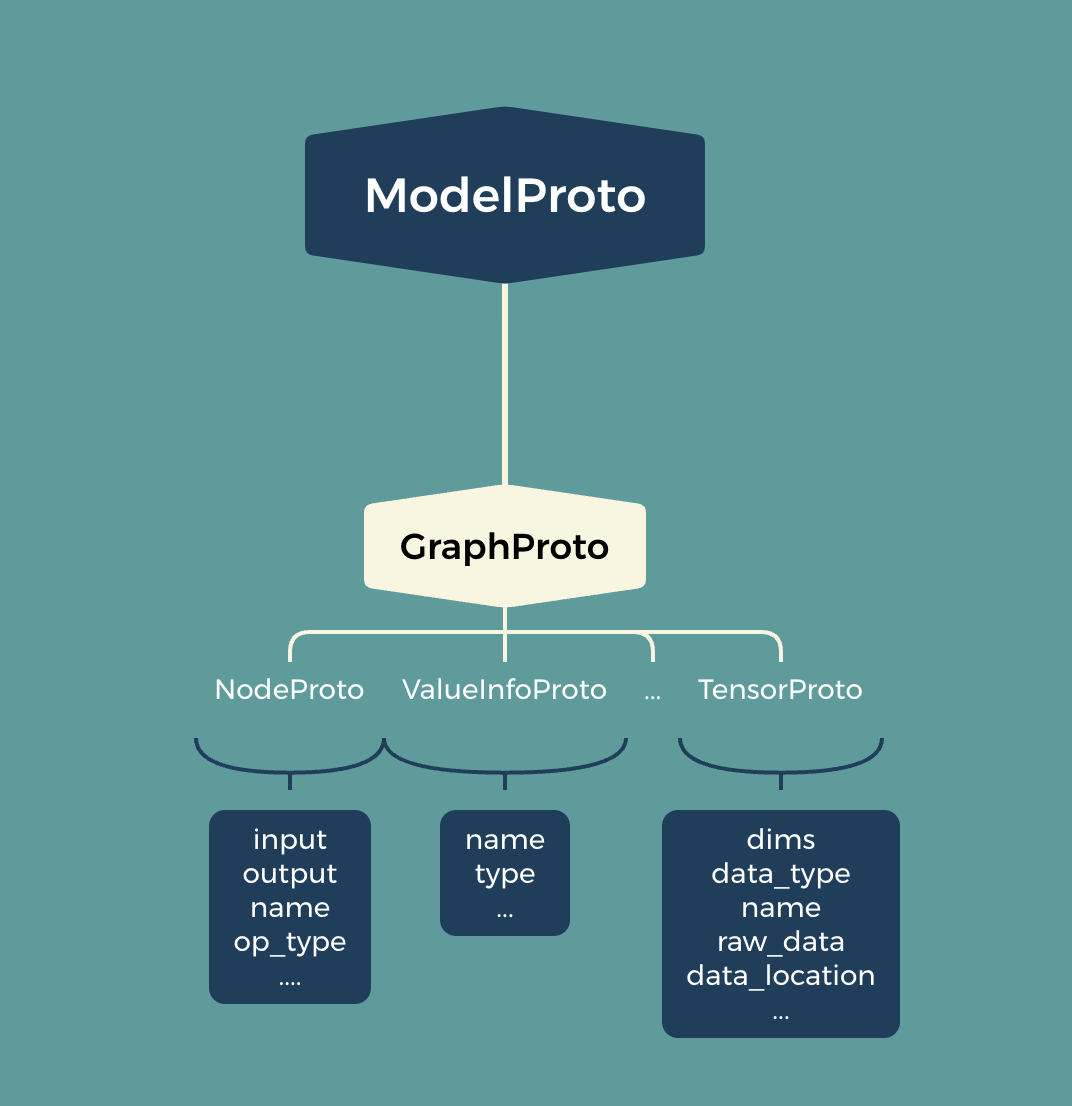
先做一点简单的知识储备,ONNX 模型本质就是一个 Protobuf 序列化后的二进制文件,所以理论上我们可以做任意合理的修改。根据 onnx.proto 的定义,首先来看一下 onnx 模型的结构。 onnx 主要包含以下几个类:ModelProto,NodeProto,GraphProto,TensorProto 等。ModelProto 作为 top-level 类,用于绑定 ML 模型并将其计算图与元数据相关联。NodeProto 用来描述了 graph 中的 node。TensorProto 则用来组织 tensor 的具体信息。所以 onnx 的结构大概可以用下图表示:
这样我们就有了一个大概的思路,读取 LoRa 模型,解析 LoRa 模型中 tensor,因为网络结构都是相同的,我们直接通过 onnxruntime 的 AddExternalInitializers 接口,来替换原始网络中的 LoRa 部分。
onnx 模型读取¶
使用 protobuf 读取 onnx 模型,而不是使用 ort:
std::ifstream fin(lora_path, std::ios::in | std::ios::binary);
onnx::ModelProto onnx_model;
onnx_model.ParseFromIstream(&fin);
auto graph = onnx_model.graph();
const auto& initializer = graph.initializer();
std::vector<std::string> init_names;
std::vector<Ort::Value> initializer_data;
for(auto& tensor: initializer){
init_names.push_back(tensor.name());
tensors.emplace_back(tensor);
}
fin.close();
OP名称¶
原始模型与 onnx 导出的模型的名字是不一致的,我们需要找到映射关系,才能正确加载。 首先加载 🤗safetensors 格式的模型
from safetensors.torch import load_file
state_dict = load_file("LoRa.safetensors")
此时 state_dict 中的 key 并不是模型 onnx 导出前的 key,这里需要做一个转换。直接参考 diffusers 的代码:
from diffusers.loaders.lora_conversion_utils import _convert_kohya_lora_to_diffusers, _maybe_map_sgm_blocks_to_diffusers
from diffusers.utils.state_dict_utils import convert_unet_state_dict_to_peft, convert_state_dict_to_diffusers
indent = " "
unet_config = None
# Map SDXL blocks correctly.
if unet_config is not None:
# use unet config to remap block numbers
state_dict = _maybe_map_sgm_blocks_to_diffusers(state_dict, unet_config)
state_dict, network_alphas = _convert_kohya_lora_to_diffusers(state_dict)
keys = list(state_dict.keys())
unet_name = "unet"
text_encoder_name = "text_encoder"
unet_keys = [k for k in keys if k.startswith(unet_name)]
unet_state_dict = {k: v for k, v in state_dict.items() if k in unet_keys}
unet_state_dict = convert_unet_state_dict_to_peft(unet_state_dict)
text_encoder_lora_state_dict = {}
if any(text_encoder_name in key for key in keys):
text_encoder_keys = [k for k in keys if k.startswith(text_encoder_name) and k.split(".")[0] == text_encoder_name]
text_encoder_lora_state_dict = {
k.replace(f"{text_encoder_name}.", ""): v for k, v in state_dict.items() if k in text_encoder_keys
}
text_encoder_lora_state_dict = convert_state_dict_to_diffusers(text_encoder_lora_state_dict)
unet_lora_state_dict = {}
for key, value in unet_state_dict.items():
name = key
if "lora_A" in key:
name = key.replace("lora_A", "lora_layer.down")
elif "lora_B" in key:
name = key.replace("lora_B", "lora_layer.up")
unet_lora_state_dict[name] = value
执行以上代码,可以得到 torch.onnx.export 前模型的 key:value。接下来就是和 onnx 模型中的 name 找到对应关系。
其实 onnx 模型中已经储存了对应的对应关系,我们使用以下代码先观察下 onnx 模型中村了什么信息(这里只输出了 lora 相关的):
onnx_model = onnx.load("unet.onnx", load_external_data=False)
for node in onnx_model.graph.node:
print(onnx.helper.printable_node(node, indent, subgraphs=True))
部分输出:
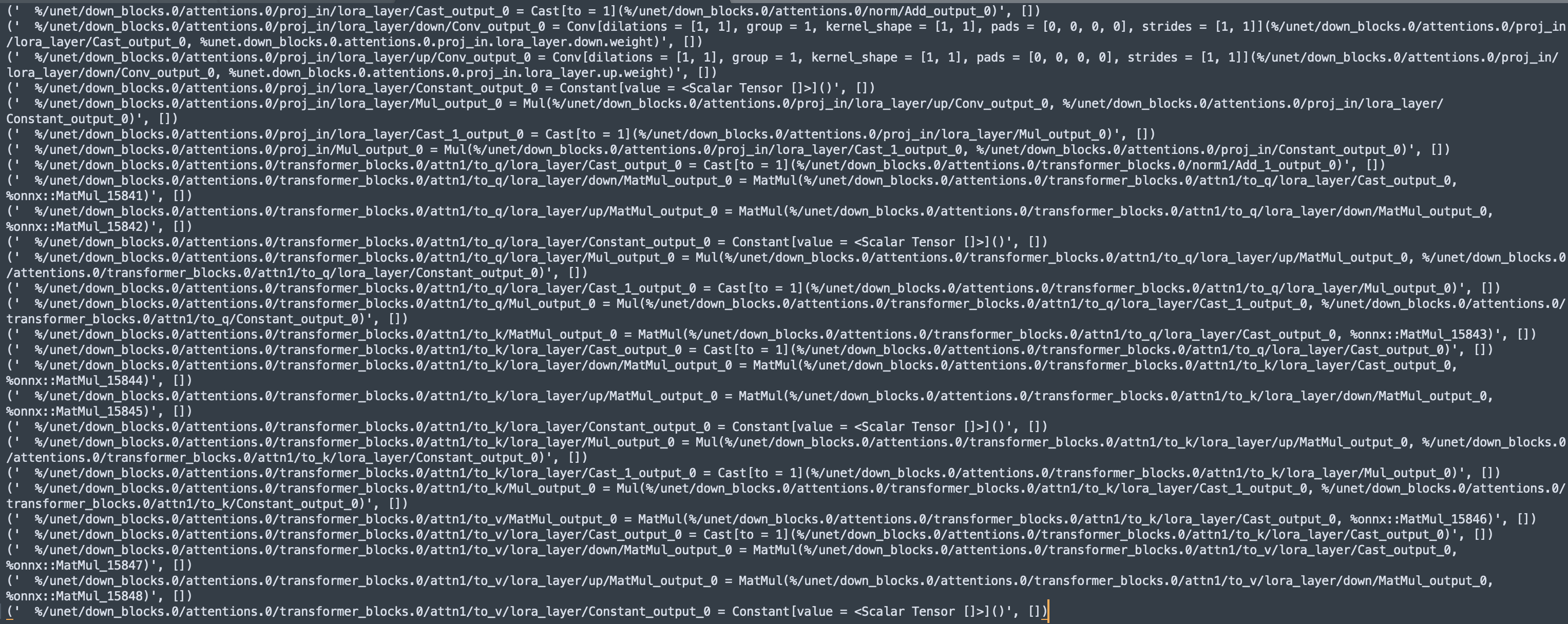
可以看到每个node的对应关系,格式如下torch-op-name = OP(param, onnx-tensor-name)。按照以上规则,可以找到两种模型opname的映射,将这种关系保存下来:
unet_mapping = {}
for node in onnx_model.graph.node:
contents = onnx.helper.printable_node(node, indent, subgraphs=True)[0]
content = re.findall(r'%.*?(?= |,)|%.*?(?=\))', contents) # torch-op-name = OP(形参, onnx-weight-name)
if ".".join(content[0].split("/")[1:-1] + ["weight"]) in unet_lora_state_dict:
unet_mapping[".".join(content[0].split("/")[1:-1] + ["weight"])] = content[-1][1:]
LoRa保存¶
最后就是如何组织新的LoRa模型了。这里为了方便,我们构造一个“假的”onnx模型,仅仅存储LoRa的权重,name以上一节映射后为准。
initializer = []
for key, value in unet_lora_state_dict.items():
initializer.append(
helper.make_tensor(
name=unet_mapping[key],
data_type=helper.TensorProto.DataType.FLOAT,
dims=value.T.shape if value.ndim == 2 else value.shape,
vals=value.T.float().numpy().astype(np.float32).tobytes()
if value.ndim == 2 else value.float().numpy().astype(np.float32).tobytes(),
raw=True
)
)
graph = helper.make_graph(
name=LoRa,
inputs=[],
outputs=[],
nodes=[],
initializer=initializer
)
opset = [
helper.make_operatorsetid(LoRa, 14)
]
model = helper.make_model(graph, opset_imports=opset)
onnx.save_model(model, "LoRa.lora")
LoRa校验¶
以上3步已经得到了新的模型,但为了确认我们的方式是否正确,我们拿一个已经导出的Unet模型和对应的LoRa权重做一下校验
import onnx
from onnx.external_data_helper import load_external_data_for_model, _get_all_tensors
import numpy as np
onnx_model1 = onnx.load("unet-model.onnx", load_external_data=True)
onnx_model2 = onnx.load("lora.lora")
lora_state_dict = {}
for t in _get_all_tensors(onnx_model2):
lora_state_dict[t.name] = np.frombuffer(t.raw_data, dtype=np.float32)
for t in _get_all_tensors(onnx_model1):
if t.name in lora_state_dict:
np.testing.assert_almost_equal(np.frombuffer(t.raw_data, dtype=np.float32),
lora_state_dict[t.name],
decimal=6)
确认没问题,我们的准备工作也算完成。下面完成C++代码部分。
LoRa加载¶
读取新的LoRa模型,将权重的name和raw_data读取出来,然后创建对应的tensor,最后调用session_options.AddExternalInitializers一起初始化即可。需要注意的是,onnxruntime的CreateTensor操作是浅拷贝,所以在写法上注意局部变量的生存周期。
if(!param._lora_path.empty()){
std::vector<std::string> init_names;
std::vector<Ort::Value> initializer_data;
std::vector<onnx::TensorProto> tensors;
auto allocator = Ort::AllocatorWithDefaultOptions();
for(const auto& lora_path: param._lora_path){
std::ifstream fin(lora_path, std::ios::in | std::ios::binary);
onnx::ModelProto onnx_model;
onnx_model.ParseFromIstream(&fin);
auto graph = onnx_model.graph();
const auto& initializer = graph.initializer();
for(auto& tensor: initializer){
init_names.push_back(tensor.name());
tensors.emplace_back(tensor);
}
fin.close();
}
for(const auto& tensor: tensors){
std::vector<int64_t> shape(tensor.dims_size(), 0);
for(int i = 0; i < tensor.dims_size(); i++){
shape[i] = tensor.dims(i);
}
Ort::Value input_tensor = Ort::Value::CreateTensor(allocator.GetInfo(),
(void *)(tensor.raw_data().c_str()),
tensor.raw_data().length(),
shape.data(),
shape.size(),
ONNXTensorElementDataType(tensor.data_type()));
initializer_data.push_back(std::move(input_tensor));
}
_session_options.AddExternalInitializers(init_names, initializer_data);
_session = std::make_shared<Ort::Session>(_env, param._model_path.c_str(), _session_options);
}
作者在C站找了几个相同结构的LoRa,分别为blindbox、mix4和moxin,测试一下效果

以上代码和模型都已开源,更多详情,敬请登陆github,欢迎Star。
本文总阅读量次