1. 前言¶
之前讲过关于模型剪枝的文章深度学习算法优化系列七 | ICCV 2017的一篇模型剪枝论文,也是2019年众多开源剪枝项目的理论基础 并分析过如何利用这个通道剪枝算法对常见的分类模型如VGG16/ResNet/DenseNet进行剪枝,见深度学习算法优化系列八 | VGG,ResNet,DenseNe模型剪枝代码实战 ,感兴趣的可以去看看。这篇推文主要是介绍一下如何将这个通道剪枝算法应用到YOLOV3上,参考的Github工程地址为:https://github.com/Lam1360/YOLOv3-model-pruning。
2. 项目整体把握¶
这个YOLOV3的剪枝工程是基于U版的YOLOV3的,也就是说我们可以直接将U版训练的YOLOV3模型加载到这里进行剪枝。另外还在工程下的models.py中也实现了对DarkNet模型的加载和保存(无论是官方的DarkNet还是AlexeyAB的DarkNet),对应着models.py里Darknet类的load_darknet_weights和save_darknet_weights函数,这里可以简单看一下:
def load_darknet_weights(self, weights_path):
"""解析和存储在'weights_path'路径的DarkNet模型"""
# 打开权重文件
with open(weights_path, "rb") as f:
header = np.fromfile(f, dtype=np.int32, count=5) # 前5行是头部的标题值
self.header_info = header # 保存权重时需要写入标题值
self.seen = header[3] # 训练的时候每次训练几张图片
weights = np.fromfile(f, dtype=np.float32) # 剩下的是权重
# 确定加载骨干网络的截断节点
cutoff = None
if "darknet53.conv.74" in weights_path:
cutoff = 75
ptr = 0
# 遍历整个模型(Pytorch下的)
for i, (module_def, module) in enumerate(zip(self.module_defs, self.module_list)):
if i == cutoff:
break
if module_def["type"] == "convolutional":
conv_layer = module[0]
if module_def["batch_normalize"]:
# Load BN bias, weights, running mean and running variance
bn_layer = module[1]
num_b = bn_layer.bias.numel() # Number of biases
# Bias
bn_b = torch.from_numpy(weights[ptr : ptr + num_b]).view_as(bn_layer.bias)
bn_layer.bias.data.copy_(bn_b)
ptr += num_b
# Weight
bn_w = torch.from_numpy(weights[ptr : ptr + num_b]).view_as(bn_layer.weight)
bn_layer.weight.data.copy_(bn_w)
ptr += num_b
# Running Mean
bn_rm = torch.from_numpy(weights[ptr : ptr + num_b]).view_as(bn_layer.running_mean)
bn_layer.running_mean.data.copy_(bn_rm)
ptr += num_b
# Running Var
bn_rv = torch.from_numpy(weights[ptr : ptr + num_b]).view_as(bn_layer.running_var)
bn_layer.running_var.data.copy_(bn_rv)
ptr += num_b
# Load conv. weights
num_w = conv_layer.weight.numel()
conv_w = torch.from_numpy(weights[ptr: ptr + num_w]).view_as(conv_layer.weight)
conv_layer.weight.data.copy_(conv_w)
ptr += num_w
else:
# 对于yolov3.weights,不带bn的卷积层就是YOLO前的卷积层
if "yolov3.weights" in weights_path:
num_b = 255
ptr += num_b
num_w = int(self.module_defs[i-1]["filters"]) * 255
ptr += num_w
else:
# Load conv. bias
num_b = conv_layer.bias.numel()
conv_b = torch.from_numpy(weights[ptr : ptr + num_b]).view_as(conv_layer.bias)
conv_layer.bias.data.copy_(conv_b)
ptr += num_b
# Load conv. weights
num_w = conv_layer.weight.numel()
conv_w = torch.from_numpy(weights[ptr : ptr + num_w]).view_as(conv_layer.weight)
conv_layer.weight.data.copy_(conv_w)
ptr += num_w
# 确保指针到达权重的最后一个位置
assert ptr == len(weights)
# 保存DarkNet类型权重(*.weights)
def save_darknet_weights(self, path, cutoff=-1):
"""
@:param path - 新的权重的路径
@:param cutoff - 保存0到cutoff层之间的所有层权重(cutoff=-1代表所有层全部保留)
"""
fp = open(path, "wb")
self.header_info[3] = self.seen
self.header_info.tofile(fp)
# Iterate through layers
for i, (module_def, module) in enumerate(zip(self.module_defs[:cutoff], self.module_list[:cutoff])):
if module_def["type"] == "convolutional":
conv_layer = module[0]
# If batch norm, load bn first
if module_def["batch_normalize"]:
bn_layer = module[1]
bn_layer.bias.data.cpu().numpy().tofile(fp)
bn_layer.weight.data.cpu().numpy().tofile(fp)
bn_layer.running_mean.data.cpu().numpy().tofile(fp)
bn_layer.running_var.data.cpu().numpy().tofile(fp)
# Load conv bias
else:
conv_layer.bias.data.cpu().numpy().tofile(fp)
# Load conv weights
conv_layer.weight.data.cpu().numpy().tofile(fp)
fp.close()
所以这个工程对我们来说是非常容易上手使用的,特别是关注公众号时间稍长的读者都知道我们针对U版的YOLOV3写了一个非常不错的PDF,地址如下:从零开始学习YOLOv3教程资源分享 。
切回正题,我们现在可以方便的加载预训练模型了,既可以是BackBone也可以是整个YOLOV3模型,那么接下来我们就可以针对这个YOLOV3模型进行稀疏训练。当然也可以不用预训练模型直接从头开始稀疏训练,但这样可能训练时间需要更久一些。注意在训练之前应该先组织好自己的目标检测数据集,这一点在上面的PDF或者作者的README都写的很清楚这里就不再讲了。
2.1 稀疏训练的原理¶
深度学习算法优化系列七 | ICCV 2017的一篇模型剪枝论文,也是2019年众多开源剪枝项目的理论基础 的想法是对于每一个通道都引入一个缩放因子\gamma,然后和通道的输出相乘。接着联合训练网络权重和这些缩放因子,最后将小缩放因子的通道直接移除,微调剪枝后的网络,特别地,目标函数被定义为:
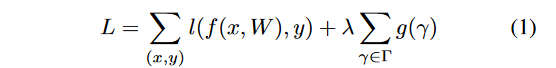
其中(x,y)代表训练数据和标签,W是网络的可训练参数,第一项是CNN的训练损失函数。g(.)是在缩放因子上的乘法项,\lambda是两项的平衡因子。论文的实验过程中选择g(s)=|s|,即L1正则化,这也被广泛的应用于稀疏化。次梯度下降法作为不平滑(不可导)的L1惩罚项的优化方法,另一个建议是使用平滑的L1正则项取代L1惩罚项,尽量避免在不平滑的点使用次梯度。
这里的缩放因子就是BN层的gamma参数。
在train.py的实现中支持了稀疏训练,其中下面这2行代码即添加了稀疏训练的稀疏系数\lambda,注意\lambda是作用在BN层的缩放系数\gamma上的:
parser.add_argument('--sparsity-regularization', '-sr', dest='sr', action='store_true',
help='train with channel sparsity regularization')
parser.add_argument('--s', type=float, default=0.01, help='scale sparse rate')
而稀疏训练的具体实现就在工程下面的utils/prune_utils.py中,代码如下:
class BNOptimizer():
@staticmethod
def updateBN(sr_flag, module_list, s, prune_idx):
if sr_flag:
for idx in prune_idx:
# Squential(Conv, BN, Lrelu)
bn_module = module_list[idx][1]
bn_module.weight.grad.data.add_(s * torch.sign(bn_module.weight.data)) # L1
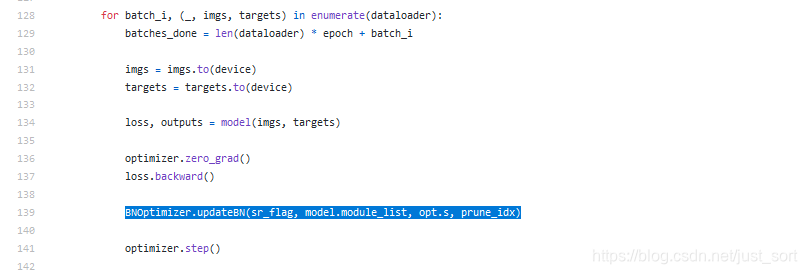
可以看到这里实现了一个BNOptimizer类,并重写了updateBN成员函数,然后在train.py中执行反向传播之后再手动调用这个函数更新一下BN层的梯度,如下:
2.2 YOLOV3模型剪枝¶
在稀疏训练之后我们就可以考虑对YOLOV3模型进行剪枝了,即调用工程下的test_prune.py文件,代码解释如下:
from models import *
from utils.utils import *
import torch
import numpy as np
from copy import deepcopy
from test import evaluate
from terminaltables import AsciiTable #AsciiTable是最简单的表。它使用+,|和-字符来构建边框。
import time
from utils.prune_utils import * #剪枝相关的实现都在这里
class opt():
model_def = "config/yolov3-hand.cfg" # cfg文件,存储网络结构
data_config = "config/oxfordhand.data" # 存储类别,训练验证集路径,类别对应名字等
model = 'checkpoints/yolov3_ckpt.pth' # 稀疏训练之后的模型
#%%
device = torch.device("cuda" if torch.cuda.is_available() else "cpu") #设备
model = Darknet(opt.model_def).to(device)
model.load_state_dict(torch.load(opt.model)) #加载模型
# 解析config文件
data_config = parse_data_config(opt.data_config)
valid_path = data_config["valid"] #获取验证集路径
class_names = load_classes(data_config["names"]) #加载类别对应名字
eval_model = lambda model:evaluate(model, path=valid_path, iou_thres=0.5, conf_thres=0.01,
nms_thres=0.5, img_size=model.img_size, batch_size=8)
obtain_num_parameters = lambda model:sum([param.nelement() for param in model.parameters()])#前向推理的模型
origin_model_metric = eval_model(model)#原始模型的评价指标(还没有剪枝)
origin_nparameters = obtain_num_parameters(model)#原始模型的参数
# 返回CBL组件的id,单独的Conv层的id,以及需要被剪枝的层的id
CBL_idx, Conv_idx, prune_idx= parse_module_defs(model.module_defs)
# 获取CBL组件的BN层的权重,即Gamma参数,我们会根据这个参数来剪枝
bn_weights = gather_bn_weights(model.module_list, prune_idx)
# 按照Gamma参数的大小进行排序,注意[0]返回的是值不是下标
sorted_bn = torch.sort(bn_weights)[0]
# 避免剪掉所有channel的最高阈值(每个BN层的gamma的最大值的最小值即为阈值上限)
highest_thre = []
for idx in prune_idx:
highest_thre.append(model.module_list[idx][1].weight.data.abs().max().item())
highest_thre = min(highest_thre)
# 找到highest_thre对应的下标对应的百分比
percent_limit = (sorted_bn==highest_thre).nonzero().item()/len(bn_weights)
print(f'Threshold should be less than {highest_thre:.4f}.')
print(f'The corresponding prune ratio is {percent_limit:.3f}.')
#开始剪枝
def prune_and_eval(model, sorted_bn, percent=.0):
# 请看https://blog.csdn.net/sodalife/article/details/89461030的解释
model_copy = deepcopy(model)
# 需要剪枝的下标阈值
thre_index = int(len(sorted_bn) * percent)
# 需要剪枝的权重阈值,即<thre那么这个通道就剪枝掉,因为这个通道不那么重要了
thre = sorted_bn[thre_index]
print(f'Channels with Gamma value less than {thre:.4f} are pruned!')
remain_num = 0
for idx in prune_idx:
bn_module = model_copy.module_list[idx][1]
# 返回不需要剪枝的通道下标
mask = obtain_bn_mask(bn_module, thre)
# 记录保留的通道数目
remain_num += int(mask.sum())
# BN层的权重(gamma)乘以这个mask,就相当于剪枝了
bn_module.weight.data.mul_(mask)
# 计算剪枝后的模型的mAP
mAP = eval_model(model_copy)[2].mean()
print(f'Number of channels has been reduced from {len(sorted_bn)} to {remain_num}')
print(f'Prune ratio: {1-remain_num/len(sorted_bn):.3f}')
print(f'mAP of the pruned model is {mAP:.4f}')
# 返回需要剪枝的权重阈值
return thre
# 表示剪枝掉85%的参数
percent = 0.85
# 求需要剪枝的权重阈值
threshold = prune_and_eval(model, sorted_bn, percent)
# 获取每一个BN层通道状态
def obtain_filters_mask(model, thre, CBL_idx, prune_idx):
pruned = 0
total = 0
num_filters = []
filters_mask = []
for idx in CBL_idx:
bn_module = model.module_list[idx][1]
# 如果idx是在剪枝下标的列表中,就执行剪枝
if idx in prune_idx:
mask = obtain_bn_mask(bn_module, thre).cpu().numpy()
# 保留的通道数
remain = int(mask.sum())
# 剪掉的通道数
pruned = pruned + mask.shape[0] - remain
if remain == 0:
print("Channels would be all pruned!")
raise Exception
print(f'layer index: {idx:>3d} \t total channel: {mask.shape[0]:>4d} \t '
f'remaining channel: {remain:>4d}')
else:
# 不用剪枝就全部保留
mask = np.ones(bn_module.weight.data.shape)
remain = mask.shape[0]
total += mask.shape[0]
num_filters.append(remain)
filters_mask.append(mask.copy())
prune_ratio = pruned / total
print(f'Prune channels: {pruned}\tPrune ratio: {prune_ratio:.3f}')
# 输出每层保留的通道数列表和每一个需要剪枝的BN层的保留通道数状态
return num_filters, filters_mask
# 调用上面的函数
num_filters, filters_mask = obtain_filters_mask(model, threshold, CBL_idx, prune_idx)
#映射成一个字典,idx->mask
CBLidx2mask = {idx: mask for idx, mask in zip(CBL_idx, filters_mask)}
# 获得剪枝后的模型
pruned_model = prune_model_keep_size(model, prune_idx, CBL_idx, CBLidx2mask)
# 对剪枝后的模型进行评价
eval_model(pruned_model)
# 拷贝一份原始模型的参数
compact_module_defs = deepcopy(model.module_defs)
# 遍历需要剪枝的CBL模块,将通道数设置为剪枝后的通道数
for idx, num in zip(CBL_idx, num_filters):
assert compact_module_defs[idx]['type'] == 'convolutional'
compact_module_defs[idx]['filters'] = str(num)
#compact_model是剪枝之后的网络的真实结构(注意上面的剪枝网络只是把那些需要剪枝的卷积层/BN层/激活层通道的权重置0了,并没有保存剪枝后的网络)
compact_model = Darknet([model.hyperparams.copy()] + compact_module_defs).to(device)
# obtain_num_parameters = lambda model:sum([param.nelement() for param in model.parameters()])
# 计算参数量,MFLOPs
compact_nparameters = obtain_num_parameters(compact_model)
# 为剪枝后的真实网络结构重新复制权重参数
init_weights_from_loose_model(compact_model, pruned_model, CBL_idx, Conv_idx, CBLidx2mask)
# 随机初始化一个输入
random_input = torch.rand((1, 3, model.img_size, model.img_size)).to(device)
# 获取模型的推理时间
def obtain_avg_forward_time(input, model, repeat=200):
model.eval()
start = time.time()
with torch.no_grad():
for i in range(repeat):
output = model(input)
avg_infer_time = (time.time() - start) / repeat
return avg_infer_time, output
# 分别获取原始模型和剪枝后的模型的推理时间和输出
pruned_forward_time, pruned_output = obtain_avg_forward_time(random_input, pruned_model)
compact_forward_time, compact_output = obtain_avg_forward_time(random_input, compact_model)
# 计算原始模型推理结果和剪枝后的模型的推理结果,如果差距比较大说明哪里错了
diff = (pruned_output-compact_output).abs().gt(0.001).sum().item()
if diff > 0:
print('Something wrong with the pruned model!')
#%%
# 在测试集上测试剪枝后的模型, 并统计模型的参数数量
compact_model_metric = eval_model(compact_model)
#%%
# 比较剪枝前后参数数量的变化、指标性能的变化
metric_table = [
["Metric", "Before", "After"],
["mAP", f'{origin_model_metric[2].mean():.6f}', f'{compact_model_metric[2].mean():.6f}'],
["Parameters", f"{origin_nparameters}", f"{compact_nparameters}"],
["Inference", f'{pruned_forward_time:.4f}', f'{compact_forward_time:.4f}']
]
print(AsciiTable(metric_table).table)
#%%
# 生成剪枝后的cfg文件并保存模型
pruned_cfg_name = opt.model_def.replace('/', f'/prune_{percent}_')
pruned_cfg_file = write_cfg(pruned_cfg_name, [model.hyperparams.copy()] + compact_module_defs)
print(f'Config file has been saved: {pruned_cfg_file}')
compact_model_name = opt.model.replace('/', f'/prune_{percent}_')
torch.save(compact_model.state_dict(), compact_model_name)
print(f'Compact model has been saved: {compact_model_name}')
然后我们针对utils/prune_utils.py里面的一些核心函数再解析一下,首先parse_module_defs这个函数:
def parse_module_defs(module_defs):
CBL_idx = []#Conv+BN+ReLU
Conv_idx = []#Conv
for i, module_def in enumerate(module_defs):
if module_def['type'] == 'convolutional':
if module_def['batch_normalize'] == '1':
CBL_idx.append(i)
else:
Conv_idx.append(i)
ignore_idx = set()#哪些层不需要剪枝
for i, module_def in enumerate(module_defs):
if module_def['type'] == 'shortcut':
ignore_idx.add(i-1)
identity_idx = (i + int(module_def['from']))
if module_defs[identity_idx]['type'] == 'convolutional':
ignore_idx.add(identity_idx)
elif module_defs[identity_idx]['type'] == 'shortcut':
ignore_idx.add(identity_idx - 1)
ignore_idx.add(84)
ignore_idx.add(96)
prune_idx = [idx for idx in CBL_idx if idx not in ignore_idx]
# 返回CBL组件的id,单独的Conv层的id,以及需要被剪枝的层的id
return CBL_idx, Conv_idx, prune_idx
接下来是gather_bn_weights函数:
def gather_bn_weights(module_list, prune_idx):
size_list = [module_list[idx][1].weight.data.shape[0] for idx in prune_idx]
bn_weights = torch.zeros(sum(size_list))
index = 0
for idx, size in zip(prune_idx, size_list):
bn_weights[index:(index + size)] = module_list[idx][1].weight.data.abs().clone()
index += size
# 获取CBL组件的BN层的权重,即Gamma参数,我们会根据这个参数来剪枝
return bn_weights
再看下obtain_bn_mask函数,这个函数返回是否需要剪枝的通道状态:
def obtain_bn_mask(bn_module, thre):
thre = thre.cuda()
# ge(a, b)相当于 a>= b
mask = bn_module.weight.data.abs().ge(thre).float()
# 返回通道是否需要剪枝的通道状态
return mask
还有prune_model_keep_size函数,这个函数将原始模型利用我们刚获得的每个CBL模块的通道保留状态值对每个层的权重进行更新,包括卷积层,BN层和LeakyReLU层。需要注意的是上面的prune_and_eval函数只是更新了BN层剪枝后的权重,没有更新卷积层的权重和LeakyReLU层的权重,代码实现如下:
def prune_model_keep_size(model, prune_idx, CBL_idx, CBLidx2mask):
# 先拷贝一份原始的模型参数
pruned_model = deepcopy(model)
# 对需要剪枝的层分别处理
for idx in prune_idx:
# 需要保留的通道
mask = torch.from_numpy(CBLidx2mask[idx]).cuda()
# 获取BN层的gamma参数,即BN层的权重
bn_module = pruned_model.module_list[idx][1]
bn_module.weight.data.mul_(mask)
# 获取保留下来的通道产生的激活值,注意是每个通道分别获取的
activation = F.leaky_relu((1 - mask) * bn_module.bias.data, 0.1)
# 两个上采样层前的卷积层
next_idx_list = [idx + 1]
if idx == 79:
next_idx_list.append(84)
elif idx == 91:
next_idx_list.append(96)
# 对下一层进行处理
for next_idx in next_idx_list:
# 当前层的BN剪枝之后会对下一个卷积层造成影响
next_conv = pruned_model.module_list[next_idx][0]
# dim=(2,3)即在(w,h)维度上进行求和,因为是通道剪枝,一个通道对应着(w,h)这个矩形
conv_sum = next_conv.weight.data.sum(dim=(2, 3))
# 将卷积层的权重和激活值想乘获得剪枝后的每个通道的偏执,以更新下一个BN层或者下一个带偏执的卷积层的偏执(因为单独的卷积层是不会被剪枝的,所以只对偏执有影响)
offset = conv_sum.matmul(activation.reshape(-1, 1)).reshape(-1)
if next_idx in CBL_idx:
next_bn = pruned_model.module_list[next_idx][1]
next_bn.running_mean.data.sub_(offset)
else:
next_conv.bias.data.add_(offset)
bn_module.bias.data.mul_(mask)
# 返回剪枝后的模型
return pruned_model
最后就是本文最核心的代码部分了,在上面的test_prune.py中代码段如下:
# 拷贝一份原始模型的参数
compact_module_defs = deepcopy(model.module_defs)
# 遍历需要剪枝的CBL模块,将通道数设置为剪枝后的通道数
for idx, num in zip(CBL_idx, num_filters):
assert compact_module_defs[idx]['type'] == 'convolutional'
compact_module_defs[idx]['filters'] = str(num)
#compact_model是剪枝之后的网络的真实结构(注意上面的剪枝网络只是把那些需要剪枝的卷积层/BN层/激活层通道的权重置0了,并没有保存剪枝后的网络)
compact_model = Darknet([model.hyperparams.copy()] + compact_module_defs).to(device)
# obtain_num_parameters = lambda model:sum([param.nelement() for param in model.parameters()])
# 计算参数量,MFLOPs
compact_nparameters = obtain_num_parameters(compact_model)
# 为剪枝后的真实网络结构重新复制权重参数
init_weights_from_loose_model(compact_model, pruned_model, CBL_idx, Conv_idx, CBLidx2mask)
可以看到获得剪枝后的网络结构不难,要给这个剪枝后的网络结构重新拷贝一份参数看起来麻烦一些,我们一起来看看这个init_weights_from_loose_model函数,代码如下:
def init_weights_from_loose_model(compact_model, loose_model, CBL_idx, Conv_idx, CBLidx2mask):
for idx in CBL_idx:
compact_CBL = compact_model.module_list[idx]
loose_CBL = loose_model.module_list[idx]
# np.argwhere返回非0元素的索引,X[:,0]是numpy中数组的一种写法,表示对一个二维数组,取该二维数组第一维中的所有数据,第二维中取第0个数据
out_channel_idx = np.argwhere(CBLidx2mask[idx])[:, 0].tolist()
# 获取剪枝后的模型当前BN层的权重
compact_bn, loose_bn = compact_CBL[1], loose_CBL[1]
compact_bn.weight.data = loose_bn.weight.data[out_channel_idx].clone()
compact_bn.bias.data = loose_bn.bias.data[out_channel_idx].clone()
compact_bn.running_mean.data = loose_bn.running_mean.data[out_channel_idx].clone()
compact_bn.running_var.data = loose_bn.running_var.data[out_channel_idx].clone()
# 获取剪枝后的模型当前卷积层的权重,这和上一个卷积层的剪枝情况有关
input_mask = get_input_mask(loose_model.module_defs, idx, CBLidx2mask)
in_channel_idx = np.argwhere(input_mask)[:, 0].tolist()
compact_conv, loose_conv = compact_CBL[0], loose_CBL[0]
# 拷贝权重到剪枝后的模型中去
tmp = loose_conv.weight.data[:, in_channel_idx, :, :].clone()
compact_conv.weight.data = tmp[out_channel_idx, :, :, :].clone()
for idx in Conv_idx:
compact_conv = compact_model.module_list[idx][0]
loose_conv = loose_model.module_list[idx][0]
# 虽然当前层是不带BN的卷积层,但仍然和上一个层的剪枝情况是相关的
input_mask = get_input_mask(loose_model.module_defs, idx, CBLidx2mask)
in_channel_idx = np.argwhere(input_mask)[:, 0].tolist()
# 拷贝权重到剪枝后的模型中去
compact_conv.weight.data = loose_conv.weight.data[:, in_channel_idx, :, :].clone()
compact_conv.bias.data = loose_conv.bias.data.clone()
其中还有一个关键函数get_input_mask,这是获取网络中当前层的前一层的通道状态,因为在剪枝的时候当前层的通道保留情况是受到它前面是哪些层影响的。
def get_input_mask(module_defs, idx, CBLidx2mask):
# 获取上一层的通道状态
if idx == 0:
return np.ones(3)
if module_defs[idx - 1]['type'] == 'convolutional':
return CBLidx2mask[idx - 1]
elif module_defs[idx - 1]['type'] == 'shortcut':
return CBLidx2mask[idx - 2]
elif module_defs[idx - 1]['type'] == 'route':
route_in_idxs = []
for layer_i in module_defs[idx - 1]['layers'].split(","):
if int(layer_i) < 0:
route_in_idxs.append(idx - 1 + int(layer_i))
else:
route_in_idxs.append(int(layer_i))
if len(route_in_idxs) == 1:
return CBLidx2mask[route_in_idxs[0]]
elif len(route_in_idxs) == 2:
return np.concatenate([CBLidx2mask[in_idx - 1] for in_idx in route_in_idxs])
else:
print("Something wrong with route module!")
raise Exception
到这里剪枝这部分就讲完了,我基本上是一句句理清了整个流程,希望对想接触模型剪枝的同学有所帮助。
2.3 微调¶
在训练完之后如果准确率不够高还需要适当的FineTune一下,因为剪枝之后模型的结构有变化可能会对准确率有些影响,所以可以适当的微调几个Epoch。
3. 结果¶
https://github.com/Lam1360/YOLOv3-model-pruning/blob/master/config/prune_yolov3-hand.cfg展示了在Oxfard人手数据集上对YOLOV3模型进行剪枝后的模型结构,可以看到部分卷积层的通道数大幅度减少。
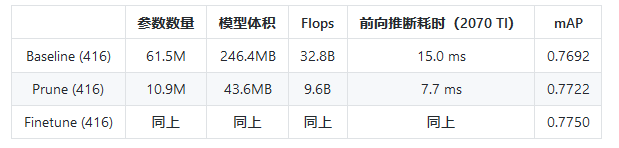
最后,剪枝前后的模型指标对比如下:
4. 结论¶
本文还是展示了如何对YOLOV3模型进行剪枝的原理和详细代码解析,希望可以帮助到正在学习模型剪枝的同学。不过需要强调的是,不是所有的模型通过这个方法都能得到很好的剪枝效果,这和你模型本身的容量以及数据集等等都是相关的,后面我会继续分享更多的模型加速技术,谢谢观看。
5. 参考¶
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。

本文总阅读量次