AiDB: 一个集合了6大推理框架的AI工具箱 | 加速你的模型部署¶
项目地址: https://github.com/TalkUHulk/ai.deploy.box
网页体验: https://www.hulk.show/aidb-webassembly-demo/
PC: https://github.com/TalkUHulk/aidb_qt_demo
Android: https://github.com/TalkUHulk/aidb_android_demo
Go Server: https://github.com/TalkUHulk/aidb_go_demo
Python Server: https://github.com/TalkUHulk/aidb_python_demo
导读¶
本文介绍了一个开源的AI模型部署工具箱--AiDB。该项目使用C++开发,将主流深度学习推理框架抽象成统一接口,包括ONNXRUNTIME、MNN、NCNN、TNN、PaddleLite和OpenVINO,支持Linux、MacOS、Windows、Android、Webassembly等平台。AiDB提供C/C++/Python/Lua等多种API接口。并且提供多种场景的部署实例Demo(Server、PC、Android等)。目前,AiDB集成了数十个开源算法(如Yolo系列、MobileSAM等),约300个模型,并且持续更新。

AiDB具备以下特点:
- 集成了市面上主流的推理框架,并抽象成统一的接口;
- 支持Linux、Windows、MacOS、Android、Webassembly等各种平台部署;
- 支持C/C++、Python、Lua接口;
- 使用友好,支持docker一键安装,开箱即用;
- 丰富的部署实例,包括Android(kotlin)、PC(Qt5)、Server(Go Zeros | Python FastApi)、Web(Webassembly);
- 提供C++/Python/Go/Lua的Colab demo;
- 内置丰富的模型,涵盖检测、关键点、分类、分割、生成等十几种开源算法,300余个模型;
整体架构¶
整个项目的架构如下:
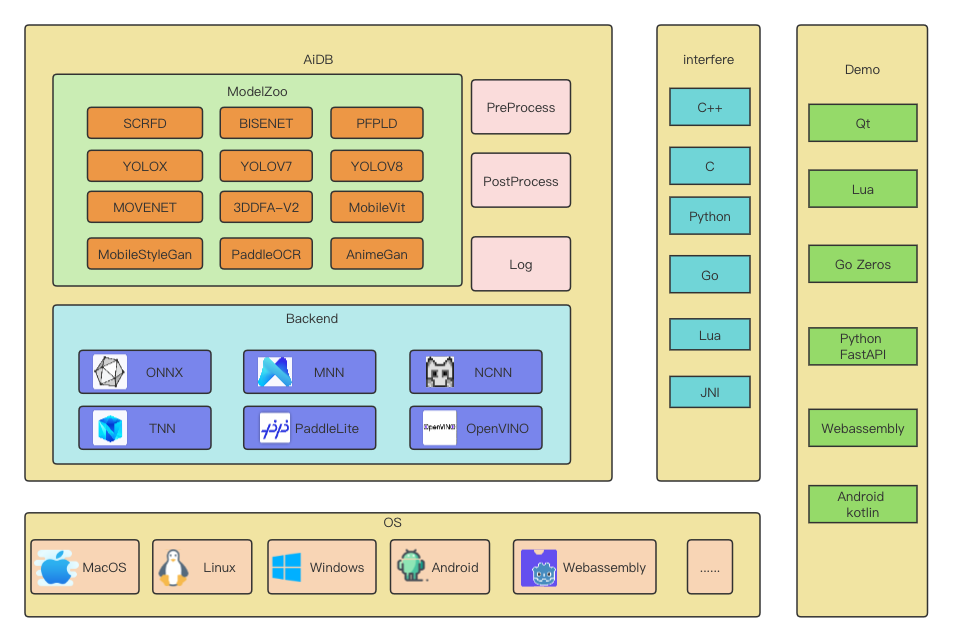
底层封装了六类推理框架,集成前后处理和日志模块,支持各类平台。内置十余种开源算法。提供C/C++、Python、Lua等接口。上层提供各种场景调用实例。
Backend封装¶
主流推理框架的调用接口其实大同小异。主要可以概括为4大步: 1.初始化;2.数据输入;3.预测;4.获取结果。但每个推理框架的具体参数和一些细节又各有不同,如MNN动态输入等。所以为了后续可以动态选择不同的backend,AiDB抽象出一个基类:
class AIDB_PUBLIC Engine {
public:
Engine() = default;
virtual StatusCode init(const Parameter&) = 0;
virtual StatusCode init(const Parameter&, const void *buffer_in1, const void* buffer_in2) = 0;
virtual ~Engine(){};
virtual void forward(const void *frame, int frame_width, int frame_height, int frame_channel, std::vector<std::vector<float>> &outputs, std::vector<std::vector<int>> &outputs_shape) = 0;
virtual void forward(const std::vector<void*> &input, const std::vector<std::vector<int>> &input_shape, std::vector<std::vector<float>> &outputs, std::vector<std::vector<int>> &outputs_shape) = 0;
std::vector<std::string> _output_node_name;
std::vector<std::string> _input_node_name;
std::map<std::string, std::vector<int>> _input_nodes; /*!< 输入节点信息*/
bool _dynamic=false;
std::string _model_name = "default";
std::string _backend_name = "default";
};
后面每类backend继承这个类实现各自的forward和init即可。比如我们要实现MNN backend:
class MNNEngine: public Engine{
public:
MNNEngine();
StatusCode init(const Parameter&) override;
StatusCode init(const Parameter&, const void *buffer_in1, const void* buffer_in2) override;
~MNNEngine() override;
void forward(const void *frame, int frame_width, int frame_height, int frame_channel, std::vector<std::vector<float>> &outputs, std::vector<std::vector<int>> &outputs_shape) override;
void forward(const std::vector<void*> &input, const std::vector<std::vector<int>> &input_shape, std::vector<std::vector<float>> &outputs, std::vector<std::vector<int>> &outputs_shape) override;
private:
void reshape_input(const std::vector<int>&);
std::shared_ptr<MNN::Tensor> get_output_by_name(const char *name);
MNN::Tensor* get_input_tensor(const char *node_name);
MNN::Tensor* get_input_tensor();
private:
std::shared_ptr<MNN::Interpreter> _mnn_net;
MNN::ScheduleConfig _net_cfg;
MNN::Session *_mnn_session;
};
通过如上操作,分别实现onnx、mnn、ncnn、paddlelite和openvino的backend部分,之后我们就可以利用c++多态特性,通过配置文件动态初始化不同的backend:
switch(engineType(model_node["backend"].as<std::string>())){
case ONNX:{
#ifdef ENABLE_ORT
ONNXParameter param = ONNXParameter(model_node);
ptr_engine = new ONNXEngine();
status = ptr_engine->init(param);
#endif
break;
}
case MNN:{
#ifdef ENABLE_MNN
MNNParameter param = MNNParameter(model_node);
ptr_engine = new MNNEngine();
status = ptr_engine->init(param);
#endif
break;
}
case NCNN:{
#ifdef ENABLE_NCNN
NCNNParameter param = NCNNParameter(model_node);
ptr_engine = new NCNNEngine();
status = ptr_engine->init(param);
#endif
break;
}
case TNN:{
#ifdef ENABLE_TNN
TNNParameter param = TNNParameter(model_node);
ptr_engine = new TNNEngine();
status = ptr_engine->init(param);
#endif
}
break;
case OPENVINO:{
#ifdef ENABLE_OPV
OPVParameter param = OPVParameter(model_node);
ptr_engine = new OPVEngine();
status = ptr_engine->init(param);
#endif
}
break;
case PADDLE_LITE:{
#ifdef ENABLE_PPLite
PPLiteParameter param = PPLiteParameter(model_node);
ptr_engine = new PPLiteEngine();
status = ptr_engine->init(param);
#endif
}
break;
default:
break;
}
预处理¶
每个模型的inference代码区别不大,差异主要集中在预处理和后处理阶段。后处理部分根据各个任务的不同(分类、检测等),很难抽象出统一的接口。但预处理可以很简单的实现统一。这里AiDB实现了一个简单的预处理类:
class ImageInput: public AIDBInput{
public:
explicit ImageInput(const YAML::Node& input_mode);
explicit ImageInput(const std::string& input_str);
~ImageInput() override;
void forward(const cv::Mat &image, cv::Mat &blob) override;
void forward(const std::string &image_path, cv::Mat &blob) override;
private:
void Normalize(cv::Mat &image);
void Permute(const cv::Mat &image, cv::Mat &blob);
void Resize(const cv::Mat &image, cv::Mat &resized);
void cvtColor(const cv::Mat &image, cv::Mat &converted);
};
使用yaml配置文件,为每个模型设置设置预处理操作:
BISENET: &bisenet_detail
num_thread: 4
device: "CPU"
PreProcess:
shape: &shape
width: 512
height: 512
channel: 3
batch: 1
keep_ratio: true
mean:
- 123.675
- 116.28
- 103.53
var:
- 58.395
- 57.12
- 57.375
imageformat: "RGB"
inputformat: &format "NCHW"
input_node1: &in_node1
input_name: "input"
format: *format
shape: *shape
input_nodes:
- *in_node1
output_nodes:
- "output"
如何增加模型¶
在对应的config里增加模型配置,比如onnx_config.yaml
SCRFD_2_5G_KPS: &scrfd_2_5g_kps
name: "SCRFD_2.5G_KPS"
model: *mp_scrfd_2_5g
backend: "ONNX"
detail: *scrfd_detail
mp_scrfd_2_5g为模型路径:
SCRFD_2_5G_KPS: &mp_scrfd_2_5g "./models/onnx/scrfd/scrfd_2.5g_kps_simplify"
scrfd_detail为详细的模型相关信息:
SCRFD: &scrfd_detail
encrypt: false
num_thread: 4
device: "CPU"
PreProcess:
shape: &shape
width: 640
height: 640
channel: 3
batch: 1
keep_ratio: true
mean:
- 127.5
- 127.5
- 127.5
var:
- 128.0
- 128.0
- 128.0
border_constant:
- 0.0
- 0.0
- 0.0
imageformat: "RGB"
inputformat: &format "NCHW"
input_node1: &in_node1
input_name: "images"
format: *format
shape: *shape
input_nodes:
- *in_node1
output_nodes:
- "out0"
- "out1"
- "out2"
- "out3"
- "out4"
- "out5"
- "out6"
- "out7"
- "out8"
最后在AIDBZOO里声明下模型:
scrfd_2.5g_kps: *scrfd_2_5g_kps
更多详情,敬请登陆github,欢迎Star。
本文总阅读量次