前言¶
这篇文章是ICCV 2017的一篇模型压缩论文,题目为《 Learning Efficient Convolutional Networks through Network Slimming》。2019年有相当多的关于YOLOv3的剪枝开源工程,他们大多数的原理都来自于这篇论文,这篇论文的思想值得仔细品读。论文原文地址和Pytorch开源代码地址见附录。
基础原理¶
这篇文章不同于之前介绍的那篇深度学习算法优化系列一 | ICLR 2017《Pruning Filters for Efficient ConvNets》 论文直接对卷积层的权重进行剪枝。而是提出了一个针对BN层的剪枝方法,论文利用BN层的权重(也就是BN层的缩放系数)来评估输入通道的重要程度(score),然后对score低于阈值(threshold)的通道进行过滤,之后在连接成剪枝后的网络时已经过滤的通道的神经元就不参与连接。
具体方法¶
论文提供了一种简单的方法来执行通道剪枝。这一节首先讨论channel-wise稀疏化的优势和运到的挑战,然后介绍利用BN的缩放系数来高效的鉴别和剪枝不重要的通道。
channel-wise稀疏化¶
稀疏化可以在不同的级别识别,即weight-level,kernel-level,layer-level。weight-level的稀疏化有最高的灵活性和泛化性能,也可以获得更高的压缩比例,但它通常需要特殊的软硬件加速器才能在稀疏模型上快速推理。而layer-level稀疏化不需要特殊的包做推理加速,但是它灵活性上不如weight-level稀疏化。事实上,只有深度够深(超过50层),移除某些层才会很高效。相比之下,channel-wise稀疏化在灵活性和实现上做了一个平衡,它可以被应用到任何经典的CNN或者全连接层(把每一个神经元看成一个通道),由此得到的网络本质上也是一个瘦的网络,可以获得推理速度的提升。
挑战¶
实现通道稀疏化需要将和一个通道有关联的所有输入和输出的连接都剪掉,但是对于已经预训练好的模型来说,不太可能做到这一点。因此这个对已经预训练好的模型做通道剪枝效率不高,比如对预训练好的ResNet做通道剪枝,在不损伤准确率的情况下,只能减少10%的参数量。"Learning structured sparsity in deep neural networks"这项工作通过将稀疏正则化强加到训练目标函数中,具体来讲就是采用group LASSO来是的所有卷积核的同一个通道在训练时同时趋近于0。然而,这个方法需要额外计算新引入的和所有卷积核有关的梯度项,这加重了网络的训练负担。
缩放因子和稀疏性惩罚¶
论文的想法是对于每一个通道都引入一个缩放因子\gamma,然后和通道的输出相乘。接着联合训练网络权重和这些缩放因子,最后将小缩放因子的通道直接移除,微调剪枝后的网络,特别地,目标函数被定义为:
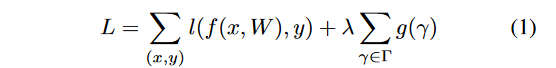
其中(x,y)代表训练数据和标签,W是网络的可训练参数,第一项是CNN的训练损失函数。g(.)是在缩放因子上的乘法项,\lambda是两项的平衡因子。论文的实验过程中选择g(s)=|s|,即L1正则化,这也被广泛的应用于稀疏化。次梯度下降法作为不平滑(不可导)的L1惩罚项的优化方法,另一个建议是使用平滑的L1正则项取代L1惩罚项,尽量避免在不平滑的点使用次梯度。
剪掉一个通道的本质是剪掉所有和这个通道相关的输入和输出连接关系,然后获得一个窄的网络,而不需要借助特殊的计算软硬件。缩放因子的作用是通道选择,因为这里是将缩放因子的正则项和权重损失函数联合优化,网络可以自动鉴别不重要的通道,然后移除掉,几乎不损失精度。

利用BN层的缩放因子¶
BN层已经被大多数现代CNN广泛采用,做为一种标准的方法来加速网络收敛并获得更好的泛化性能。BN归一化激活值的方法给了作者设计一种简单高效的方法的灵感,即与channel-wise缩放因子的结合。尤其是,BN层使用mini-batch的统计特性对内部激活值归一化。z_{in}和z_{out}分别是BN层的输入和输出,B指代现在的minibatch,BN层执行下面的转换:
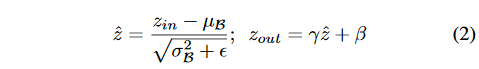
通常的做法就是在卷积层之后插入一个BN层,引入channel-wise的缩放/平移参数。因此,论文直接将BN层的\gamma参数作为我们网络瘦身的缩放因子,这样做的又是在于没有给网络带来额外的开销。事实上,这也可能是我们能够学习到的最有意义的做通道剪枝的缩放因子,因为1)如果我们不使用BN层,而在卷积层之后加入一个缩放层,缩放因子的值对于评估一个通道的重要性没有任何意义,因为卷积层和缩放层就是一种线性变换而已。我们可以通过一方面降低缩放因子的值一方面方法卷积层的权重来使最终的结果保持不变;2)如果我们在BN层之前插入一个缩放层,缩放层的影响将完全被BN层所掩盖;3)如果在BN层之后插入一个缩放层,那么对于每个通道将会有两个连续的缩放因子。
通道剪枝和微调¶
引入了缩放因子正则化后,训练出来的模型许多缩放因子都会趋近于0,如Figure1所示。具体来说,假设经过卷积层之后的特征图维度为h\times w \times c,其中h和w分别代表特征图的长宽,c代表特征图的通道数,将其送入BN层会得到归一化后的特征题意,特征图中的每一个通道都对应一组\gamma和\lambda,前面说的剪掉小的\gamma对应的通道实际上就是直接剪掉这个特征图对应的卷积核。至于什么样的\gamma算小呢?这个取决于我们为整个网络所有层设置的一个全局阈值,它被定义为所有缩放因子值的一个比例,例如我们要剪掉整个网络中70%的通道,那么我们先对缩放因子的绝对值排个序,然后取从小到大排序的缩放因子中70%的位置的缩放因子为阈值。这样我们最终就可以得到一个参数较少,运行时内存小,紧凑的CNN模型了。
Muti-Pass¶
论文提出可以将剪枝方法从单阶段的学习扩展到多阶段,也即是对网络进行多次剪枝,这样可以得到一个压缩程度更高的模型。

跨层连接和预激活结构怎么处理¶
上面的方法可以直接用到大多数比较简单的CNN结构,如AlexNet,VGGNet等。但对于有跨层连接和预激活设计的网络如ResNet、DenseNet等,应该如何使用这个方法呢?对于这些网络,每一层的输出会作为后续多个层的输入,且其BN层是在卷积层之前,在这种情况下,稀疏化是在层的输入末端得到的,一个层选择性的接受所有通道的子集去做下一步的卷积运算。为了在测试时节省参数和运行时间,需要放置一个通道选择层鉴别出重要的通道。这个地方暂时没理解不要紧,我后面会分析源码,看到代码就懂了。
实验¶
论文分别在CIFAR、SVHN、ImageNet、MNIST数据上做了测试,训练和测试一些细节如下:
- 使用SGD算法从头开始训练网络。
- 在CIFAR和SVHN数据集上,minibatch为64,epochs分别为160和20,初始的学习率为0.1,在训练迭代次数的50%和75%时均缩小10倍。
- 在ImageNet和MNIST数据集上,训练的迭代次数epochs分别为60和30,minibatch为256,初始学习率为0.1,在训练迭代次数的1/3和2/3时缩小10倍。
- 权重衰减率为10^{-4},所有的实验中通道缩放因子都初始化为0.5。
- 超参数\lambda依靠网络搜索得到,常见的范围是10^{-3},10^{-4},10^{-5}。对于VGG16选择\lambda为10^{-3},对于ResNet和DenseNet,选择\lambda为10^{-5},对于ImageNet上的VGG-A,选择\lambda为10^{-5}。
- 剪枝之后获得了一个更窄更紧凑的模型,接下来便是微调,在CIFAR、SVHN、MNIST数据集上,微调使用和训练相同的优化设置;在ImageNet数据集上,由于时间的限制,我们仅对剪枝后的VGG-A使用10^{-3}的学习率学习5个epochs。
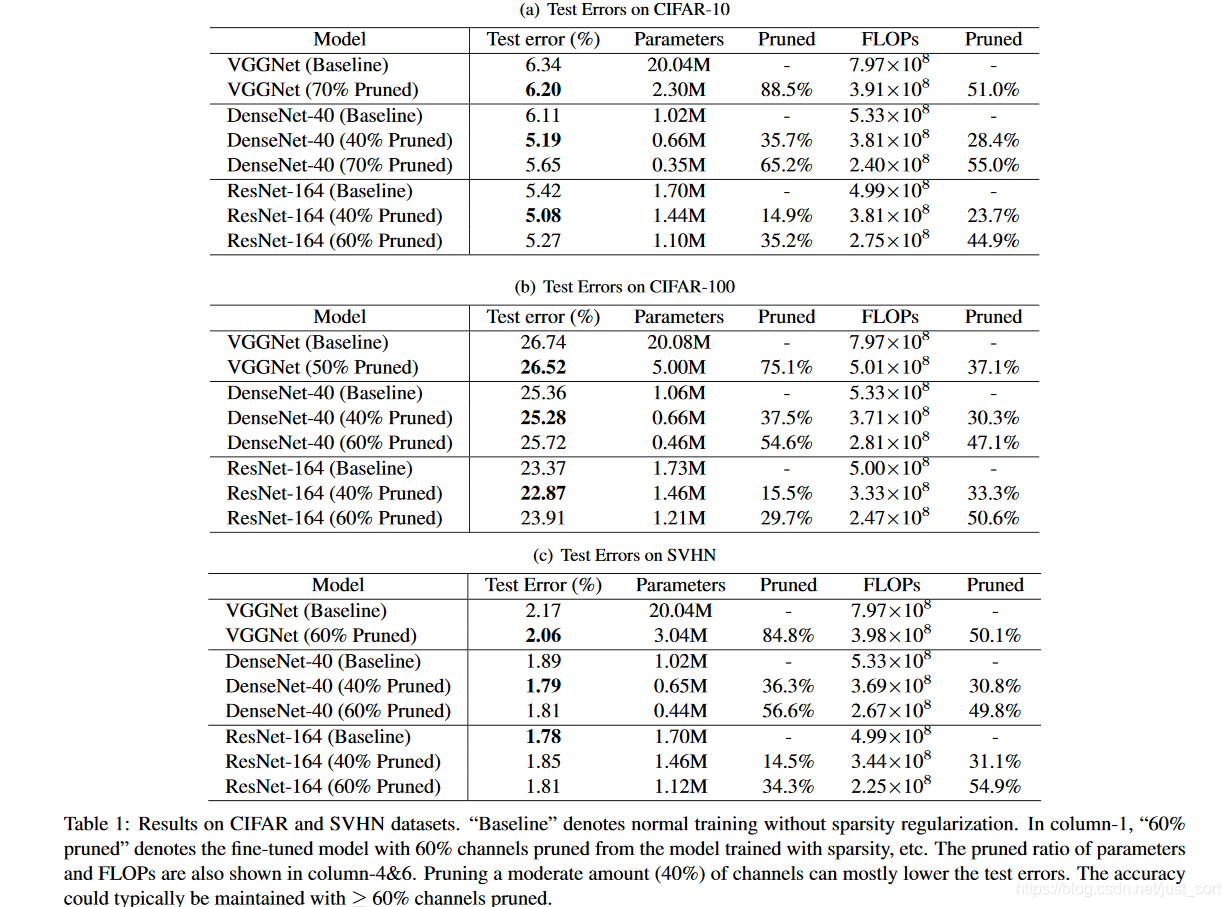
CIFAR和SVHN上的结果¶
参数量和FLOPs¶

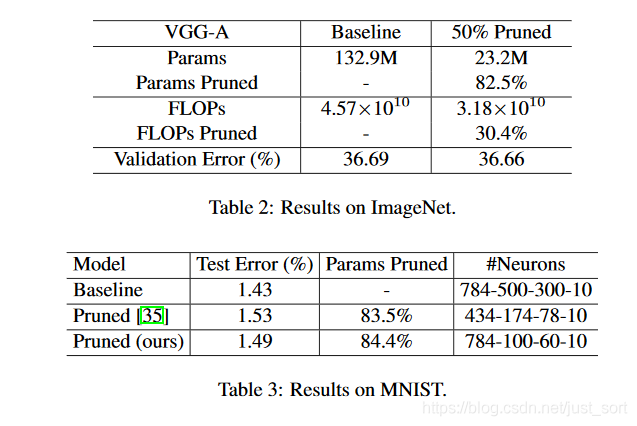
在ImageNet和MNIST上的结果¶
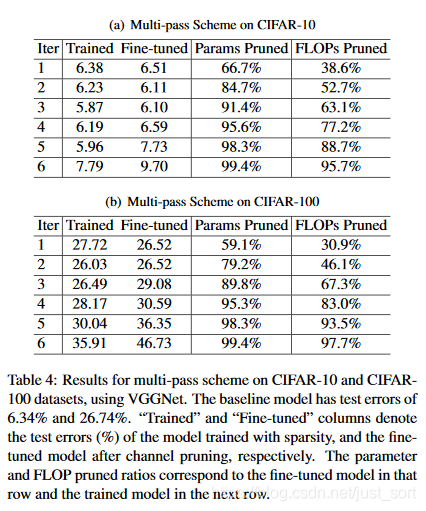
Muti-Pass结果¶
分析¶
在网络剪枝中有2个关键的超参数,第一个是百分比t和稀疏正则项系数\gamma,它们对模型剪枝的影响如下。 - 剪枝百分比的影响:t设置的过小,节省的资源会很有限,设置的过大,剪掉太多的通道会给准确率带来永久性损伤,无法通过后续的微调恢复.Figure5展示了在CIFAR-10上训练的DenseNet-40模型,\gamma=10^{-5}。
 - 通道稀疏正则化的影响。Figure4展示的是不同\gamma取值下,缩放因子值的分布情况。可以看到当\gamma=10^{-4}时,几乎所有的缩放因子值都掉到了一个接近零的区域,这个过程中可以看成是一种类似于网络中间层的选择过程,只有不可忽视的缩放因子对应的通道才会被选择。
- 通道稀疏正则化的影响。Figure4展示的是不同\gamma取值下,缩放因子值的分布情况。可以看到当\gamma=10^{-4}时,几乎所有的缩放因子值都掉到了一个接近零的区域,这个过程中可以看成是一种类似于网络中间层的选择过程,只有不可忽视的缩放因子对应的通道才会被选择。
 然后论文进一步通过热力图对这个过程可视化,Figure6展示了VGGNet的某一层缩放因子的幅值随着迭代次数的变化情况,每个通道开始的权重相同,缩放因子值也相同,随着训练的进行,一些通道的缩放因子会逐渐变大(深色),一些通道的缩放因子会逐渐变小(浅色)。
然后论文进一步通过热力图对这个过程可视化,Figure6展示了VGGNet的某一层缩放因子的幅值随着迭代次数的变化情况,每个通道开始的权重相同,缩放因子值也相同,随着训练的进行,一些通道的缩放因子会逐渐变大(深色),一些通道的缩放因子会逐渐变小(浅色)。
结论¶
这篇文章提出利用BN层的缩放系数来进行剪枝,在多个大型数据集和多个大型网络的测试结果说明了这个方法的有效性。这个方法可以在丝毫不损失精度的条件下将分类中的SOTA网络如VGG16,DenseNet,ResNet剪掉20倍以上的参数,是这两天多数剪枝算法的奠基石。后面会继续更新这个算法的一些源码解析。
附录¶
论文原文:https://arxiv.org/pdf/1708.06519.pdf
Pytorch源码:https://github.com/Eric-mingjie/network-slimming
欢迎关注我的微信公众号GiantPandaCV,期待和你一起交流机器学习,深度学习,图像算法,优化技术,比赛及日常生活等。
本文总阅读量次