前言¶
因为最近在和计算棒打交道,自然存在一个模型转换问题,如果说YOLOv3或者YOLOV3-tiny怎么进一步压缩,我想大多数人都会想到将标准卷积改为深度可分离卷积结构?而当前很多人都是基于DarkNet框架训练目标检测模型,并且github也有开源一个Darknet转到OpenVINO推理框架的工具,地址见附录。而要说明的是,github上的开源工具只是支持了原生的YOLOv3和YOLOV3-tiny模型转到tensorflow的pb模型,然后再由pb模型转换到IR模型执行在神经棒的推理。因此,我写了一个脚本可以将带深度可分离卷积的YOLOv3或YOLOV3-tiny转换到pb模型并转换到IR模型,且测试无误。就奉献一下啦。
项目配置¶
- Tensorflow 1.8.0
- python3
工具搭建¶
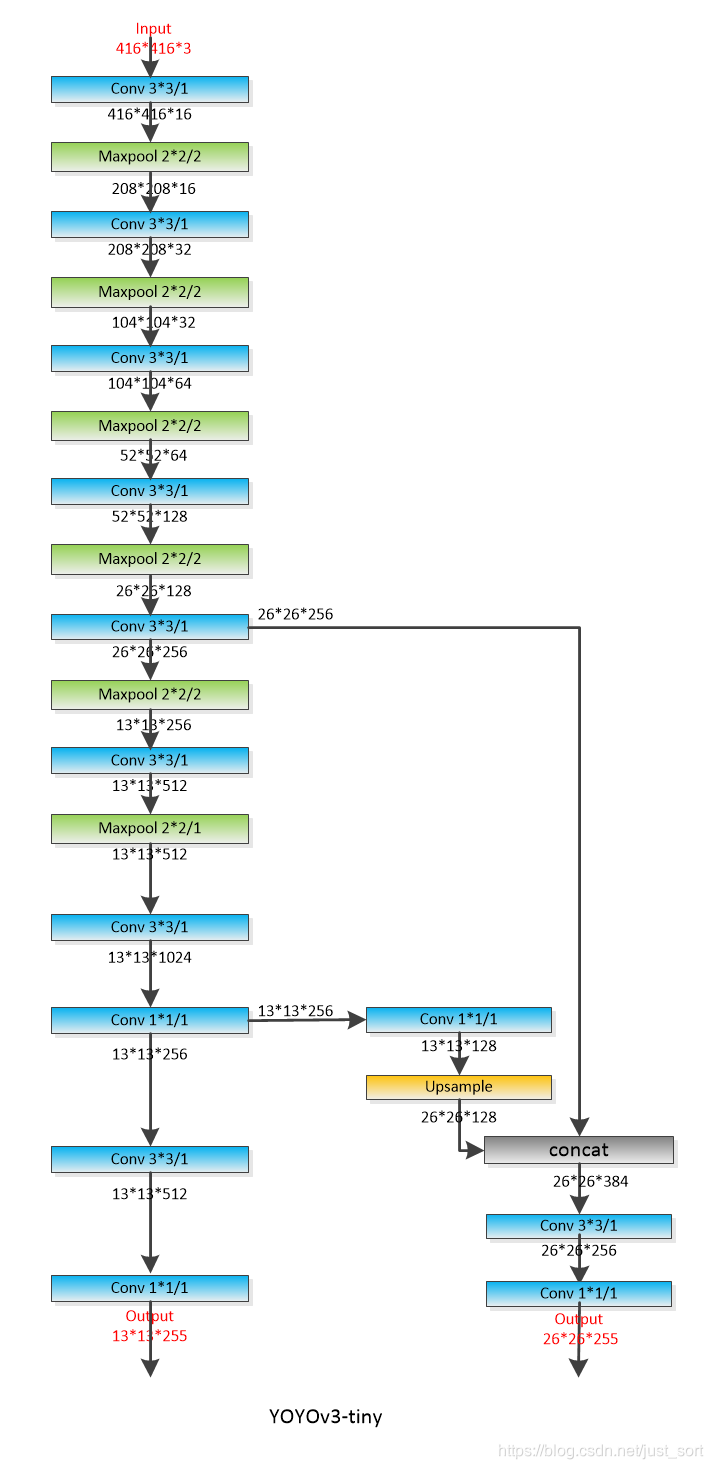
此工具基于github上mystic123的darknet模型转pb模型的工具tensorflow-yolo-v3,具体见附录。我这里以修改一下YOLOV3-tiny里面的有1024个通道的标准卷积为深度可分离卷积为例来介绍。下图是YOLOv3-tiny的网络结构,我们考虑如何把1024个通道的标准卷积改造成深度可分离卷积的形式即可。其他卷积类似操作即可。
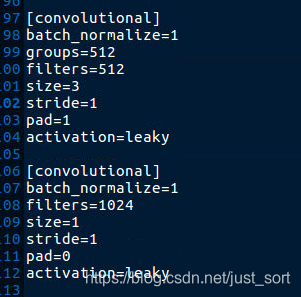
- 步骤一:修改YOLOv3-tiny的cfg文件,
1024个输出通道的卷积层输入通道数512,卷积核尺寸为3x3,因此对应到深度可分离卷积的结构就是[512,512,3,3]的分组卷积核[512,1024,1,1]的点卷积(也是标准的1x1)卷积。所以我们将1024个输出通道的卷积层替换为这两个层即可,这里使用AlexAB版本的Darknet进行训练,链接也在附录,注意要使用groups分组卷积这个参数,需要用cudnn7以上的版本编译DarkNet。然后我们修改cfg文件夹下面的yolov3-tiny.cfg,把其中的1024通道的卷积换成深度可分离卷积,如下图所示。注意是groups而不是group。
 - 步骤二:训练好模型,并使用DarkNet测试一下模型是否表现正常。
- 步骤三:克隆
- 步骤二:训练好模型,并使用DarkNet测试一下模型是否表现正常。
- 步骤三:克隆tensorflow-yolo-v3工程,链接见附录。
- 步骤四:用我的工具转换训练出来的darknet模型到tensorflow的pb模型,这一步骤的具体操作为用下面我提供的脚本替换一下tensorflow-yolo-v3工程中的yolov3-tiny.py即可,注意是全部替换。我的脚本具体代码如下:
# -*- coding: utf-8 -*-
import numpy as np
import tensorflow as tf
from yolo_v3 import _conv2d_fixed_padding, _fixed_padding, _get_size, \
_detection_layer, _upsample
slim = tf.contrib.slim
_BATCH_NORM_DECAY = 0.9
_BATCH_NORM_EPSILON = 1e-05
_LEAKY_RELU = 0.1
_ANCHORS = [(10, 14), (23, 27), (37, 58),
(81, 82), (135, 169), (344, 319)]
def yolo_v3_tiny(inputs, num_classes, is_training=False, data_format='NCHW', reuse=False):
"""
Creates YOLO v3 tiny model.
:param inputs: a 4-D tensor of size [batch_size, height, width, channels].
Dimension batch_size may be undefined. The channel order is RGB.
:param num_classes: number of predicted classes.
:param is_training: whether is training or not.
:param data_format: data format NCHW or NHWC.
:param reuse: whether or not the network and its variables should be reused.
:return:
"""
# it will be needed later on
img_size = inputs.get_shape().as_list()[1:3]
# transpose the inputs to NCHW
if data_format == 'NCHW':
inputs = tf.transpose(inputs, [0, 3, 1, 2])
# normalize values to range [0..1]
inputs = inputs / 255
# set batch norm params
batch_norm_params = {
'decay': _BATCH_NORM_DECAY,
'epsilon': _BATCH_NORM_EPSILON,
'scale': True,
'is_training': is_training,
'fused': None, # Use fused batch norm if possible.
}
with tf.variable_scope('yolo-v3-tiny'):
for i in range(6):
inputs = slim.conv2d(inputs, 16 * pow(2, i), 3, 1, padding='SAME', biases_initializer=None,
activation_fn=lambda x: tf.nn.leaky_relu(x, alpha=_LEAKY_RELU),
normalizer_fn=slim.batch_norm, normalizer_params=batch_norm_params)
if i == 4:
route_1 = inputs
if i == 5:
inputs = slim.max_pool2d(
inputs, [2, 2], stride=1, padding="SAME", scope='pool2')
else:
inputs = slim.max_pool2d(
inputs, [2, 2], scope='pool2')
# inputs = _conv2d_fixed_padding(inputs, 1024, 3)
inputs = slim.separable_conv2d(inputs, num_outputs=None, kernel_size=3, depth_multiplier=1, stride=1, biases_initializer=None,
activation_fn=lambda x: tf.nn.leaky_relu(x, alpha=_LEAKY_RELU),
normalizer_fn=slim.batch_norm, normalizer_params=batch_norm_params,
padding='SAME')
inputs = slim.conv2d(inputs, 1024, 1, 1, biases_initializer=None,
activation_fn=lambda x: tf.nn.leaky_relu(x, alpha=_LEAKY_RELU),
normalizer_fn=slim.batch_norm, normalizer_params=batch_norm_params, padding='VALID')
inputs = slim.conv2d(inputs, 256, 1, 1, padding='SAME', biases_initializer=None,
activation_fn=lambda x: tf.nn.leaky_relu(x, alpha=_LEAKY_RELU),
normalizer_fn=slim.batch_norm, normalizer_params=batch_norm_params)
route_2 = inputs
inputs = slim.conv2d(inputs, 512, 3, 1, padding='SAME', biases_initializer=None,
activation_fn=lambda x: tf.nn.leaky_relu(x, alpha=_LEAKY_RELU),
normalizer_fn=slim.batch_norm, normalizer_params=batch_norm_params)
# inputs = _conv2d_fixed_padding(inputs, 255, 1)
detect_1 = _detection_layer(
inputs, num_classes, _ANCHORS[3:6], img_size, data_format)
detect_1 = tf.identity(detect_1, name='detect_1')
inputs = slim.conv2d(route_2, 128, 1, 1, padding='SAME', biases_initializer=None,
activation_fn=lambda x: tf.nn.leaky_relu(x, alpha=_LEAKY_RELU),
normalizer_fn=slim.batch_norm, normalizer_params=batch_norm_params)
upsample_size = route_1.get_shape().as_list()
inputs = _upsample(inputs, upsample_size, data_format)
inputs = tf.concat([inputs, route_1],
axis=1 if data_format == 'NCHW' else 3)
inputs = slim.conv2d(inputs, 256, 3, 1, padding='SAME', biases_initializer=None,
activation_fn=lambda x: tf.nn.leaky_relu(x, alpha=_LEAKY_RELU),
normalizer_fn=slim.batch_norm, normalizer_params=batch_norm_params)
# inputs = _conv2d_fixed_padding(inputs, 255, 1)
detect_2 = _detection_layer(
inputs, num_classes, _ANCHORS[0:3], img_size, data_format)
detect_2 = tf.identity(detect_2, name='detect_2')
detections = tf.concat([detect_1, detect_2], axis=1)
detections = tf.identity(detections, name='detections')
return detections
可以看到我仍然使用了tensorflow的slim模块搭建整个框架,和原始的yolov3-tiny的区别就在:
# inputs = _conv2d_fixed_padding(inputs, 1024, 3)
inputs = slim.separable_conv2d(inputs, num_outputs=None, kernel_size=3, depth_multiplier=1, stride=1, biases_initializer=None,
activation_fn=lambda x: tf.nn.leaky_relu(x, alpha=_LEAKY_RELU),
normalizer_fn=slim.batch_norm, normalizer_params=batch_norm_params,
padding='SAME')
inputs = slim.conv2d(inputs, 1024, 1, 1, biases_initializer=None,
activation_fn=lambda x: tf.nn.leaky_relu(x, alpha=_LEAKY_RELU),
normalizer_fn=slim.batch_norm, normalizer_params=batch_norm_params, padding='VALID')
需要进一步注意的是slim.separable_conv2d深度可分离卷积的参数传递方式,我们来看一下这个函数的参数列表:
def separable_convolution2d(
inputs,
num_outputs,
kernel_size,
depth_multiplier=1,
stride=1,
padding='SAME',
data_format=DATA_FORMAT_NHWC,
rate=1,
activation_fn=nn.relu,
normalizer_fn=None,
normalizer_params=None,
weights_initializer=initializers.xavier_initializer(),
pointwise_initializer=None,
weights_regularizer=None,
biases_initializer=init_ops.zeros_initializer(),
biases_regularizer=None,
reuse=None,
variables_collections=None,
outputs_collections=None,
trainable=True,
scope=None):
"""一个2维的可分离卷积,可以选择是否增加BN层。
这个操作首先执行逐通道的卷积(每个通道分别执行卷积),创建一个称为depthwise_weights的变量。如果num_outputs
不为空,它将增加一个pointwise的卷积(混合通道间的信息),创建一个称为pointwise_weights的变量。如果
normalizer_fn为空,它将给结果加上一个偏置,并且创建一个为biases的变量,如果不为空,那么归一化函数将被调用。
最后再调用一个激活函数然后得到最终的结果。
Args:
inputs: 一个形状为[batch_size, height, width, channels]的tensor
num_outputs: pointwise 卷积的卷积核个数,如果为空,将跳过pointwise卷积的步骤.
kernel_size: 卷积核的尺寸:[kernel_height, kernel_width],如果两个的值相同,则可以为一个整数。
depth_multiplier: 卷积乘子,即每个输入通道经过卷积后的输出通道数。总共的输出通道数将为:
num_filters_in * depth_multiplier。
stride:卷积步长,[stride_height, stride_width],如果两个值相同的话,为一个整数值。
padding: 填充方式,'VALID' 或者 'SAME'.
data_format:数据格式, `NHWC` (默认) 和 `NCHW`
rate: 空洞卷积的膨胀率:[rate_height, rate_width],如果两个值相同的话,可以为整数值。如果这两个值
任意一个大于1,那么stride的值必须为1.
activation_fn: 激活函数,默认为ReLU。如果设置为None,将跳过。
normalizer_fn: 归一化函数,用来替代biase。如果归一化函数不为空,那么biases_initializer
和biases_regularizer将被忽略。 biases将不会被创建。如果设为None,将不会有归一化。
normalizer_params: 归一化函数的参数。
weights_initializer: depthwise卷积的权重初始化器
pointwise_initializer: pointwise卷积的权重初始化器。如果设为None,将使用weights_initializer。
weights_regularizer: (可选)权重正则化器。
biases_initializer: 偏置初始化器,如果为None,将跳过偏置。
biases_regularizer: (可选)偏置正则化器。
reuse: 网络层和它的变量是否可以被重用,为了重用,网络层的scope必须被提供。
variables_collections: (可选)所有变量的collection列表,或者是一个关键字为变量值为collection的字典。
outputs_collections: 输出被添加的collection.
trainable: 变量是否可以被训练
scope: (可选)变量的命名空间。
Returns:
代表这个操作的输出的一个tensor
- 步骤四:执行下面的模型转换命令,就可以把带深度可分离卷积的
yolov3-tiny模型转到tensorflow的pb模型了。
python3 convert_weights_pb.py \
--class_names coco.names \
--weights_file weights/yolov3-tiny.weights \
--data_format NHWC \
--tiny \
--output_graph pbmodels/frozen_tiny_yolo_v3.pb
- 步骤五:接下来就是把
pb模型转为IR模型,在Intel神经棒上进行推理,这一部分之前的推文已经详细说过了,这里就不再赘述了。想详细了解请看之前的推文,地址如下:YOLOv3-tiny在VS2015上使用Openvino部署 。
测试结果¶
将1024个输出通道的卷积核替换为深度可分离卷积之后,模型从34M压缩到了18M,并且在我的数据集上精度没有显著下降(这个需要自己评判了,因为我的数据自然是没有VOC或者COCO数据集那么复杂的),并且速度也获得了提升。
后记¶
这个工具可以为大家提供了一个花式将Darknet转换为pb模型的一个BaseLine,DarkNet下面的MobileNet-YOLO自然比Caffe的MobileNet-YOLO更容易获得,因为动手改几个groups参数就可以啦。所以我觉得这件事对于使用DarkNet同时玩一下计算棒的同学是有一点意义的,我把我修改后的工程放在github了,地址见附录。
附录¶
原始的darknet转pb模型工程:https://github.com/mystic123/tensorflow-yolo-v3
支持深度可分离卷积的darknet转pb模型工程:https://github.com/BBuf/cv_tools
AlexAB版Darknet:https://github.com/AlexeyAB/darknet
欢迎关注我的微信公众号GiantPandaCV,期待和你一起交流机器学习,深度学习,图像算法,优化技术,比赛及日常生活等。
本文总阅读量次