c++实现yolov5的OpenVINO部署
[GiantPandaCV导语] 本文介绍了一种使用c++实现的,使用OpenVINO部署yolov5的方法。此方法在2020年9月结束的极市开发者榜单中取得后厨老鼠识别赛题第四名。2020年12月,注意到yolov5有了许多变化,对部署流程重新进行了测试,并进行了整理。希望能给需要的朋友一些参考,节省一些踩坑的时间。
模型训练¶
1. 首先获取yolov5工程¶
git clone https://github.com/ultralytics/yolov5.git
本文编辑的时间是2020年12月3日,官方最新的releases是v3.1,在v3.0的版本中,官网有如下的声明
- August 13, 2020**: v3.0 release(
https://github.com/ultralytics/yolov5/releases/tag/v3.0): nn.Hardswish() activations, data autodownload, native AMP.
yolov5训练获得的原始的模型以.pt文件方式存储,要转换为OpenVINO的.xml和.bin的模型存储方式,需要经历两次转换.
两次转换所用到的工具无法同时支持nn.Hardswish()函数的转换,v3.0版本时需要切换到v2.0版本替换掉nn.Hardswish()函数才能够完成两次模型转换,当时要完成模型转换非常的麻烦.
在v3.1版本的yolov5中用于进行pt模型转onnx模型的程序对nn.Hardswish()进行了兼容,模型转换过程大为化简.
2. 训练准备¶
yolov5官方的指南: https://github.com/ultralytics/yolov5/wiki/Train-Custom-Data
描述信息准备¶
在yolov5的文件夹下/yolov5/models/目录下可以找到以下文件
yolov5s.yaml
yolov5m.yaml
yolov5l.yaml
这三个文件分别对应s(小尺寸模型),m(中尺寸模型)和l(大尺寸模型)的结构描述信息
其中为了实现自己的训练常常需要更改以下两个参数
- nc
需要识别的类别数量,yolov5原始的默认类别数量为80
- anchors
通过kmeans等算法根据自己的数据集得出合适的锚框. 这里需要注意:yolov5内部实现了锚框的自动计算训练过程默认使用自适应锚框计算.
经过实际测试,自己通过kmeans算法得到的锚框在特定数据集上能取得更好的性能
在3.执行训练中将提到禁止自动锚框计算的方法.
数据准备¶
参考官方指南的
- Create Labels
- Organize Directories
部分的数据要求
注意标注格式是class x_center y_center width height,其中x_center y_center width height均是根据图像尺寸归一化的0到1之间的数值.
3. 执行训练¶
python ~/src_repo/yolov5/train.py --batch 16 --epochs 10 --data ~/src_repo/rat.yaml --cfg ~/src_repo/yolov5/models/yolov5s.yaml --weights ""
其中
- --data 参数后面需要填充的是训练数据的说明文件.其中需要说明训练集,测试集,种类数目和种类名称等信息,具体格式可以参考yolov5/data/coco.yaml.
- --cfg 为在训练准备阶段完成的模型结构描述文件.
- --weights 后面跟预训练模型的路径,如果是""则重新训练一个模型.推荐使用预训练模型继续训练,不使用该参数则默认使用预训练模型.
- --noautoanchor 该参数可选,使用该参数则禁止自适应anchor计算,使用--cfg文件中提供的原始锚框.
模型转换¶
经过训练,模型的原始存储格式为.pt格式,为了实现OpenVINO部署,需要首先转换为.onnx的存储格式,之后再转化为OpenVINO需要的.xml和.bin的存储格式.
1. pt格式转onnx格式¶
这一步的转换主要由yolov5/models/export.py脚本实现.
可以参考yolov5提供的简单教程:https://github.com/ultralytics/yolov5/issues/251
使用该教程中的方法可以获取onnx模型,但直接按照官方方式获取的onnx模型其中存在OpenVINO模型转换中不支持的运算,因此,使用该脚本之前需要进行一些更改:
- opset_version
在/yolov5/models/export.py中
torch.onnx.export(model, img, f, verbose=False, opset_version=12, input_names=['images'],
output_names=['classes', 'boxes'] if y is None else ['output'])
opset_version=12,将导致后面的OpenVINO模型装换时遇到未支持的运算 因此设置为opset_version=10.
- Detect layer export
model.model[-1].export = True
设置为True则Detect层(包含nms,锚框计算等)不会输出到模型中.
设置为False包含Detect层的模型无法通过onnx到OpenVINO格式模型的转换.
需要执行如下指令:
python ./models/export.py --weight .pt文件路径 --img 640 --batch 1
需要注意的是在填入的.pt文件路径不存在时,该程序会自动下载官方预训练的模型作为转换的原始模型,转换完成则获得onnx格式的模型.
转换完成后可以使用Netron:https://github.com/lutzroeder/netron.git 进行可视化.对于陌生的模型,该可视化工具对模型结构的认识有很大的帮助.
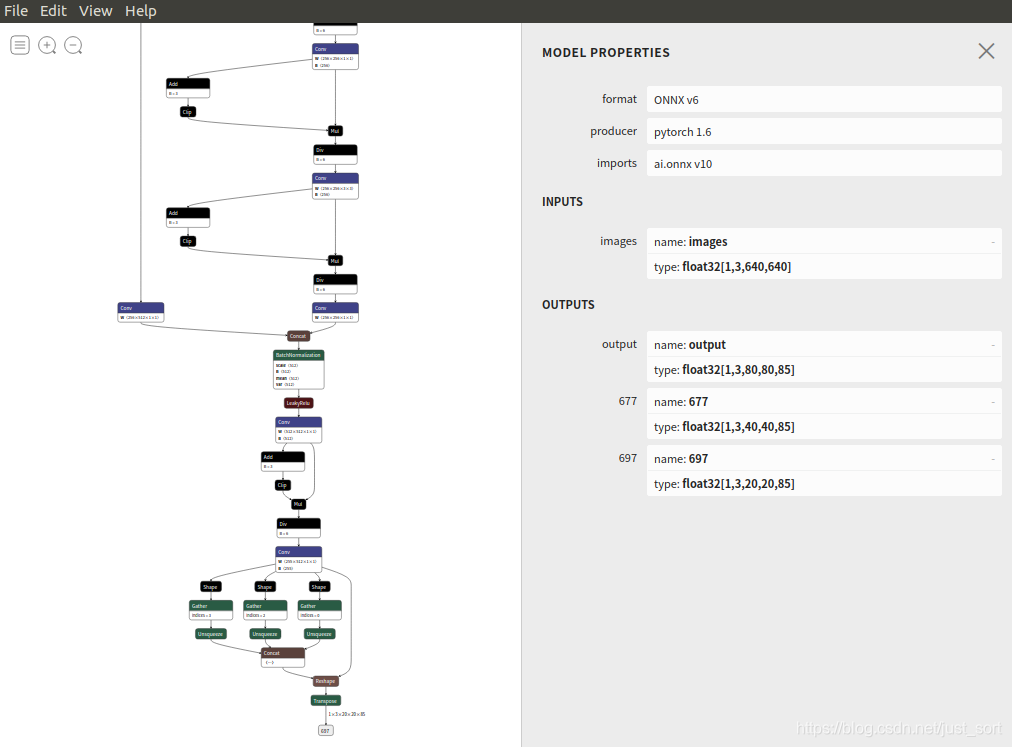
2. onnx格式转换OpenVINO的xml和bin格式¶
OpenVINO是一个功能丰富的跨平台边缘加速工具箱,本文用到了其中的模型优化工具和推理引擎两部分内容.
OpenVINO的安装配置可以参考https://docs.openvinotoolkit.org/2019_R2/_docs_install_guides_installing_openvino_linux.html ,本文的所有实现基于2020.4版本,为确保可用,建议下载2020.4版本的OpenVINO.
安装完成后在~/.bashrc文件中添加如下内容,用于在终端启动时配置环境变量.
source /opt/intel/openvino/bin/setupvars.sh
source /opt/intel/openvino/opencv/setupvars.sh
安装完成后运行如下脚本实现onnx模型到xml bin模型的转换.
python /opt/intel/openvino/deployment_tools/model_optimizer/mo_onnx.py --input_model .onnx文件路径 --output_dir 期望模型输出的路径
运行成功之后会获得.xml和.bin文件,xml和bin是OpenVINO中的模型存储方式,后续将基于bin和xml文件进行部署.该模型转换工具还有定点化等模型优化功能,有兴趣可以自己试试.
使用OpenVINO进行推理部署¶
OpenVINO除了模型优化工具外,还提供了一套运行时推理引擎.
想使用OpenVINO的模型进行推理部署,有两种方式,第一种方式是使用OpenVINO原生的sdk,另外一种方式是使用支持OpenVINO的opencv(比如OpenVINO自带的opencv)进行部署,本文对原生sdk的部署方式进行介绍.
OpenVINO提供了相对丰富的例程,本文中实现的yolov5的部署参考了/opt/intel/openvino/deployment_tools/inference_engine/demos/object_detection_demo_yolov3_async文件夹中yolov3的实现方式.
1. 推理引擎的初始化¶
首先需要进行推理引擎的初始化,此部分代码封装在detector.cpp的init函数.
主要流程如下:
Core ie;
//读入xml文件,该函数会在xml文件的目录下自动读取相应的bin文件,无需手动指定
auto cnnNetwork = ie.ReadNetwork(_xml_path);
//从模型中获取输入数据的格式信息
InputsDataMap inputInfo(cnnNetwork.getInputsInfo());
InputInfo::Ptr& input = inputInfo.begin()->second;
_input_name = inputInfo.begin()->first;
input->setPrecision(Precision::FP32);
input->getInputData()->setLayout(Layout::NCHW);
ICNNNetwork::InputShapes inputShapes = cnnNetwork.getInputShapes();
SizeVector& inSizeVector = inputShapes.begin()->second;
cnnNetwork.reshape(inputShapes);
//从模型中获取推断结果的格式
_outputinfo = OutputsDataMap(cnnNetwork.getOutputsInfo());
for (auto &output : _outputinfo) {
output.second->setPrecision(Precision::FP32);
}
//获取可执行网络,这里的CPU指的是推断运行的器件,可选的还有"GPU",这里的GPU指的是intel芯片内部的核显
//配置好核显所需的GPU运行环境,使用GPU模式进行的推理速度上有很大提升,这里先拿CPU部署后面会提到GPU环境的配置方式
_network = ie.LoadNetwork(cnnNetwork, "CPU");
2. 数据准备¶
为了适配网络的输入数据格式要求,需要对原始的opencv读取的Mat数据进行预处理.
- resize
最简单的方式是将输入图像直接resize到640*640尺寸,此种方式会造成部分物体失真变形,识别准确率会受到部分影响,简单起见,在demo代码里使用了该方式.
在竞赛代码中,为了追求正确率,图像缩放的时候需要按图像原始比例将图像的长或宽缩放到640.假设长被放大到640,宽按照长的变换比例无法达到640,则在图像的两边填充黑边确保输入图像总尺寸为640*640.竞赛代码中使用了该种缩放方式,需要注意的是如果使用该种缩放方式,在获取结果时需要将结果转换为在原始图像中的坐标.
- 颜色通道转换
鉴于opencv和pytorch的颜色通道差异,opencv是BGR通道,pytorch是RGB,在输入网络之前,需要进行通道转换.
- 推断请求和blob填充
InferRequest::Ptr infer_request = _network.CreateInferRequestPtr();
Blob::Ptr frameBlob = infer_request->GetBlob(_input_name);
InferenceEngine::LockedMemory<void> blobMapped = InferenceEngine::as<InferenceEngine::MemoryBlob>(frameBlob)->wmap();
float* blob_data = blobMapped.as<float*>();
//nchw
for(size_t row =0;row<640;row++){
for(size_t col=0;col<640;col++){
for(size_t ch =0;ch<3;ch++){
//将图像转换为浮点型填入模型
blob_data[img_size*ch + row*640 + col] = float(inframe.at<Vec3b>(row,col)[ch])/255.0f;
}
}
}
3. 推断执行与解析¶
- 推断执行
infer_request->Infer();
- 获取推断结果
从Netron的可视化结果可知
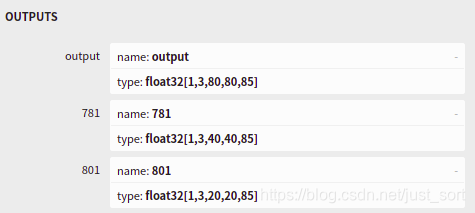
网络只包含到输出三个检测头的部分,三个检测头分别对应80,40,和20的栅格尺寸,因此需要对三种尺寸的检测头输出结果依次解析,具体的解析过程在parse_yolov5函数中进行了实现:
//获取各层结果
vector<Rect> origin_rect; //保存原始的框信息
vector<float> origin_rect_cof; //保存框对应的置信度信息
int s[3] = {80,40,20};
int i=0;
for (auto &output : _outputinfo) {
auto output_name = output.first;
Blob::Ptr blob = infer_request->GetBlob(output_name);
parse_yolov5(blob,s[i],_cof_threshold,origin_rect,origin_rect_cof);
++i;
}
- 对检测头的内容进行解析
这部分主要是使用c++将yolov5代码中的detect层内容重新实现一下,主要代码实现如下:
//注意此处的阈值是框和物体prob乘积的阈值
bool Detector::parse_yolov5(const Blob::Ptr &blob,int net_grid,float cof_threshold,
vector<Rect>& o_rect,vector<float>& o_rect_cof){
vector<int> anchors = get_anchors(net_grid);
LockedMemory<const void> blobMapped = as<MemoryBlob>(blob)->rmap();
const float *output_blob = blobMapped.as<float *>();
//80个类是85,一个类是6,n个类是n+5
//int item_size = 6;
int item_size = 85;
size_t anchor_n = 3;
for(int n=0;n<anchor_n;++n)
for(int i=0;i<net_grid;++i)
for(int j=0;j<net_grid;++j)
{
double box_prob = output_blob[n*net_grid*net_grid*item_size + i*net_grid*item_size + j *item_size+ 4];
box_prob = sigmoid(box_prob);
//框置信度不满足则整体置信度不满足
if(box_prob < cof_threshold)
continue;
//注意此处输出为中心点坐标,需要转化为角点坐标
double x = output_blob[n*net_grid*net_grid*item_size + i*net_grid*item_size + j*item_size + 0];
double y = output_blob[n*net_grid*net_grid*item_size + i*net_grid*item_size + j*item_size + 1];
double w = output_blob[n*net_grid*net_grid*item_size + i*net_grid*item_size + j*item_size + 2];
double h = output_blob[n*net_grid*net_grid*item_size + i*net_grid*item_size + j *item_size+ 3];
double max_prob = 0;
int idx=0;
for(int t=5;t<85;++t){
double tp= output_blob[n*net_grid*net_grid*item_size + i*net_grid*item_size + j *item_size+ t];
tp = sigmoid(tp);
if(tp > max_prob){
max_prob = tp;
idx = t;
}
}
float cof = box_prob * max_prob;
//对于边框置信度小于阈值的边框,不关心其他数值,不进行计算减少计算量
if(cof < cof_threshold)
continue;
x = (sigmoid(x)*2 - 0.5 + j)*640.0f/net_grid;
y = (sigmoid(y)*2 - 0.5 + i)*640.0f/net_grid;
w = pow(sigmoid(w)*2,2) * anchors[n*2];
h = pow(sigmoid(h)*2,2) * anchors[n*2 + 1];
double r_x = x - w/2;
double r_y = y - h/2;
Rect rect = Rect(round(r_x),round(r_y),round(w),round(h));
o_rect.push_back(rect);
o_rect_cof.push_back(cof);
}
if(o_rect.size() == 0) return false;
else return true;
}
这一部分最艰难的是搞清楚输出数据的排列方式,一开始我也试了很多次,最后才得到了正确的输出.
需要注意的一点是,按照输出排列方式读取的数值不是最终我们需要的结果,需要进行一些计算来进行转换,
转换的依据可以参考yolov5/models/yolo.py中forward函数的实现.
注意这里有一个参数cof_threshold,其计算方式是框置信度乘以物品置信度,如果识别效果不佳,则需要对该数值进行调整.
- NMS获取最终结果
经过以上步骤,原始的框信息存储在origin_rect变量中,还需要通过NMS去除同一个物体多余的框.
OpenVNIO自带的opencv提供了NMS的一种实现,因而直接进行调用.
vector<int> final_id;
dnn::NMSBoxes(origin_rect,origin_rect_cof,_cof_threshold,_nms_area_threshold,final_id);
//根据final_id获取最终结果
for(int i=0;i<final_id.size();++i){
Rect resize_rect= origin_rect[final_id[i]];
detected_objects.push_back(Object{
origin_rect_cof[final_id[i]],
"",resize_rect
});
}
其中origin_rect为原始矩形,origin_rect_cof为矩形对应的置信度,_cof_threshold为置信度(框置信度乘以物品置信度)阈值,_nms_area_threshold是重叠百分比多少则算为一个物体的阈值,final_id为目标矩形在origin_rect中的下标.
4. 性能测试¶
计时实现如下:
auto start = chrono::high_resolution_clock::now();
auto end = chrono::high_resolution_clock::now();
std::chrono::duration<double> diff = end - start;
cout<<"use "<<diff.count()<<" s" << endl;
原始的未经优化的CPU运行的yolov5,推理时间在240ms左右,测试平台为intel corei7 6700hq.
检测结果如下:

推理加速¶
- 使用核显GPU进行计算
将
_network = ie.LoadNetwork(cnnNetwork, "CPU");
改为
_network = ie.LoadNetwork(cnnNetwork, "GPU");
如果OpenVINO环境配置设置无误程序应该可以直接运行.
检测环境是否配置无误的方法是运行:
/opt/intel/openvino/deployment_tools/demo中的./demo_security_barrier_camera.sh
若成功运行则cpu环境正常.
./demo_security_barrier_camera.sh -d GPU 运行正常则gpu环境运行正常.
- 使用openmp进行并行化
在推理之外的数据预处理和解析中存在大量循环,这些循环都可以利用openmp进行并行优化.
- 模型优化如定点化为int8类型
在模型转换时通过设置参数可以实现模型的定点化.
git项目使用¶
项目地址:https://github.com/fb029ed/yolov5_cpp_openvino
- demo部分完成了yolov5原始模型的部署
使用方法为依次执行
cd ./demo
mkdir build
cd build
cmake ..
make
./detect_test
- cvmart_competition部分为开发者榜单竞赛的参赛代码,不能直接运行仅供参考
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。

本文总阅读量次