1. 前言¶
今天我将以GoogleNet为例来展示如何在TensorRT中实现细粒度的Profiling并且顺带介绍一下TensorRT的16Bit推理。
2. 关键概念¶
下面来描述几个关键概念。
- FP16。我们知道FP32指的是Full Precise Float 32,而FP16对应的就是Float 16。相比于FP32,FP16更省内存空间和更节省推理时间。
- Half2Mode。这是TensorRT的一种执行模式,在这种模式下图片上相邻区域的Tensor是以16位交叉存储的方式存储的。并且当Batch大于1时,这种存储模式是最快的。这一点的原理可以看:
https://wenku.baidu.com/view/43f5d1d333d4b14e8524687b。 - Profiling 。这是本节的核心内容,Profiling表示测量网络每一层的运行时间,这样可以方便的看出使用了TensorRT和没有使用TensorRT在时间上的差别。
下面的Figure1代表了2D和3D情况下的交叉存储示意图,大家可以看一看:
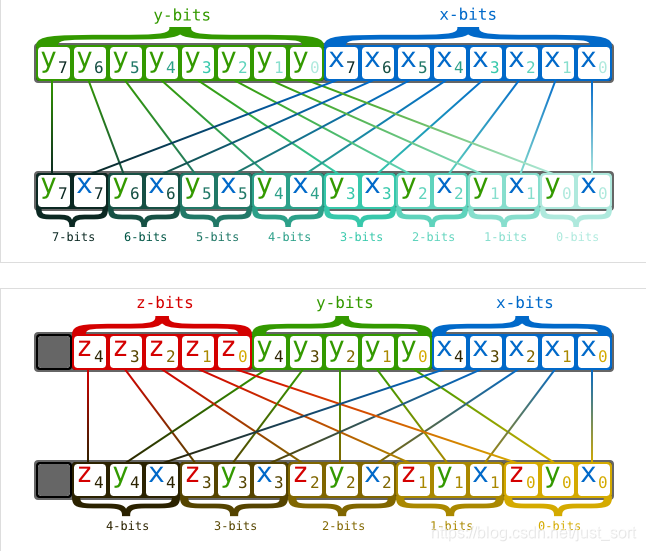
3. 为什么TensorRT能让模型跑的快?¶
这一问题的答案就隐藏下面这张图中:

从图上可以看到,TensorRT主要做了下面几件事,来提升模型的运行速度。 - TensorRT支持FP16和INT8的计算。我们知道深度学习在训练的时候一般是应用32位或者16位数据,TensorRT在推理的时候可以降低模型参数的位宽来进行低精度推理,以达到加速推断的目的。这在后面的文章中是重点内容,笔者经过一周的研究,大概明白了TensorRT INT8量化的一些细节,后面会逐渐和大家一起分享讨论。 - TensorRT对于网络结构进行重构,把一些能够合并的运算合并在了一起,针对GPU的特性做了优化。大家如果了解GPU的话会知道,在GPU上跑的函数叫Kernel,TensorRT是存在Kernel的调用的。在绝大部分框架中,比如一个卷积层、一个偏置层和一个reload层,这三层是需要调用三次cuDNN对应的API,但实际上这三层的实现完全是可以合并到一起的,TensorRT会对一些可以合并网络进行合并;再比如说,目前的网络一方面越来越深,另一方面越来越宽,可能并行做若干个相同大小的卷积,这些卷积计算其实也是可以合并到一起来做的。(加粗的话转载自参考链接1)。 - 然后Concat层是可以去掉的,因为TensorRT完全可以实现直接接到需要的地方。 - Kernel Auto-Tuning:网络模型在推理计算时,是调用GPU的CUDA核进行计算的。TensorRT可以针对不同的算法,不同的网络模型,不同的GPU平台,进行 CUDA核的调整,以保证当前模型在特定平台上以最优性能计算。 - Dynamic Tensor Memory 在每个tensor的使用期间,TensorRT会为其指定显存,避免显存重复申请,减少内存占用和提高重复使用效率。 - 不同的硬件如P4卡还是V100卡甚至是嵌入式设备的卡,TensorRT都会做优化,得到优化后的engine。
下面是一个原始的Inception Block,首先input后会有多个卷积,卷积完后有Bias和ReLU,结束后将结果concat到一起,得到下一个input。我们一起来看一下使用TensorRT后,这个原始的计算图会被优化成了什么样子。
首先,在没有经过优化的时候Inception Block如Figure1所示:
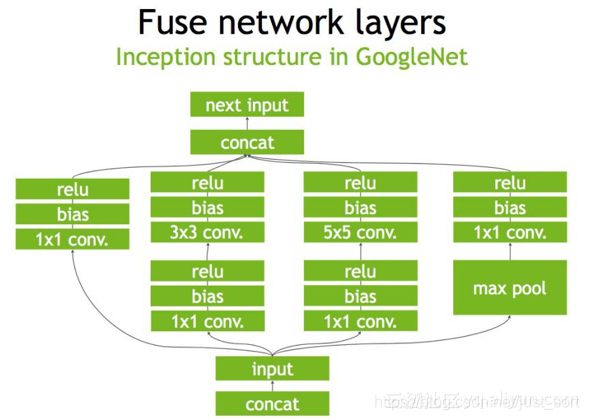
第二步,对于网络结构进行垂直整合,即将目前主流神经网络的conv、BN、Relu三个层融合为了一个层,所谓CBR,合并后就成了Figure2中的结构。
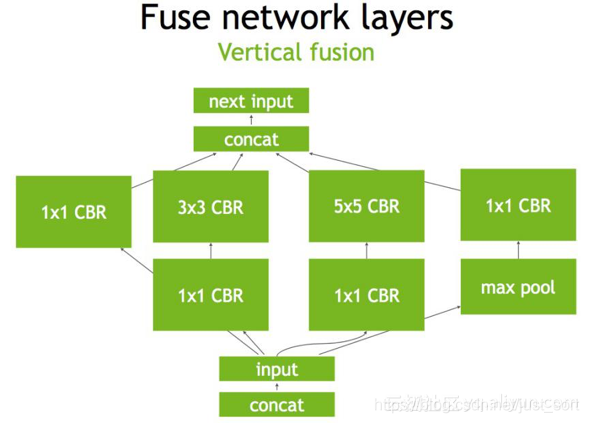
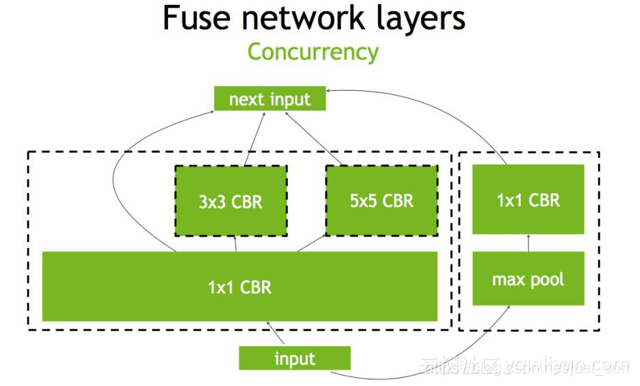
第三步,TensorRT还可以对网络做水平组合,水平组合是指将输入为相同张量和执行相同操作的层融合一起,下面的Figure3即是将三个相连的1\times 1的CBR为一个大的1\times 1的CBR。
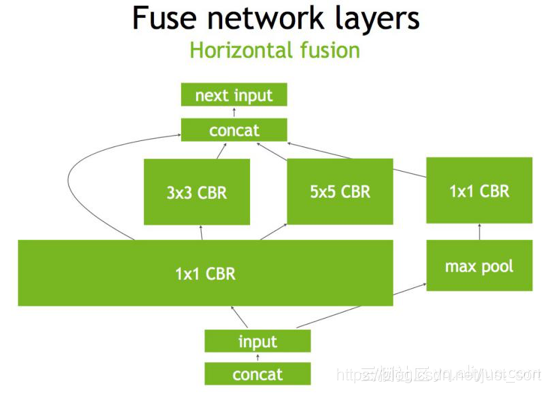
最后,对于concat层,将contact层的输入直接送入下面的操作中,不用单独进行concat后在输入计算,相当于减少了一次传输吞吐,然后就获得了如Figure4所示的最终计算图。
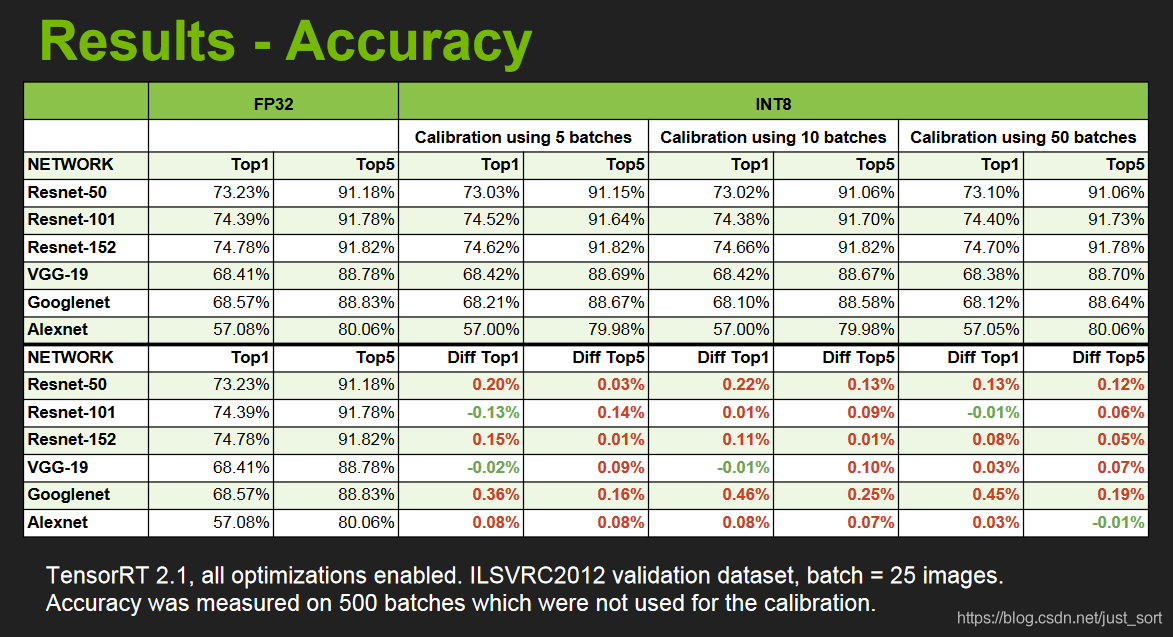
除了计算图和底层优化,最重要的就是低精度推理了,这个后面会细讲的,我们先来看一下使用了INT8低精度模式进行推理的结果展示:包括精度和速度。来自NIVIDA提供的PPT。
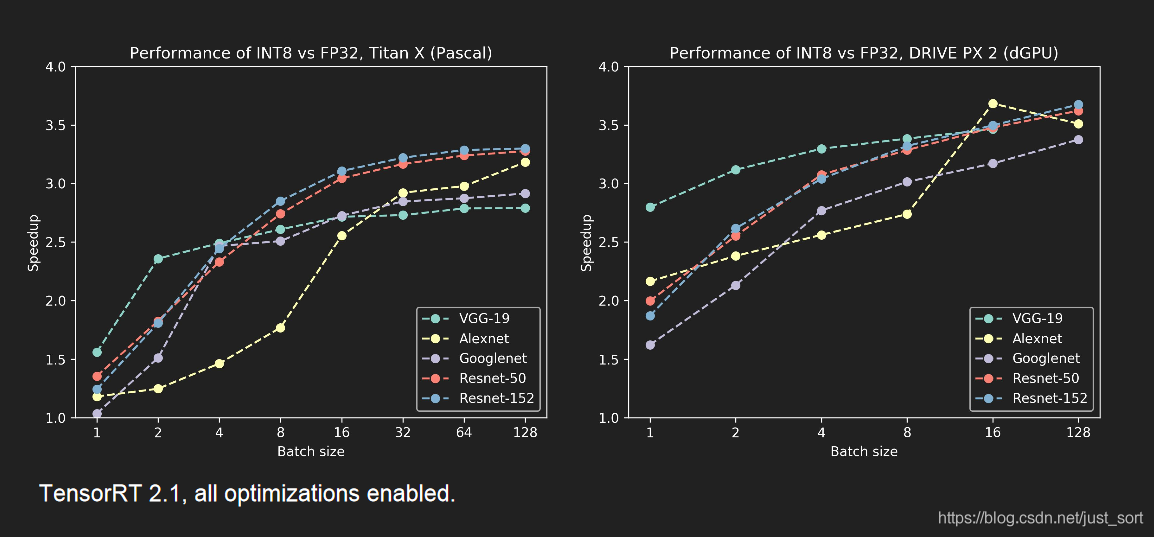
4. 具体做法¶
在TensorRT的samples文件夹下有一个命令行包装工具,叫trtexec,在我的电脑里的路径如下图所示:
trtexec可以用来评测我们的网络模型,具体来说它有以下两个功能:
- 被用来在指定的网络模型中,对随机输入数据进行基准测试。
- 被用来对指定网络模型产生序列化引擎。
基准测试 如果你有一个UFF网络模型文件,ONNX网络模型文件或者Caffe网络模型文件,你可以使用TensorRT的trtexc工具来测试这个网络在推理时的表现。trtexec有许多用于指定输入和输出的选项,用于性能计时的迭代,允许的精度以及其他选项。
序列化引擎生成 如果生成已保存的序列化引擎文件,则可以将其拉入另一个运行推理的应用程序。 例如,你可以使用TensorRT Laboratory(https://github.com/NVIDIA/tensorrt-laboratory)以完全流水线异步方式从多个线程运行具有多个执行上下文的引擎,以测试并行推理性能。 值得注意的是,如果您使用了Caffe prototxt文件而未提供模型,则会生成随机权重。 同样,在INT8模式下,将使用随机权重,这意味着trtexec不提供校准功能。
下例显示了如何加载模型文件及其权重,构建针对batch=16优化的引擎并将其保存到文件中的方法。
Windows下使用的命令如下:
F:\TensorRT-6.0.1.5\bin\trtexec.exe --deploy=F:\TensorRT-6.0.1.5\data\googlenet\googlenet.prototxt --model=F:\TensorRT-6.0.1.5\data\googlenet\googlenet.caffemodel --output=prob --batch=16 --saveEngine=F:\TensorRT-6.0.1.5\data\googlenet\mnist16.trt
Linux下使用的命令如下:
trtexec --deploy=/path/to/mnist.prototxt --model=/path/to/mnist.caffemodel --output=prob --batch=16 --saveEngine=mnist16.trt
我们来看一下输出了什么信息:
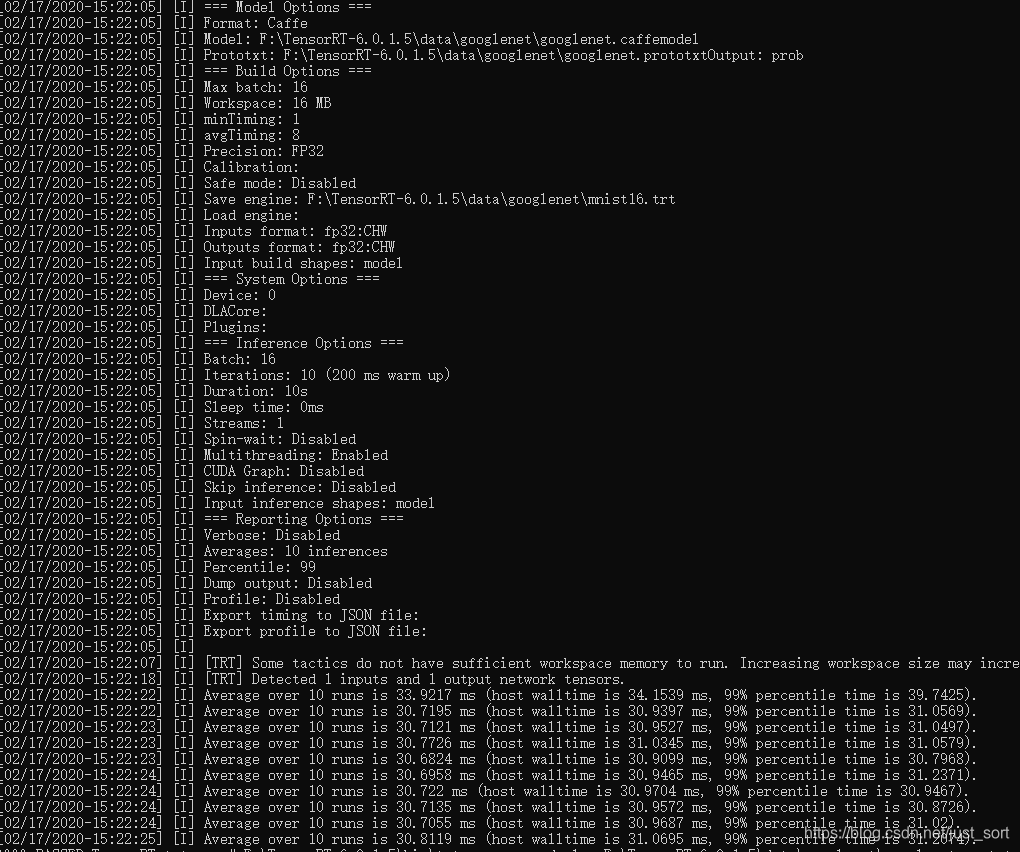
可以看到除了一些关键参数和硬件参数,窗口中还打印出了网络执行10次(这个参数也是可以指定的)前向推理的耗时并且还在F:\TensorRT-6.0.1.5\data\googlenet文件夹下生成了序列化引擎文件mnist.trt。
然后,可以将生成的引擎用于基准测试,下面的命令展示了如何加载引擎并在batch=16的输入(随机生成)上进行推理。
Linux:
trtexec --loadEngine=mnist16.trt --batch=16
Windows:
F:\TensorRT-6.0.1.5\bin\trtexec.exe --loadEngine=F:\TensorRT-6.0.1.5\data\googlenet\mnist16.trt --batch=16
测试结果如下所示:
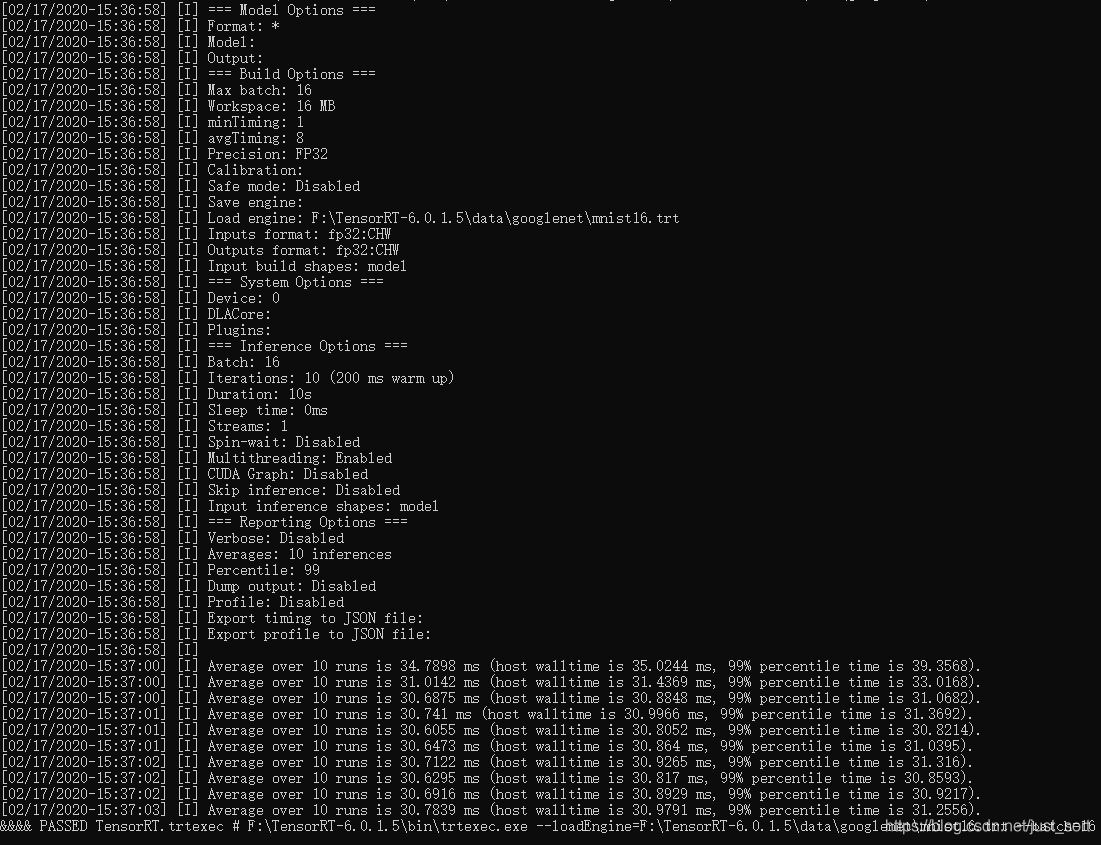
上面都是宏观的Profiling了整个googlenet,接下来我们加一个参数就可以细粒度的Profiling每个层的运行时间了。使用的命令如下:
F:\TensorRT-6.0.1.5\bin\trtexec.exe --deploy=F:\TensorRT-6.0.1.5\data\googlenet\googlenet.prototxt --model=F:\TensorRT-6.0.1.5\data\googlenet\googlenet.caffemodel --output=prob --batch=16 --saveEngine=F:\TensorRT-6.0.1.5\data\googlenet\mnist16.trt --dumpProfile
然后窗口种除了输出上面的信息还输出了每一个层的推理时间,注意在第3节讲到了,TensorRT的网络已经被优化合并了,所以这里的输出是优化合并后的网络结构的每个层的时间测试信息。
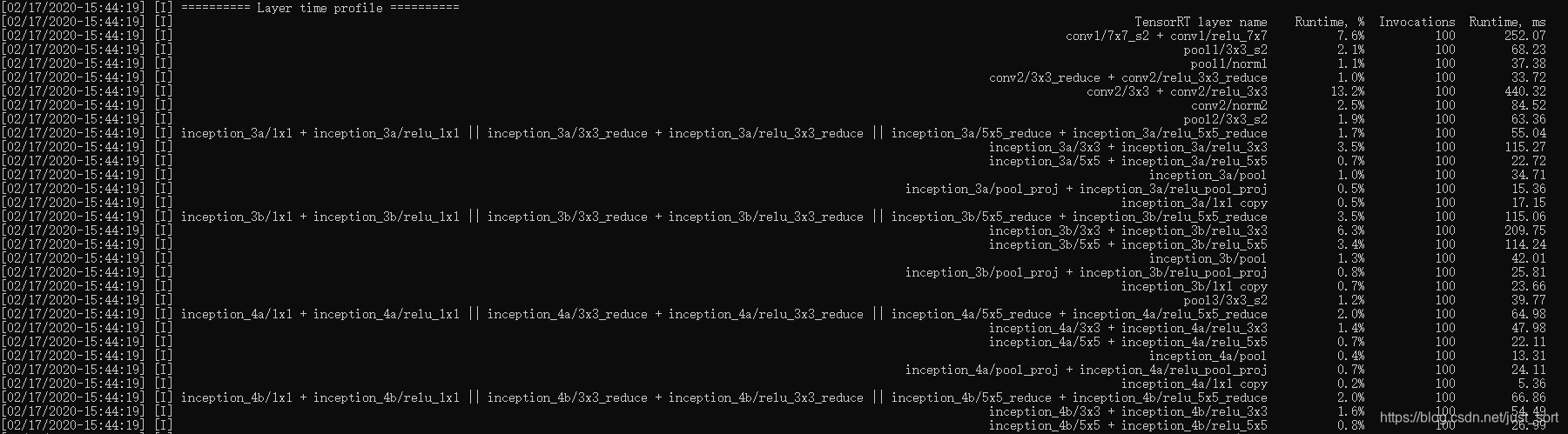
从这些信息我们可以方便的看出我们自己的网络里面到底是哪些层耗时最多,然后针对性的去优化。
如果你想测试FP16的性能,你可以通过新增一个参数--fp16来实现,但并不是所有的NVIDIA GPU系列都支持FP16或者说FP16模式都有加速效果,支持FP16的NVIDIA显卡为:
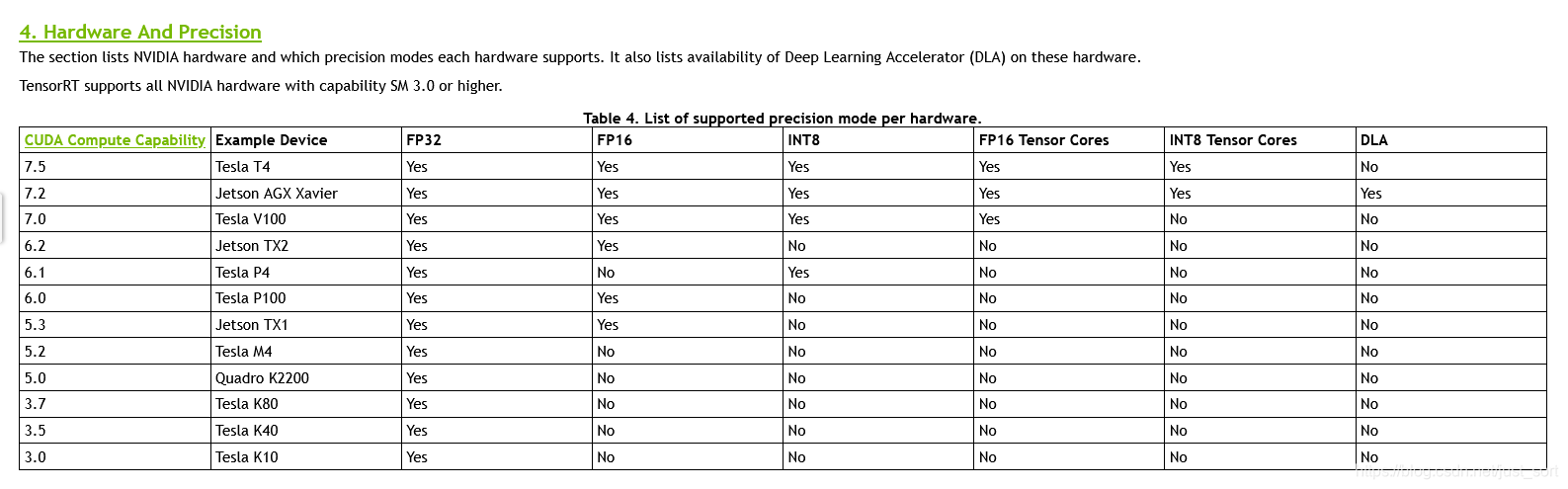
如果你的显卡支持FP16并有加速效果,可以细粒度的Profiling一下。
5. 总结¶
这篇文章介绍了一下如何在TensorRT中来细粒度的Profiling网络,方便快速查找我们的网络最耗时的部分,然后针对性的优化加速。
6. 参考¶
- https://arleyzhang.github.io/articles/fda11be6/
- https://github.com/NVIDIA/TensorRT/tree/master/samples/opensource/trtexec
- https://docs.nvidia.com/deeplearning/sdk/tensorrt-support-matrix/index.html#hardware-precision-matrix
7. 同期文章¶
- 深度学习算法优化系列十七 | TensorRT介绍,安装及如何使用?
- 深度学习算法优化系列十八 | TensorRT Mnist数字识别使用示例
- 深度学习算法优化系列十九 | 如何使用tensorRT C++ API搭建网络
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

本文总阅读量次