前言¶
具体原理已经讲过了,见上回的推文。深度学习算法优化系列七 | ICCV 2017的一篇模型剪枝论文,也是2019年众多开源剪枝项目的理论基础 。这篇文章是从源码实战的角度来解释模型剪枝,源码来自:https://github.com/Eric-mingjie/network-slimming 。我这里主要是结合源码来分析每个模型的具体剪枝过程,希望能给你剪枝自己的模型一些启发。
稀疏训练¶
论文的想法是对于每一个通道都引入一个缩放因子\gamma,然后和通道的输出相乘。接着联合训练网络权重和这些缩放因子,最后将小缩放因子的通道直接移除,微调剪枝后的网络,特别地,目标函数被定义为:
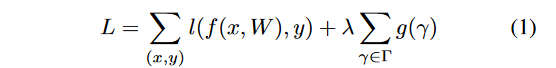
其中(x,y)代表训练数据和标签,W是网络的可训练参数,第一项是CNN的训练损失函数。g(.)是在缩放因子上的乘法项,\lambda是两项的平衡因子。论文的实验过程中选择g(s)=|s|,即L1正则化,这也被广泛的应用于稀疏化。次梯度下降法作为不平滑(不可导)的L1惩罚项的优化方法,另一个建议是使用平滑的L1正则项取代L1惩罚项,尽量避免在不平滑的点使用次梯度。
在main.py的实现中支持了稀疏训练,其中下面这行代码即添加了稀疏训练的惩罚系数\lambda,注意\gamma是作用在BN层的缩放系数上的:
parser.add_argument('--s', type=float, default=0.0001,
help='scale sparse rate (default: 0.0001)')
因此BN层的更新也要相应的加上惩罚项,代码如下:
def updateBN():
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):
m.weight.grad.data.add_(args.s*torch.sign(m.weight.data)) # L1
def train(epoch):
model.train()
for batch_idx, (data, target) in enumerate(train_loader):
if args.cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data), Variable(target)
optimizer.zero_grad()
output = model(data)
loss = F.cross_entropy(output, target)
pred = output.data.max(1, keepdim=True)[1]
loss.backward()
if args.sr:
updateBN()
optimizer.step()
if batch_idx % args.log_interval == 0:
print('Train Epoch: {} [{}/{} ({:.1f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.data[0]))
def test():
model.eval()
test_loss = 0
correct = 0
for data, target in test_loader:
if args.cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data, volatile=True), Variable(target)
output = model(data)
test_loss += F.cross_entropy(output, target, size_average=False).data[0] # sum up batch loss
pred = output.data.max(1, keepdim=True)[1] # get the index of the max log-probability
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.1f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))
return correct / float(len(test_loader.dataset))
def save_checkpoint(state, is_best, filepath):
torch.save(state, os.path.join(filepath, 'checkpoint.pth.tar'))
if is_best:
shutil.copyfile(os.path.join(filepath, 'checkpoint.pth.tar'), os.path.join(filepath, 'model_best.pth.tar'))
best_prec1 = 0.
for epoch in range(args.start_epoch, args.epochs):
if epoch in [args.epochs*0.5, args.epochs*0.75]:
for param_group in optimizer.param_groups:
param_group['lr'] *= 0.1
train(epoch)
prec1 = test()
is_best = prec1 > best_prec1
best_prec1 = max(prec1, best_prec1)
save_checkpoint({
'epoch': epoch + 1,
'state_dict': model.state_dict(),
'best_prec1': best_prec1,
'optimizer': optimizer.state_dict(),
}, is_best, filepath=args.save)
print("Best accuracy: "+str(best_prec1))
VGG16的剪枝¶
代码为工程目录下的vggprune.py。剪枝的具体步骤如下:
模型加载¶
加载需要剪枝的模型,也即是稀疏训练得到的BaseLine模型,代码如下,其中args.depth用于指定VGG模型的深度,一般为16和19:
model = vgg(dataset=args.dataset, depth=args.depth)
if args.cuda:
model.cuda()
if args.model:
if os.path.isfile(args.model):
print("=> loading checkpoint '{}'".format(args.model))
checkpoint = torch.load(args.model)
args.start_epoch = checkpoint['epoch']
best_prec1 = checkpoint['best_prec1']
model.load_state_dict(checkpoint['state_dict'])
print("=> loaded checkpoint '{}' (epoch {}) Prec1: {:f}"
.format(args.model, checkpoint['epoch'], best_prec1))
else:
print("=> no checkpoint found at '{}'".format(args.resume))
print(model)
预剪枝¶
首先确定剪枝的全局阈值,然后根据阈值得到剪枝后的网络每层的通道数cfg_mask,这个cfg_mask就可以确定我们剪枝后的模型的结构了,注意这个过程只是确定每一层那一些索引的通道要被剪枝掉并获得cfg_mask,还没有真正的执行剪枝操作。我给代码加了部分注释,应该不难懂。
# 计算需要剪枝的变量个数total
total = 0
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):
total += m.weight.data.shape[0]
# 确定剪枝的全局阈值
bn = torch.zeros(total)
index = 0
for m in model.modules():
if isinstance(m, nn.BatchNorm2d):
size = m.weight.data.shape[0]
bn[index:(index+size)] = m.weight.data.abs().clone()
index += size
# 按照权值大小排序
y, i = torch.sort(bn)
thre_index = int(total * args.percent)
# 确定要剪枝的阈值
thre = y[thre_index]
#********************************预剪枝*********************************#
pruned = 0
cfg = []
cfg_mask = []
for k, m in enumerate(model.modules()):
if isinstance(m, nn.BatchNorm2d):
weight_copy = m.weight.data.abs().clone()
# 要保留的通道标记Mask图
mask = weight_copy.gt(thre).float().cuda()
# 剪枝掉的通道数个数
pruned = pruned + mask.shape[0] - torch.sum(mask)
m.weight.data.mul_(mask)
m.bias.data.mul_(mask)
cfg.append(int(torch.sum(mask)))
cfg_mask.append(mask.clone())
print('layer index: {:d} \t total channel: {:d} \t remaining channel: {:d}'.
format(k, mask.shape[0], int(torch.sum(mask))))
elif isinstance(m, nn.MaxPool2d):
cfg.append('M')
pruned_ratio = pruned/total
print('Pre-processing Successful!')
对预剪枝后的模型进行测试¶
没什么好说的,看一下我的代码注释好啦。
# simple test model after Pre-processing prune (simple set BN scales to zeros)
#********************************预剪枝后model测试*********************************#
def test(model):
kwargs = {'num_workers': 1, 'pin_memory': True} if args.cuda else {}
# 加载测试数据
if args.dataset == 'cifar10':
test_loader = torch.utils.data.DataLoader(
datasets.CIFAR10('./data.cifar10', train=False, transform=transforms.Compose([
transforms.ToTensor(),
# 对R, G,B通道应该减的均值
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])),
batch_size=args.test_batch_size, shuffle=True, **kwargs)
elif args.dataset == 'cifar100':
test_loader = torch.utils.data.DataLoader(
datasets.CIFAR100('./data.cifar100', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.4914, 0.4822, 0.4465), (0.2023, 0.1994, 0.2010))])),
batch_size=args.test_batch_size, shuffle=True, **kwargs)
else:
raise ValueError("No valid dataset is given.")
model.eval()
correct = 0
for data, target in test_loader:
if args.cuda:
data, target = data.cuda(), target.cuda()
data, target = Variable(data, volatile=True), Variable(target)
output = model(data)
pred = output.data.max(1, keepdim=True)[1] # get the index of the max log-probability
# 记录类别预测正确的个数
correct += pred.eq(target.data.view_as(pred)).cpu().sum()
print('\nTest set: Accuracy: {}/{} ({:.1f}%)\n'.format(
correct, len(test_loader.dataset), 100. * correct / len(test_loader.dataset)))
return correct / float(len(test_loader.dataset))
acc = test(model)
正式剪枝¶
在预剪枝之后我们获得了每一个特征图需要剪掉哪些通道数的索引列表,接下来我们就可以按照这个列表执行剪枝操作了。剪枝的完整代码如下:
# 定义原始模型和新模型的每一层保留通道索引的mask
start_mask = torch.ones(3)
end_mask = cfg_mask[layer_id_in_cfg]
for [m0, m1] in zip(model.modules(), newmodel.modules()):
# 对BN层和ConV层都要剪枝
if isinstance(m0, nn.BatchNorm2d):
# np.squeeze 从数组的形状中删除单维度条目,即把shape中为1的维度去掉
# np.argwhere(a) 返回非0的数组元组的索引,其中a是要索引数组的条件。
idx1 = np.squeeze(np.argwhere(np.asarray(end_mask.cpu().numpy())))
# 如果维度是1,那么就新增一维,这是为了和BN层的weight的维度匹配
if idx1.size == 1:
idx1 = np.resize(idx1,(1,))
m1.weight.data = m0.weight.data[idx1.tolist()].clone()
m1.bias.data = m0.bias.data[idx1.tolist()].clone()
m1.running_mean = m0.running_mean[idx1.tolist()].clone()
m1.running_var = m0.running_var[idx1.tolist()].clone()
layer_id_in_cfg += 1
# 注意start_mask在end_mask的前一层,这个会在裁剪Conv2d的时候用到
start_mask = end_mask.clone()
if layer_id_in_cfg < len(cfg_mask): # do not change in Final FC
end_mask = cfg_mask[layer_id_in_cfg]
elif isinstance(m0, nn.Conv2d):
idx0 = np.squeeze(np.argwhere(np.asarray(start_mask.cpu().numpy())))
idx1 = np.squeeze(np.argwhere(np.asarray(end_mask.cpu().numpy())))
print('In shape: {:d}, Out shape {:d}.'.format(idx0.size, idx1.size))
if idx0.size == 1:
idx0 = np.resize(idx0, (1,))
if idx1.size == 1:
idx1 = np.resize(idx1, (1,))
# 注意卷积核Tensor维度为[n, c, w, h],两个卷积层连接,下一层的输入维度n就等于当前层的c
w1 = m0.weight.data[:, idx0.tolist(), :, :].clone()
w1 = w1[idx1.tolist(), :, :, :].clone()
m1.weight.data = w1.clone()
elif isinstance(m0, nn.Linear):
# 注意卷积核Tensor维度为[n, c, w, h],两个卷积层连接,下一层的输入维度n'就等于当前层的c
idx0 = np.squeeze(np.argwhere(np.asarray(start_mask.cpu().numpy())))
if idx0.size == 1:
idx0 = np.resize(idx0, (1,))
m1.weight.data = m0.weight.data[:, idx0].clone()
m1.bias.data = m0.bias.data.clone()
torch.save({'cfg': cfg, 'state_dict': newmodel.state_dict()}, os.path.join(args.save, 'pruned.pth.tar'))
print(newmodel)
model = newmodel
test(model)
到这里VGG16就被剪枝完了,剪枝完成后我们还需要对这个新模型进行Retrain,仍然是使用main.py即可,参数改一下,命令如下:
python main.py --refine [PATH TO THE PRUNED MODEL] --dataset cifar10 --arch vgg --depth 16 --epochs 160
这样就可以获得最终的模型了,VGG16在CIFAR10/100上剪枝并Retrain后最终的测试结果为:

 结果相当优秀了,剪枝Retrain之后精度更高了。
结果相当优秀了,剪枝Retrain之后精度更高了。
ResNet的剪枝¶
在深度学习算法优化系列七 | ICCV 2017的一篇模型剪枝论文,也是2019年众多开源剪枝项目的理论基础 提到对于ResNet和DenseNet这种每一层的输出会作为后续多个层的输入,且其BN层是在卷积层之前,在这种情况下,稀疏化是在层的输入末端得到的,一个层选择性的接受所有通道的子集去做下一步的卷积运算。为了在测试时节省参数和运行时间,需要放置一个通道选择层鉴别出重要的通道。 再通俗的解释一下通道鉴别层的作用吧,对于ResNet的BN层来讲,如果这个BN层后面放置了通道鉴别层就不需要做剪枝了,通道鉴别层都是放在每一个残差模块的第一个BN层后面以及整个网络的最后一个BN层后面,这是因为这几个层的输入不仅仅和一个层相关还和多个层相关。所以为了保持网络的泛化能力,这几个BN层不剪枝,只剪枝其他的BN层。
设置通道鉴别层¶
通道鉴别层的代码在models/channel_selection.py中,如下:
class channel_selection(nn.Module):
"""
从BN层的输出中选择通道。它应该直接放在BN层之后,此层的输出形状由self.indexes中的1的个数决定
"""
def __init__(self, num_channels):
"""
使用长度和通道数相同的全1向量初始化"indexes", 剪枝过程中,将要剪枝的通道对应的indexes位置设为0
"""
super(channel_selection, self).__init__()
self.indexes = nn.Parameter(torch.ones(num_channels))
def forward(self, input_tensor):
"""
参数:
输入Tensor维度: (N,C,H,W),这也是BN层的输出Tensor
"""
selected_index = np.squeeze(np.argwhere(self.indexes.data.cpu().numpy()))
if selected_index.size == 1:
selected_index = np.resize(selected_index, (1,))
output = input_tensor[:, selected_index, :, :]
return output
将通道鉴别层放入ResNet¶
将通道鉴别层按照前面介绍的方法放入ResNet中,代码在models/presnet.py中,如下注释部分是在原始的ResNet 部分BN层后面放入了通道鉴别层,其他都和原始模型一样。代码如下:
class Bottleneck(nn.Module):
expansion = 4
def __init__(self, inplanes, planes, cfg, stride=1, downsample=None):
super(Bottleneck, self).__init__()
self.bn1 = nn.BatchNorm2d(inplanes)
# 新增的通道鉴别层,放在BN之后
self.select = channel_selection(inplanes)
self.conv1 = nn.Conv2d(cfg[0], cfg[1], kernel_size=1, bias=False)
self.bn2 = nn.BatchNorm2d(cfg[1])
self.conv2 = nn.Conv2d(cfg[1], cfg[2], kernel_size=3, stride=stride,
padding=1, bias=False)
self.bn3 = nn.BatchNorm2d(cfg[2])
self.conv3 = nn.Conv2d(cfg[2], planes * 4, kernel_size=1, bias=False)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
def forward(self, x):
residual = x
out = self.bn1(x)
out = self.select(out)
out = self.relu(out)
out = self.conv1(out)
out = self.bn2(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn3(out)
out = self.relu(out)
out = self.conv3(out)
if self.downsample is not None:
residual = self.downsample(x)
out += residual
return out
class resnet(nn.Module):
def __init__(self, depth=164, dataset='cifar10', cfg=None):
super(resnet, self).__init__()
assert (depth - 2) % 9 == 0, 'depth should be 9n+2'
n = (depth - 2) // 9
block = Bottleneck
if cfg is None:
# Construct config variable.
cfg = [[16, 16, 16], [64, 16, 16]*(n-1), [64, 32, 32], [128, 32, 32]*(n-1), [128, 64, 64], [256, 64, 64]*(n-1), [256]]
cfg = [item for sub_list in cfg for item in sub_list]
self.inplanes = 16
self.conv1 = nn.Conv2d(3, 16, kernel_size=3, padding=1,
bias=False)
self.layer1 = self._make_layer(block, 16, n, cfg = cfg[0:3*n])
self.layer2 = self._make_layer(block, 32, n, cfg = cfg[3*n:6*n], stride=2)
self.layer3 = self._make_layer(block, 64, n, cfg = cfg[6*n:9*n], stride=2)
self.bn = nn.BatchNorm2d(64 * block.expansion)
# 新增的通道鉴别层,放在BN之后
self.select = channel_selection(64 * block.expansion)
self.relu = nn.ReLU(inplace=True)
self.avgpool = nn.AvgPool2d(8)
if dataset == 'cifar10':
self.fc = nn.Linear(cfg[-1], 10)
elif dataset == 'cifar100':
self.fc = nn.Linear(cfg[-1], 100)
for m in self.modules():
if isinstance(m, nn.Conv2d):
n = m.kernel_size[0] * m.kernel_size[1] * m.out_channels
m.weight.data.normal_(0, math.sqrt(2. / n))
elif isinstance(m, nn.BatchNorm2d):
m.weight.data.fill_(0.5)
m.bias.data.zero_()
def _make_layer(self, block, planes, blocks, cfg, stride=1):
downsample = None
if stride != 1 or self.inplanes != planes * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.inplanes, planes * block.expansion,
kernel_size=1, stride=stride, bias=False),
)
layers = []
layers.append(block(self.inplanes, planes, cfg[0:3], stride, downsample))
self.inplanes = planes * block.expansion
for i in range(1, blocks):
layers.append(block(self.inplanes, planes, cfg[3*i: 3*(i+1)]))
return nn.Sequential(*layers)
def forward(self, x):
x = self.conv1(x)
x = self.layer1(x) # 32x32
x = self.layer2(x) # 16x16
x = self.layer3(x) # 8x8
x = self.bn(x)
x = self.select(x)
x = self.relu(x)
x = self.avgpool(x)
x = x.view(x.size(0), -1)
x = self.fc(x)
return x
对Resnet进行剪枝¶
和VGGNet几乎一致,只关注一个核心改变之处,就是正式剪枝的函数多了一点,这部分代码在根目录下的resprune.py中,我贴一下相比于VGG16的变化之处的代码,也就是正式剪枝时的代码,有注释,不难:
for layer_id in range(len(old_modules)):
m0 = old_modules[layer_id]
m1 = new_modules[layer_id]
# 对BN层和ConV层都要剪枝
if isinstance(m0, nn.BatchNorm2d):
# np.squeeze 从数组的形状中删除单维度条目,即把shape中为1的维度去掉
# np.argwhere(a) 返回非0的数组元组的索引,其中a是要索引数组的条件。
idx1 = np.squeeze(np.argwhere(np.asarray(end_mask.cpu().numpy())))
# 如果维度是1,那么就新增一维,这是为了和BN层的weight的维度匹配
if idx1.size == 1:
idx1 = np.resize(idx1,(1,))
# 如果下一层是通道选择层,这个是ResNet和VGG剪枝的唯一不同之处
if isinstance(old_modules[layer_id + 1], channel_selection):
# 如果下一层是通道选择层,这一层就不剪枝
m1.weight.data = m0.weight.data.clone()
m1.bias.data = m0.bias.data.clone()
m1.running_mean = m0.running_mean.clone()
m1.running_var = m0.running_var.clone()
# We need to set the channel selection layer.
m2 = new_modules[layer_id + 1]
m2.indexes.data.zero_()
m2.indexes.data[idx1.tolist()] = 1.0
layer_id_in_cfg += 1
start_mask = end_mask.clone()
if layer_id_in_cfg < len(cfg_mask):
end_mask = cfg_mask[layer_id_in_cfg]
else:
# 否则正常剪枝
m1.weight.data = m0.weight.data[idx1.tolist()].clone()
m1.bias.data = m0.bias.data[idx1.tolist()].clone()
m1.running_mean = m0.running_mean[idx1.tolist()].clone()
m1.running_var = m0.running_var[idx1.tolist()].clone()
layer_id_in_cfg += 1
start_mask = end_mask.clone()
if layer_id_in_cfg < len(cfg_mask): # do not change in Final FC
end_mask = cfg_mask[layer_id_in_cfg]
elif isinstance(m0, nn.Conv2d):
if conv_count == 0:
m1.weight.data = m0.weight.data.clone()
conv_count += 1
continue
# 正常剪枝就好
if isinstance(old_modules[layer_id-1], channel_selection) or isinstance(old_modules[layer_id-1], nn.BatchNorm2d):
# This convers the convolutions in the residual block.
# The convolutions are either after the channel selection layer or after the batch normalization layer.
conv_count += 1
idx0 = np.squeeze(np.argwhere(np.asarray(start_mask.cpu().numpy())))
idx1 = np.squeeze(np.argwhere(np.asarray(end_mask.cpu().numpy())))
print('In shape: {:d}, Out shape {:d}.'.format(idx0.size, idx1.size))
if idx0.size == 1:
idx0 = np.resize(idx0, (1,))
if idx1.size == 1:
idx1 = np.resize(idx1, (1,))
w1 = m0.weight.data[:, idx0.tolist(), :, :].clone()
# If the current convolution is not the last convolution in the residual block, then we can change the
# number of output channels. Currently we use `conv_count` to detect whether it is such convolution.
if conv_count % 3 != 1:
w1 = w1[idx1.tolist(), :, :, :].clone()
m1.weight.data = w1.clone()
continue
# We need to consider the case where there are downsampling convolutions.
# For these convolutions, we just copy the weights.
m1.weight.data = m0.weight.data.clone()
elif isinstance(m0, nn.Linear):
idx0 = np.squeeze(np.argwhere(np.asarray(start_mask.cpu().numpy())))
if idx0.size == 1:
idx0 = np.resize(idx0, (1,))
m1.weight.data = m0.weight.data[:, idx0].clone()
m1.bias.data = m0.bias.data.clone()
Retrain¶
最后仍然需要Retrain,在CIFAR10和CIFAR100上的测试结果为:


DenseNet的剪枝¶
前面说清楚了VGGNet和ResNet的剪枝,对于DenseNet的剪枝我们只需要关注和上面两个剪枝的区别即可。然后观察了一下,和ResNet完全一致,所以就不再赘述了。这里只看一下结果测试:


后记¶
上面介绍了3个主流的Backbone网络VGG16,Resnet164,DenseNet40的剪枝方法和细节,这三个网络在CIFAR10/100数据上保证精度不掉(多数情况还提高了精度)的情况下可以剪掉原始模型一半以上的参数,充分证明了这个算法的有效性,并且也是工程友好的。另外这个剪枝代码配合pytorch->onnx->移动端框架也是比较好移植的。
备注¶
欢迎关注我的微信公众号GiantPandaCV,期待和你一起交流机器学习,深度学习,图像算法,优化技术,比赛及日常生活等。
本文总阅读量次