1. 前言¶
继续学习优化知识,这一节将以一个简单的肤色检测算法为例谈谈当一个算法中有比较运算符时,我们该如何向量化并进行加速,简单来说就是如何将比较运算语句写成SSE指令。
2. 普通实现¶
这是一个用来做肤色检测的算法,在《human skin color clustering for face detection》这篇文章中被提出,核心伪代码就是如果满足下面这个条件:R>95 And G>40 And B>20 And R>G And R>B And Max(R,G,B)-Min(R,G,B)>15 And Abs(R-G)>15 那么这个区域就是肤色区域,代码实现自然也是非常简单的。但这个算法的效果肯定是不太好的,但因为我们这个专题专注于优化技术,所以可以暂时不考虑这一点,普通实现的代码如下:
void IM_GetRoughSkinRegion(unsigned char *Src, unsigned char *Skin, int Width, int Height, int Stride) {
for (int Y = 0; Y < Height; Y++)
{
unsigned char *LinePS = Src + Y * Stride;
unsigned char *LinePD = Skin + Y * Width;
for (int X = 0; X < Width; X++)
{
int Blue = LinePS[0], Green = LinePS[1], Red = LinePS[2];
if (Red >= 60 && Green >= 40 && Blue >= 20 && Red >= Blue && (Red - Green) >= 10 && IM_Max(IM_Max(Red, Green), Blue) - IM_Min(IM_Min(Red, Green), Blue) >= 10)
LinePD[X] = 255;
else
LinePD[X] = 16;
LinePS += 3;
}
}
}
然后我们用一张图片来测试一下:


来测一下速度:
| 分辨率 | 算法优化 | 循环次数 | 速度 |
|---|---|---|---|
| 4272x2848 | 普通实现 | 1000 | 41.40ms |
3. 肤色检测算法第一版优化¶
首先最容易想到的是是否可以将这个算法并行起来加速呢?显然是可以的,利用OpenMP的编译制导语句并稍加修改代码获得一个多线程的肤色检测程序,代码如下:
void IM_GetRoughSkinRegion_OpenMP(unsigned char *Src, unsigned char *Skin, int Width, int Height, int Stride) {
for (int Y = 0; Y < Height; Y++)
{
unsigned char *LinePS = Src + Y * Stride;
unsigned char *LinePD = Skin + Y * Width;
#pragma omp parallel for num_threads(4)
for (int X = 0; X < Width; X++)
{
int Blue = LinePS[X*3 + 0], Green = LinePS[X*3 + 1], Red = LinePS[X*3 + 2];
if (Red >= 60 && Green >= 40 && Blue >= 20 && Red >= Blue && (Red - Green) >= 10 && IM_Max(IM_Max(Red, Green), Blue) - IM_Min(IM_Min(Red, Green), Blue) >= 10)
LinePD[X] = 255;
else
LinePD[X] = 16;
}
}
}
同样,来测一把速度:
| 分辨率 | 算法优化 | 循环次数 | 速度 |
|---|---|---|---|
| 4272x2848 | 普通实现 | 1000 | 41.40ms |
| 4272x2848 | OpenMP 4线程 | 1000 | 36.54ms |
可以看到速度稍微加快了些,这个优化还是有效的。
4. 肤色检测算法第二版优化¶
接下来我们用SSE指令集来尝试并行这个程序,先直接给出代码再来分析原理。
void IM_GetRoughSkinRegion_SSE(unsigned char *Src, unsigned char *Skin, int Width, int Height, int Stride) {
const int NonSkinLevel = 10; //非肤色部分的处理程序,本例取16,最大值取100,那样就是所有区域都为肤色,毫无意义
const int BlockSize = 16;
int Block = Width / BlockSize;
for (int Y = 0; Y < Height; Y++) {
unsigned char *LinePS = Src + Y * Stride;
unsigned char *LinePD = Skin + Y * Width;
for (int X = 0; X < Block * BlockSize; X += BlockSize, LinePS += BlockSize * 3, LinePD += BlockSize) {
__m128i Src1, Src2, Src3, Blue, Green, Red, Result, Max, Min, AbsDiff;
Src1 = _mm_loadu_si128((__m128i *)(LinePS + 0));
Src2 = _mm_loadu_si128((__m128i *)(LinePS + 16));
Src3 = _mm_loadu_si128((__m128i *)(LinePS + 32));
Blue = _mm_shuffle_epi8(Src1, _mm_setr_epi8(0, 3, 6, 9, 12, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
Blue = _mm_or_si128(Blue, _mm_shuffle_epi8(Src2, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, 2, 5, 8, 11, 14, -1, -1, -1, -1, -1)));
Blue = _mm_or_si128(Blue, _mm_shuffle_epi8(Src3, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 1, 4, 7, 10, 13)));
Green = _mm_shuffle_epi8(Src1, _mm_setr_epi8(1, 4, 7, 10, 13, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
Green = _mm_or_si128(Green, _mm_shuffle_epi8(Src2, _mm_setr_epi8(-1, -1, -1, -1, -1, 0, 3, 6, 9, 12, 15, -1, -1, -1, -1, -1)));
Green = _mm_or_si128(Green, _mm_shuffle_epi8(Src3, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 2, 5, 8, 11, 14)));
Red = _mm_shuffle_epi8(Src1, _mm_setr_epi8(2, 5, 8, 11, 14, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
Red = _mm_or_si128(Red, _mm_shuffle_epi8(Src2, _mm_setr_epi8(-1, -1, -1, -1, -1, 1, 4, 7, 10, 13, -1, -1, -1, -1, -1, -1)));
Red = _mm_or_si128(Red, _mm_shuffle_epi8(Src3, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 0, 3, 6, 9, 12, 15)));
Max = _mm_max_epu8(_mm_max_epu8(Blue, Green), Red); //IM_Max(IM_Max(Red, Green), Blue)
Min = _mm_min_epu8(_mm_min_epu8(Blue, Green), Red); //IM_Min(IM_Min(Red, Green), Blue)
Result = _mm_cmpge_epu8(Blue, _mm_set1_epi8(20)); //Blue >= 20
Result = _mm_and_si128(Result, _mm_cmpge_epu8(Green, _mm_set1_epi8(40))); //Green >= 40
Result = _mm_and_si128(Result, _mm_cmpge_epu8(Red, _mm_set1_epi8(60))); //Red >= 60
Result = _mm_and_si128(Result, _mm_cmpge_epu8(Red, Blue)); //Red >= Blue
Result = _mm_and_si128(Result, _mm_cmpge_epu8(_mm_subs_epu8(Red, Green), _mm_set1_epi8(10))); //(Red - Green) >= 10
Result = _mm_and_si128(Result, _mm_cmpge_epu8(_mm_subs_epu8(Max, Min), _mm_set1_epi8(10))); //IM_Max(IM_Max(Red, Green), Blue) - IM_Min(IM_Min(Red, Green), Blue) >= 10
Result = _mm_or_si128(Result, _mm_set1_epi8(16));
_mm_storeu_si128((__m128i*)(LinePD + 0), Result);
}
for (int X = Block * BlockSize; X < Width; X++, LinePS += 3, LinePD++)
{
int Blue = LinePS[0], Green = LinePS[1], Red = LinePS[2];
if (Red >= 60 && Green >= 40 && Blue >= 20 && Red >= Blue && (Red - Green) >= 10 && IM_Max(IM_Max(Red, Green), Blue) - IM_Min(IM_Min(Red, Green), Blue) >= 10)
LinePD[0] = 255; // 全为肤色部分
else
LinePD[0] = 16;
}
}
}
这里的SSE代码就是对普通实现的向量化,这里面最重要的东西其实就是如何处理程序中的比较运算符。这个代码里面的细节如下:
- 首先和【AI PC端算法优化】二,一步步优化自然饱和度算法一样,将B/G/R分量分别提取到一个SSE变量中。
- 然后来看一下Red >= 60 && Green >= 40 && Blue >= 20这个条件,我们需要一个unsigned char类型的比较函数,而SSE只提供了singed char类型的SSE比较函数即_mm_cmpeq_ps:
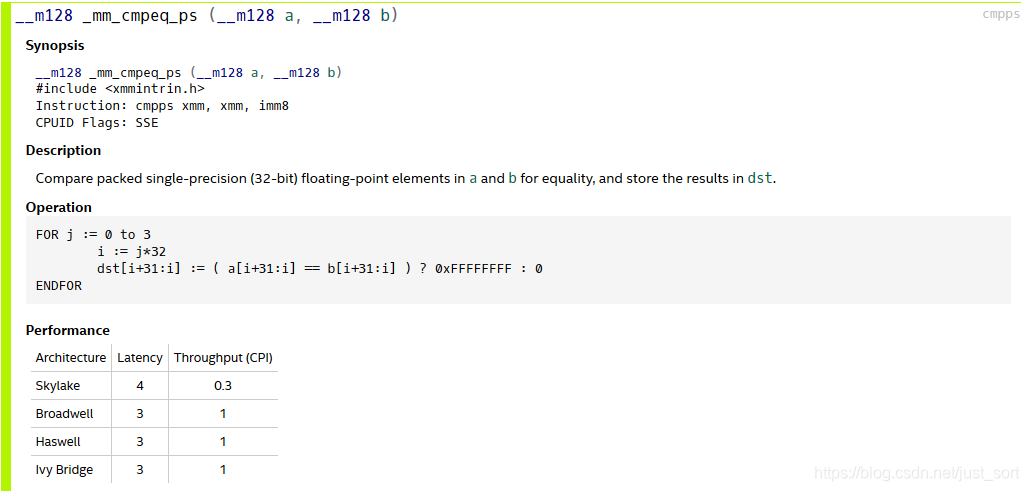
这个问题在:http://www.alfredklomp.com/programming/sse-intrinsics/ 这里可以找到解决办法,我截图如下:
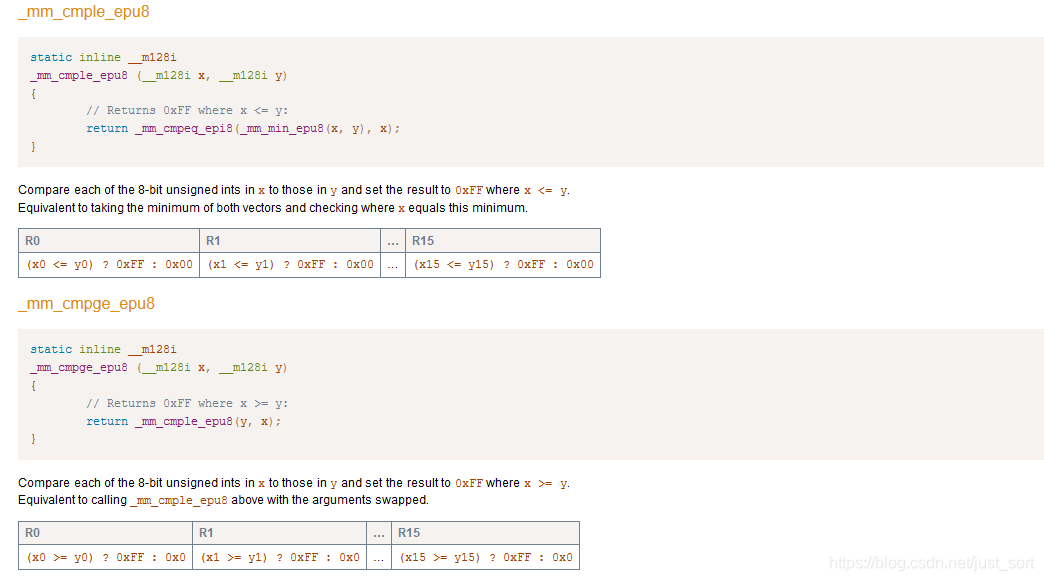
- 接下来我们再来看一下这个条件
(Red - Green) >= 10,如果计算Red-Green,则需要把他们转换为ushort类型才可能满足可能存在负数的情况,但如果使用_mm_subs_epu8这个饱和计算函数,当Red<Green时,Red-Green就被截断为0了,这个时候(Red-Green)>=10就会返回false了,而如果Red-Green>0就不会发生截断,刚好满足。其中_mm_subs_epu8这个饱和计算函数实现功能如下所示:
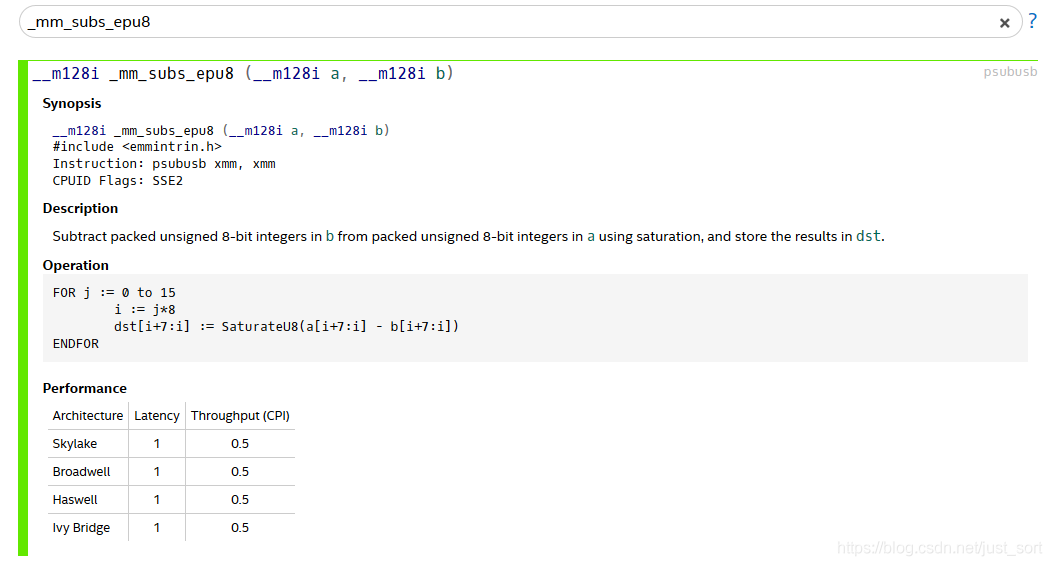
-
还有一个条件
IM_Max(IM_Max(Red, Green), Blue) - IM_Min(IM_Min(Red, Green), Blue) >= 10。这个是最简单的一个,直接用_mm_max_epu8和_mm_min_epu8获得B/G/R三分量的最大值和最小值,这个时候很明显max>min,因此有可以直接使用_mm_subs_epu8函数产生不会截断的正确结果。 -
注意到SSE的比较函数只有
0和255这两种结果,因此上面的6个判断条件直接进行and操作就可以获得最后的组合值了,满足所有的条件的像素结果就是255,否则就是0。 - 最后还有一个操作是不满条件的像素被设置成了
16或者其他值,这里作者提供的方式直接与其他数或起来即可,因为255和其他数进行or操作还是255,而0和其它数进行or操作就会变为其它数。
接下来还是测一把速度:
| 分辨率 | 算法优化 | 循环次数 | 速度 |
|---|---|---|---|
| 4272x2848 | 普通实现 | 1000 | 41.40ms |
| 4272x2848 | OpenMP 4线程 | 1000 | 36.54ms |
| 4272x2848 | SSE第一版 | 1000 | 6.77ms |
可以看到速度已经提升了6倍多,说明这个优化还是很有效的。
5. 肤色检测算法第三版优化¶
接着以前的思路,如果我们利用std::async实现异步多线程我们是否能获得更好的速度呢?那来试试吧,代码实现如下:
void _IM_GetRoughSkinRegion(unsigned char* Src, const int32_t Width, const int32_t start_row, const int32_t thread_stride, const int32_t Stride, unsigned char* Dest) {
const int NonSkinLevel = 10; //非肤色部分的处理程序,本例取16,最大值取100,那样就是所有区域都为肤色,毫无意义
const int BlockSize = 16;
int Block = Width / BlockSize;
for (int Y = start_row; Y < start_row + thread_stride; Y++) {
unsigned char *LinePS = Src + Y * Stride;
unsigned char *LinePD = Dest + Y * Width;
for (int X = 0; X < Block * BlockSize; X += BlockSize, LinePS += BlockSize * 3, LinePD += BlockSize) {
__m128i Src1, Src2, Src3, Blue, Green, Red, Result, Max, Min, AbsDiff;
Src1 = _mm_loadu_si128((__m128i *)(LinePS + 0));
Src2 = _mm_loadu_si128((__m128i *)(LinePS + 16));
Src3 = _mm_loadu_si128((__m128i *)(LinePS + 32));
Blue = _mm_shuffle_epi8(Src1, _mm_setr_epi8(0, 3, 6, 9, 12, 15, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
Blue = _mm_or_si128(Blue, _mm_shuffle_epi8(Src2, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, 2, 5, 8, 11, 14, -1, -1, -1, -1, -1)));
Blue = _mm_or_si128(Blue, _mm_shuffle_epi8(Src3, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 1, 4, 7, 10, 13)));
Green = _mm_shuffle_epi8(Src1, _mm_setr_epi8(1, 4, 7, 10, 13, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
Green = _mm_or_si128(Green, _mm_shuffle_epi8(Src2, _mm_setr_epi8(-1, -1, -1, -1, -1, 0, 3, 6, 9, 12, 15, -1, -1, -1, -1, -1)));
Green = _mm_or_si128(Green, _mm_shuffle_epi8(Src3, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 2, 5, 8, 11, 14)));
Red = _mm_shuffle_epi8(Src1, _mm_setr_epi8(2, 5, 8, 11, 14, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1));
Red = _mm_or_si128(Red, _mm_shuffle_epi8(Src2, _mm_setr_epi8(-1, -1, -1, -1, -1, 1, 4, 7, 10, 13, -1, -1, -1, -1, -1, -1)));
Red = _mm_or_si128(Red, _mm_shuffle_epi8(Src3, _mm_setr_epi8(-1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 0, 3, 6, 9, 12, 15)));
Max = _mm_max_epu8(_mm_max_epu8(Blue, Green), Red); //IM_Max(IM_Max(Red, Green), Blue)
Min = _mm_min_epu8(_mm_min_epu8(Blue, Green), Red); //IM_Min(IM_Min(Red, Green), Blue)
Result = _mm_cmpge_epu8(Blue, _mm_set1_epi8(20)); //Blue >= 20
Result = _mm_and_si128(Result, _mm_cmpge_epu8(Green, _mm_set1_epi8(40))); //Green >= 40
Result = _mm_and_si128(Result, _mm_cmpge_epu8(Red, _mm_set1_epi8(60))); //Red >= 60
Result = _mm_and_si128(Result, _mm_cmpge_epu8(Red, Blue)); //Red >= Blue
Result = _mm_and_si128(Result, _mm_cmpge_epu8(_mm_subs_epu8(Red, Green), _mm_set1_epi8(10))); //(Red - Green) >= 10
Result = _mm_and_si128(Result, _mm_cmpge_epu8(_mm_subs_epu8(Max, Min), _mm_set1_epi8(10))); //IM_Max(IM_Max(Red, Green), Blue) - IM_Min(IM_Min(Red, Green), Blue) >= 10
Result = _mm_or_si128(Result, _mm_set1_epi8(16));
_mm_storeu_si128((__m128i*)(LinePD + 0), Result);
}
for (int X = Block * BlockSize; X < Width; X++, LinePS += 3, LinePD++)
{
int Blue = LinePS[0], Green = LinePS[1], Red = LinePS[2];
if (Red >= 60 && Green >= 40 && Blue >= 20 && Red >= Blue && (Red - Green) >= 10 && IM_Max(IM_Max(Red, Green), Blue) - IM_Min(IM_Min(Red, Green), Blue) >= 10)
LinePD[0] = 255; // 全为肤色部分
else
LinePD[0] = 16;
}
}
}
void IM_GetRoughSkinRegion_SSE2(unsigned char *Src, unsigned char *Skin, int width, int height, int stride) {
const int32_t hw_concur = std::min(height >> 4, static_cast<int32_t>(std::thread::hardware_concurrency()));
std::vector<std::future<void>> fut(hw_concur);
const int thread_stride = (height - 1) / hw_concur + 1;
int i = 0, start = 0;
for (; i < std::min(height, hw_concur); i++, start += thread_stride)
{
fut[i] = std::async(std::launch::async, _IM_GetRoughSkinRegion, Src, width, start, thread_stride, stride, Skin);
}
for (int j = 0; j < i; ++j)
fut[j].wait();
}
来测一下速度:
| 分辨率 | 算法优化 | 循环次数 | 速度 |
|---|---|---|---|
| 4272x2848 | 普通实现 | 1000 | 41.40ms |
| 4272x2848 | OpenMP 4线程 | 1000 | 36.54ms |
| 4272x2848 | SSE第一版 | 1000 | 6.77ms |
| 4272x2848 | SSE第二版(std::async) | 1000 | 4.73ms |
现在相对于原始的实现,已经有8.75倍的加速了,或许你在想还有没有办法更进一步加速呢?答案是肯定的,AVX指令集自然可以做到更快,但是写指令集花费的时间比较多,这里我就不再放出这个算法的AVX指令集了,感兴趣的同学可以自己实现以获得更好的加速效果。
6. 总结¶
本节就讲到这里了,我们首先介绍了一个简单的肤色检测算法,然后利用多线程,SSE指令集等技术一步一步来对这个算法进行了优化,最终达到了9倍左右的加速比并且通过这一节的学习,我们掌握了如何在有条件判断语句的时候将算法向量化,干货还是很多的,希望感兴趣的同学可以读一读。
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

本文总阅读量次