0x0. 前言¶
由于CUDA水平太菜,所以一直没写过这方面的笔记。现在日常的工作中已经不能离开写CUDA代码,所以准备学习ZZK随缘做一做CUDA的笔记记录一下学习到的知识和技巧。这篇文章记录的是阅读OneFlow的Element-Wise系列CUDA算子实现方案学习到的技巧,希望可以帮助到一起入门CUDA的小伙伴们。Elemet-Wise算子指的是针对输入Tensor进行逐元素操作,比如ReLU就是针对输入Tensor的每个值进行判断是否大于0,大于0的话输出就是输入否则就是0。用CUDA来表达最简单的写法就是:
__global__ void relu_kernel(float* input, float* output){
int32_t idx = blockIdx.x * blockDim.x + threadIdx.x;
output[idx] = input[idx] < 0 ? 0 : input[idx];
}
int main(){
float* input;
float* output;
int32_t elem_cnt = 3*224*224;
cudaMalloc(&input, sizeof(float)*elem_cnt);
cudaMalloc(&output, sizeof(float)*elem_cnt);
int32_t thread_num = 256;
int32_t grid_size = (elem_cnt + thread_num -1) / thread_num;
relu_kernel<<<grid_size, thread_num>>>(src, dst);
cudaDeviceSynchronize();
cudaFree(src);
cudaFree(dst);
return 0;
}
虽然这种写法非常简单明了,但却存在明显的性能问题。所以这篇文章将基于OneFlow开源的Element-Wise CUDA算子方案来解释如何写一个高性能的Element-Wise CUDA算子。
0x1. 性能¶
以GELU激活函数为例子,分别测试 dtype = float32,不同shape下的前向耗时以及带宽利用率(NVIDIA A100-PCIE-40GB)。性能情况如下图所示:
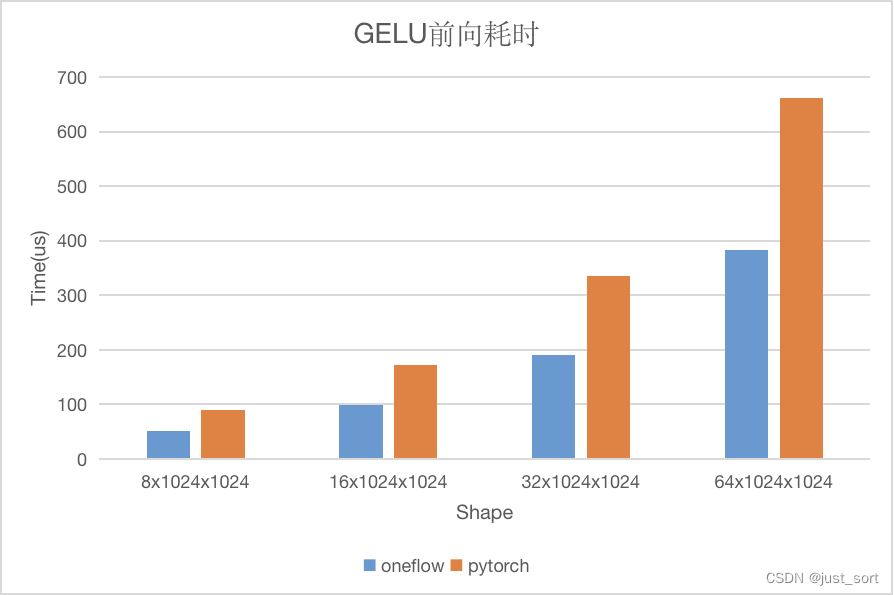
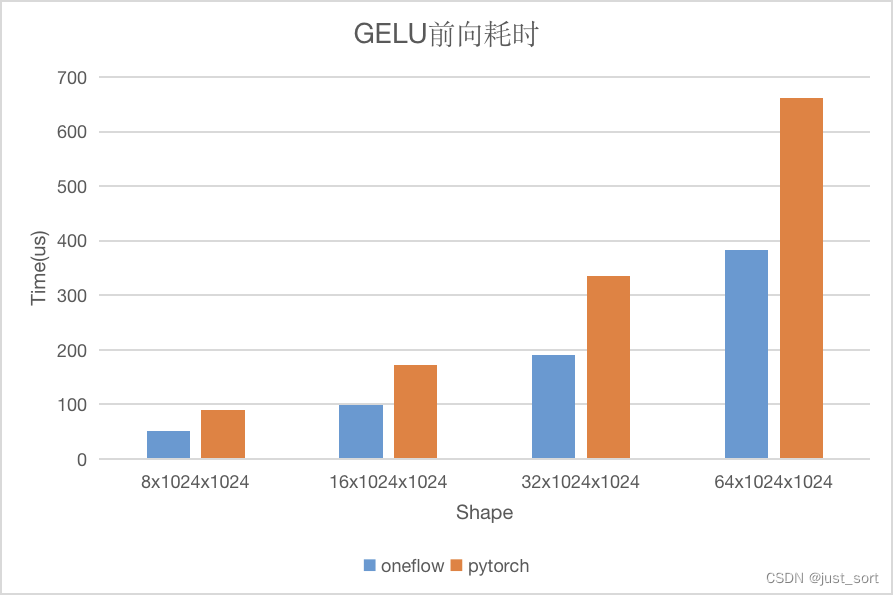
可以看到对于 GeLU 来说,无论是性能还是带宽 OneFlow 的实现都是更优的,接下来我们就来了解一下为什么 OneFlow 的 Element-Wise 算子性能可以做到更优。
0x2. 用法¶
OneFlow在 elementwise.cuh 文件中分别针对一元,二元,三元运算的 Element-Wise 操作实现了模板函数。在包含这个头文件之后我们可以使用 cuda::elementwise::Unary/Binary/Ternary 这几个模板函数来针对我们自己定义的 Element-Wise 操作进行计算。注意,这里说的一元,二元,三元代表的是这个 Element-Wise 操作有几个输入 Tensor。
我们举个例子,假设我们要做的 Element-Wise 操作是逐点乘法,也即有 2 个输入Tensor x 和 y,然后 x 和 y的形状和数据类型都是一致的。那么我们可以定义一个模板类:
template<typename T>
struct MultiplyFunctor {
OF_DEVICE_FUNC T operator()(T x, T y) const {
return x*y;
}
};
这里 OF_DEVICE_FUNC 表示我们定义的这个函数既可以运行在 CPU 又可以运行在 GPU 上,它的定义是:
#if defined(__CUDACC__)
#define OF_DEVICE_FUNCTION __device__ __host__ __forceinline__
#else
#define OF_DEVICE_FUNCTION inline
#endif
然后我们就可以使用 cuda::elementwise::Binary 这个模板函数来完成这个二元的 Element-Wise 算子了。示例代码如下:
const user_op::Tensor* x = ctx->Tensor4ArgNameAndIndex("x", 0);
const user_op::Tensor* y = ctx->Tensor4ArgNameAndIndex("y", 0);
user_op::Tensor* out = ctx->Tensor4ArgNameAndIndex("out", 0);
const int64_t elem_cnt = x->shape().elem_cnt();
OF_CUDA_CHECK(cuda::elementwise::Binary(MultiplyFunctor<T>(), elem_cnt, out->mut_dptr<T>(),
x->dptr<T>(),
y->dptr<T>(),
ctx->device_ctx()->cuda_stream()));
这里的 x, y, out 分别代表这个 Element-Wise 操作的输入输出 Tensor,然后 element_cnt 表示 Tensor 的元素个数,输出张量的数据首地址 out->mut_dptr<T>(), 输入张量的数据首地址 x->dptr<T>() && y->dptr<T>() ,最后一个参数则是当前 Kernel 运行的 cuda Stream对象。
0x3. 原理&&代码实现解析¶
我个人认为这里有几个要点,分别是一个线程处理多个数据,向量化数据访问提升带宽,设置合理的Block数量(GridSize)和线程数量(BlockSize)以及在合适的地方进行循环展开(unrool)以及一些编程上的技巧。
0x3.1 给 Element-Wise 操作设置合理的 GridSize 和 BlockSize¶
下面这段代码展示了 OneFlow 针对 Element-Wise 算子是如何设置 GridSize 和 BlockSize 的。对应的源码地址为:https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/core/cuda/elementwise.cuh#L30-L52 。
constexpr int kBlockSize = 256;
constexpr int kNumWaves = 32;
inline cudaError_t GetNumBlocks(int64_t n, int* num_blocks) {
int dev;
{
cudaError_t err = cudaGetDevice(&dev);
if (err != cudaSuccess) { return err; }
}
int sm_count;
{
cudaError_t err = cudaDeviceGetAttribute(&sm_count, cudaDevAttrMultiProcessorCount, dev);
if (err != cudaSuccess) { return err; }
}
int tpm;
{
cudaError_t err = cudaDeviceGetAttribute(&tpm, cudaDevAttrMaxThreadsPerMultiProcessor, dev);
if (err != cudaSuccess) { return err; }
}
*num_blocks = std::max<int>(1, std::min<int64_t>((n + kBlockSize - 1) / kBlockSize,
sm_count * tpm / kBlockSize * kNumWaves));
return cudaSuccess;
}
这个地方 BlockSize 直接被设置为了 256 ,对应 constexpr int kBlockSize = 256; 这行代码,也就是说每个 Block 有 256 个线程。为什么是 256 ?大家不妨读一下俊丞大佬这篇经典的 给CUDA Kernel设置合适的 GridSize 和 Block Size 的文章 。文章中通过对 SM 的资源分析确定在主流的GPU上将 BlockSize 设置为 128 或者 256 是比较合适,在这里直接设置为了 256 。
确定了 BlockSize 之后需要确定 Kernel 启动线程块的数量,我一直觉得上述文章中对这一段的分析是尤其精彩的,这里再截图展示一下:

根据这里的分析,对于 Element-Wise 操作要设置合适的 GridSize 不仅需要考虑元素的数量还要考虑由于 SM 硬件本身带来的限制。如下公式所述:
*num_blocks = std::max<int>(1, std::min<int64_t>((n + kBlockSize - 1) / kBlockSize,
sm_count * tpm / kBlockSize * kNumWaves));
这里的 (n + kBlockSize - 1) / kBlockSize 就是根据 Element-Wise 操作的元素个数来计算需要启动多少个线程块,比如在文章开头的例子中有 224 \times 224 \times 3 = 150528 个元素,那么就一共需要 (150528+256-1)/256=588个线程块。然后这里以GTX 3080Ti为例,它的SM个数也就是sm_count=80,每个SM最多调度的线程数tpm=1536,那么sm_count * tpm / kBlockSize * kNumWaves = 80 * 1536 / 256 * 32 = 15360,所以在这个例子中我们最终设置的线程块个数为 588 个。
通过上述讲解和分析我们已经确定了启动 Element-Wise CUDA Kernel 的 GridSize 和 BlockSize。
0x3.2 向量化数据访问提升带宽¶
对于大多数 Element-Wise 算子来说,一般它们的计算量不会太大,所以它们的瓶颈一般在GPU的带宽上。在 NVIDIA 的性能优化博客 https://developer.nvidia.com/blog/cuda-pro-tip-increase-performance-with-vectorized-memory-access/ 中提到,对于很多 CUDA 核函数我们都可以通过向量化数据访问的方式来提升带宽受限的 Kernel 的性能,特别是对于架构比较新的 GPU 向量化数据访问的效果会更加明显。
在 OneFlow 的 Element-Wise 系列算子中,为了更好的进行向量化的数据访问,俊丞设计了如下的 Pack 数据结构(代码位置:https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/core/cuda/elementwise.cuh#L54-L70):
template<typename T, int pack_size>
struct GetPackType {
using type = typename std::aligned_storage<pack_size * sizeof(T), pack_size * sizeof(T)>::type;
};
template<typename T, int pack_size>
using PackType = typename GetPackType<T, pack_size>::type;
template<typename T, int pack_size>
union Pack {
static_assert(sizeof(PackType<T, pack_size>) == sizeof(T) * pack_size, "");
__device__ Pack() {
// do nothing
}
PackType<T, pack_size> storage;
T elem[pack_size];
};
首先 GetPackType 结构体中使用了 std::aligned_storage 先声明了一个内存对齐的数据类型 type ,注意这个 type 的内存长度为 pack_size * sizeof(T) 。然后这里的 T 是我们需要进行 Pack 的数据类型,而 pack_size 则表示我们需要 Pack 的元素个数。接下来我们看到 Pack 联合体中声明了 storage 和 elem 两个数组,它们公用同一段对齐的内存。然后 Pack 联合体的入口有一个检查: static_assert(sizeof(PackType<T, pack_size>) == sizeof(T) * pack_size, ""); 这是用来判断我们之前声明的 type 的内存长度是否符合预期。
接下来我们从 https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/core/cuda/elementwise.cuh#L155-L194 这里可以看到这个 Pack 联合体主要是用在 Kernel 启动之前判断 Element-Wise 操作的输入输出 Tensor 对应的数据指针地址是否满足内存对齐的条件,如果不满足则这个 Element-Wise 操作无法执行数据 Pack 。对应下图2个画红色框的地方。
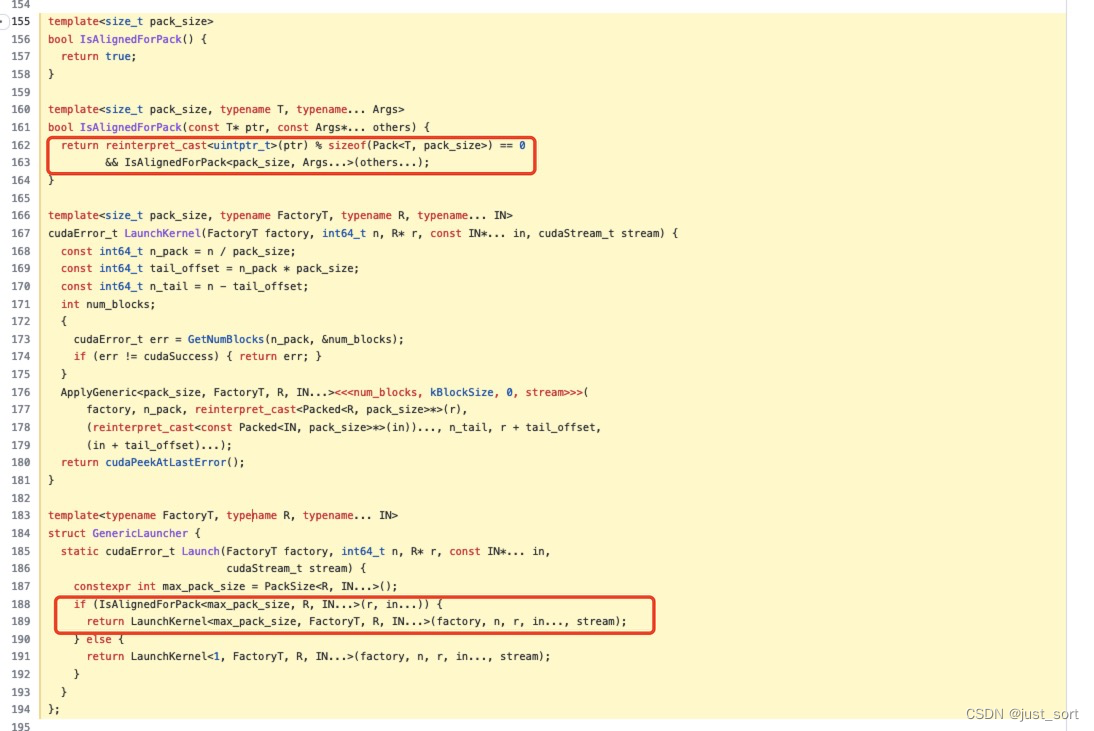
接下来,OneFlow 定义了真正要执行数据 Pack 的数据结构 Packed 并且定义了计算 PackSize 的工具函数。代码位置为:https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/core/cuda/elementwise.cuh#L72-L95 。
template<typename T, int pack_size>
struct alignas(sizeof(T) * pack_size) Packed {
__device__ Packed() {
// do nothing
}
union {
T elem[pack_size];
};
};
constexpr int kMaxPackBytes = 128 / 8;
constexpr int kMaxPackSize = 8;
constexpr int Min(int a, int b) { return a < b ? a : b; }
template<typename T>
constexpr int PackSize() {
return Min(kMaxPackBytes / sizeof(T), kMaxPackSize);
}
template<typename T, typename U, typename... Args>
constexpr int PackSize() {
return Min(PackSize<T>(), PackSize<U, Args...>());
}
这里需要注意的是对于 CUDA 来说,最多支持 128 个 bit 的访问粒度,也就是说 PackSize 的大小不能超过 128 个bit。然后对于各种数据类型来说,Half 数据类型的 bit 数是最少的即 16,所以一次性可以支持 Pack 8个half类型的数据,4个float32的数据,以此类推。所以这里的定义的 kMaxPackSize 表示 128/16=8 ,然后 kMaxPackBytes 则表示最大可以 Pack 的 byte 数 。
请注意区分 bit 和 byte 。
接下来 https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/core/cuda/elementwise.cuh#L97-L144 则是真正的为 Element-Wise 操作完成数据 Pack 并执行计算。
首先来看这段充满技巧的代码:

首先这里定义了一个 HasApply2 类用来判断 Functor是否支持两个两个的操作,比如half2。如果 Functor 里定义了apply2,那么test就会匹配到one函数,返回的是sizeof char,value是true。比如 half 可以 Pack 一次8个,但是有 __half22float2 这种针对 half2 的操作,那它就可以两个两个的做。可以看到对于 half2 类型的 Element-Wise 操作我们需要给对应的 Functor 定义一个 Apply2 函数,比如对于 Cast 操作的 Functor 定义如下:
template<typename To, typename From, typename = void>
struct CastFunctor {
__device__ To operator()(From from) const { return static_cast<To>(from); }
};
template<typename To>
struct CastFunctor<To, half, typename std::enable_if<!std::is_same<To, half>::value>::type> {
__device__ To operator()(half from) const { return static_cast<To>(static_cast<float>(from)); }
__device__ void Apply2(To* to, const half* from) const {
const float2 f2 = __half22float2(*reinterpret_cast<const half2*>(from));
to[0] = static_cast<To>(f2.x);
to[1] = static_cast<To>(f2.y);
}
};
0x3.3 启动 Kernel¶
我们接下来看一下 Element-Wise 的 Kernel 实现:https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/core/cuda/elementwise.cuh#L133-L144 。

在 Kernel 中我们发现每一个线程实际上处理了多个 Pack 后的数据,也即:for (int64_t i = global_tid; i < n_pack; i += blockDim.x * gridDim.x) 。初学者看到这个循环也许会比较疑惑,为什么它的步幅是 blockDim.x * gridDim.x ? 这个 blockDim.x * gridDim.x 表示的是 CUDA 线程网格中的线程总数。假设线程网格中有 1280 个线程,线程 0 将计算元素 0、1280、2560 等。通过使用步幅等于网格大小的循环,确保了 warp 中的所有寻址都是单位步幅,可以获得最大的内存合并。想了解更多细节可以查看:https://zhuanlan.zhihu.com/p/571320529 。
除此之外,使用这种技巧的还有个好处就是如果对于 Kernel 中存在每个线程都包含一个公共的操作,那么线程数的增多,也代表着这部分的开销变大。这个时候我们减少线程的数量并循环进行处理的话那么这个公共操作的开销就会更低。
最后,在循环之外,我们还需要根据传入的 n_tail 参数,看一下还有没有因为没有被 pack_size 整除的剩余元素,如果有的话就单独调用 functor 进行处理。
0x3.4 unroll¶
实际上就是代码中的 #pragma unroll ,这个宏会对我们的 for 循环做循环展开,让更多的指令可以并行执行。但容易想到,只有处理的数据没有前后依赖关系的时候我们可以做。对于大多数的 ElementWise 算子来说一般是满足这个条件的。
0x3.5 Kernel Launch的细节¶
在 https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/core/cuda/elementwise.cuh#L166-L181 这个位置 OneFlow 展示了 Element-Wise Kernel 的启动细节,我们简单注释一下:
template<size_t pack_size, typename FactoryT, typename R, typename... IN>
cudaError_t LaunchKernel(FactoryT factory, int64_t n, R* r, const IN*... in, cudaStream_t stream) {
const int64_t n_pack = n / pack_size; // 根据元素个数和pack_size,计算pack数目,比如1026 / 4 = 256。
const int64_t tail_offset = n_pack * pack_size; // 如果存在不被整除的情况,我们计算使用pack的偏移量:256*4;
const int64_t n_tail = n - tail_offset; // // 元素数目-偏移量 = 剩下的元素个数-> 1026-1024 = 2
int num_blocks;
{
cudaError_t err = GetNumBlocks(n_pack, &num_blocks); // 计算线程块数目
if (err != cudaSuccess) { return err; }
}
ApplyGeneric<pack_size, FactoryT, R, IN...><<<num_blocks, kBlockSize, 0, stream>>>(
factory, n_pack, reinterpret_cast<Packed<R, pack_size>*>(r),
(reinterpret_cast<const Packed<IN, pack_size>*>(in))..., n_tail, r + tail_offset,
(in + tail_offset)...);
return cudaPeekAtLastError();
}
0x4. 总结¶
以上就是我对 OneFlow Element-Wise 系列 CUDA 算子实现的解析,后续有空会持续更新学习到的新知识。
本文总阅读量次