【BBuf的CUDA笔记】三,reduce优化入门学习笔记
reduce优化学习笔记¶
这里记录学习 NIVDIA 的reduce优化官方博客 做的笔记。完整实验代码见:https://github.com/BBuf/how-to-optim-algorithm-in-cuda
问题介绍¶
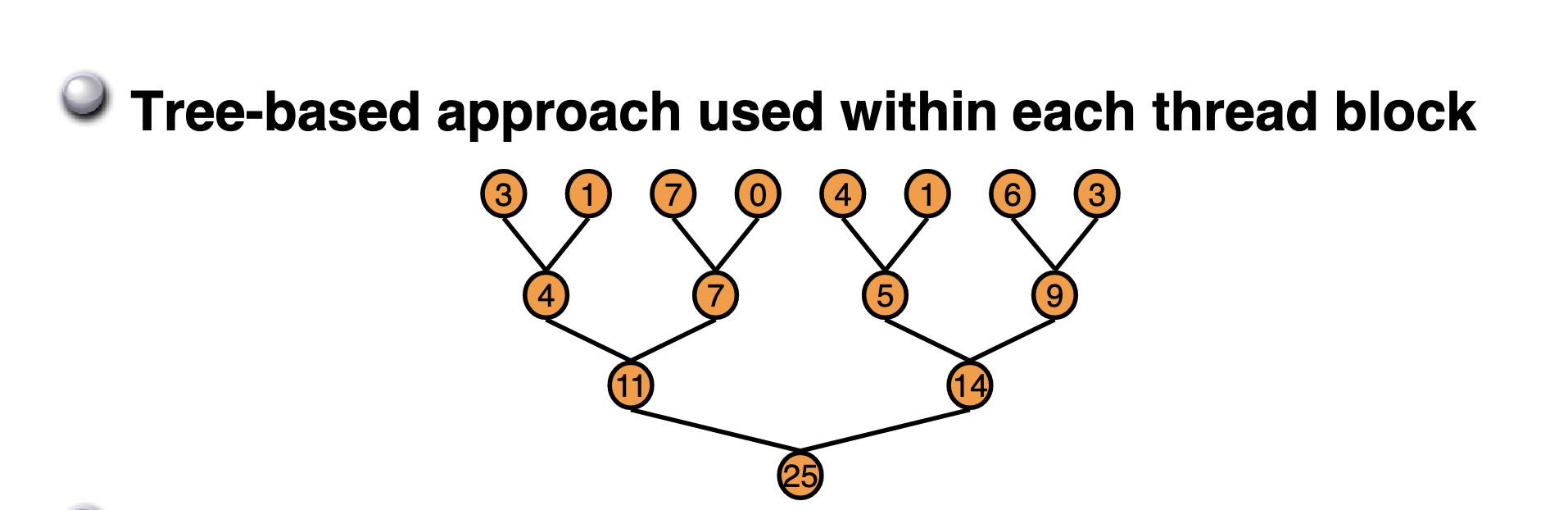
通俗的来说,Reduce就是要对一个数组求 sum,min,max,avg 等等。Reduce又被叫作规约,意思就是递归约减,最后获得的输出相比于输入一般维度上会递减。比如 nvidia 博客上这个 Reduce Sum 问题,一个长度为 8 的数组求和之后得到的输出只有一个数,从 1 维数组变成一个标量。本文就以 Reduce Sum 为例来记录 Reduce 优化。
硬件环境¶
NVIDIA A100-PCIE-40GB , 峰值带宽在 1555 GB/s , CUDA版本为11.8.
构建BaseLine¶
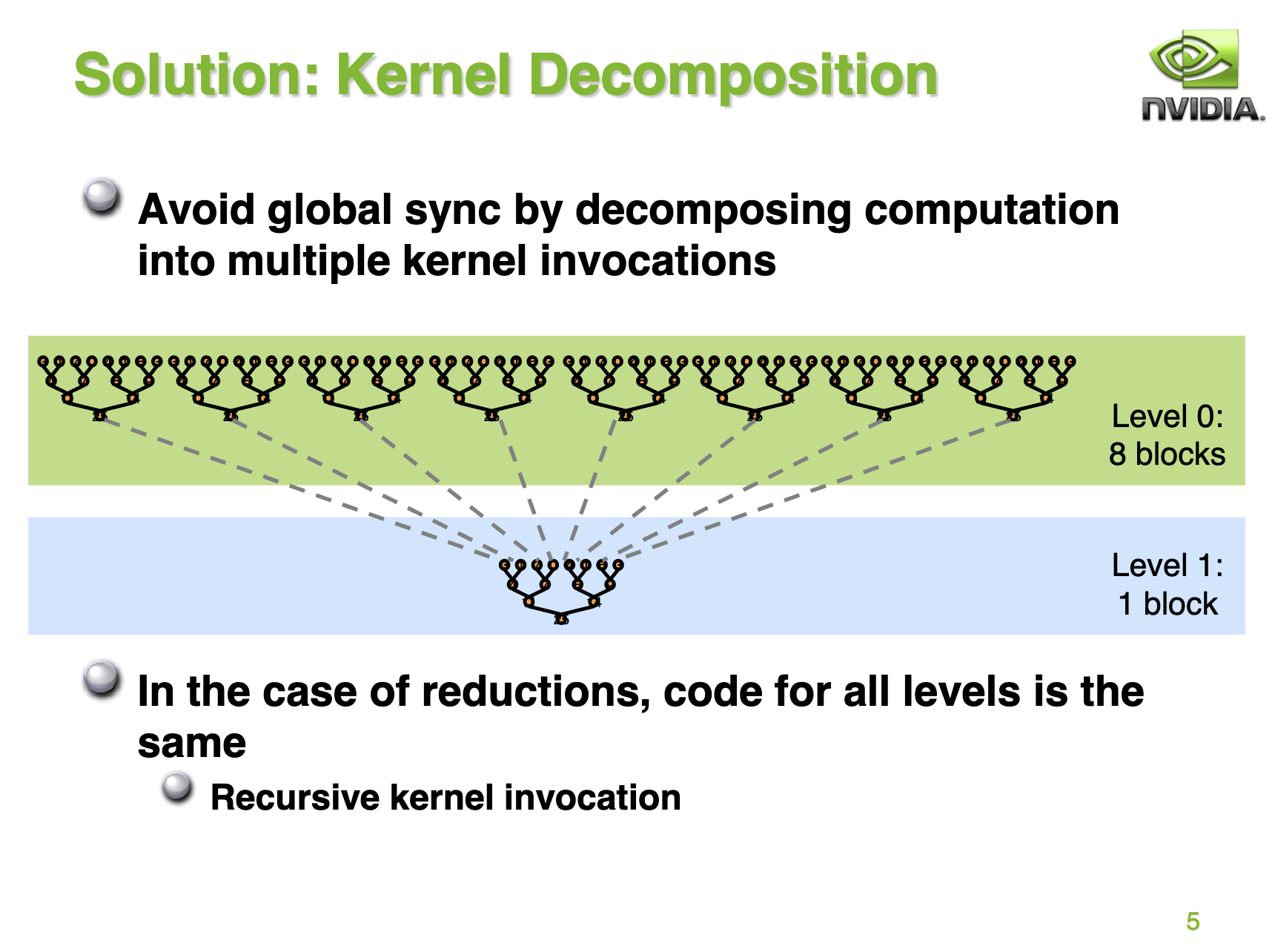
在问题介绍一节中的 Reduce 求和图实际上就指出了 BaseLine 的执行方式,我们将以树形图的方式去执行数据累加,最终得到总和。但由于GPU没有针对 global memory 的同步操作,所以博客指出我们可以通过将计算分成多个阶段的方式来避免 global memrory 的操作。如下图所示:
接着 NVIDIA 博客给出了 BaseLine 算法的实现:

这里的 g_idata 表示的是输入数据的指针,而 g_odata 则表示输出数据的指针。然后首先把 global memory 数据 load 到 shared memory 中,接着在 shared memory 中对数据进行 Reduce Sum 操作,最后将 Reduce Sum 的结果写会 global memory 中。
但接下来的这页 PPT 指出了 Baseine 实现的低效之处:

这里指出了2个问题,一个是warp divergent,另一个是取模这个操作很昂贵。这里的warp divergent 指的是对于启动 BaseLine Kernel 的一个 block 的 warp 来说,它所有的 thread 执行的指令都是一样的,而 BaseLine Kernel 里面存在 if 分支语句,一个 warp 的32个 thread 都会执行存在的所有分支,但只会保留满足条件的分支产生的结果。
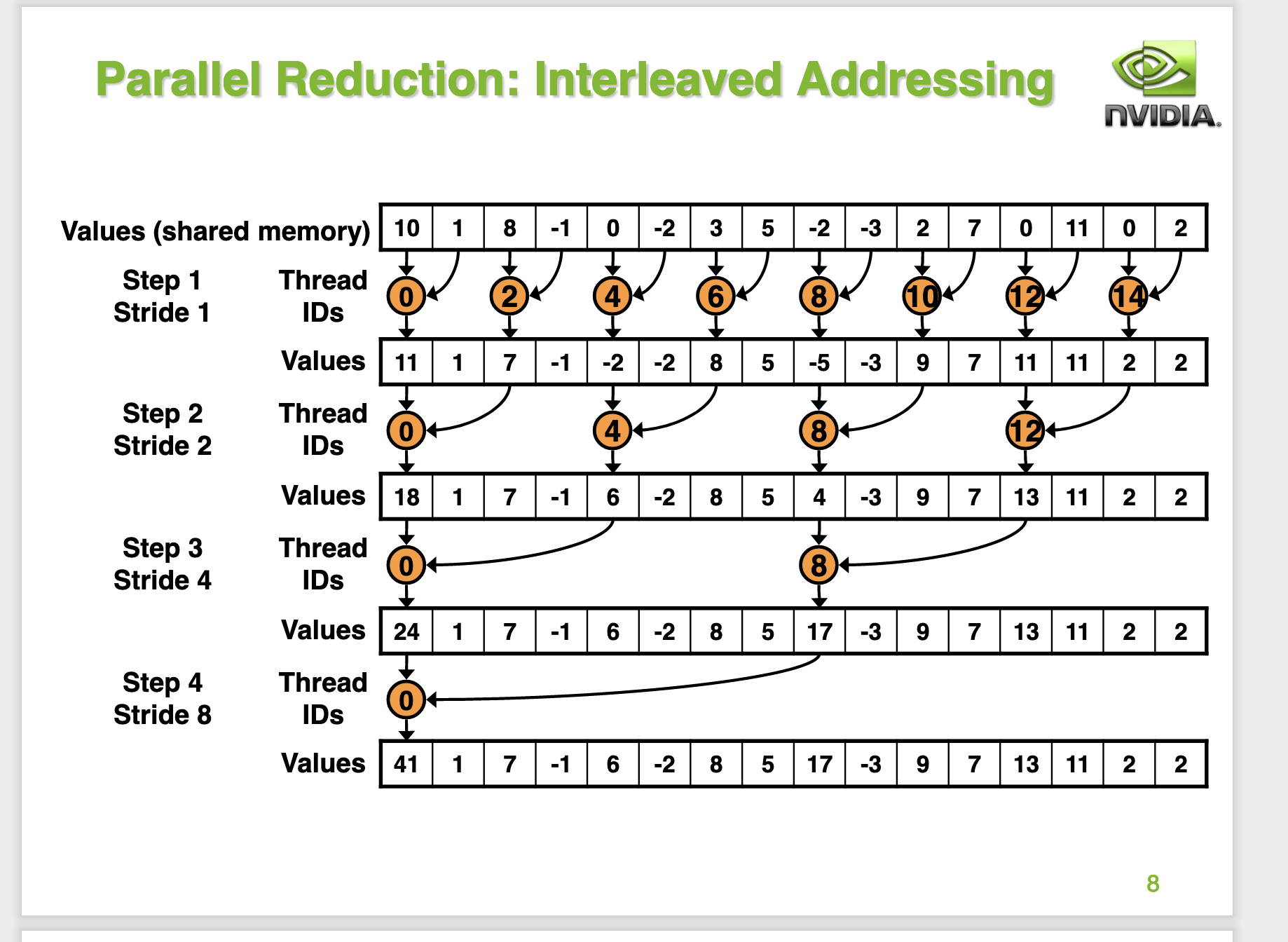
我们可以在第8页PPT里面看到,对于每一次迭代都会有两个分支,分别是有竖直的黑色箭头指向的小方块(有效计算的线程)以及其它没有箭头指向的方块,所以每一轮迭代实际上都有大量线程是空闲的,无法最大程度的利用GPU硬件。
从这个PPT我们可以计算出,对于一个 Block 来说要完成Reduce Sum,一共有8次迭代,并且每次迭代都会产生warp divergent。
接下来我们先把 BaseLine 的代码抄一下,然后我们设定好一个 GridSize 和 BlockSize 启动 Kernel 测试下性能。在PPT的代码基础上,我么补充一下内存申请以及启动 Kernel 的代码。
#include <cuda.h>
#include <cuda_runtime.h>
#include <time.h>
#define N 32*1024*1024
#define BLOCK_SIZE 256
__global__ void reduce_v0(float *g_idata,float *g_odata){
__shared__ float sdata[BLOCK_SIZE];
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*blockDim.x + threadIdx.x;
sdata[tid] = g_idata[i];
__syncthreads();
// do reduction in shared mem
for(unsigned int s=1; s < blockDim.x; s *= 2) {
if (tid % (2*s) == 0) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
int main() {
float *input_host = (float*)malloc(N*sizeof(float));
float *input_device;
cudaMalloc((void **)&input_device, N*sizeof(float));
for (int i = 0; i < N; i++) input_host[i] = 2.0;
cudaMemcpy(input_device, input_host, N*sizeof(float), cudaMemcpyHostToDevice);
int32_t block_num = (N + BLOCK_SIZE - 1) / BLOCK_SIZE;
float *output_host = (float*)malloc((N / BLOCK_SIZE) * sizeof(float));
float *output_device;
cudaMalloc((void **)&output_device, (N / BLOCK_SIZE) * sizeof(float));
dim3 grid(N / BLOCK_SIZE, 1);
dim3 block(BLOCK_SIZE, 1);
reduce_v0<<<grid, block>>>(input_device, output_device);
cudaMemcpy(output_device, output_host, block_num * sizeof(float), cudaMemcpyDeviceToHost);
return 0;
}
我们这里设定输入数据的长度是 32*1024*1024 个float数 (也就是PPT中的4M数据),然后每个 block 的线程数我们设定为 256 (BLOCK_SIZE = 256, 也就是一个 Block 有 8 个 warp)并且每个 Block 要计算的元素个数也是 256 个,然后当一个 Block 的计算完成后对应一个输出元素。所以对于输出数据来说,它的长度是输入数据长度处以 256 。我们代入 kernel 加载需要的 GridSize(N / 256) 和 BlockSize(256) 再来理解一下 BaseLine 的 Reduce kernel。
首先,第 tid 号线程会把 global memroy 的第 i 号数据取出来,然后塞到 shared memroy 中。接下来针对已经存储到 shared memroy 中的 256 个元素展开多轮迭代,迭代的过程如 PPT 的第8页所示。完成迭代过程之后,这个 block 负责的256个元素的和都放到了 shared memrory 的0号位置,我们只需要将这个元素写回global memory就做完了。
接下来我们使用 nvcc -o bin/reduce_v0 reduce_v0_baseline.cu 编译一下这个源文件,并且使用nsight compute去profile一下。
性能和带宽的测试情况如下:
| 优化手段 | 耗时(us) | 带宽利用率 | 加速比 |
|---|---|---|---|
| reduce_baseline | 990.66us | 39.57% | ~ |
优化手段1: 交错寻址(Interleaved Addressing)¶
接下来直接NVIDIA的PPT给出了优化手段1:

这里是直接针对 BaseLine 中的 warp divergent 问题进行优化,通过调整BaseLine中的分支判断代码使得更多的线程可以走到同一个分支里面,降低迭代过程中的线程资源浪费。具体做法就是把 if (tid % (2*s) == 0) 替换成 strided index的方式也就是int index = 2 * s * tid,然后判断 index 是否在当前的 block 内。虽然这份优化后的代码没有完全消除if语句,但是我们可以来计算一下这个版本的代码在8次迭代中产生 warp divergent 的次数。对于第一次迭代,0-3号warp的index都是满足
我们继续抄一下这个代码然后进行profile一下。
#define N 32*1024*1024
#define BLOCK_SIZE 256
__global__ void reduce_v1(float *g_idata,float *g_odata){
__shared__ float sdata[BLOCK_SIZE];
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*blockDim.x + threadIdx.x;
sdata[tid] = g_idata[i];
__syncthreads();
// do reduction in shared mem
for(unsigned int s=1; s < blockDim.x; s *= 2) {
// if (tid % (2*s) == 0) {
// sdata[tid] += sdata[tid + s];
// }
int index = 2 * s * tid;
if (index < blockDim.x) {
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
性能和带宽的测试情况如下:
| 优化手段 | 耗时(us) | 带宽利用率 | 加速比 |
|---|---|---|---|
| reduce_baseline | 990.66us | 39.57% | ~ |
| reduce_v1_interleaved_addressing | 479.58us | 81.74% | 2.06 |
可以看到这个优化还是很有效的,相比于BaseLine的性能有2倍的提升。
优化手段2: 解决Bank Conflict¶
对于 reduce_v1_interleaved_addressing 来说,它最大的问题时产生了 Bank Conflict。使用 shared memory 有以下几个好处:
- 更低的延迟(20-40倍)
- 更高的带宽(约为15倍)
- 更细的访问粒度,shared memory是4byte,global memory是32byte
但是 shared memrory 的使用量存在一定上限,而使用 shared memory 要特别小心 bank conflict 。实际上,shared memory 是由 32 个 bank 组成的,如下面这张 PPT 所示:

而 bank conflict 指的就是在一个 warp 内,有2个或者以上的线程访问了同一个 bank 上不同地址的内存。比如:
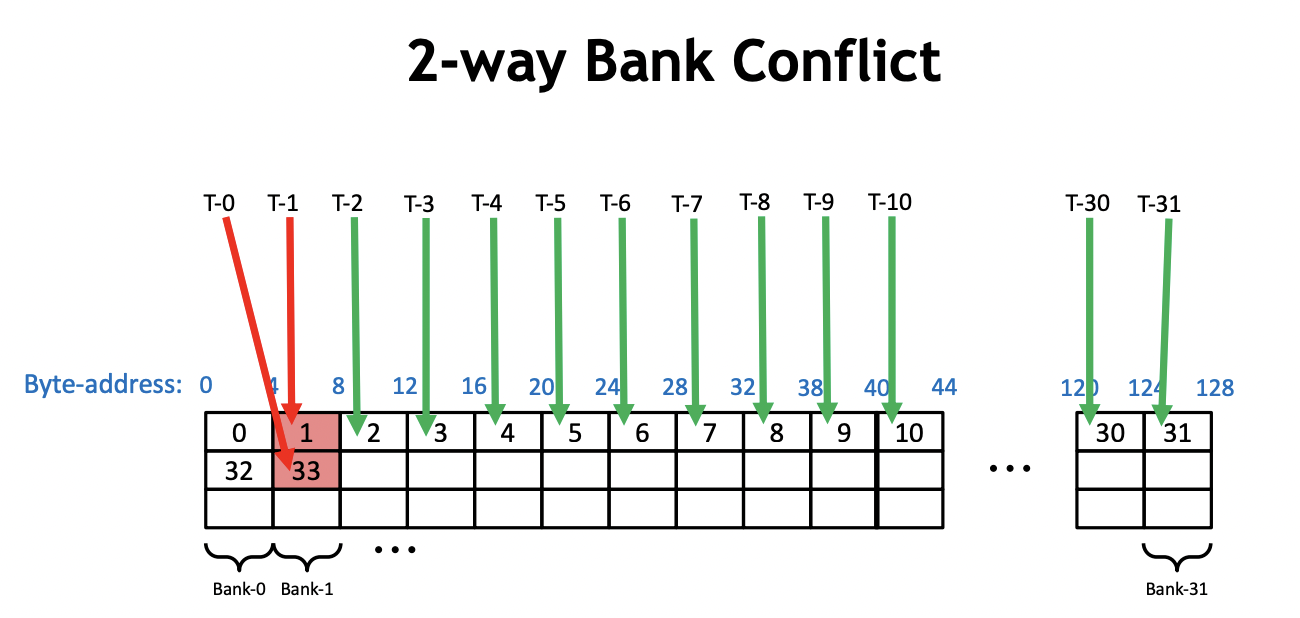
在 reduce_v1_interleaved_addressing 的 Kernel 中,我们以0号warp为例。在第一次迭代中,0号线程需要去加载 shared memory 的0号和1号地址,然后写回0号地址。此时,0号 warp 的16号线程需要加载 shared memory 的32和33号地址并且写回32号地址。所以,我们在一个warp内同时访问了一个bank的不同内存地址,发生了2路的 Bank Conflict,如上图所示。类似地,在第二次迭代过程中,0号warp的0号线程会加载0号和2号地址并写回0号地址,然后0号warp的8号线程需要加载 shared memory 的32号和34号地址(2*2*8=32, 32+2=34)并写回32号线程,16号线程会加载64号和68号地址,24号线程会加载96号和100号地址。然后0,32,64,96号地址都在一个bank中,所以这里产生了4路的 Bank Conflict 。以此类推,下一次迭代会产生8路的 Bank Conflict,使得整个 Kernel 一直受到 Bank Conflict 的影响。
接下来PPT为我们指出了避免Bank Conflict的方案,那就是把循环迭代的顺序修改一下:
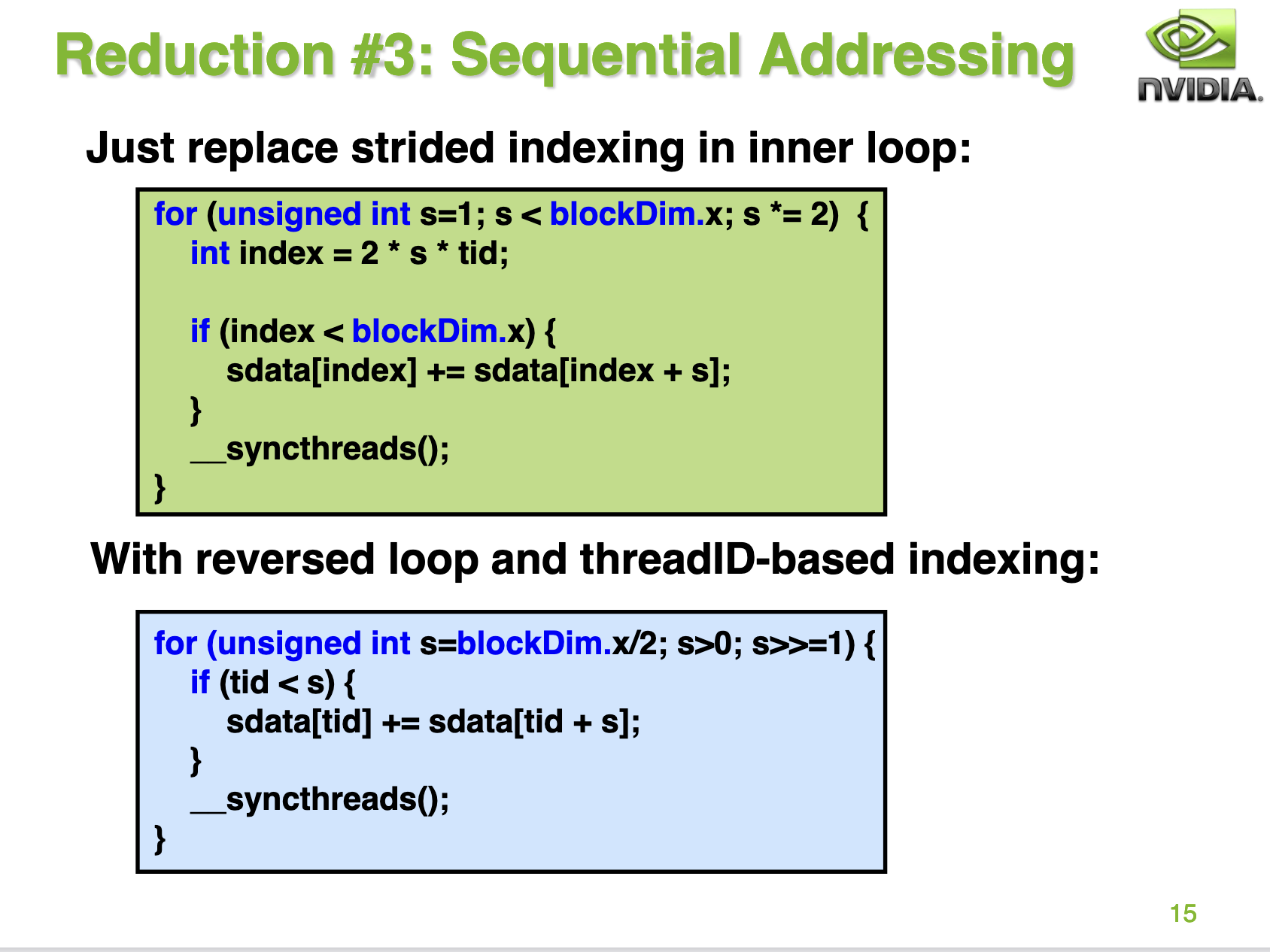
为啥这样就可以避免Bank Conflict呢?我们继续分析一下0号wap的线程,首先在第一轮迭代中,0号线程现在需要加载0号以及128号地址,并且写回0号地址。而1号线程需要加载1号和129号地址并写回1号地址。2号线程需要加载2号和130号地址并写回2号地址。我们可以发现第0个warp的线程在第一轮迭代中刚好加载shared memory的一行数据,不会产生 bank conflict。接下来对于第2次迭代,0号warp仍然也是刚好加载shared memory的一行数据,不会产生 bank conflict 。对于第三次迭代,也是这样。而对于第4次迭代,0号线程load shared memory 0号和16号地址,而这个时候16号线程什么都不干被跳过了,因为s=16,16-31号线程不满足if的条件。整体过程如PPT的14页:
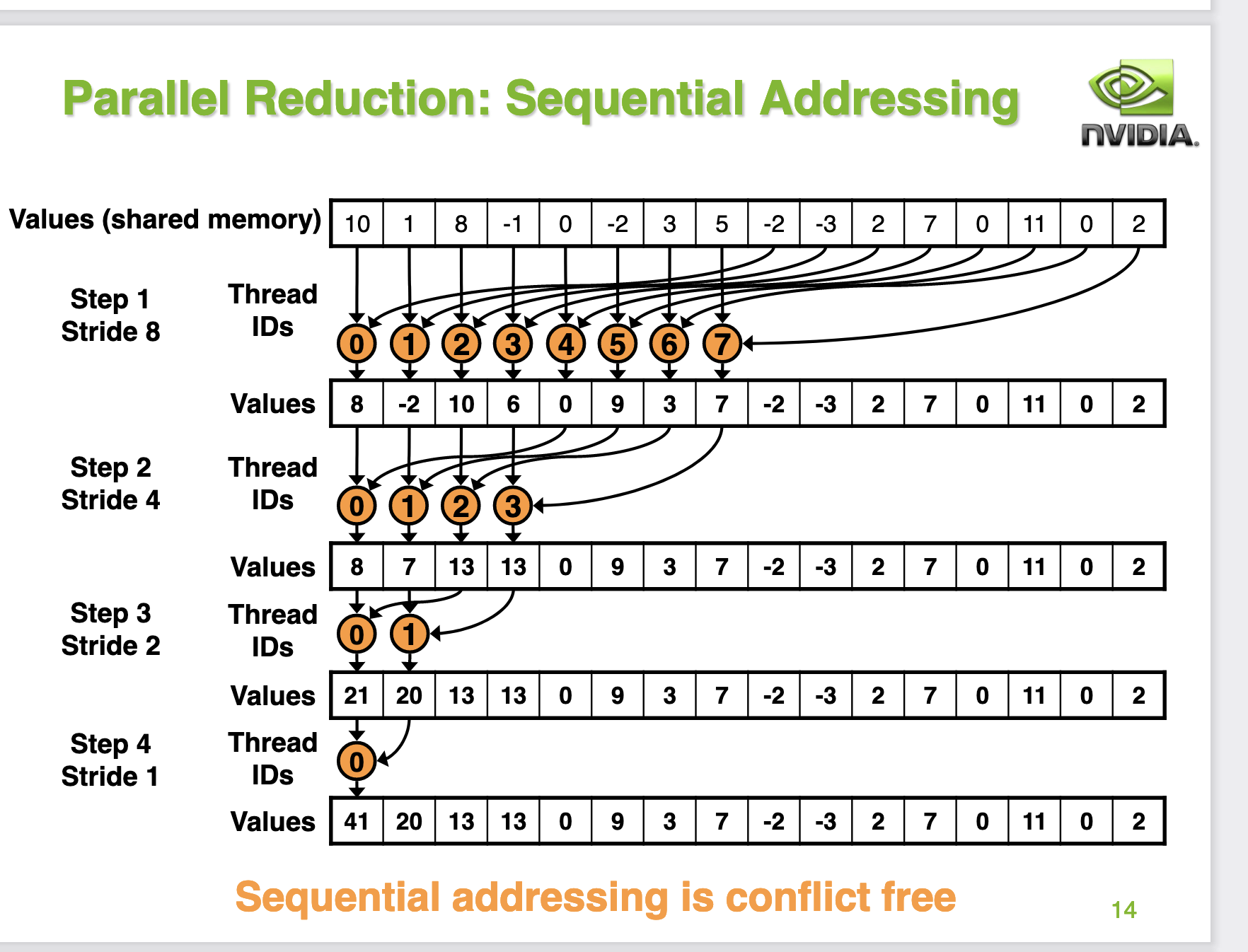
接下来我们修改下代码再profile一下:
#define N 32*1024*1024
#define BLOCK_SIZE 256
__global__ void reduce_v2(float *g_idata,float *g_odata){
__shared__ float sdata[BLOCK_SIZE];
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*blockDim.x + threadIdx.x;
sdata[tid] = g_idata[i];
__syncthreads();
// do reduction in shared mem
for(unsigned int s=blockDim.x/2; s>0; s >>= 1) {
if (tid < s){
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
性能和带宽的测试情况如下:
| 优化手段 | 耗时(us) | 带宽利用率 | 加速比 |
|---|---|---|---|
| reduce_baseline | 990.66us | 39.57% | ~ |
| reduce_v1_interleaved_addressing | 479.58us | 81.74% | 2.06 |
| reduce_v2_bank_conflict_free | 462.02us | 84.81% | 2.144 |
可以看到相比于优化版本1性能和带宽又提升了一些。
优化手段3: 解决 Idle 线程¶
接下来PPT 17指出,reduce_v2_bank_conflict_free 的 kernel 浪费了大量的线程。对于第一轮迭代只有128个线程在工作,而第二轮迭代只有64个线程工作,第三轮迭代只有32和线程工作,以此类推,在每一轮迭代中都有大量的线程是空闲的。

那么可以如何避免这种情况呢?PPT 18给了一个解决方法:

这里的意思就是我们让每一轮迭代的空闲的线程也强行做一点工作,除了从global memory中取数之外再额外做一次加法。但需要注意的是,为了实现这个我们需要把block的数量调成之前的一半,因为这个Kernel现在每次需要管512个元素了。我们继续组织下代码并profile一下:
#define N 32*1024*1024
#define BLOCK_SIZE 256
__global__ void reduce_v3(float *g_idata,float *g_odata){
__shared__ float sdata[BLOCK_SIZE];
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;
sdata[tid] = g_idata[i] + g_idata[i + blockDim.x];
__syncthreads();
// do reduction in shared mem
for(unsigned int s=blockDim.x/2; s>0; s >>= 1) {
if (tid < s){
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
性能和带宽的测试情况如下:
| 优化手段 | 耗时(us) | 带宽利用率 | 加速比 |
|---|---|---|---|
| reduce_baseline | 990.66us | 39.57% | ~ |
| reduce_v1_interleaved_addressing | 479.58us | 81.74% | 2.06 |
| reduce_v2_bank_conflict_free | 462.02us | 84.81% | 2.144 |
| reduce_v3_idle_threads_free | 244.16us | 83.16% | 4.057 |
优化手段4: 展开最后一个warp¶
首先来看 PPT 的第20页:

这里的意思是,对于 reduce_v3_idle_threads_free 这个 kernel 来说,它的带宽相比于理论带宽还差得比较远,因为 Reduce 操作并不是算术密集型的算子。因此,一个可能的瓶颈是指令的开销。这里说的指令不是加载,存储或者给计算核心用的辅算术指令。换句话说,这里的指令就是指地址算术指令和循环的开销。
接下来 PPT 21指出了减少指令开销的优化方法:

这里的意思是当reduce_v3_idle_threads_free kernel里面的s<=32时,此时的block中只有一个warp0在干活时,但线程还在进行同步操作。这一条语句造成了极大的指令浪费。由于一个warp的32个线程都是在同一个simd单元上,天然保持了同步的状态,所以当s<=32时,也即只有一个warp在工作时,完全可以把__syncthreads()这条同步语句去掉,使用手动展开的方式来代替。具体做法就是:

注意 这里的warpReduce函数的参数使用了一个volatile修饰符号,volatile的中文意思是“易变的,不稳定的”,对于用volatile修饰的变量,编译器对访问该变量的代码不再优化,总是从它所在的内存读取数据。对于这个例子,如果不使用volatile,对于一个线程来说(假设线程ID就是tid),它的s_data[tid]可能会被缓存在寄存器里面,且在某个时刻寄存器和shared memory里面s_data[tid]的数值还是不同的。当另外一个线程读取s_data[tid]做加法的时候,也许直接就从shared memory里面读取了旧的数值,从而导致了错误的结果。详情请参考:https://stackoverflow.com/questions/21205471/cuda-in-warp-reduction-and-volatile-keyword?noredirect=1&lq=1
我们继续整理一下代码并profile一下:
__device__ void warpReduce(volatile float* cache, unsigned int tid){
cache[tid]+=cache[tid+32];
cache[tid]+=cache[tid+16];
cache[tid]+=cache[tid+8];
cache[tid]+=cache[tid+4];
cache[tid]+=cache[tid+2];
cache[tid]+=cache[tid+1];
}
__global__ void reduce_v4(float *g_idata,float *g_odata){
__shared__ float sdata[BLOCK_SIZE];
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;
sdata[tid] = g_idata[i] + g_idata[i + blockDim.x];
__syncthreads();
// do reduction in shared mem
for(unsigned int s=blockDim.x/2; s>32; s >>= 1) {
if (tid < s){
sdata[tid] += sdata[tid + s];
}
__syncthreads();
}
// write result for this block to global mem
if (tid < 32) warpReduce(sdata, tid);
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
性能和带宽的测试情况如下:
| 优化手段 | 耗时(us) | 带宽利用率 | 加速比 |
|---|---|---|---|
| reduce_baseline | 990.66us | 39.57% | ~ |
| reduce_v1_interleaved_addressing | 479.58us | 81.74% | 2.06 |
| reduce_v2_bank_conflict_free | 462.02us | 84.81% | 2.144 |
| reduce_v3_idle_threads_free | 244.16us | 83.16% | 4.057 |
| reduce_v4_unroll_last_warp | 167.10us | 54.10% | 5.928 |
这个地方我目前是有疑问的,nvidia的ppt指出这个kernel会继续提升性能和带宽,但是在我实测的时候发现性能确实继续提升了,但是带宽的利用率却下降了,目前想不清楚这个原因是什么?这里唯一的区别就是我使用的GPU是 A100-PCIE-40GB,而nvidia gpu上使用的gpu是 G80 GPU 。欢迎大佬评论区指点。

优化手段5: 完全展开循环¶
在 reduce_v4_unroll_last_warp kernel 的基础上就很难再继续优化了,但为了极致的性能NVIDIA的PPT上给出了对for循环进行完全展开的方案。

这种方案的实现如下:
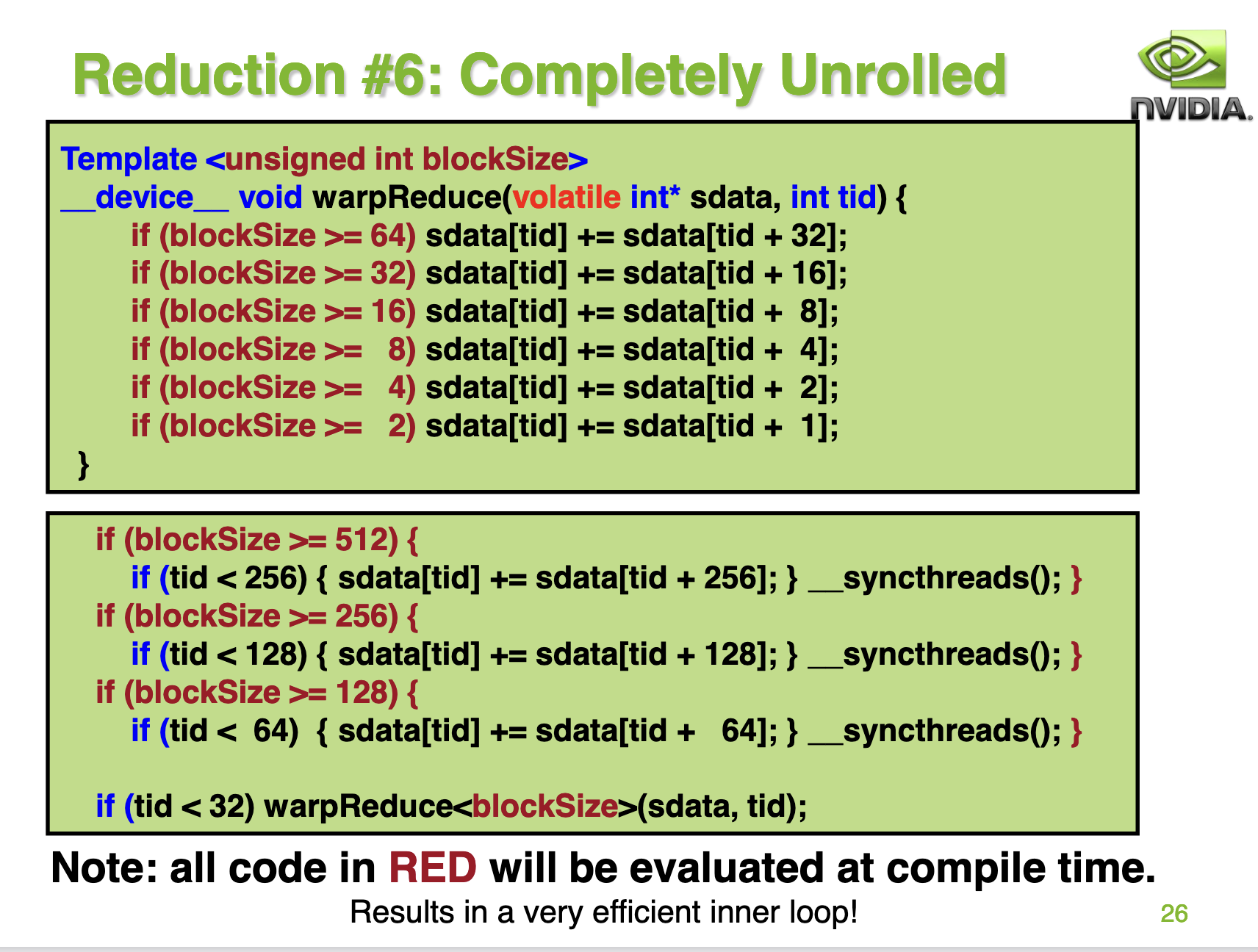
kernel的代码实现如下:
template <unsigned int blockSize>
__device__ void warpReduce(volatile float* cache,int tid){
if(blockSize >= 64)cache[tid]+=cache[tid+32];
if(blockSize >= 32)cache[tid]+=cache[tid+16];
if(blockSize >= 16)cache[tid]+=cache[tid+8];
if(blockSize >= 8)cache[tid]+=cache[tid+4];
if(blockSize >= 4)cache[tid]+=cache[tid+2];
if(blockSize >= 2)cache[tid]+=cache[tid+1];
}
template <unsigned int blockSize>
__global__ void reduce_v5(float *g_idata,float *g_odata){
__shared__ float sdata[BLOCK_SIZE];
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockDim.x*2) + threadIdx.x;
sdata[tid] = g_idata[i] + g_idata[i + blockDim.x];
__syncthreads();
// do reduction in shared mem
if(blockSize>=512){
if(tid<256){
sdata[tid]+=sdata[tid+256];
}
__syncthreads();
}
if(blockSize>=256){
if(tid<128){
sdata[tid]+=sdata[tid+128];
}
__syncthreads();
}
if(blockSize>=128){
if(tid<64){
sdata[tid]+=sdata[tid+64];
}
__syncthreads();
}
// write result for this block to global mem
if(tid<32)warpReduce<blockSize>(sdata,tid);
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
性能和带宽的测试情况如下:
| 优化手段 | 耗时(us) | 带宽利用率 | 加速比 |
|---|---|---|---|
| reduce_baseline | 990.66us | 39.57% | ~ |
| reduce_v1_interleaved_addressing | 479.58us | 81.74% | 2.06 |
| reduce_v2_bank_conflict_free | 462.02us | 84.81% | 2.144 |
| reduce_v3_idle_threads_free | 244.16us | 83.16% | 4.057 |
| reduce_v4_unroll_last_warp | 167.10us | 54.10% | 5.928 |
| reduce_v5_completely_unroll | 158.78us | 56.94% | 6.239 |
优化手段6: 调节BlockSize和GridSize¶
PPT的第31页为我们展示了最后一个优化技巧:

这里的意思就是我们还可以通过调整GridSize和BlockSize的方式获得更好的性能收益,也就是说一个线程负责更多的元素计算。对应到代码的修改就是:

这里再贴一下kernel的代码:
template <unsigned int blockSize>
__device__ void warpReduce(volatile float* cache,int tid){
if(blockSize >= 64)cache[tid]+=cache[tid+32];
if(blockSize >= 32)cache[tid]+=cache[tid+16];
if(blockSize >= 16)cache[tid]+=cache[tid+8];
if(blockSize >= 8)cache[tid]+=cache[tid+4];
if(blockSize >= 4)cache[tid]+=cache[tid+2];
if(blockSize >= 2)cache[tid]+=cache[tid+1];
}
template <unsigned int blockSize, int NUM_PER_THREAD>
__global__ void reduce_v6(float *g_idata,float *g_odata){
__shared__ float sdata[BLOCK_SIZE];
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x*(blockDim.x * NUM_PER_THREAD) + threadIdx.x;
sdata[tid] = 0;
#pragma unroll
for(int iter=0; iter<NUM_PER_THREAD; iter++){
sdata[tid] += g_idata[i+iter*blockSize];
}
__syncthreads();
// do reduction in shared mem
if(blockSize>=512){
if(tid<256){
sdata[tid]+=sdata[tid+256];
}
__syncthreads();
}
if(blockSize>=256){
if(tid<128){
sdata[tid]+=sdata[tid+128];
}
__syncthreads();
}
if(blockSize>=128){
if(tid<64){
sdata[tid]+=sdata[tid+64];
}
__syncthreads();
}
// write result for this block to global mem
if(tid<32)warpReduce<blockSize>(sdata,tid);
if (tid == 0) g_odata[blockIdx.x] = sdata[0];
}
int main() {
float *input_host = (float*)malloc(N*sizeof(float));
float *input_device;
cudaMalloc((void **)&input_device, N*sizeof(float));
for (int i = 0; i < N; i++) input_host[i] = 2.0;
cudaMemcpy(input_device, input_host, N*sizeof(float), cudaMemcpyHostToDevice);
const int block_num = 1024;
const int NUM_PER_BLOCK = N / block_num;
const int NUM_PER_THREAD = NUM_PER_BLOCK / BLOCK_SIZE;
float *output_host = (float*)malloc((block_num) * sizeof(float));
float *output_device;
cudaMalloc((void **)&output_device, (block_num) * sizeof(float));
dim3 grid(block_num, 1);
dim3 block(BLOCK_SIZE, 1);
reduce_v6<BLOCK_SIZE ,NUM_PER_THREAD><<<grid, block>>>(input_device, output_device);
cudaMemcpy(output_device, output_host, block_num * sizeof(float), cudaMemcpyDeviceToHost);
return 0;
}
profile结果:

性能和带宽的测试情况如下:
| 优化手段 | 耗时(us) | 带宽利用率 | 加速比 |
|---|---|---|---|
| reduce_baseline | 990.66us | 39.57% | ~ |
| reduce_v1_interleaved_addressing | 479.58us | 81.74% | 2.06 |
| reduce_v2_bank_conflict_free | 462.02us | 84.81% | 2.144 |
| reduce_v3_idle_threads_free | 244.16us | 83.16% | 4.057 |
| reduce_v4_unroll_last_warp | 167.10us | 54.10% | 5.928 |
| reduce_v5_completely_unroll | 158.78us | 56.94% | 6.239 |
| reduce_v6_multi_add | 105.47us | 85.75% | 9.392 |
在把block_num从65536调整到1024之后,无论是性能还是带宽都达到了最强,相比于最初的BaseLine加速了9.4倍。
PyTorch Block Reduce¶
接下来我们介绍一下 PyTorch 的 Block Reduce 方案,https://zhuanlan.zhihu.com/p/584936904 这篇文章介绍得比较详细。我在 https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/reduce/pytorch_block_reduce.cu 这里也整理一些方便理解的注释。
总的来说就是利用 warp 原语 __shfl_down_sync 来对一个warp内的val进行规约求和。可以单独编译的.cu文件实现在:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/reduce/reduce_v7_shfl_down_sync.cu 。我们贴一下c++的实现:
#define N 32*1024*1024
#define BLOCK_SIZE 256
#define WARP_SIZE 32
template <unsigned int blockSize>
__device__ __forceinline__ float warpReduceSum(float sum) {
if (blockSize >= 32)sum += __shfl_down_sync(0xffffffff, sum, 16); // 0-16, 1-17, 2-18, etc.
if (blockSize >= 16)sum += __shfl_down_sync(0xffffffff, sum, 8);// 0-8, 1-9, 2-10, etc.
if (blockSize >= 8)sum += __shfl_down_sync(0xffffffff, sum, 4);// 0-4, 1-5, 2-6, etc.
if (blockSize >= 4)sum += __shfl_down_sync(0xffffffff, sum, 2);// 0-2, 1-3, 4-6, 5-7, etc.
if (blockSize >= 2)sum += __shfl_down_sync(0xffffffff, sum, 1);// 0-1, 2-3, 4-5, etc.
return sum;
}
template <unsigned int blockSize, int NUM_PER_THREAD>
__global__ void reduce7(float *g_idata,float *g_odata, unsigned int n){
float sum = 0;
// each thread loads one element from global to shared mem
unsigned int tid = threadIdx.x;
unsigned int i = blockIdx.x * (blockSize * NUM_PER_THREAD) + threadIdx.x;
#pragma unroll
for(int iter=0; iter<NUM_PER_THREAD; iter++){
sum += g_idata[i+iter*blockSize];
}
// Shared mem for partial sums (one per warp in the block)
static __shared__ float warpLevelSums[WARP_SIZE];
const int laneId = threadIdx.x % WARP_SIZE;
const int warpId = threadIdx.x / WARP_SIZE;
sum = warpReduceSum<blockSize>(sum);
if(laneId == 0 )warpLevelSums[warpId] = sum;
__syncthreads();
// read from shared memory only if that warp existed
sum = (threadIdx.x < blockDim.x / WARP_SIZE) ? warpLevelSums[laneId] : 0;
// Final reduce using first warp
if (warpId == 0) sum = warpReduceSum<blockSize/WARP_SIZE>(sum);
// write result for this block to global mem
if (tid == 0) g_odata[blockIdx.x] = sum;
}
profile结果:
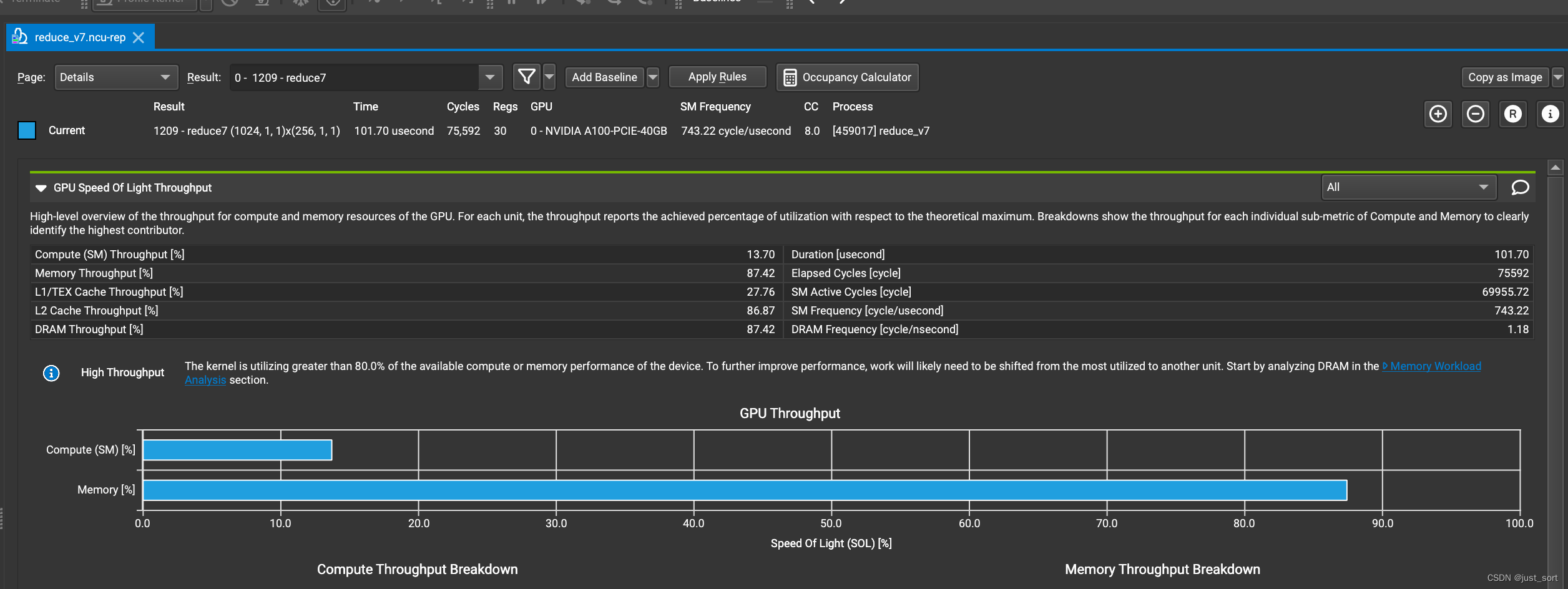
性能和带宽的测试情况如下:
| 优化手段 | 耗时(us) | 带宽利用率 | 加速比 |
|---|---|---|---|
| reduce_baseline | 990.66us | 39.57% | ~ |
| reduce_v1_interleaved_addressing | 479.58us | 81.74% | 2.06 |
| reduce_v2_bank_conflict_free | 462.02us | 84.81% | 2.144 |
| reduce_v3_idle_threads_free | 244.16us | 83.16% | 4.057 |
| reduce_v4_unroll_last_warp | 167.10us | 54.10% | 5.928 |
| reduce_v5_completely_unroll | 158.78us | 56.94% | 6.239 |
| reduce_v6_multi_add | 105.47us | 85.75% | 9.392 |
| reduce_v7_shfl_down_sync | 101.7us | 87.42% | 9.74 |
可以看到基于 warp 原语 __shfl_down_sync 进行优化之后,带宽利用率可以达到 87.42% ,并且耗时也是最低的。
PyTorch BlockReduce + Pack + 选择更更合理的 GridSize¶
最后我们在 reduce_v7_shfl_down_sync 的基础上加上数据 Pack,并且使用 OneFlow 的自动选择 GridSize (Block数量)的函数来计算 GridSize 。代码实现如下:
#define PackSize 4
#define kWarpSize 32
#define N 32 * 1024 * 1024
constexpr int BLOCK_SIZE = 256;
constexpr int kBlockSize = 256;
constexpr int kNumWaves = 1;
int64_t GetNumBlocks(int64_t n) {
int dev;
{
cudaError_t err = cudaGetDevice(&dev);
if (err != cudaSuccess) { return err; }
}
int sm_count;
{
cudaError_t err = cudaDeviceGetAttribute(&sm_count, cudaDevAttrMultiProcessorCount, dev);
if (err != cudaSuccess) { return err; }
}
int tpm;
{
cudaError_t err = cudaDeviceGetAttribute(&tpm, cudaDevAttrMaxThreadsPerMultiProcessor, dev);
if (err != cudaSuccess) { return err; }
}
int64_t num_blocks = std::max<int64_t>(1, std::min<int64_t>((n + kBlockSize - 1) / kBlockSize,
sm_count * tpm / kBlockSize * kNumWaves));
return num_blocks;
}
template<typename T, int pack_size>
struct alignas(sizeof(T) * pack_size) Packed {
__device__ Packed(T val){
#pragma unroll
for(int i = 0; i < pack_size; i++){
elem[i] = val;
}
}
__device__ Packed() {
// do nothing
}
union {
T elem[pack_size];
};
__device__ void operator+=(Packed<T, pack_size> packA){
#pragma unroll
for(int i = 0; i < pack_size; i++){
elem[i] += packA.elem[i];
}
}
};
template<typename T, int pack_size>
__device__ T PackReduce(Packed<T, pack_size> pack){
T res = 0.0;
#pragma unroll
for(int i = 0; i < pack_size; i++){
res += pack.elem[i];
}
return res;
}
template<typename T>
__device__ T warpReduceSum(T val){
for(int lane_mask = 16; lane_mask > 0; lane_mask /=2){
val += __shfl_down_sync(0xffffffff, val, lane_mask);
}
return val;
}
__global__ void reduce_v8(float *g_idata,float *g_odata, unsigned int n){
// each thread loads one element from global to shared mem
unsigned int i = blockDim.x * blockIdx.x + threadIdx.x;
Packed<float, PackSize> sum_pack(0.0);
Packed<float, PackSize> load_pack(0.0);
const auto* pack_ptr = reinterpret_cast<const Packed<float, PackSize>*>(g_idata);
for(int32_t linear_index = i; linear_index < n / PackSize; linear_index+=blockDim.x * gridDim.x){
Packed<float, PackSize> g_idata_load = pack_ptr[linear_index];
sum_pack += g_idata_load;
}
float PackReduceVal = PackReduce<float, PackSize>(sum_pack);
// Shared mem for partial sums (one per warp in the block)
static __shared__ float warpLevelSums[kWarpSize];
const int laneId = threadIdx.x % kWarpSize;
const int warpId = threadIdx.x / kWarpSize;
float sum = warpReduceSum<float>(PackReduceVal);
__syncthreads();
if(laneId == 0 )warpLevelSums[warpId] = sum;
__syncthreads();
// read from shared memory only if that warp existed
sum = (threadIdx.x < blockDim.x / kWarpSize) ? warpLevelSums[laneId] : 0;
// Final reduce using first warp
if (warpId == 0) sum = warpReduceSum<float>(sum);
// write result for this block to global mem
if (threadIdx.x == 0) g_odata[blockIdx.x] = sum;
}
profile结果:

性能和带宽的测试情况如下:
| 优化手段 | 耗时(us) | 带宽利用率 | 加速比 |
|---|---|---|---|
| reduce_baseline | 990.66us | 39.57% | ~ |
| reduce_v1_interleaved_addressing | 479.58us | 81.74% | 2.06 |
| reduce_v2_bank_conflict_free | 462.02us | 84.81% | 2.144 |
| reduce_v3_idle_threads_free | 244.16us | 83.16% | 4.057 |
| reduce_v4_unroll_last_warp | 167.10us | 54.10% | 5.928 |
| reduce_v5_completely_unroll | 158.78us | 56.94% | 6.239 |
| reduce_v6_multi_add | 105.47us | 85.75% | 9.392 |
| reduce_v7_shfl_down_sync | 101.7us | 87.42% | 9.74 |
| reduce_v8_shfl_down_sync_pack | 99.71us | 89.76% | 9.935 |
基于 Pack 以及选择更适合硬件的 Block 数量可以继续提升 Reduce Kernel 的带宽和性能。画了个图更直观一点:
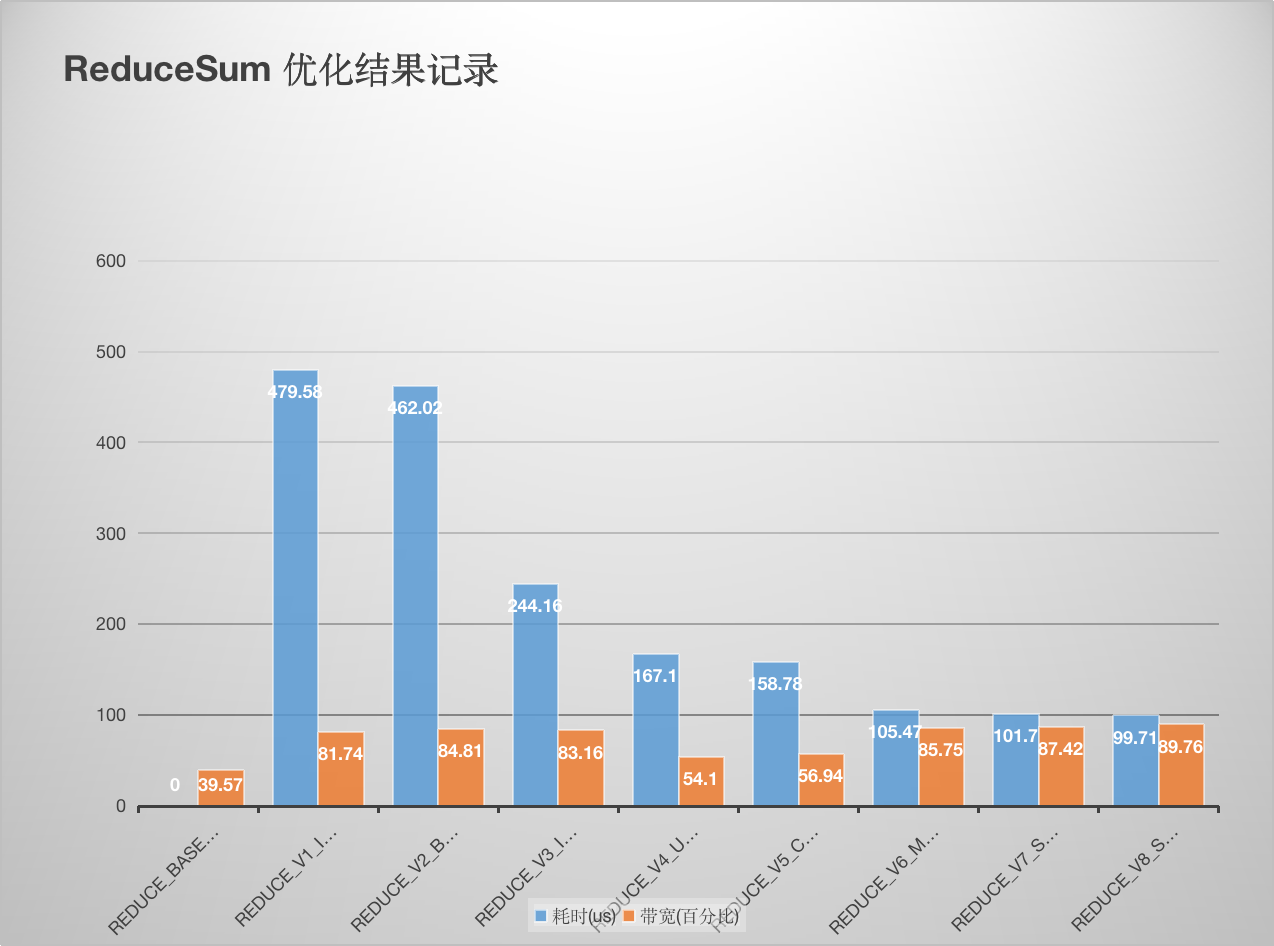
总结¶
我这里的测试结果和nvidia ppt里提供的结果有一些出入,nvidia ppt的34页展示的结果是对于每一种优化相比于前一种无论是性能还是带宽都是稳步提升的。但我这里的测试结果不完全是这样,对于 reduce_v4_unroll_last_warp 和 reduce_v5_completely_unroll 这两个优化,虽然耗时近一步减少但是带宽却降低了,我也还没想清楚原因。欢迎大佬评论区指点。
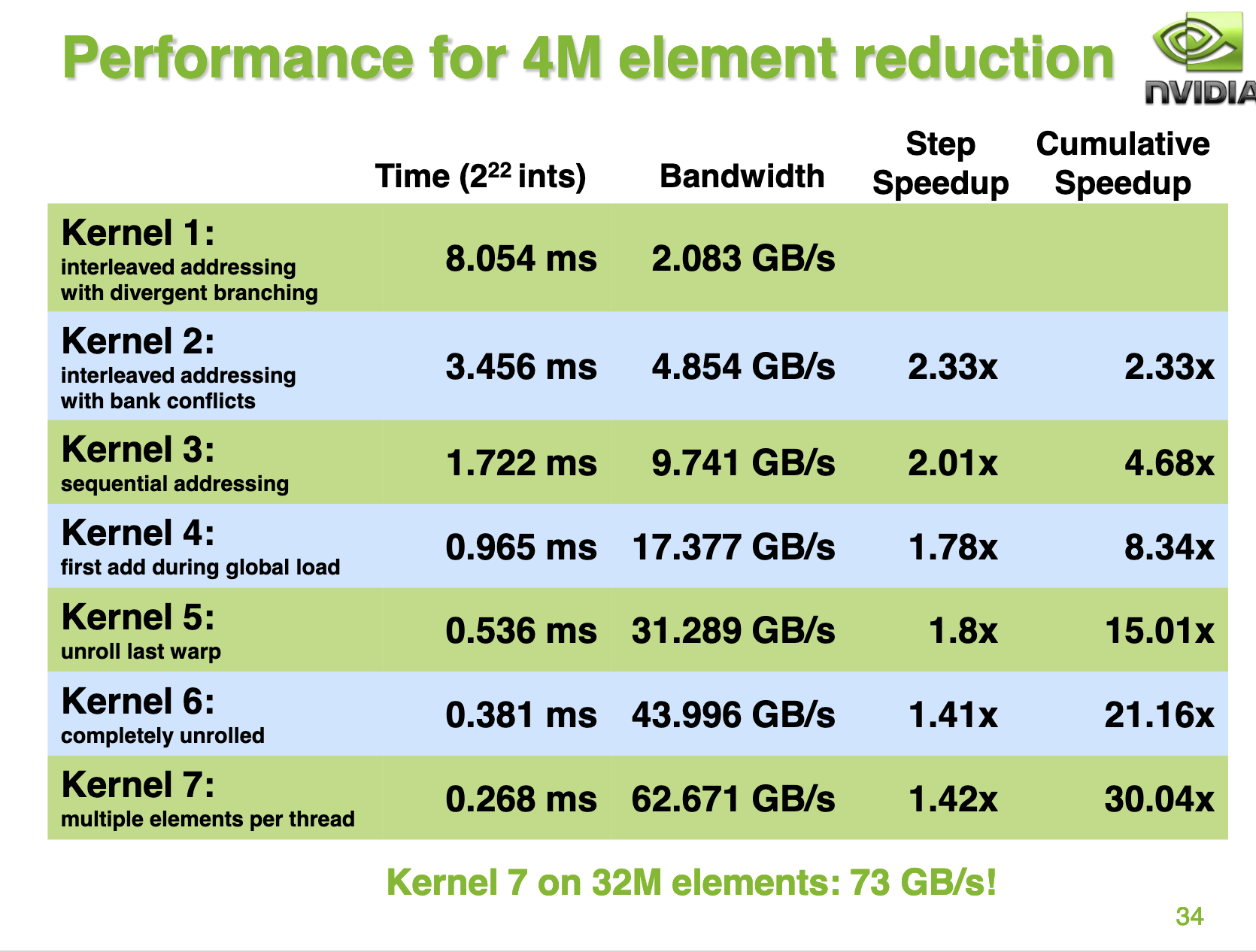
并且最终的Kernel带宽利用率为 73 / 86.4 = 84.5% ,和我在A100上的reduce_v6_multi_add kernel的测试结果基本相当。
后续我再换个gpu试一试,把数据同步到这里:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/reduce/README.md
参考¶
- https://developer.download.nvidia.com/assets/cuda/files/reduction.pdf
- https://zhuanlan.zhihu.com/p/426978026
- https://mp.weixin.qq.com/s/1_ao9xM6Qk3JaavptChXew
- https://zhuanlan.zhihu.com/p/559549740
本文总阅读量次