0x1. 前言¶
在ResNet中(https://github.com/pytorch/vision/blob/main/torchvision/models/resnet.py),关于BatchNorm的调用一共有两种模式,第一种是ReLU接在BN之后:
out = self.bn1(out)
out = self.relu(out)
另外一种模式是残差结构引入的 BNAddReLU 的模式:
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
我们知道在 CUDA 优化中常见的一个技巧是将一些ElementWise的算子融合到之前的计算密集型算子如卷积,矩阵乘等。在OneFlow中针对上述两种情况并且cudnn无法fuse时分别进行了fuse和优化,本篇文章就来解析一下这里的代码实现,体会其中的CUDA优化技巧。这里的源码开源在OneFlow的github仓库:https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/user/kernels/normalization_kernel.cu 。如果本文对你产生了启发,不妨为OneFlow投个star。
0x2. 代码解析¶
0x2.1 CUDNN BatchNorm算子的实现和局限¶
我们先来看一下OneFlow中是如何使用CUDNN库实现BatchNorm算子的。代码见:https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/user/kernels/normalization_kernel.cu#L31-L244 。这段代码中首先实现了一个getCudnnBatchNormMode工具函数:
cudnnBatchNormMode_t getCudnnBatchNormMode(const int64_t dim) {
if (dim == 2) {
return CUDNN_BATCHNORM_PER_ACTIVATION;
} else if (ParseBooleanFromEnv("ONEFLOW_ENABLE_NHWC", false)) {
return CUDNN_BATCHNORM_SPATIAL_PERSISTENT;
} else {
// NOTE(Liang Depeng): The new CUDNN_BATCHNORM_SPATIAL_PERSISTENT mode was
// introduced in CuDNN 7 for performance optimization, but it results in
// accuracy losses in convolution models such as ResNeXt-101 and
// video R(2+1)D. We will fall back to the normal CUDNN_BATCHNORM_SPATIAL
return CUDNN_BATCHNORM_SPATIAL;
}
}
这里的dim表示输入Tensor的维度,比如形状为(1, 3, 224, 224)的输入Tensor,这里的维度就是4。然后这里涉及到三种不同的cudnnBatchNormMode_t,我们看一下CUDNN的文档(https://docs.nvidia.com/deeplearning/cudnn/api/index.html#cudnnBatchNormMode_t):

可以看到 CUDNN_BATCHNORM_PER_ACTIVATION 被用于非卷积层,在OneFlow中只有当输入Tensor的维度为2时才选取这种模式。而CUDNN_BATCHNORM_SPATIAL_PERSISTENT这种模式只有当输入Tensor的数据排布为NHWC方式时才会启用。而对于其它的模式,在OneFlow中一律选取CUDNN_BATCHNORM_SPATIAL模式。
接下来阅读一下 InferDimSizeAndDataFormat 函数:
void InferDimSizeAndDataFormat(const ShapeView& x_shape, const int32_t axis, int32_t* n, int32_t* c,
int32_t* h, int32_t* w, cudnnTensorFormat_t* format) {
if (x_shape.Count(axis + 1) == 1) {
if (axis == 0) {
*n = 1;
*h = 1;
} else {
*n = x_shape.At(0);
*h = x_shape.Count(1, axis);
}
*w = 1;
*c = x_shape.At(axis);
*format = CUDNN_TENSOR_NHWC;
} else {
*n = x_shape.Count(0, axis);
*c = x_shape.At(axis);
*h = x_shape.Count(axis + 1);
*w = 1;
*format = CUDNN_TENSOR_NCHW;
}
}
// 推断和设置cudnn中的Tensor描述符
void InferXYCudnnTensorDesc(const ShapeView& xy_shape, const DataType& data_type,
const int32_t axis, cudnnTensorDescriptor_t xy_desc) {
int32_t n, c, h, w;
cudnnTensorFormat_t format;
// 根据输入Tensor的shape推断format和n, c, h, w
InferDimSizeAndDataFormat(xy_shape, axis, &n, &c, &h, &w, &format);
// 根据上述的推断结果,设置Tensor的描述符
OF_CUDNN_CHECK(
cudnnSetTensor4dDescriptor(xy_desc, format, GetCudnnDataType(data_type), n, c, h, w));
}
// 根据输入Tensor的描述符xy_desc和cudnnBatchNormMode_t模式设置参数的描述符param_desc
void InferParamCudnnTensorDesc(const cudnnTensorDescriptor_t xy_desc, cudnnBatchNormMode_t mode,
cudnnTensorDescriptor_t param_desc) {
OF_CUDNN_CHECK(cudnnDeriveBNTensorDescriptor(param_desc, xy_desc, mode));
}
// 这个类就是完整使用上述的工具函数的工具类,负责推断cudnn BatchNorm接口需要的各种描述信息比如这里的xy_desc_,param_desc_,param_data_type_和param_size_
class CudnnTensorDescHelper final {
public:
OF_DISALLOW_COPY_AND_MOVE(CudnnTensorDescHelper);
CudnnTensorDescHelper(const ShapeView& xy_shape, const DataType& data_type, const int32_t axis,
cudnnBatchNormMode_t mode) {
OF_CUDNN_CHECK(cudnnCreateTensorDescriptor(&xy_desc_));
InferXYCudnnTensorDesc(xy_shape, data_type, axis, xy_desc_);
OF_CUDNN_CHECK(cudnnCreateTensorDescriptor(¶m_desc_));
InferParamCudnnTensorDesc(xy_desc_, mode, param_desc_);
int n, c, h, w, n_stride, c_stride, h_stride, w_stride;
OF_CUDNN_CHECK(cudnnGetTensor4dDescriptor(param_desc_, ¶m_data_type_, &n, &c, &h, &w,
&n_stride, &c_stride, &h_stride, &w_stride));
param_size_ = c;
}
~CudnnTensorDescHelper() {
OF_CUDNN_CHECK(cudnnDestroyTensorDescriptor(param_desc_));
OF_CUDNN_CHECK(cudnnDestroyTensorDescriptor(xy_desc_));
}
cudnnTensorDescriptor_t xy_desc() const { return xy_desc_; }
cudnnTensorDescriptor_t param_desc() const { return param_desc_; }
void CheckParamTensor(const user_op::Tensor* tensor) const {
CHECK_NOTNULL(tensor);
CHECK_EQ(tensor->shape_view().NumAxes(), 1);
CHECK_EQ(tensor->shape_view().At(0), param_size_);
CHECK_EQ(GetCudnnDataType(tensor->data_type()), param_data_type_);
}
private:
cudnnTensorDescriptor_t xy_desc_ = nullptr;
cudnnTensorDescriptor_t param_desc_ = nullptr;
cudnnDataType_t param_data_type_;
int32_t param_size_ = 0;
};
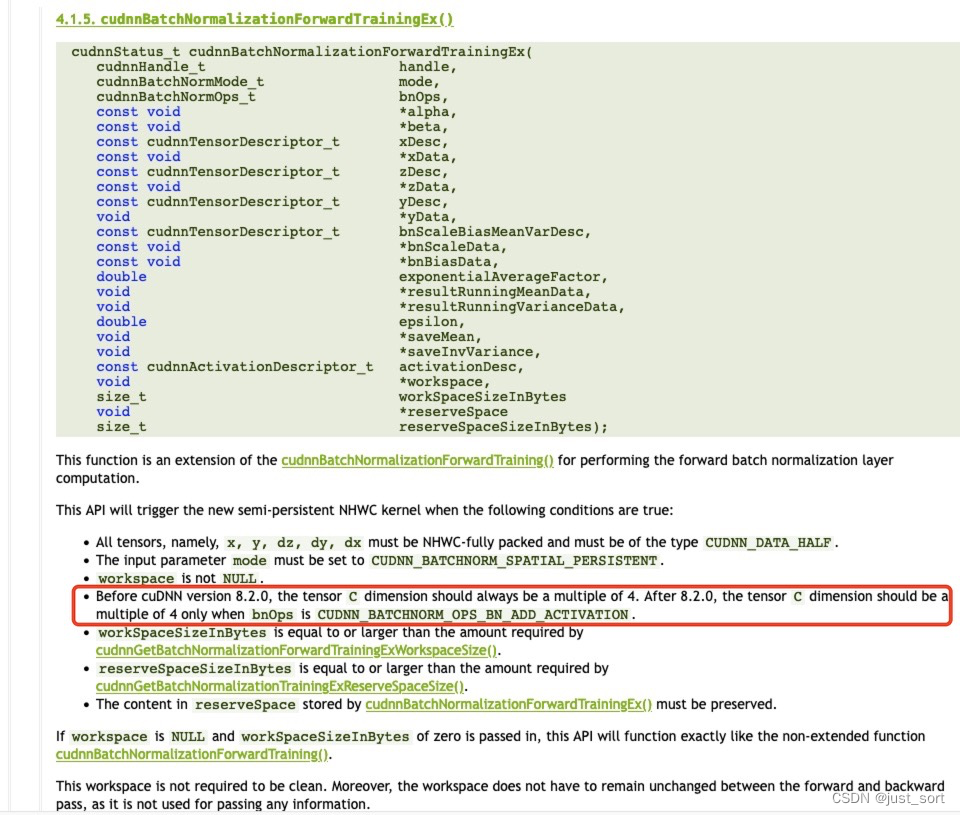
除了这些描述信息之外,我们还可以在cudnn提供的文档中查看BatchNorm相关的算子一般还需要什么特殊的输入信息。我们来看 cudnnBatchNormalizationForwardTrainingEx() 这个API :https://docs.nvidia.com/deeplearning/cudnn/api/index.html#cudnnBatchNormalizationForwardTrainingEx 。

可以看到这个算子是 cudnnBatchNormalizationForwardTraining() 这个算子的扩展,扩展的内容就是可以我们可以传入额外的一个Activation的算子比如ReLU以及一个Add算子分别对应我们在前言中介绍的 ResNet 中的 BNReLU 和 BNAddReLU 模式。可以看到在这个算子接口中除了对输入Tensor x,BN后需要add的输入Tensor z以及输出Tensor y的描述信息外,还需要指定workspace和reserveSpace,这个workspace是cudnn的BatchNorm以NHWC模式计算时需要的GPU内存buffer,而reserveSpace则表示当前这个配置的BN算子至少还需要多少可以申请的GPU显存(从文档猜测应该是和BNReLU/BNAddReLU这俩Pattern相关)。
在OneFlow中, https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/user/kernels/normalization_kernel.cu#L126-L175 以及 https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/user/kernels/normalization_kernel.cu#L637-L684 就是为了推断BN算子以及BN扩展的算子需要的额外GPU内存大小,然后在OneFlow的内存池中开辟一块显存供调用cudnn的 cudnnBatchNormalizationForwardTrainingEx() 和 cudnnBatchNormalizationBackwardEx() 接口时使用。
关于调用cudnn的BatchNorm相关的算子api,我们还需要注意一点,那就是要使用cudnn提供的扩展接口cudnnBatchNormalizationForwardTrainingEx() 和 cudnnBatchNormalizationBackwardEx() 还存在一些限制:
 首先是cudnn版本的限制,然后对于
首先是cudnn版本的限制,然后对于CUDNN_BATCHNORM_OPS_BN_ADD_ACTIVATION的Op模式,输入Tensor的通道数必须是4的倍数,最后这个扩展Op必须在输入Tensor的数据排布模式是NHWC时才能启动。这些限制对应到OneFlow的代码在:https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/core/job_rewriter/cudnn_fused_normalization_add_relu_pass.cpp#L79-L86 。
0x2.2 善用CUDA优化打破cudnn的限制¶
上面提到要使用CUDNN的扩展算子有一系列限制,我们有没有办法打破这限制呢?有的。以ResNet为例,针对BNReLu和BNAddReLU这两种Pattern,我们可以分别针对ReLU和AddReLU实现一个CUDA Kernel,相信入门CUDA的小伙伴写这两个算子都没什么问题。但如何在考虑到Backward的时候把这两个算子优化到位呢?OneFlow给出了一个解决方案。


以 ReLU 算子为例,前向的输入为x,输出为y,后向的输入为dy和y,输出dx。后向计算中的y仅用来判断对应元素是否大于0,因此可以将y替换为由前向生成的bitset(对应上述代码中的mask),理论上可以省掉ReLU的后向算子对冗余的y的访问操作,减少约y大小的读取,也对应约⅓的global memory访问。对于ReLU/ReLUAdd这种ElementWise算子来说,GPU的带宽是极容易成为瓶颈的,通过这种优化可以大大提升ReLU和ReLUAdd算子的带宽。
在 《OneFlow是如何做到世界上最快的深度学习框架》(https://zhuanlan.zhihu.com/p/271740706) 文章中已经介绍到了这种基于bitmask优化后向算子的方案。并且文章中给出了3种方案,但没有给出对应的代码实现,实际上我只读懂了第一种和第三种方案,接下来我们描述一下这两种方案。
- Bitset mask生成方案一:顺序遍历法
这种方法是让每个CUDA线程连续读取内存中的8个元素,并根据每个元素是否大于0生成一个int8类型的mask,并写入到最终的bitset mask中。这种访问对于写全局内存是连续访问的,但对于读(Read)全局内存,线程间内存访问不连续,所以没有充分合并内存事务。下图展示了这种方案读写内存的示例:
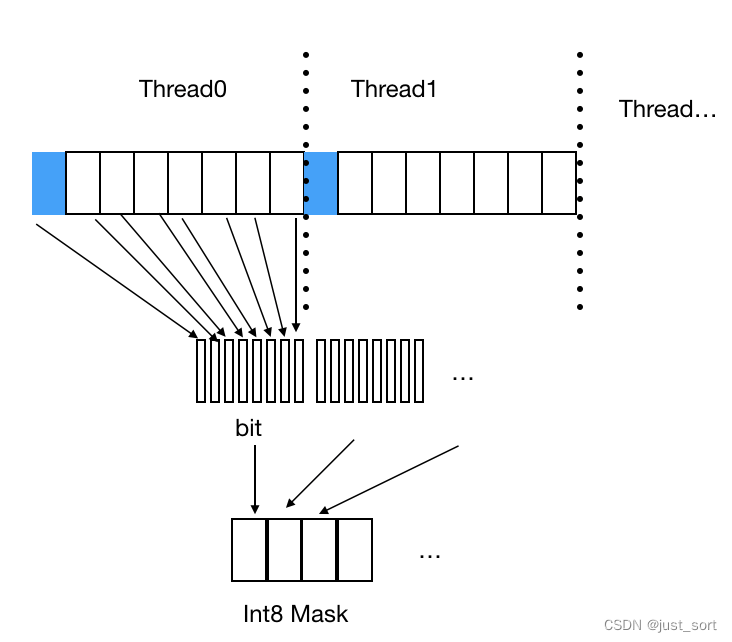 以ReLU为例子,这种方案的代码实现如下:
以ReLU为例子,这种方案的代码实现如下:
template<typename T>
__global__ void ReluGpu(int64_t n, const T* x, T* y, int8_t* mask) {
CUDA_1D_KERNEL_LOOP(i, n) {
int8_t mask_val = 0;
for(int32_t j = 0; j < 8; j++) {
int32_t offset = i * 8 + j;
const bool is_positive = (x[offset] > 0);
if(is_positive) {
y[offset] = sum;
mask_val |= (1<<j);
} else {
y[offset] = 0;
mask_val &= (~(1<<j));
}
}
mask[i] = mask_val;
}
}
在这种方案中,每个thread需要连续读的8个float32数据,则相邻线程每次加载数据的间隔为32 bytes = 4 bytes * 8。所以每个线程一次加载指令就要执行一个32字节的内存事务。故warp内的线程间全局内存访问完全没有合并,实际有效访存带宽仅为 ⅛,访存效率十分低下,性能很差。
- Bitset mask生成方案三:warp同步法
我们可以采用warp级别的同步原语:__ballot_sync(unsigned mask, predicate),这个函数接收两个参数,第一个参数是warp中参与计算的线程掩码,第二个参数是要参与判断的bool值,返回一个32bit的mask,每个bit代表warp中各个线程传入的元素是否大于0,最后由每个warp中的0号线程将生成的mask写入global memory中。(idea可以参考NVIDIA的性能优化博客:https://developer.nvidia.com/blog/using-cuda-warp-level-primitives/)
这种方案的示意图如下:
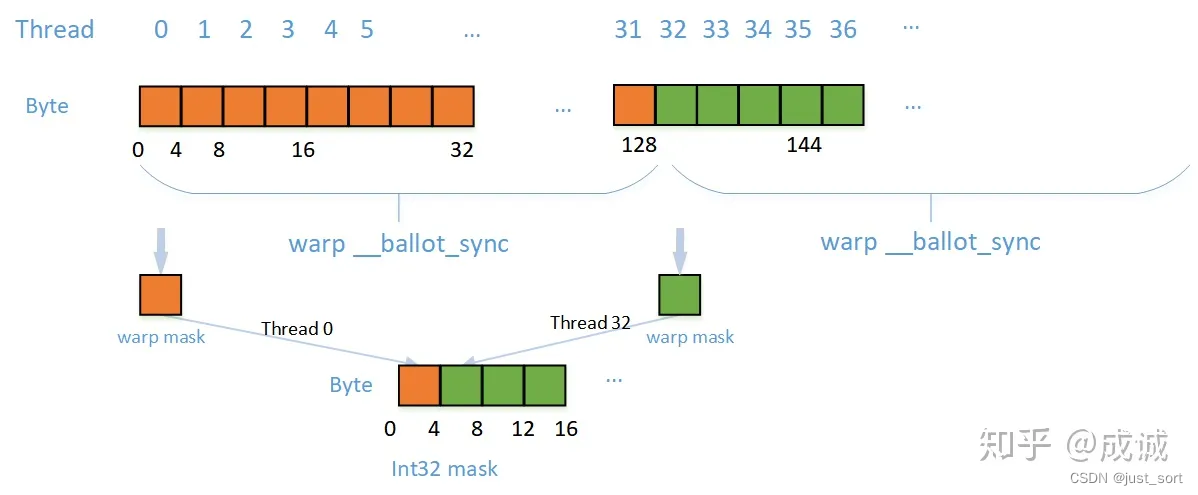 以ReLU为例,代码实现如下:
以ReLU为例,代码实现如下:
template<typename T>
__global__ void ReluGpu(int64_t n, const T* x, T* y, int32_t* mask) {
const int32_t lane_id = threadIdx.x % kCudaWarpSize; // 如果lane_id=0,表示当前线程是一个warp的0号线程
CUDA_1D_KERNEL_LOOP(i, n) {
const bool is_positive = (x[i] > 0);
int32_t warp_mask = __ballot_sync(__activemask(), static_cast<int>(is_positive));
if (lane_id == 0) { mask[i / kCudaWarpSize] = warp_mask; } // 0号线程将生成的mask写入global memory
y[i] = is_positive ? sum : 0;
}
}
0x3. 性能¶
我们这里对比一下BNReLU这个Pattern在优化前后的后向Kernel(也就是ReLU Grad Kernel)的性能和带宽表现,本次测试的环境为A100 PCIE 40G,使用Nsight Compute工具进行Profile。Profile的脚本为:
import oneflow as flow
bn = flow.nn.BatchNorm2d(num_features=32, eps=1e-5, momentum=0.1).to("cuda")
fused_bn = flow.nn.FusedBatchNorm2d(32).to("cuda")
bn.train()
fused_bn.train()
x = flow.randn(16, 32, 112, 112).to("cuda").requires_grad_()
y = flow.relu(bn(x)) # 这个是未优化的实现
# y = fused_bn(x) # 打开这行代表启用上述介绍的优化
res = y.sum()
res.backward()
res_scalar = res.detach().cpu().numpy()
经过多次测试,flow.relu(bn(x))中对应的ReLU的反向Kernel耗时大概为 48.3us,而fused_bn(x)中对应的ReLU的反向Kernel耗时大概为 42.8us ,可以说明上述基于mask掩码降低全局内存访问的优化方法是有效的。而对于BNAddReLU的Pattern来说,则可以获得更好的性能提升,因为ReluBackward相当于将这两个ElementWise操作给fuse了。
0x4. 总结¶
这里暂时写了一下个人看OneFlow Normalization 系列算子实现的理解。实际上我个人还是有一些疑问在,如果后续能搞清楚的话,会继续补充和修改。
0x5. 相关链接¶
- cudnn文档:https://docs.nvidia.com/deeplearning/cudnn/api/index.html
- oneflow代码实现:https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/user/kernels/normalization_kernel.cu
本文总阅读量次