本文把pytorch index_add算子的代码抽取出来放在:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/indexing/index_add_cuda_pytorch_impl.cu 。如果不太熟悉PyTorch的话也可以直接看这个.cu文件,有问题请在这个repo提issue。
0x0. 前言¶
我们可以在 PyTorch 的文档中找到 torch.index_add_ 的定义(https://pytorch.org/docs/stable/generated/torch.Tensor.index_add_.html#torch.Tensor.index_add_):
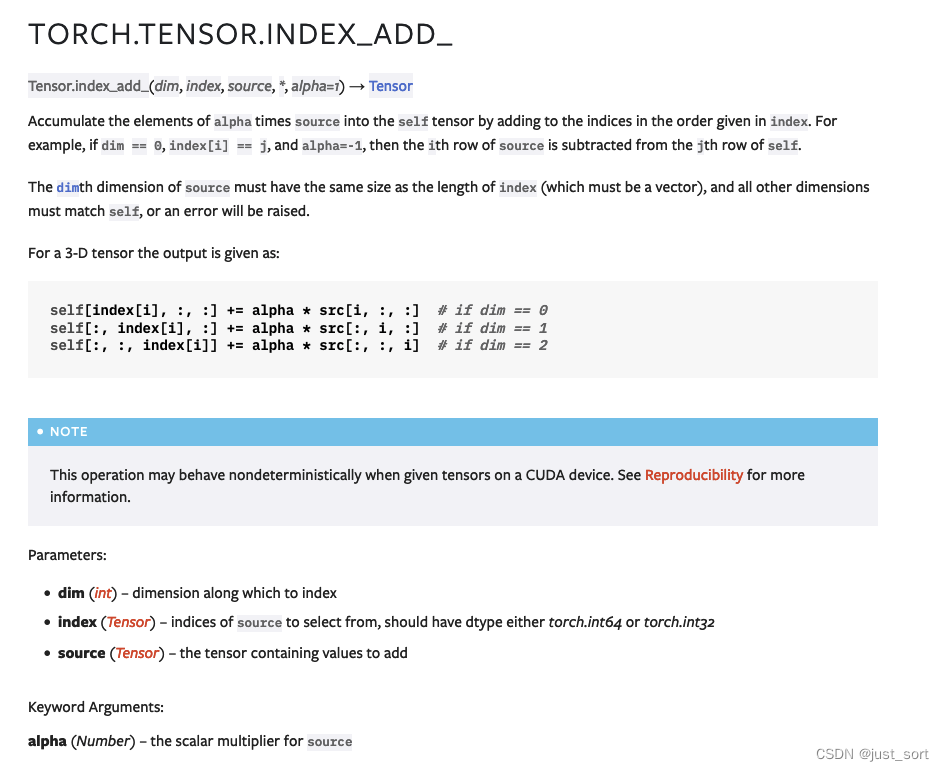 简单来说就是我们需要根据index的索引完成对当前Tensor dim维度的inplace加和,注意被加数是由另外一个Tensor src决定的。在PyTorch的codebase中搜索index_add,我们可以发现这个操作应用得非常广泛,比如说作为as_strided算子的backward的一部分,作为一些sparse操作的一部分等等。我最近研究了一下,发现PyTorch对index_add算子的cuda kernel进行了较为精细的优化,主要有两个亮点,本篇文章就来学习一下。
简单来说就是我们需要根据index的索引完成对当前Tensor dim维度的inplace加和,注意被加数是由另外一个Tensor src决定的。在PyTorch的codebase中搜索index_add,我们可以发现这个操作应用得非常广泛,比如说作为as_strided算子的backward的一部分,作为一些sparse操作的一部分等等。我最近研究了一下,发现PyTorch对index_add算子的cuda kernel进行了较为精细的优化,主要有两个亮点,本篇文章就来学习一下。
顺便提一下,在PyTorch中index_add的cuda kernel实现在https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cuda/Indexing.cu#L712 ,如果你想自己详细读这个代码我建议先编译一下PyTorch再进行调试和阅读,编译PyTorch源码可以参考:https://github.com/BBuf/how-to-optim-algorithm-in-cuda/tree/master/how-to-complie-pytorch-from-source(这个也是参考PyTorch官方的教程,补充了几个报错的坑) 。
0x1. 亮点1: 按照index的元素个数派发不同的实现¶
PyTorch优化的出发点是,index_add操作中index这个Tensor是尤其重要,它决定了输入Tensor的哪些位置会被重新赋值,然后index的元素可多可少。如果使用同一套naive的计算逻辑可能会因为重复访问index导致全局内存访问过多,而如果index很大那么为了保证性能kernel又需要满足足够的并行度才可以。为了平衡这两种情况,PyTorch按照index的元素个数实现了2套kernel。这2套kernel的实现在:https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cuda/Indexing.cu#L576-L675 。然后根据index元素个数进行dispatch:https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cuda/Indexing.cu#L801-L829 。

我在 https://github.com/BBuf/how-to-optim-algorithm-in-cuda/blob/master/indexing/indexing_pytorch_explain.cu#L381-L505 这里以PyTorch文档展示的例子(https://pytorch.org/docs/stable/generated/torch.Tensor.index_add_.html#torch.Tensor.index_add_)为例记录了各个中间变量的值,并加上了一些方便理解的注释,感兴趣的可以查看。
我们这里展示一下当index的元素很少的时候的indexFuncSmallIndex kernel实现(代码中的设置是index元素个数少于16):
// 如果索引的数量很少,我们更喜欢使用这个Kernel来避免重新加载 index。
// 这个kernel实际上适用于几乎所有问题大小的选择,但如果选择的索引数量很大,
// 那么indexFuncLargeIndex Kernel是增加并行度的更好选择。
// 下面的innerSize就是输人的self张量忽略dim维度的切片大小,对于每一个indices[i],我们都要处理innerSize个元素的copy
// selfAddDim(dstAddDim) = 0
// sourceAddDim(srcAddDim) = 0
// sliceSize(innerSize) = 3
// selfAddDimSize(dstAddDimSize) = 5
// selfNumel(dstNumel) = 15
// selfInfo.sizes(dst): 1, 3,
// selfInfo.strides(dst): 3, 1,
// sourceInfo.sizes(src): 1, 3,
// sourceInfo.strides(src): 3, 1
// indexInfo.sizes(indices): 3,
// indexInfo.strides(indices): 1,
template <typename T, typename IndicesType, typename IndexType, int DstDim, int SrcDim, int IdxDim,
typename func_t>
__global__ void indexFuncSmallIndex(cuda::detail::TensorInfo<T, IndexType> dst,
cuda::detail::TensorInfo<T, IndexType> src,
cuda::detail::TensorInfo<IndicesType, IndexType> indices,
int dstAddDim,
int srcAddDim,
IndexType innerSize,
int64_t dstAddDimSize,
int64_t dstNumel,
const func_t& op,
T alpha) {
// In order to avoid reloading the index that we are copying, load
// it once to handle all of the points that are being selected, so
// it can be reused as much as possible. This kernel is chosen when
// this is a good choice (small number of chosen indices), since
// re-accessing indices in addition to src elements can be slow.
// 为了避免重新加载我们正在复制的索引,加载一次以处理所有正在选择的点,以便尽可能地重复使用它。
// 当这是一个不错的选择(选择的索引数量很少)时,就会选择这个Kernel,
// 因为除了 src 元素之外,重新访问索引可能很慢。
for (IndexType srcIndex = 0; srcIndex < indices.sizes[0]; ++srcIndex) {
// Lua indices begin at 1
IndexType dstIndex =
indices.data[cuda::detail::IndexToOffset<IndicesType, IndexType, IdxDim>::get(srcIndex, indices)];
CUDA_KERNEL_ASSERT(dstIndex < dstAddDimSize);
// We stride over the output ignoring the indexed dimension
// (innerSize), whose offset calculation is handled differently
for (IndexType linearIndex = blockIdx.x * blockDim.x + threadIdx.x;
linearIndex < innerSize;
linearIndex += gridDim.x * blockDim.x) {
IndexType dstOffset =
cuda::detail::IndexToOffset<T, IndexType, DstDim>::get(linearIndex, dst);
dstOffset += dstIndex * dst.strides[dstAddDim];
IndexType srcOffset =
cuda::detail::IndexToOffset<T, IndexType, SrcDim>::get(linearIndex, src);
srcOffset += srcIndex * src.strides[srcAddDim];
T val = src.data[srcOffset] * alpha;
op(dst.data, dstOffset, dstNumel, &val);
}
}
}
我们可以看到首先有一个for (IndexType srcIndex = 0; srcIndex < indices.sizes[0]; ++srcIndex) 的循环来避免重复加载 index Tensor(这个时候index Tensor信息由indices管理),后续的实验结果也将证明这个优化在 index 元素个数比较小而 self Tensor 比较大的时候是有一定性能提升的。然后选定一个indices[i] 之后就启动一堆线程计算完这个indices[i]对应的 self Tensor的一个切片(linearIndex < innerSize)。
indexFuncLargeIndex Kernel我就不展示了,感兴趣的小伙伴可以直接阅读代码实现。
实现完这两个Kernel之后,我们可以在 https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cuda/Indexing.cu#L753-L778 这里看到PyTorch分别为这两个Kernel设置了不同的GridSize和BlockSize。
// selfAddDim = 0
// sourceAddDim = 0
// sliceSize = 3
// selfAddDimSize = 5
// selfNumel = 15
#define SMALL_INDEX(TENSOR_TYPE, INDICES_TYPE, TYPE, SELF_DIM, SOURCE_DIM, IDX_DIM) \
indexFuncSmallIndex<TENSOR_TYPE, INDICES_TYPE, TYPE, SELF_DIM, SOURCE_DIM, IDX_DIM> \
<<<smallIndexGrid, smallIndexBlock, 0, stream>>>( \
selfInfo, sourceInfo, indexInfo, \
selfAddDim, sourceAddDim, sliceSize, selfAddDimSize, \
selfNumel, reduce_add, alpha_value); \
C10_CUDA_KERNEL_LAUNCH_CHECK();
#define LARGE_INDEX(TENSOR_TYPE, INDICES_TYPE, TYPE, \
SELF_DIM, SOURCE_DIM, IDX_DIM, IDX_IS_MAJOR) \
indexFuncLargeIndex<TENSOR_TYPE, INDICES_TYPE, TYPE, \
SELF_DIM, SOURCE_DIM, IDX_DIM, IDX_IS_MAJOR> \
<<<largeIndexGrid, largeIndexBlock, 0, stream>>>( \
selfInfo, sourceInfo, indexInfo, \
selfAddDim, sourceAddDim, sourceTotalSize, \
(IDX_IS_MAJOR) ? sliceSize : numIndex, \
selfAddDimSize, selfNumel, reduce_add, alpha_value); \
C10_CUDA_KERNEL_LAUNCH_CHECK();
// small index以正在索引的每个切片的大小为基准来设定GridSize和BlockSize,同时要考虑到需要满足足够多的wave保证利用率
const dim3 smallIndexGrid(std::min(ceil_div(sliceSize, (ptrdiff_t)128), (ptrdiff_t)(mpc * 8)));
const dim3 smallIndexBlock(std::min(sliceSize, (ptrdiff_t)128));
// large index以source 张量的总大小为基准来设定GridSize和BlockSize,同时要考虑到需要满足足够多的wave保证利用率
const dim3 largeIndexGrid(std::min(ceil_div(sourceTotalSize, (ptrdiff_t)128), (ptrdiff_t)(mpc * 8)));
const dim3 largeIndexBlock(std::min(sourceTotalSize, (ptrdiff_t)128));
对于index的元素个数比较小也就是smallIndex的情况,线程块的数量由sliceSize来决定,而对于index元素个数比较大也就是largeIndex的时候线程块的数量则由输入Tensor self的总元素数量来决定。我个人感觉这里设置GridSize和BlockSize还是存在一定问题的,在profile的时候ncu对于index比较小并且输入Tensor也不太大的情况会提示grid太小无法充分发挥并行性的问题。建议阅读https://mp.weixin.qq.com/s/1_ao9xM6Qk3JaavptChXew 这篇文章设置更合理的GridSize和BlocSize,或许可以提升smallIndex Kernel的性能。
比如index很小但是输入Tensor只有一个维度的情况下,这个时候PyTorch只会启动一个Block以及一个Thread,这显然是个bad case:

0x2. 亮点2: 维度压缩减少坐标映射的计算量¶
index_add里面的第二个优化亮点是对Tensor的维度压缩,对应代码的https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cuda/Indexing.cu#L793, https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/native/cuda/Indexing.cu#L787 ,这个维度压缩是什么意思呢?
假设index_add操作的输入Tensor是三个维度假设形状为(32, 1024, 1024),而dim设置为0。那么在cuda Kernel中索引位置的时候是可以提前把dim后面的维度给合并起来的(这里使用TensorInfo数据结构来完成,其实本质上就是操作这个TensorInfo对象维护的Tensor的stride和size,具体可见这里的实现:https://github.com/pytorch/pytorch/blob/master/aten/src/ATen/CollapseDims.h#L22),这样子原始的输入Tensor的形状就会变成(32, 1024)。这样在indexFuncSmallIndex和indexFuncLargeIndex Kernel里面做坐标映射的时候就可以降低计算量以及降低对全局内存的访问提升带宽。注意,这里的维度压缩也可以压缩dim之前的所有维度为一个维度,这样子最终kernel需要处理的self输入张量维度只有1,2,3三种情况。
虽然这个优化是算法层面的优化,但是也间接让cuda kernel的带宽进行了提升和计算量进行了下降。实际上这个思路也启发了我在oneflow中实现index_add的kernel,我也是间接做了维度压缩。以这个例子来说:
x = torch.randn(32, 1024, 1024).to("cuda")
t = torch.randn(15, 1024, 1024).to("cuda")
index = torch.randint(0, 32, (15,)).to("cuda")
x.index_add_(0, index, t)
torch.cuda.synchronize()
使用ncu在a100 pcie 40g上profile,我发现使用了维度压缩优化之后将这个cuda kernel从接近300+us的运行速度提升到了180+ us。
0x3. 实战性能表现¶
我这里对比了一下PyTorch的index_add和oneflow中index_add的性能表现。做性能profile的时候,我使用了以下脚本:
import torch
x = torch.randn(32*1024*1024).to("cuda")
t = torch.randn(15).to("cuda")
index = torch.randint(0, 1024, (15,)).to("cuda")
x.index_add_(0, index, t)
torch.cuda.synchronize()
x = torch.randn(32*1024, 1024).to("cuda")
t = torch.randn(15, 1024).to("cuda")
index = torch.randint(0, 1024, (15,)).to("cuda")
x.index_add_(0, index, t)
torch.cuda.synchronize()
x = torch.randn(32, 1024, 1024).to("cuda")
t = torch.randn(15, 1024, 1024).to("cuda")
index = torch.randint(0, 32, (15,)).to("cuda")
x.index_add_(0, index, t)
torch.cuda.synchronize()
x = torch.randn(32*1024*1024).to("cuda")
t = torch.randn(1024).to("cuda")
index = torch.randint(0, 1024, (1024,)).to("cuda")
x.index_add_(0, index, t)
torch.cuda.synchronize()
x = torch.randn(32*1024, 1024).to("cuda")
t = torch.randn(1024, 1024).to("cuda")
index = torch.randint(0, 1024, (1024,)).to("cuda")
x.index_add_(0, index, t)
torch.cuda.synchronize()
测试环境为 A100 PCIE 40G,测试结果如下:
| 框架 | self tensor的shape | dim | source shape | index shape | 速度 |
|---|---|---|---|---|---|
| PyTorch | (32 * 1024 *1024,) | 0 | (15) | (15) | 17.15us |
| OneFlow | (32 * 1024 *1024,) | 0 | (15) | (15) | 12us |
| PyTorch | (32 * 1024, 1024) | 0 | (15, 1024) | (15) | 27.78us |
| OneFlow | (32 * 1024, 1024,) | 0 | (15, 1024) | (15) | 26.98us |
| PyTorch | (32, 1024, 1024) | 0 | (15, 1024, 1024) | (15) | 186.88us |
| OneFlow | (32 * 1024 *1024,) | 0 | (15, 1024, 1024) | (15) | 247.10us |
| PyTorch | (32 * 1024 *1024,) | 0 | (1024) | (1024) | 7.9us |
| OneFlow | (32 * 1024 *1024,) | 0 | (1024) | (1024) | 7.79us |
| PyTorch | (32 * 1024, 1024,) | 0 | (1024, 1024) | (1024) | 27.87us |
| OneFlow | (32 * 1024, 1024,) | 0 | (1024, 1024) | (1024) | 28.67us |
整体来说 PyTorch 在 index Tensor元素很小,但Tensor很大的情况下相比于oneflow有一些性能提升,其它情况和 OneFlow 基本持平,也有一些case是慢于oneflow比如index很小但是输入Tensor只有一个维度的情况下,这个时候PyTorch只会启动一个Block以及一个Thread,这显然是个bad case。OneFlow的index_add实现在 https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/user/kernels/index_add_kernel.cu ,我们并没有针对 index 的大小来单独派发kernel,所以在某些case上性能暂时比PyTorch低一些,后续有需求的话可以继续优化下。
0x4. 总结¶
我这里相对粗糙的学习了一下调研PyTorch index_add这个算子的cuda实现的优化技术。但PyTorch的这个index_add实现仍然有一些改进空间,比如IndexToOffset的实现有取模操作,这个可以改成一次乘法和减法,可以节省计算指令。然后index_add 的两个kernel来说,GridSize和BlockSize并不是很合理,有改进空间。
0x5. 相关链接¶
- https://github.com/pytorch/pytorch
- https://github.com/Oneflow-Inc/oneflow/blob/master/oneflow/user/kernels/index_add_kernel.cu
- https://github.com/BBuf/how-to-optim-algorithm-in-cuda
本文总阅读量次