浅谈NVIDIA-H100白皮书
忙完手头工作,就赶紧来过了一遍 H100 白皮书。下面我就以框架开发和炼丹师的角度谈谈 H100 的一些新特性,如有说错的地方还望指正。
硬件层级¶
相较于A100的108个SM,H100 提升到了132个SM,每个SM里一共有 128个FP32 CUDA Core,并配备了第四代 TensorCore。每个 GPU 一共有16896个 FP32 CUDA Core,528个Tensor Core。

我还留意了下其他文章所提及的,这次 FP32 CUDA Core是独立的,而在安培架构,是有复用 INT32 部分。相较A100,这次是在没复用的情况下把 FP32 CUDA Core数量翻倍。
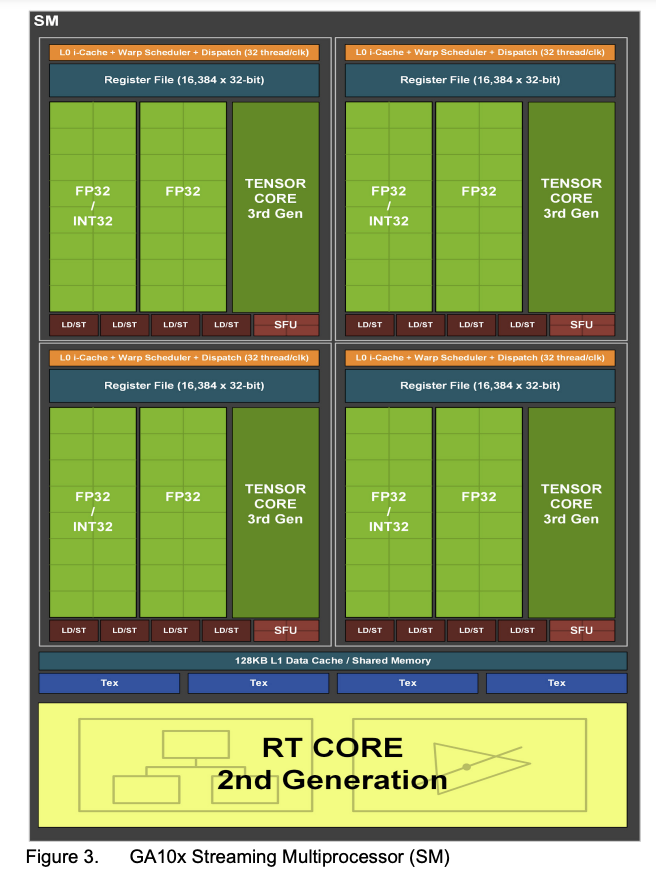
第四代TensorCore¶
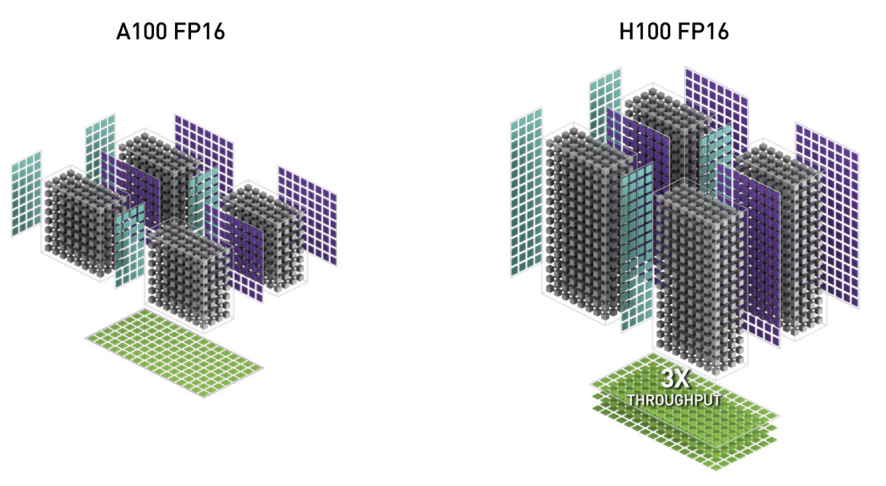
TensorCore对矩阵乘法有着高度优化,这一次发布了第四代,在FP16矩阵乘法下有3倍的提升
FP8 数据格式¶
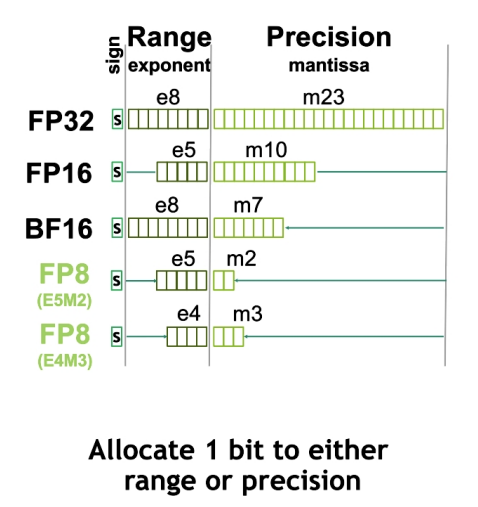
NV也发布了一款全新的数据格式 Float8,具体而言分两种模式,E5M2是 5个指数位,2个尾数位,1个符号位;另一个 E4M3 是 4个指数位置,3个尾数位,一个符号位。需要比较大的范围,则用 E5M2,对精度有一定要求可以使用 E4M3
并且支持多种精度类型的累加:

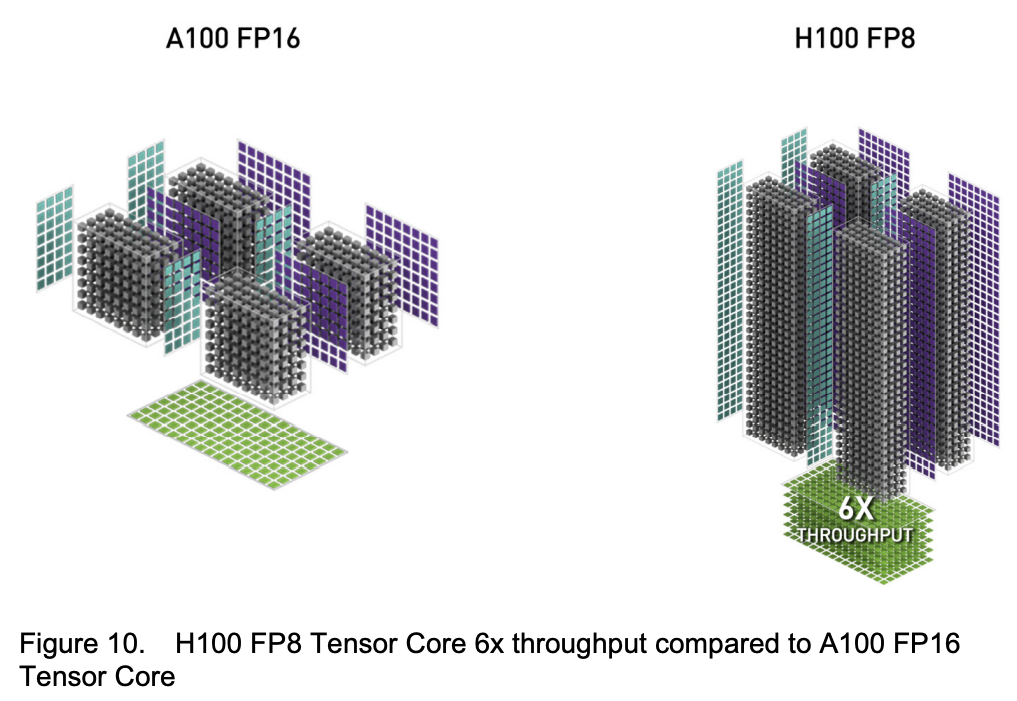
前面 TensorCore 在 FP16 已经有3倍提升了,对应的在 FP8 情况则有6倍提升
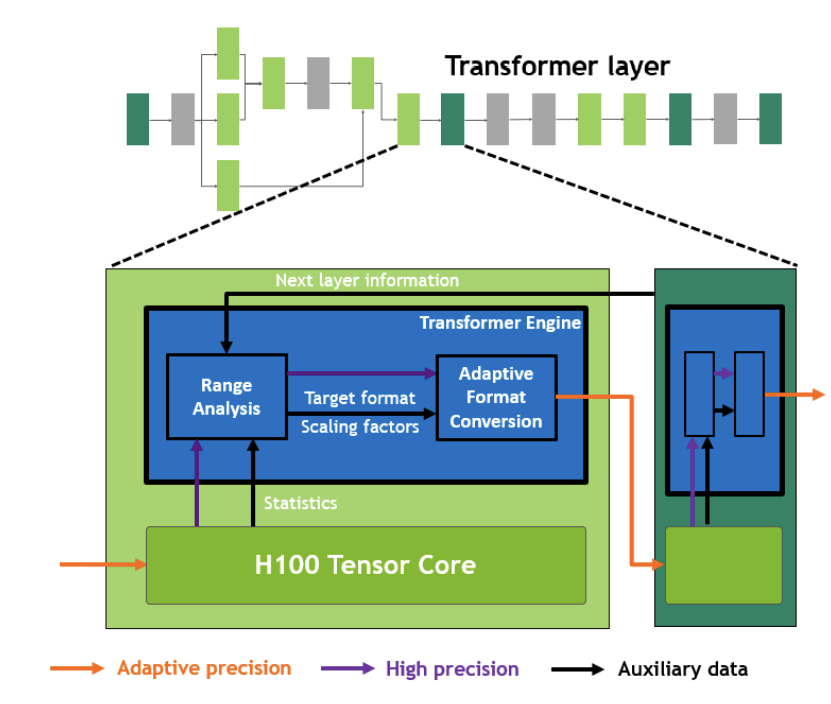
Transformer Engine¶
一开始我以为只是名字恰好取的是Transformer,但看他意思是专为Transformer模型而生的一个组件
随着 GPT-3 等模型发展,Transformer类的模型越来越大,训练时间也越来越长,以Megatron Turing NLG为例,需要 2048张 A100 训8周。而自动混合精度训练逐渐成熟,能够以更小,更快的数据格式(FP16)训练,同时也能保证模型准确率,Transformer Engine也应运而生了。
我理解 NV 这里是通过硬件+软件的方式来实现了自动混合精度训练,我们常说的自动混合精度训练都是fp16为主,而Transformer Engine支持了 FP8 数据格式。Transformer Engine会对 TensorCore 的计算结果进行统计分析,并决定是否要转换精度,并会搭配scale来进行缩放。
看上去Transformer Engine专门为Transformer模型而生,很好奇后续应该通过什么专用工具库来调用Transformer Engine。
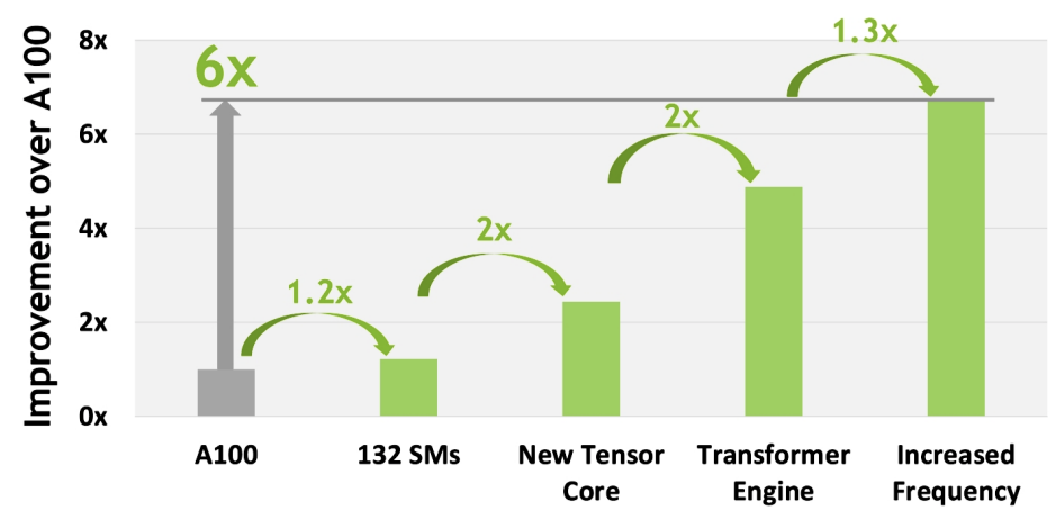
至此:
- SM相较上一代提升了22%
- 第四代TensorCore性能有着两倍提升
- FP8数据类型引入+Transformer Engine又有两倍提升
- 时钟频率提升带来了30%提升 这一代相比A100有着6倍的提升
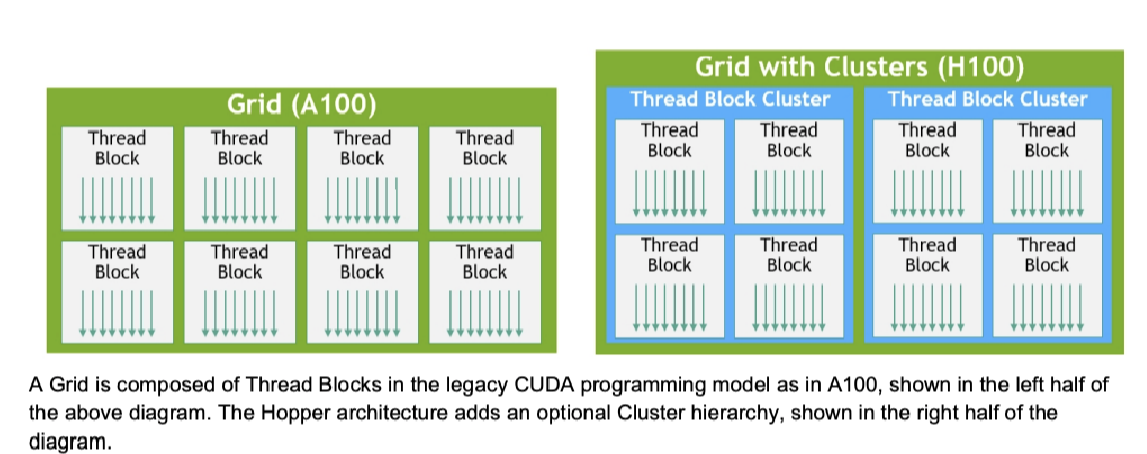
新的线程层次 Thread Block Cluster¶
在之前CUDA编程里,我们将多个线程块组织成一个Grid,多个线程组织成一个线程块。一个线程块被单个SM调度,并且块内的线程可以同步,并利用SM上的shared memory来交换数据。线程块这个概念作为CUDA编程模型里唯一一个局部单元,已经无法最大限度拉满执行效率。
这一次在 Block 和 Grid 中间,插入了一个新的线程层次 Thread Block Cluster。一个 Cluster 是由一组线程块构成,并能被并发地被一组 SM 调度。
在一个 Cluster 内,所有线程可以访问其他SM上的Shared Memory进行数据读取交换:
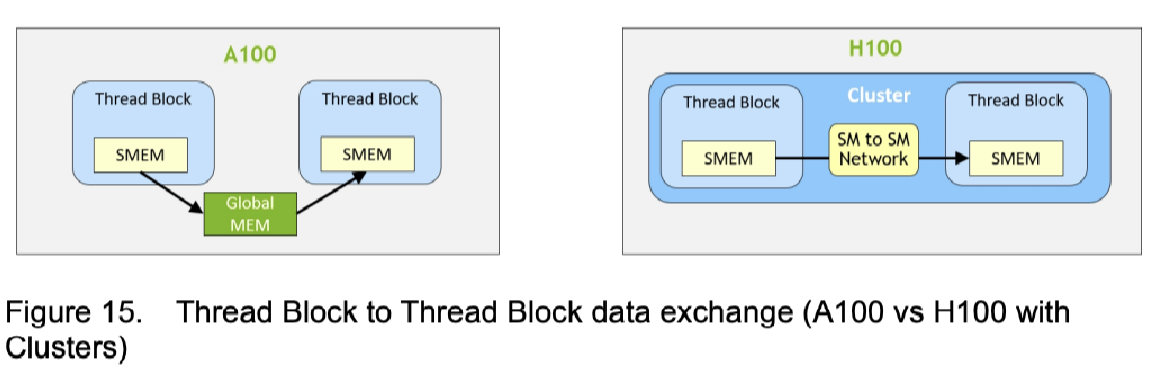
而在A100只能借助Global Memory实现不同SM上的Shared Memory访问
这种新的数据交换方式能够提升7倍的速度
碍于鄙人的能力,这个我暂时只能想到做reduce_sum的时候,各线程块的部分和结果可以直接通过 Cluster 内的Distributed Shared Memory相加,而无需重新启动一个核函数或用AtomicAdd实现最后的求和。
Tensor Memory Accelerator¶
TensorCore计算能力上来了,那IO也得对应升级一下。TMA则是针对数据从Global Memory传输到Shared Memory而生。

TMA编程模型是单线程的,即一个线程束内,会随机选一个线程用来异步操作,其他线程则等待数据完成传输。
这一硬件也解放了线程,以往地址计算和数据搬运是需要线程执行,而这一次都由TMA包了:

还有一些特性没完全看完,看得出NV已经是All in AI,并且押宝在Transformer类模型上了,期待后续的实际测试。
本文总阅读量次