图解神秘的NC4HW4
【GiantPandaCV导语】以卷积和im2col+gemm实现卷积操作举例,来图解深度学习中Tensor的NC4HW4(其实应该是N{C/4+C%4>0?1:0}HW4),写成CN4HW4方便阅读.
什么是NC4HW4?¶
- 对于卷积操作, 根据计算机内存排布特点, 按行进行处理.处理完一个通道的数据, 转入下一个通道继续按行处理.

- 对于一个nchw格式的Tensor来说, 其在计算机中的内存排布是这样的:
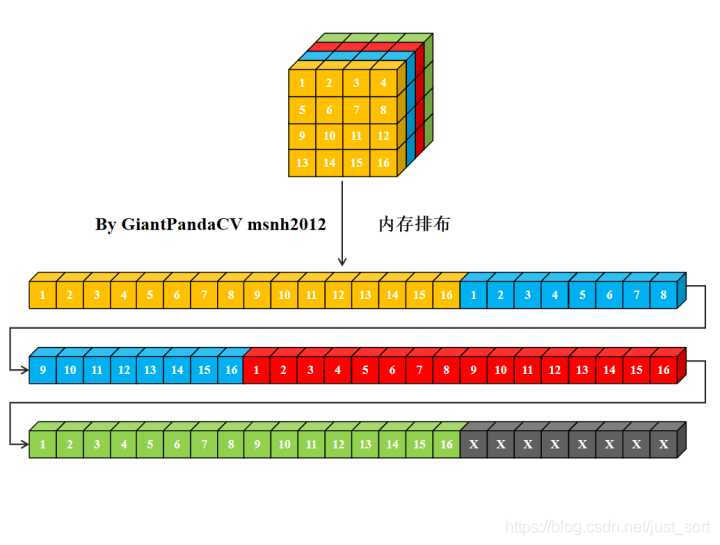
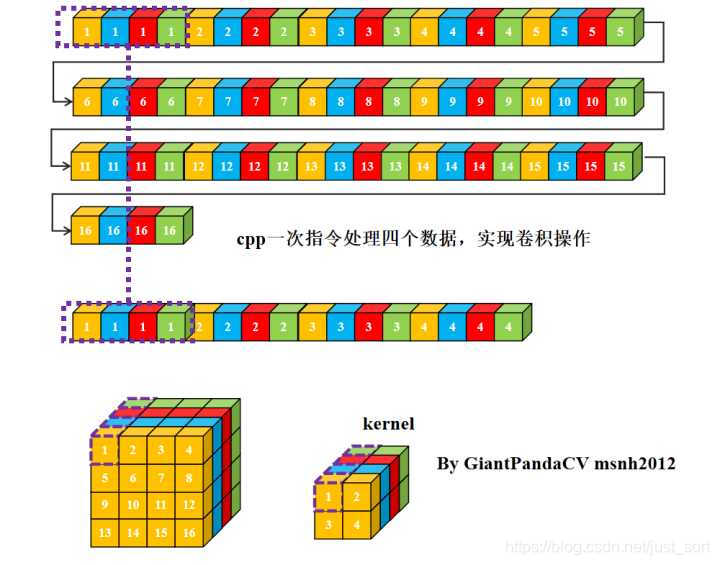
- 使用cpp一次指令处理一个数据, 用来处理卷积操作, 即循环实现乘法相加即可.
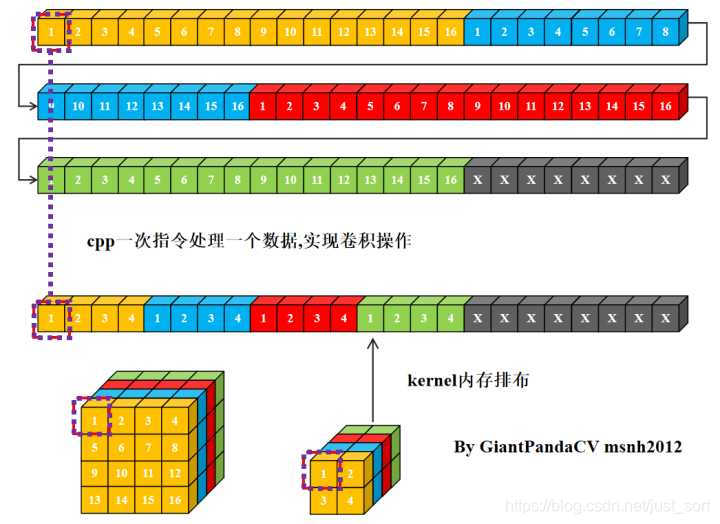
- 现在有一条指令处理4组数据的能力, 比如x86结构的sse指令,arm的neon指令.以及GPGPU的OpenGL和OpenCL,单次处理RGBA四组数据. 如果继续使用nchw内存排布的话, 是这样的.
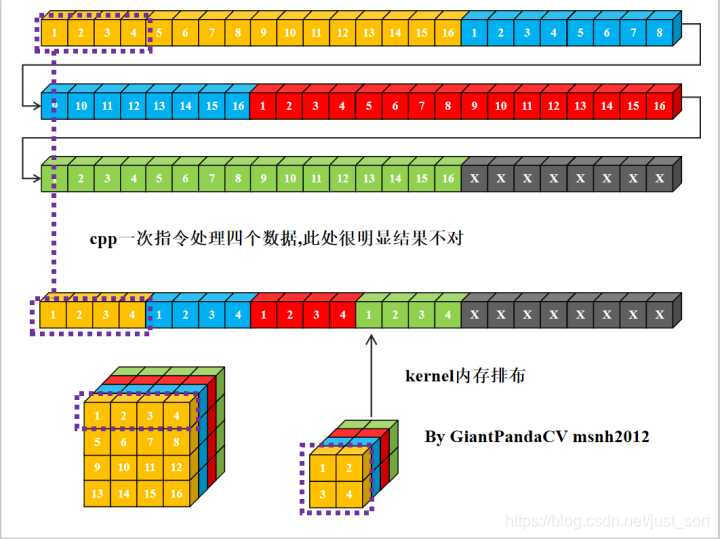
- 根据按行处理特点, 对于Feature和kernel的宽不是4倍数进行处理, 会出现错误. 图中的kernel很明显以已经到了第二行的值。那么有没有方法在按行处理的思想上, 一次处理4个数,而不受影响.答案是有的, 即NC4HW4.即把前4个通道合并在一个通道上, 依次类推, 在通道数不够4的情况下进行补0.

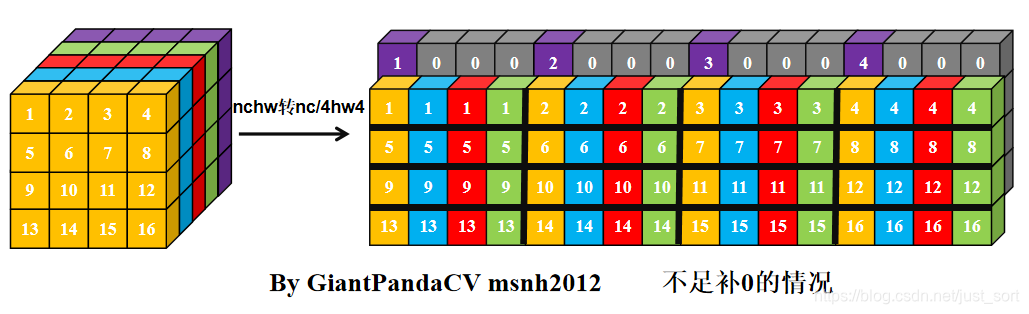
- 经过NC4HW4重排后的Tensor在内存中的排布情况如下:

- 那么, 此时在进行单次指令处理4组数据的处理,就没有问题了.只不过处理结果也是NC4HW4结构的,需要在结果输出加上NC4HW4转nchw.
NC4HW4中使用im2col+gemm实现卷积:¶
- im2col+gemm在深度学习中是最常用的对卷积进行加速计算的方案。最早在caffe框架中支持。思路如下:
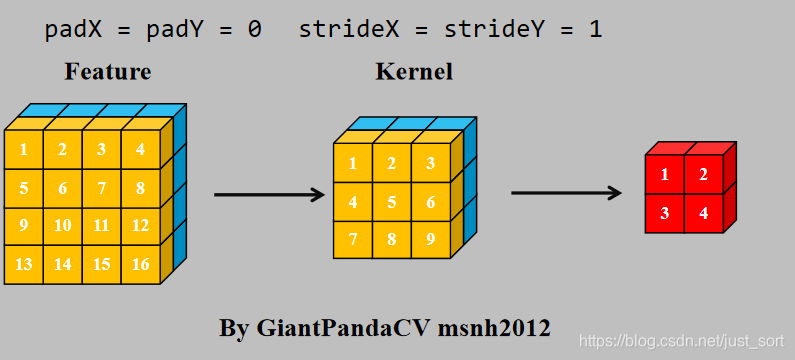
- 使用im2col+gemm进行计算:
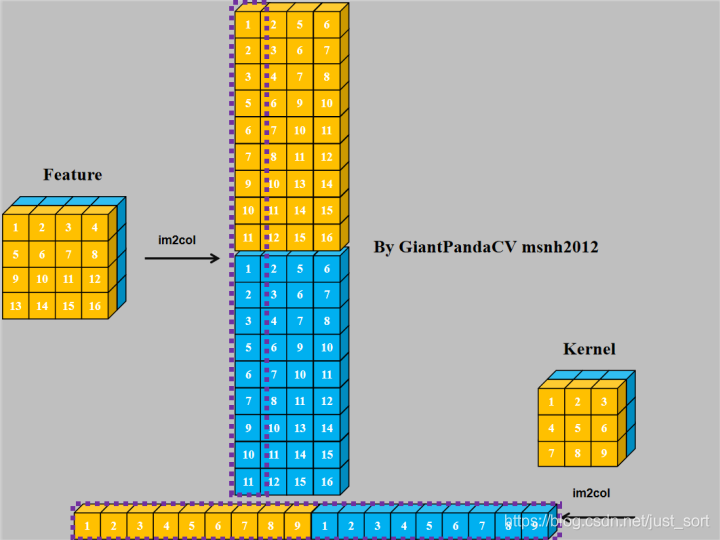
- 对于NC4HW4内存排布的Tensor来说,同样可以采用im2col+gemm来处理.
- 有如下卷积,可以使用NC4HW4内存排布方式,使用指令集优化对卷积进行加速.
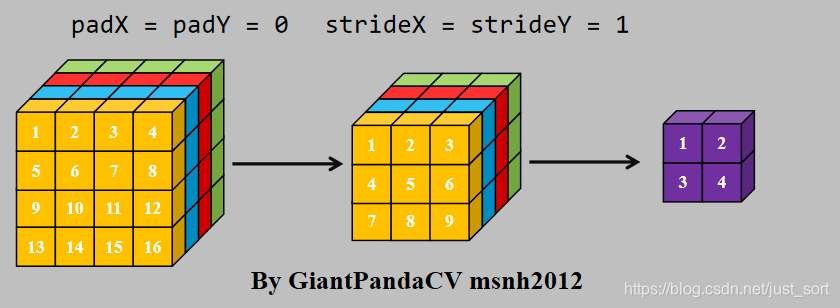
- NCHW转NC4HW4.
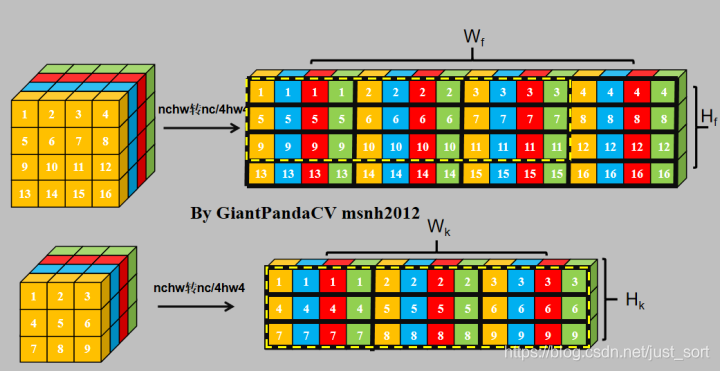
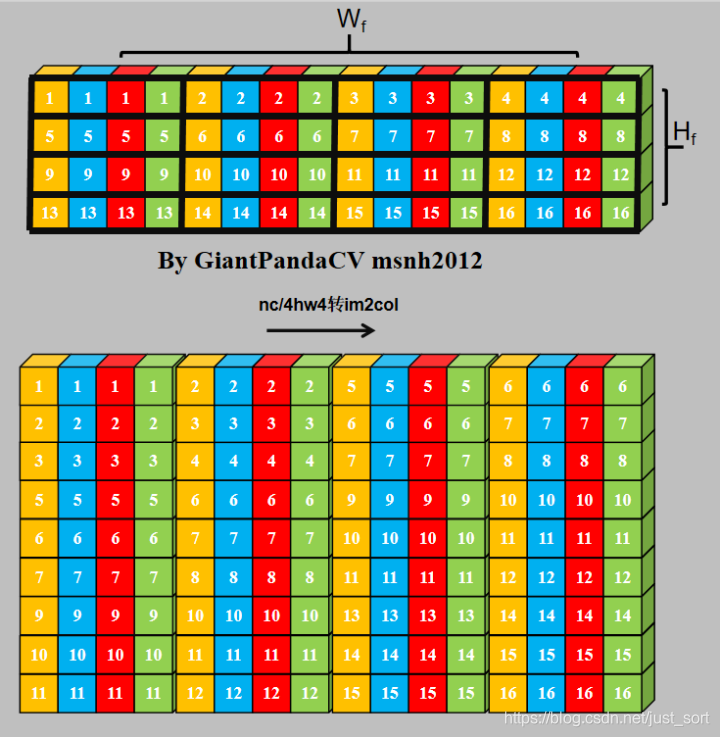
- NC4HW4对feature进行im2col
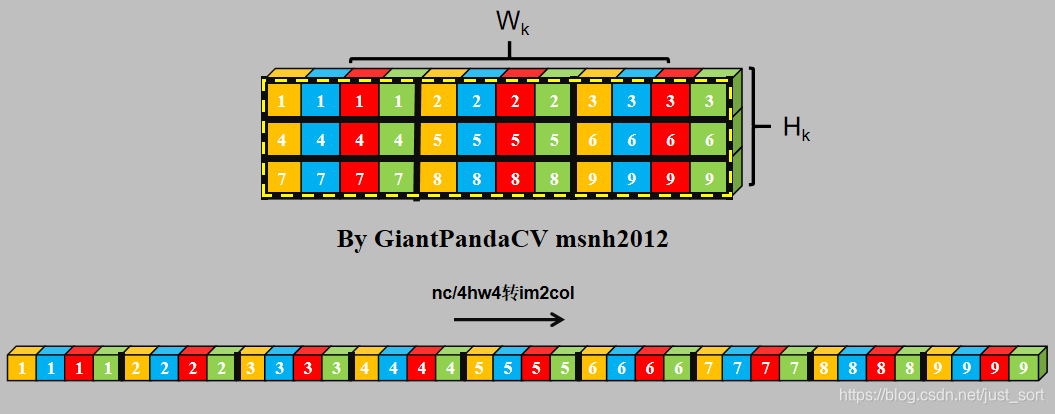
- NC4HW4对kernel进行im2col
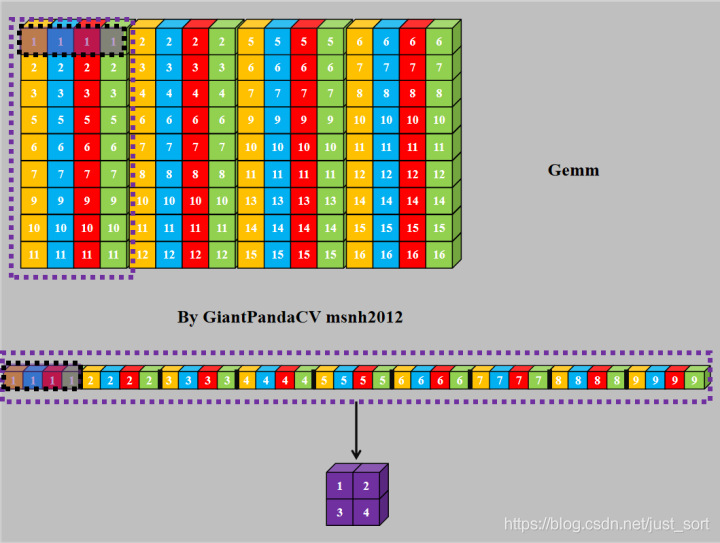
- 使用SSE,Neon,OpenCL或OpenGL实现Gemm.
最后¶
- 欢迎关注我和BBuf及公众号的小伙伴们一块维护的一个深度学习框架Msnhnet: https://github.com/msnh2012/Msnhnet
推荐阅读¶
- 多平台轻量级PyTorch模型推理框架MsnhNet
- Pytorch转Msnhnet模型思路分享
- 视觉算法工业部署及优化学习路线分享
- 基于how-to-optimize-gemm初探矩阵乘法优化
- 详解Im2Col+Pack+Sgemm策略更好的优化卷积运算
- Im2Col+GEMM的改进方法MEC,一种更加高效的卷积计算策略
欢迎关注GiantPandaCV, 在这里你将看到独家的深度学习分享,坚持原创,每天分享我们学习到的新鲜知识。( • ̀ω•́ )✧
有对文章相关的问题,或者想要加入交流群,欢迎添加BBuf微信:

为了方便读者获取资料以及我们公众号的作者发布一些Github工程的更新,我们成立了一个QQ群,二维码如下,感兴趣可以加入。

本文总阅读量次