Msnhnet¶
一款基于纯c++的轻量级推理框架,本框架受到darknet启发。

Msnhnet开发背景¶
- 很简单,三个字:造轮子。(笔者认为,别人的轮子再好,也不如自己的轮子改起来得心应手)。
- 实际上笔者以前是使用tensorflow框架开发项目,使用tensorflow c_api部署项目。然而从tf2.0开始, tensorflow变得复杂冗长,便从tensorflow转向pytorch. 然而之前pytorch在部署上不太成熟,虽有pytorch to onnx,或者pytorch to caffe等方案,还是感觉不是太nice.
- 其实笔者最大的需求还是轻量化推理框架,考虑过caffe框架,但是caffe依赖太重,尤其是boost,这个对于c++来说真的是一个超级重的依赖。然后笔者也很讨厌protobuf,最大原因还是不同版本不兼容,这个对于工程项目来说不太友好。
- 然后笔者也调研了一下其他框架,一开始是tiny-dnn,不过停更了。然后是paddlepaddle, ncnn, mnn, darknet等。这些框架各有特点,但是使用起来还是需要有一个熟悉的过程。那么反正都要学习,何必不自己搭一个框架。至此,Msnhnet正式立项。由于那段时间笔者在研究yolov3,所以就拿darknet作为主要参考。
- 对于选着主要支持pytorch模型的原因,主要还是darknet和pytorch的内存结构一样,且目前大量的网络都有pytorch的实现,受众面广。同时pytorch支持动态构建,方便调试。
Msnhnet目前的特点¶
-
由纯c++和cuda编写而成。
-
支持主流平台,windows, linux, macOS等。
-
支持主流芯片,intel x86, amd x86(未测试)和arm。
-
支持x86结构avx加速(持续优化中)。
-
支持arm结构neon加速(持续优化中)。
-
支持NNPack(主要为arm框架所用)。
-
支持Nvidia GPU。
-
支持Nvidia cuda库(cuda10+)。
-
支持Nvidia cudnn库(cudnn7+)。
-
支持Nvidia f16加速(持续优化中,确保显卡支持fp16双倍加速)。
-
支持Nvidia Jeston系列GPU。
-
支持c_api。
-
支持pytorch一键转msnhnet(目前只支持部分Op, 持续更新中)。
-
支持keras一键转msnhnet(部分Op)。
-
测试过的网络:
- lenet5
- lenet5_bn
- alexnet
- vgg16
- vgg16_bn
- resnet18
- resnet34
- resnet50
- resnet101
- resnet152
- darknet53
- googLenet
- mobilenetv2
- yolov3
- mobilenetv2_yolov3
- yolov3_spp
- yolov3_tiny
- yolov4
- fcns
- unet
-
支持C#语言,MsnhnetSharp。
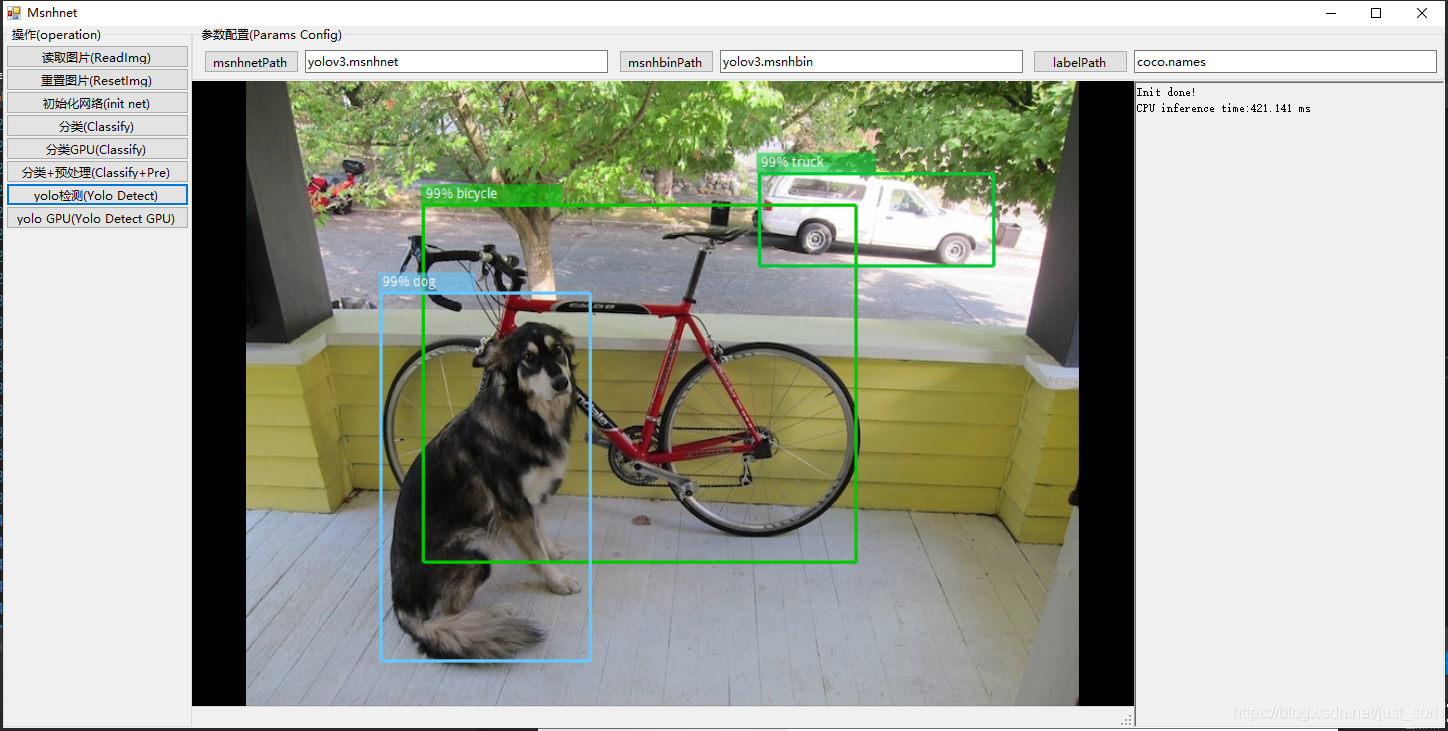
- 支持msnhnet可视化,类似netron。
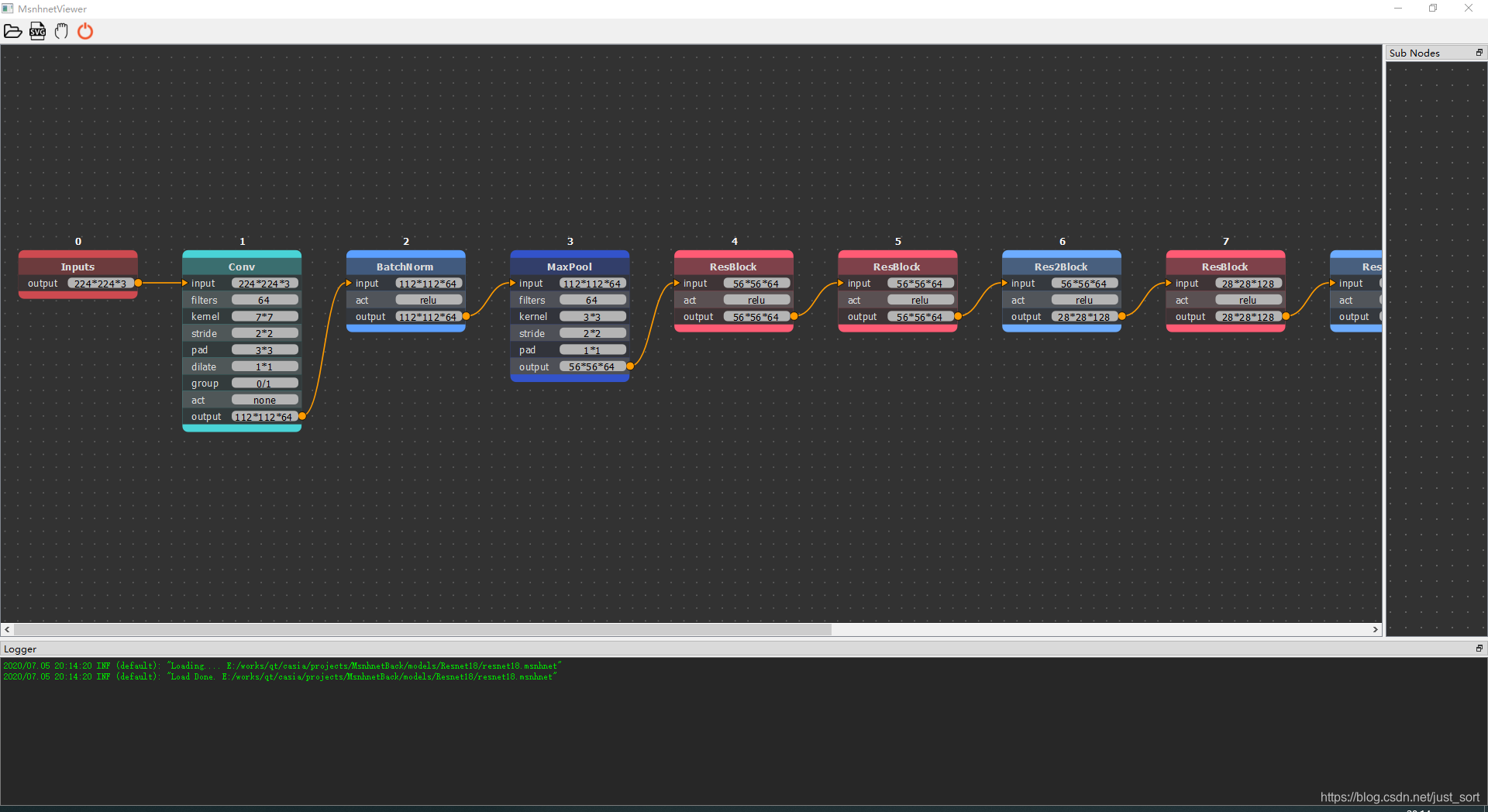
-
部分网络的表现。(持续优化中...)
-
Yolo CPU
- Win10 MSVC 2017 I7-10700F
net yolov3 yolov3_tiny yolov4 time 465ms 75ms 600ms
- ARM(Yolov3Tiny cpu)
|cpu|raspberry 3B|raspberry 4B|Jeston NX|
|:---:|:---:|:---:|:---:|
|without NNPack|6s|2.5s|1.2s|
|with NNPack|2.5s|1.1s|0.6s|
- **Yolo GPU**
- Ubuntu16.04 GCC Cuda10.1 GTX1080Ti
|net|yolov3|yolov3_tiny|yolov4|
|:---:|:---:|:---:|:---:|
|time|30ms|8ms|30ms|
- Jetson NX
|net|yolov3|yolov3_tiny|yolov4|
|:---:|:---:|:---:|:---:|
|time|280ms|30ms|210ms|
- **Yolo GPU cuDnn FP16**
- Jetson NX
|net|yolov3|yolov4|
|:---:|:---:|:---:|
|time|140ms|120ms|
- **Mobilenet Yolo GPU cuDnn Test**
- Jetson NX
|net|yoloface100k|yoloface500k|mobilenetv2_yolov3_nano|mobilenetv2_yolov3_lite|
|:---:|:---:|:---:|:---:|:---:|
|time|7ms|20ms|20ms|30ms|
Msnhnet未来计划¶
- 新增更多的算子(x86 + arm)。
- 对特殊算子进行优化, 例如对1x1, 2x2, 3x3, 4x4等卷积进行单独实现(x86 + arm)。
- 使用更优的算法对卷积层进行优化,如winograd, FFT, 大核分块等(x86 + arm)。
- 进一步对arm框架进行neon intrins支持和neon assembly支持。
- 支持fp16(arm)。
- 支持INT8/7<模型后量化>(x86 + arm)。
- 支持2BIT/3BIT/dorefa(x86 + arm)。
- 框架图优化。
- 算子精简(x86 + arm)。
- IO优化(x86 + arm)。
- 新增一些预处理+预处理优化(x86 + arm)。
- 新增一些后处理+后处理优化(x86 + arm)。
- 对vulkan/opengl加速支持(x86 + arm)。
- 对C#版更多网络的支持。
- 对python语言的支持。
- 对更多pytorch的op支持。
Msnhnet维护人员¶
Msnhnet证书¶
- MIT
关于Msnhnet¶
- Msnhnet由参与人员业余时间进行维护,更新速度可能不会很快。同时也欢迎更多对Msnhnet感兴趣的小伙伴参与Msnhnet维护改进,欢迎大家pr.同时由于开发人员的能力认知有限,也希望大家给我们提出宝贵的建议。
本文总阅读量次