乱谈CUTLASS GTC2020 SLIDES
前言¶
开局先来点鸡汤:
本篇博客基于 cutlass GTC2020的slides,地址为:https://www.nvidia.com/en-us/on-demand/session/gtcsj20-s21745/
what are tensorcores¶

TensorCore是一个硬件概念,主要是用于加速矩阵乘操作运算(我们也叫MMA,Matrix Multiply Add),执行的是:
D = A * B + C
同时也支持多种输入类型,数值累加类型。
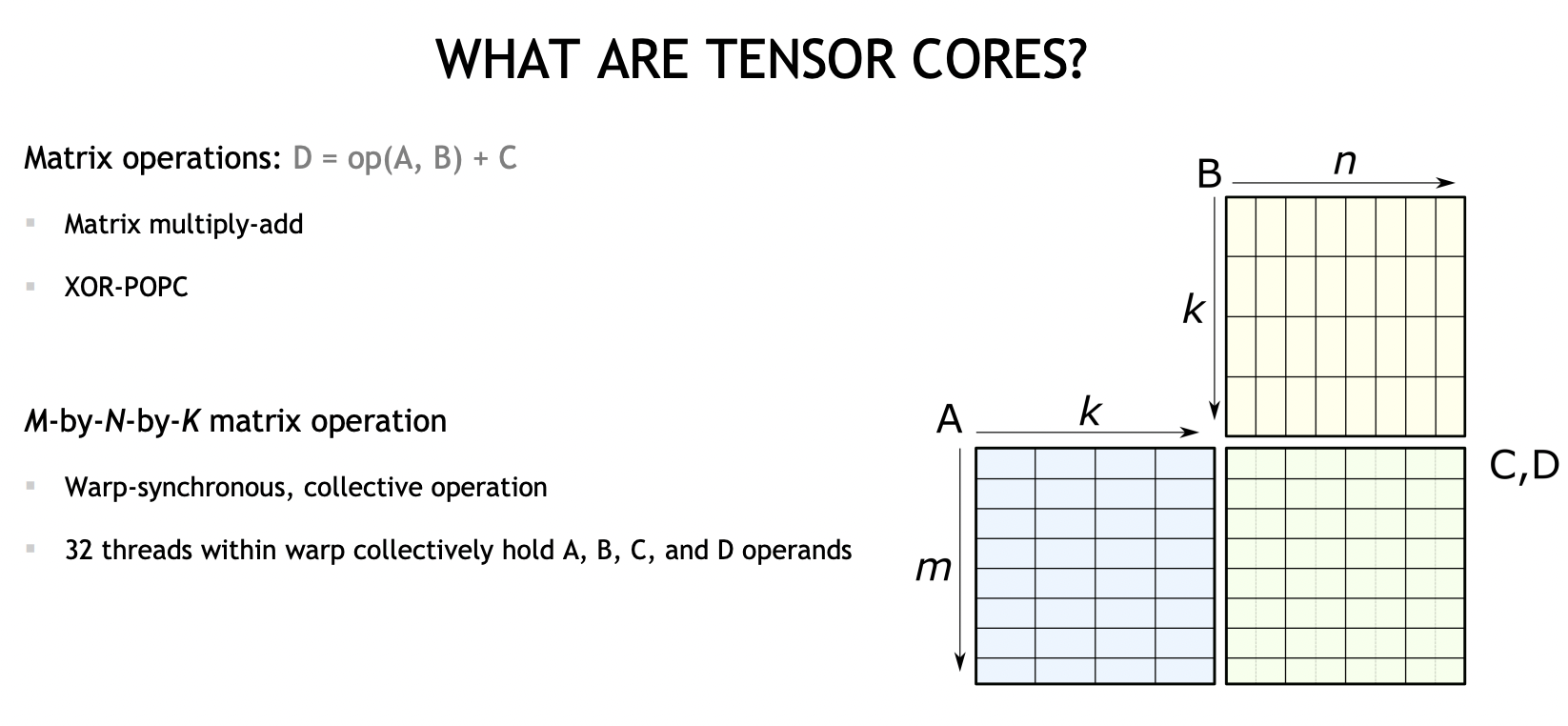
编程层次上,TensorCore处于Warp(连续的32个threads)这一层,一个WARP内持有A, B, C, D四个操作数的数据。
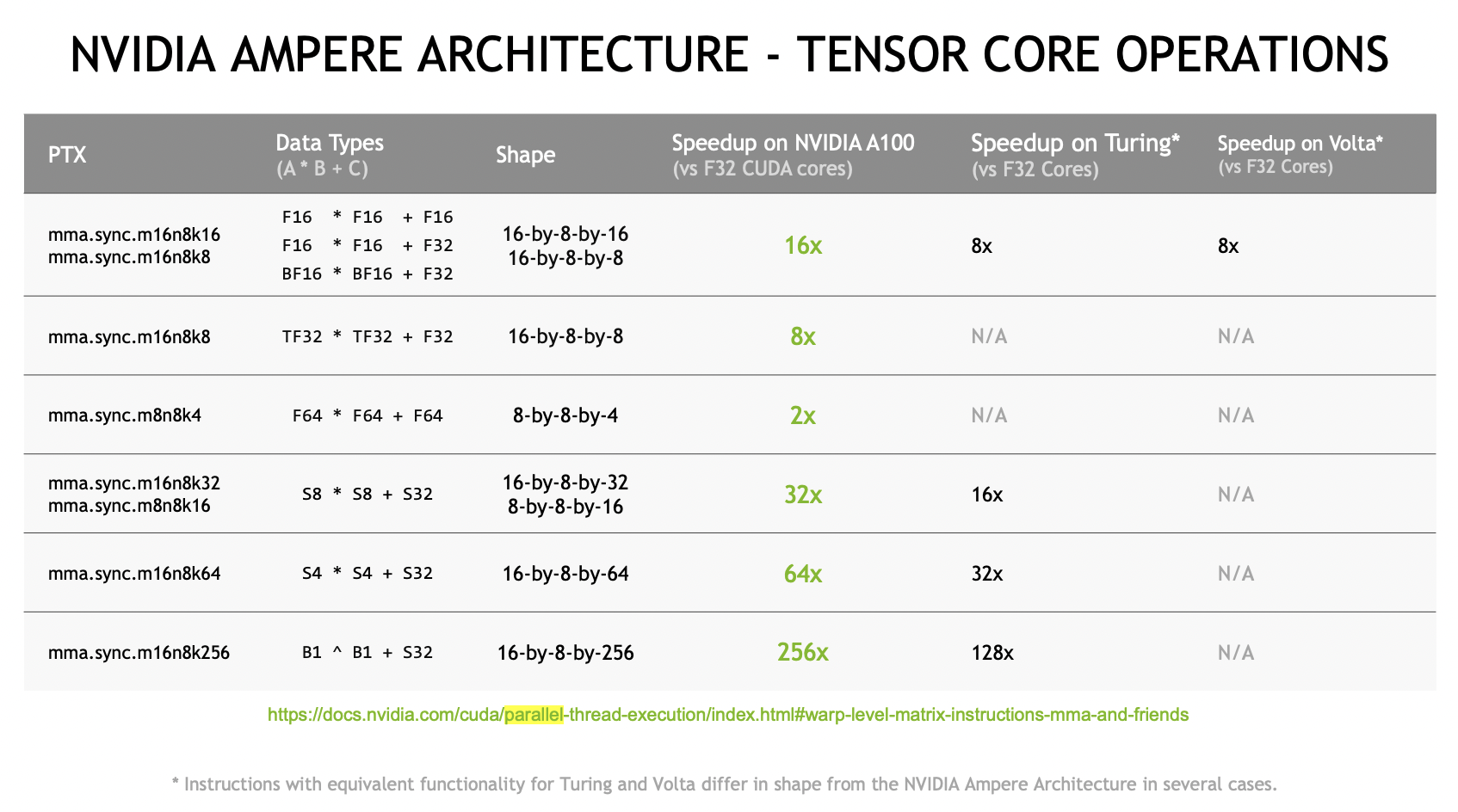
上图是Ampere架构支持的MMA指令,支持多种尺寸,数据类型。
Slides下面就是介绍各种尺寸的MMA,我们可以结合代码跑一下
S8 * S8 + S32 Code¶
使用TensorCore的时候,对数据排布是有特殊要求的。MMA指令是在一个WARP内执行,所以各个线程对应取数据的位置也是有特殊的映射关系。
首先来个简单的 int8 x int8 = int32 的(8x16 matmul 16x8 = 8x8)运算,Slides里的排布是这样:
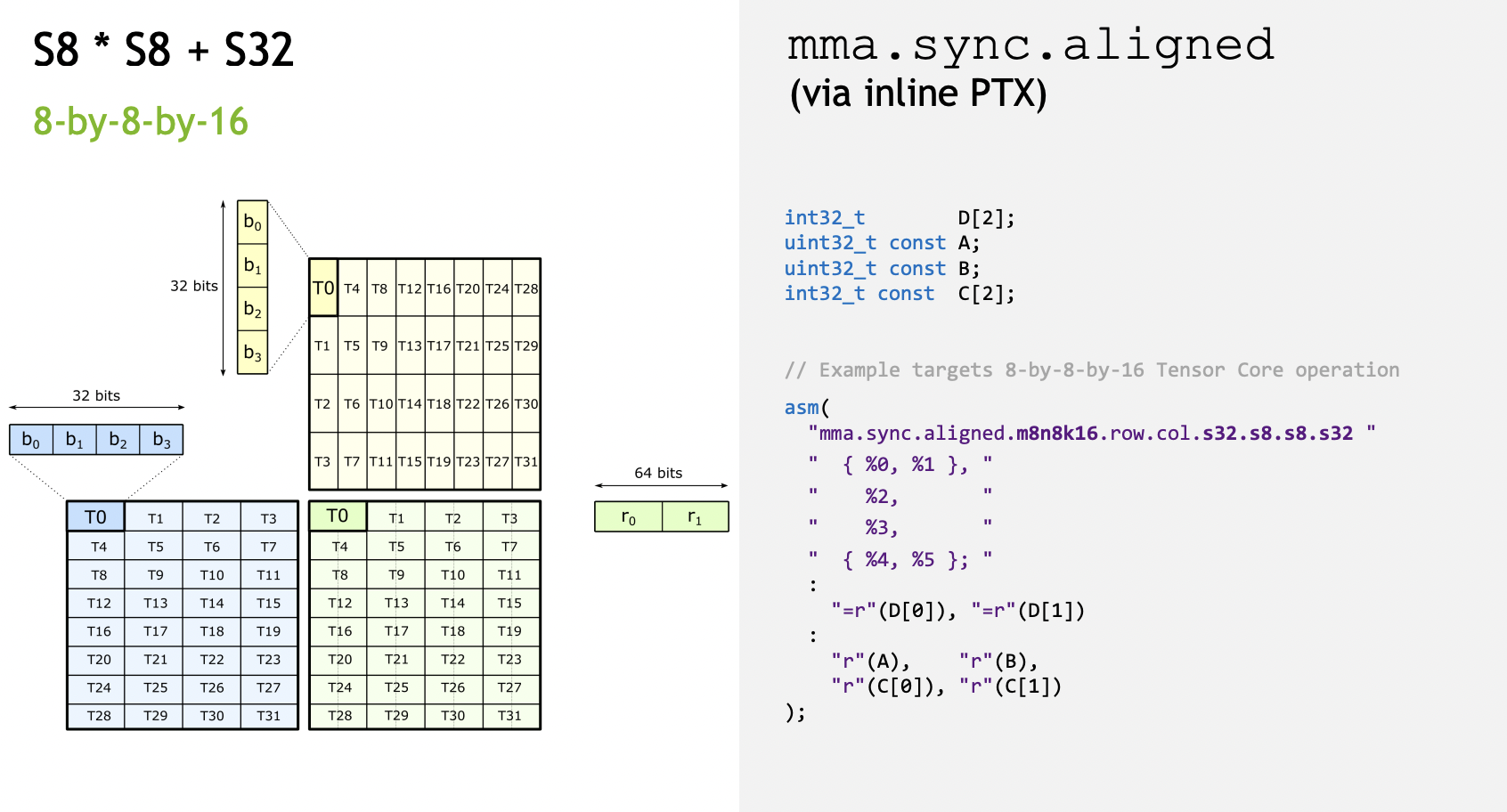
每个线程持有 A的4x8bit = 32bit 数据,B的4x8bit = 32bit 数据,C/D的 2x32bit = 64bit 数据
我们假设使用的矩阵为:

我们把线程映射跟元素写到一块:
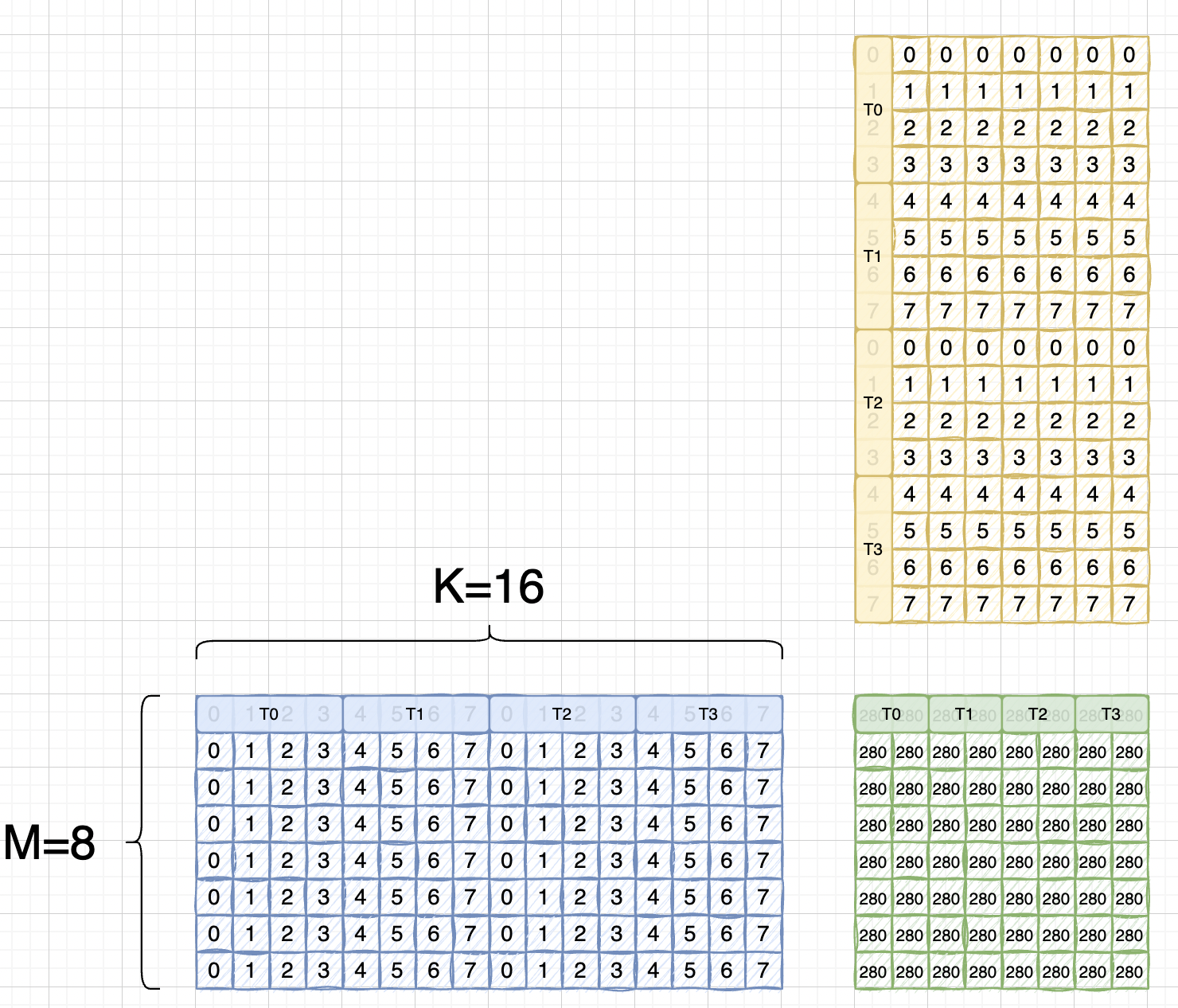
而由于tensor core instruction is TN layout.
这里还是沿用blas计算库的说法,blas库里,会将 a x b = c -> b_T x a_T = c_T,这里的T说的是B矩阵是transpose的,也即A矩阵是RowMajor, B矩阵是ColMajor.
所以实际上应该是:

可以看到跟A矩阵是完全一样了,后面取元素的时候两个矩阵寄存器所使用的index是一致的
这里使用的代码是slides里的example。

先简单写个初始化的kernel:
#include "stdio.h"
#include "stdint.h"
__global__ void set_value(int8_t* x, int32_t elem_cnt){
for(int i = 0; i < elem_cnt; i++){
x[i] = static_cast<int8_t>(i % 8);
}
}
接下来是TensorCore运算的kernel,需要注意的是这里用的都是int32类型,而我们执行的是 s8 x s8 = s32 的计算,调用的时候需要reinterpret_cast下。
// Do AxB + C = D.
__global__ void tensor_core_example_8x8x16(int32_t *D,
uint32_t const *A,
uint32_t const *B,
int32_t const *C) {
// Compute the coordinates of accesses to A and B matrices
int outer = threadIdx.x / 4; // m or n dimension
int inner = threadIdx.x % 4; // k dimension
// Compute the coordinates for the accumulator matrices
int c_row = threadIdx.x / 4;
int c_col = 2 * (threadIdx.x % 4);
// Compute linear offsets into each matrix
int ab_idx = outer * 4 + inner;
int cd_idx = c_row * 8 + c_col;
// Issue Tensor Core operation
asm volatile("mma.sync.aligned.m8n8k16.row.col.s32.s8.s8.s32 {%0,%1}, {%2}, {%3}, {%4,%5};\n"
: "=r"(D[cd_idx]), "=r"(D[cd_idx+1])
: "r"(A[ab_idx]), "r"(B[ab_idx]), "r"(C[cd_idx]), "r"(C[cd_idx+1]));
}
__global__ void printMatrix(int32_t* result, const int m, const int n){
for(int row = 0; row < m; row++){
for(int col = 0; col < n; col++){
printf("Row id: %d, Col id: %d, result is: %d \n", row, col, result[row * n + col]);
}
}
}
int main(){
int8_t* a;
int8_t* b;
int32_t* c;
int32_t* d;
const int32_t m = 8;
const int32_t k = 16;
const int32_t n = 8;
cudaMalloc(&a, m * k * sizeof(int8_t));
cudaMalloc(&b, k * n * sizeof(int8_t));
cudaMalloc(&c, m * n * sizeof(int32_t));
cudaMalloc(&d, m * n * sizeof(int32_t));
set_value<<<1, 1>>>(a, m * k);
set_value<<<1, 1>>>(b, k * n);
cudaMemset(c, 0, sizeof(int32_t) * m * n);
cudaMemset(d, 0, sizeof(int32_t) * m * n);
tensor_core_example_8x8x16<<<1, 32>>>(reinterpret_cast<int32_t*>(d),
reinterpret_cast<uint32_t*>(a),
reinterpret_cast<uint32_t*>(b),
reinterpret_cast<int32_t*>(c));
printMatrix<<<1, 1>>>(d, m, n);
cudaDeviceSynchronize();
cudaFree(a);
cudaFree(b);
cudaFree(c);
cudaFree(d);
}
举一反三¶
下面我们也可以举一反三,写下 f16*f16+fp32的 tensorcore程序,对应的指令是 16 x 8 x 8,不过线程持有的数据跟前面的例子有些不同,需要改下

#include "stdio.h"
#include "stdint.h"
#include "cuda_fp16.h"
template<typename T>
__global__ void set_value(T* x, int32_t elem_cnt){
for(int i = 0; i < elem_cnt; i++){
x[i] = static_cast<T>(i % 8);
}
}
__global__ void tensor_core_example_16x8x8(float *D,
uint32_t const *A,
uint32_t const *B,
float const *C) {
// Compute the coordinates of accesses to A and B matrices
int outer = threadIdx.x / 4; // m or n dimension
int inner = threadIdx.x % 4; // k dimension
// Compute the coordinates for the accumulator matrices
int c_row = threadIdx.x / 4;
int c_col = 2 * (threadIdx.x % 4);
// Compute linear offsets into each matrix
int ab_idx = outer * 4 + inner;
int cd_idx = c_row * 8 + c_col;
// Issue Tensor Core operation
asm volatile("mma.sync.aligned.m16n8k8.row.col.f32.f16.f16.f32 {%0,%1,%2,%3}, {%4,%5}, {%6}, {%7,%8,%9,%10};\n"
: "=f"(D[cd_idx]), "=f"(D[cd_idx+1]), "=f"(D[cd_idx+64]), "=f"(D[cd_idx+1+64])
:
"r"(A[ab_idx]), "r"(A[ab_idx+32]),
"r"(B[ab_idx]),
"f"(C[cd_idx]), "f"(C[cd_idx+1]), "f"(C[cd_idx+64]), "f"(C[cd_idx+1+64])
);
}
__global__ void printMatrix(float* result, const int m, const int n){
for(int row = 0; row < m; row++){
printf("Row id: %d, result is: ", row);
for(int col = 0; col < n; col++){
printf("%f ", static_cast<float>(result[row * n + col]));
}
printf("\n");
}
}
int main(){
half* a;
half* b;
float* c;
float* d;
const int32_t m = 16;
const int32_t k = 8;
const int32_t n = 8;
cudaMalloc(&a, m * k * sizeof(half));
cudaMalloc(&b, k * n * sizeof(half));
cudaMalloc(&c, m * n * sizeof(float));
cudaMalloc(&d, m * n * sizeof(float));
set_value<half><<<1, 1>>>(a, m * k);
set_value<half><<<1, 1>>>(b, k * n);
cudaMemset(c, 0, sizeof(float) * m * n);
cudaMemset(d, 0, sizeof(float) * m * n);
tensor_core_example_16x8x8<<<1, 32>>>(reinterpret_cast<float*>(d),
reinterpret_cast<uint32_t*>(a),
reinterpret_cast<uint32_t*>(b),
reinterpret_cast<float*>(c));
printMatrix<<<1, 1>>>(d, m, n);
cudaDeviceSynchronize();
cudaFree(a);
cudaFree(b);
cudaFree(c);
cudaFree(d);
}

实际使用的话,只需对应实例化MMA模板即可:

DATA Movement¶
下面几张Slides谈论的是矩阵乘中数据搬运的部分,以及新架构引入的LDMatrix指令。

这张Slide还是以S8 x S8 + S32的mma为例,前面我们也推导过,一个WARP完成 8x16 matmul 16x8, 那么一个WARP加载A矩阵和B矩阵一共需要 (8x16 + 16x8) = 256B,FLOPS计算如下:
C 矩阵一共 8 * 8 = 64 个元素
每个元素需要16次乘法和加法,
FLOPS = 64 * 16 * 2 = 2048
那么我们再看下Ampere架构白皮书里面标注的设计规格,A100的Int8 tensorcore算力是624TFLOPS(312是FP16,int8对应翻一倍),80GB A100的HBM速度为1.6TB/s,那么其理想计算访存比是 400flops/byte
相较两者访存比,可以看到使用了TensorCore后,访存成为了瓶颈,这也是为什么数据搬运在优化GEMM里是很重要的一环。
这里我觉得是作为一种理想情况的估算,实际情况可能更复杂,需要考虑缓存命中率等(参考知乎李少侠的文章)
因此cutlass抽象了一套高效的数据搬运流程,过往很多GEMM优化文章都有介绍,就不赘述了:
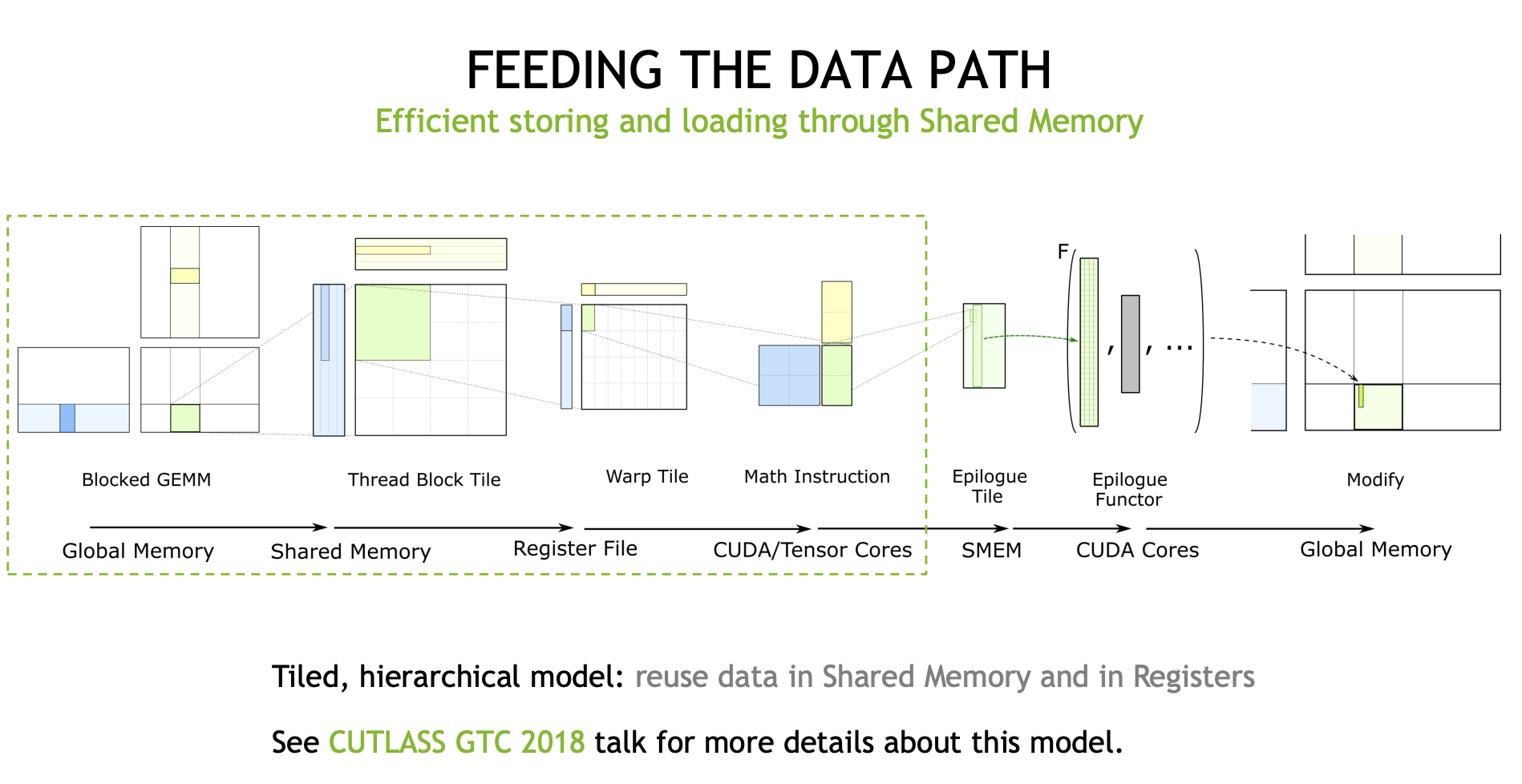
其中在Ampere架构里面,新引入了AsyncCopy机制,也就是在Global Memory 到 SharedMemory 这一个环节。以往我们需要从Global Memory读取到线程寄存器,再从寄存器里存储到SharedMemory,但有了这个指令后,我们可以一步到位,从GlobalMemory -> SharedMemory,一定程度减轻了寄存器压力。(如果你常profile GEMM应该能有所体会)

并且它是一种异步操作,意味着我们可以提前发射出好几轮(在cutlass里往往称为Stage)数据预取的指令,以实现延迟隐藏(我搬我的,你算你的)。
而另外一个比较特殊的指令则是LDMatrix,这个指令是用在SharedMemory到Register的过程。
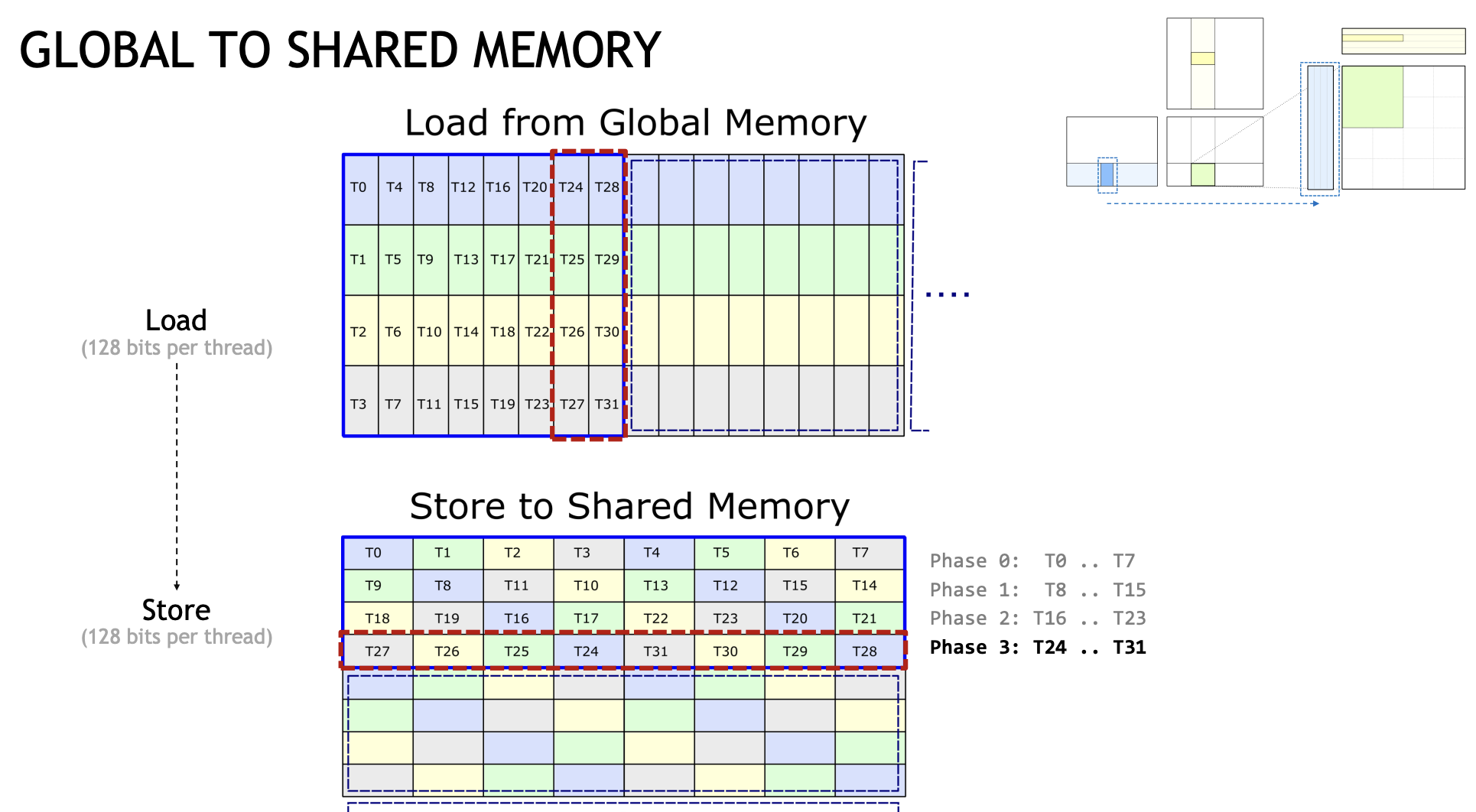
为了尽可能打满带宽,在GlobalMemory->SharedMemory这一环节中,每个线程都是以128bit的访问粒度去存储。而前面也提到TensorCore对应每个线程对数据有不同的索引,这也就导致每个线程需要的元素在SharedMemory上是不连续的。

以Slides为例,我们看T0线程,它需要T0,T8,T16,T24对应SharedMemory的第一个元素。在没有LDMatrix之前,它需要对应四次LDS32操作,而如果我们调用LDMatrix,可以一个指令就完成上述的操作:

下面我们简单提一下Cutlass的crosswise Layout(我看的不是很明白)。通常来说为了避免BankConflict,我们常见的做法是Padding多一个元素,让Warp内线程访问错开,但是这样肯定是带来了SharedMemory浪费。而Cutlass提出了一种新的Layout,通过一系列很复杂的异或操作算出来了一个索引,最终大概长这样:
这里每个线程存了128bit数据,也就是占了4个bank。还是以刚刚线程0所需的数据为例,可以看到T0 T8 T16 T24都是错开到不同的Bank上(其他线程同理)
下面是一个LDMatrix的example
PS:我不知道我写的对不对,至少从结果上看还挺合理,如果有错也麻烦指正
LDMatrix example¶
#include "stdio.h"
#include "stdint.h"
#include "cuda_fp16.h"
#define LDMATRIX_X4(R0, R1, R2, R3, addr) \
asm volatile("ldmatrix.sync.aligned.x4.m8n8.shared.b16 {%0, %1, %2, %3}, [%4];\n" \
: "=r"(R0), "=r"(R1), "=r"(R2), "=r"(R3) \
: "r"(addr))
template<typename T>
__global__ void set_value(T* x, int32_t elem_cnt){
for(int i = 0; i < elem_cnt; i++){
x[i] = static_cast<T>(i % 8);
}
}
// 从CUTLASS里抄的
__device__ uint32_t cast_smem_ptr_to_uint(void const* const ptr) {
// We prefer to use the new CVTA intrinsics if they are available, otherwise we will fall back to
// the previous internal intrinsics if they are available.
#if CUTE_CVTA_GENERIC_TO_SHARED_ACTIVATED
//
// This NVVM intrinsic converts an address in shared memory to a plain
// unsigned integer. This is necessary to pass to shared memory instructions
// in inline PTX.
//
// In CUDA 11 and beyond, this replaces __nvvm_get_smem_pointer() [only available in 10.2].
//
//__device__ size_t __cvta_generic_to_shared(void* ptr);
/// CUTE helper to get SMEM pointer
return static_cast<uint32_t>(__cvta_generic_to_shared(ptr));
#elif CUTE_NVVM_GET_SMEM_POINTER_ACTIVATED
return __nvvm_get_smem_pointer(ptr);
#elif defined(__CUDA_ARCH__)
uint32_t smem_ptr;
asm(
"{ .reg .u64 smem_ptr; cvta.to.shared.u64 smem_ptr, %1; cvt.u32.u64 %0, smem_ptr; }\n"
: "=r"(smem_ptr) : "l"(ptr));
return smem_ptr;
#else
(void) ptr;
printf("ERROR: cast_smem_ptr_to_uint not supported but used.\n");
return 0;
#endif
}
__global__ void ldmatrix_example(uint32_t* x,
uint32_t* y) {
const int32_t row_tid = threadIdx.x / 8;
const int32_t col_tid = threadIdx.x % 8;
uint32_t RegisterLoad[4];
uint32_t RegisterTensorcore[4];
__shared__ half smem[4][64];
*reinterpret_cast<float4*>(RegisterLoad) = *reinterpret_cast<float4*>((x + threadIdx.x * 4));
half* half_register_load_ptr = reinterpret_cast<half*>(RegisterLoad);
if(threadIdx.x == 0){
printf("ThreadIdx: %d, Value is: %f, %f, %f, %f, %f, %f, %f, %f. \n", threadIdx.x,
static_cast<float>(half_register_load_ptr[0]), static_cast<float>(half_register_load_ptr[1]),
static_cast<float>(half_register_load_ptr[2]), static_cast<float>(half_register_load_ptr[3]),
static_cast<float>(half_register_load_ptr[4]), static_cast<float>(half_register_load_ptr[5]),
static_cast<float>(half_register_load_ptr[6]), static_cast<float>(half_register_load_ptr[7]));
}
int32_t xor_idx = threadIdx.x;
if(row_tid == 1){
xor_idx ^= 1;
}
if(row_tid == 2){
xor_idx ^= 2;
}
if(row_tid == 3){
xor_idx ^= 3;
}
const int32_t store_smem_row_tid = xor_idx / 8;
const int32_t store_smem_col_tid = xor_idx % 8;
// if(threadIdx.x == 0){
printf("ThreadIdx: %d, XorIdx is: %d, store_smem_row_tid is :%d, store_smem_col_tid is: %d. \n", threadIdx.x, xor_idx, store_smem_row_tid, store_smem_col_tid * 8);
// }
half* smem_ptr = &(smem[store_smem_row_tid][store_smem_col_tid * 8]); // smem[store_smem_row_tid][store_smem_col_tid * 4];
*reinterpret_cast<float4*>(smem_ptr) = *reinterpret_cast<float4*>(RegisterLoad);
__syncthreads();
if(threadIdx.x == 0 || threadIdx.x == 8 || threadIdx.x == 16 || threadIdx.x == 24){
printf("ThreadIdx: %d, SMEM Value is: %f, %f, %f, %f, %f, %f, %f, %f. \n", threadIdx.x,
static_cast<float>(smem[0][0]), static_cast<float>(smem[0][1]),
static_cast<float>(smem[0][2]), static_cast<float>(smem[0][3]),
static_cast<float>(smem[0][4]), static_cast<float>(smem[0][5]),
static_cast<float>(smem[0][6]), static_cast<float>(smem[0][7]));
}
uint32_t addr = cast_smem_ptr_to_uint(smem_ptr);
LDMATRIX_X4(RegisterTensorcore[0], RegisterTensorcore[1], RegisterTensorcore[2], RegisterTensorcore[3], addr);
half* half_register_tensorcore_ptr = reinterpret_cast<half*>(RegisterTensorcore);
if(threadIdx.x == 0){
printf("After LDMATRIX, ThreadIdx: %d, Value is: %f, %f, %f, %f, %f, %f, %f, %f. \n",
threadIdx.x,
static_cast<float>(half_register_tensorcore_ptr[0]), static_cast<float>(half_register_tensorcore_ptr[1]),
static_cast<float>(half_register_tensorcore_ptr[2]), static_cast<float>(half_register_tensorcore_ptr[3]),
static_cast<float>(half_register_tensorcore_ptr[4]), static_cast<float>(half_register_tensorcore_ptr[5]),
static_cast<float>(half_register_tensorcore_ptr[6]), static_cast<float>(half_register_tensorcore_ptr[7]));
}
}
__global__ void printMatrix(half* result, const int m, const int n){
for(int row = 0; row < m; row++){
printf("Row id: %d, result is: ", row);
for(int col = 0; col < n; col++){
printf("%f ", static_cast<float>(result[row * n + col]));
}
printf("\n");
}
}
int main(){
half* x;
half* y;
const int32_t m = 16;
const int32_t k = 16;
const int32_t n = 8;
cudaMalloc(&x, m * k * sizeof(half));
cudaMalloc(&y, m * k * sizeof(half));
set_value<half><<<1, 1>>>(x, m * k);
cudaMemset(y, 0, sizeof(half) * m * k);
ldmatrix_example<<<1, 32>>>(reinterpret_cast<uint32_t*>(x),
reinterpret_cast<uint32_t*>(y));
// printMatrix<<<1, 1>>>(y, m, k);
cudaDeviceSynchronize();
cudaFree(x);
cudaFree(y);
}
对于 cast_smem_ptr_to_uint 这个函数我也不是很清楚,我从元戎启行的矩阵转置Blog里摘了一段:
需要额外注意的是,共享内存的地址并不是全局同步地址(Generic Address),因此在使用共享内存地址读取或写入数据前,要经过一次内置函数__cvta_generic_to_shared,当然也可以自己手写PTX
xor 换算索引 example¶
for i in range(8, 16):
print(i, i ^ 1)
for i in range(16, 24):
print(i, i ^ 2)
for i in range(24, 32):
print(i, i ^ 3)
本文总阅读量次